

在现代金融科技领域,Plaid 作为一家领先的支付和金融服务平台,一直在寻求优化其基础设施以支持不断增长的业务需求。本文将详细介绍 Plaid 如何从 AWS Aurora MySQL 迁移到 TiDB,这一过程不仅提升了系统的可靠性和性能,还显著降低了维护成本。通过这次迁移,Plaid 为未来 5 到 10 年的增长奠定了坚实的基础。
动机
作为 Plaid 存储团队的创始人,Zander Hill 看到了他们在 Aurora MySQL 上的投资以及与其他他们自托管的系统相比所面临的限制。Plaid 的存储团队提供了一个可扩展且可靠的平台,用于存储 Plaid 的在线数据,并专注于关系型、NoSQL 和缓存存储系统。
Zander 与公司的架构负责人 Joy Zheng 以及数据库技术专家 Mingjian Liu 一起制定了评估替代方案的结构,然后为团队设定了一个雄心勃勃的时间表:一个季度进行研究,一个季度进行原型设计,并在 Amazon 的 MySQL 5.7 停用之前完成向新平台的服务过渡!为了确保项目为业务带来高价值,他们设定了一个设计约束,即该项目不能持续超过两年。
技术概况
- 总在线存储堆栈:约 800 台服务器,约 50 万次 QPS,约 650 TB 数据,内部 SLA 为 99.99%+ 可用性。
- SQL 平台:约 446 台服务器,约 14 万次 QPS,约 40 TB 数据,SLA 为 99.99%+。
- TiDB 部分(当前):约 160 台服务器,约 17 万次 QPS,约 70 TB 数据,跨集群约 700 个 vCPU。
- 存储团队的 6 名软件工程师。
为什么 Plaid 要放弃 Aurora MySQL
有几个原因促使 Plaid 寻找主要关系型数据存储的新解决方案:
1. 可靠性挑战
- Plaid 的公共 SLA 和内部 SLO 在应用层转换为数据库层的 99.995%(应用 Google SRE 最佳实践,增加一个“9”的可靠性)。
- Aurora 的单写入器架构成为一个单点故障,在配置更改、扩展、重启和故障转移期间引入停机时间。
- 要求每个团队都具备数据库专业知识以确保可靠性并不具扩展性,Plaid 看到了集中化所有权和可靠性保证的机会。
2. 开发人员效率低下
- 随着 Aurora 上的工作负载增长,Plaid 遇到了写入吞吐量瓶颈(例如,大表上的高行争用模式下每秒约 12,000 次写入)。
- 在线模式更改通常需要复杂的变通方法。团队添加了新表而不是修改现有表,以避免服务中断或延长维护时间。
- Plaid 每年花费两年的工程时间来设计应对 Aurora 限制的方案,尤其是在大表(2-10+ TB)上。
3. 高维护负担
- 2023 年,Plaid 花费了两个工程季度将 Aurora 从 MySQL 5.6 升级到 5.7。每次升级或例行任务(启用二进制日志复制、调整大小等)都需要几分钟的停机时间。
4. 分片和可扩展性需求
- Aurora 在写入方面可扩展到一定程度,并且在读取流量方面广泛可扩展。
- TiDB 提供自动分片,即使在写入流量方面也能保持一致的性能。
5. MySQL 5.7 停用
- MySQL 5.7 社区支持已结束,Aurora 的停用也迫在眉睫。
- Plaid 知道 MySQL 5.7 到 8.0 的升级将是一项巨大努力,基于 Facebook 的 8.0 升级经验。
- Plaid 决定将升级工作重新定位为平台切换。
Plaid 的时间表
- 2023 年第一季度:评估替代 AWS Aurora MySQL 5.7 的选项。
- 2023 年第二季度:完成初步概念验证并验证 TiDB 对 Plaid 的功能。
- 2023 年第三季度:最终确定 RFC,获得财务和领导层支持,并构建初始 TiDB 基础设施。
- 2023 年第四季度至 2024 年第一季度:在 TiDB 上采用第一个服务。在几个季度内进展到约 17 个服务。
- 2025 年 1 月:到 2024 年底,Plaid 已过渡 41 个服务。
- 未来:到 2025 年年中完成全面过渡。
服务过渡
单个服务的生命周期
将数据库迁移到新平台可以分解为许多微步骤。Plaid 的内部运行手册有约 200 个不同的任务和约 20 个子运行手册。在高层次上,每个服务过渡遵循四个阶段:移除不兼容性、复制数据、验证和切换。
1. 移除不兼容性
- 强制主键:TiCDC(TiDB 的变更数据捕获机制)需要主键以实现一致的复制。如果表没有主键,Plaid 要求服务团队添加一个。
- 移除外键:外键在 TiDB 的某些生态系统工具中不受支持,并且在分布式数据库中会降低性能。Plaid 在数据库层删除它们,并在需要时在应用层强制执行。
- 审核事务隔离级别:TiDB 不提供可串行化隔离级别。在 MySQL 中使用它的团队必须调整应用逻辑以处理快照隔离(即可重复读)或其他模式。
- 审核自增字段:TiDB 的自增 ID 不是全局单调递增的(因为多个节点分配范围)。如果服务依赖于严格递增的 ID,Plaid 建议按时间戳排序或重新设计 ID 生成逻辑。
- 证明兼容性:在自动化单元和集成测试中切换服务以使用 TiDB,并在生产切换之前暂停该服务的模式迁移。
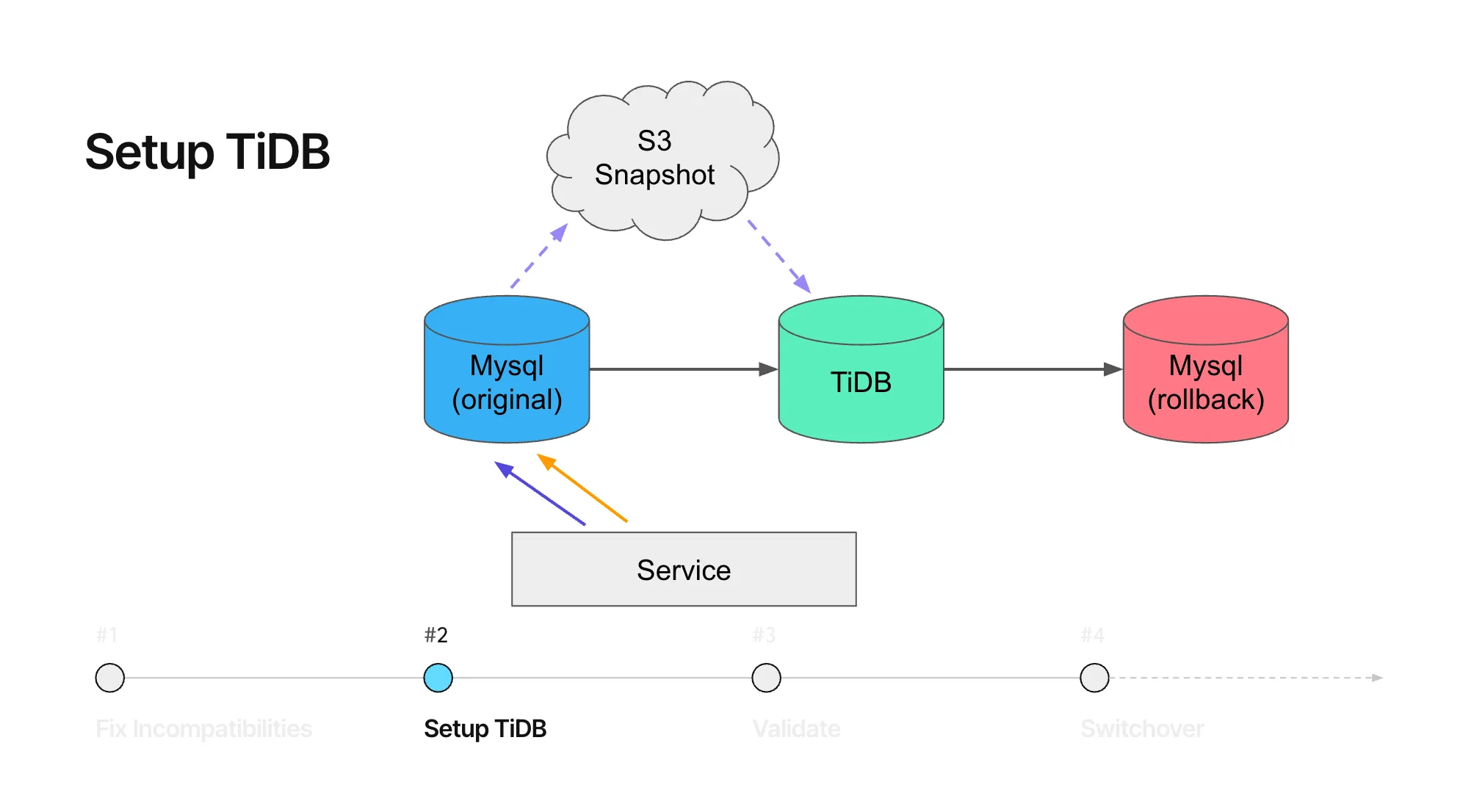
2. 复制数据
一旦表和查询兼容:
- 快照原始 MySQL 数据库并使用 TiDB Lightning 导入到 TiDB。
- 克隆原始 MySQL 数据库到回滚集群,使用相同的快照,为 Plaid 提供了一个在出现问题时的回退路径。
- 在原始 MySQL、TiDB 和回滚 MySQL 集群之间设置复制。
集成 Plaid 的“mysql/tidb/rollback mysql”切换客户端,这是一种内置到共享数据库驱动程序中的功能标记方法,允许停止流量并指向不同的数据库端点。
3. 验证
验证在每一步都会重复进行,Plaid 优先考虑正确性而非速度:
- 数据一致性检查:在导入或开始复制后,Plaid 运行一系列不同的工具(例如 TiDB 的“sync-diff-inspector”)以确保数据完全匹配。Plaid 发现了二进制主键和时间戳列的边缘情况,需要 PingCAP 的补丁。
- 实时查询验证:Plaid 从 Aurora 进行双写和读取到他们的验证集群,以比较正确性和性能。这突显了查询计划的差异,有时 TiDB 使用次优索引,导致额外的数据库负载。Plaid 通过重写查询或使用索引提示来修复这些问题。
- 性能基准测试:这些测量提供了更高的行为正确性保证,对于高流量的 Tier 0 和 Tier 1 服务,延迟至关重要。
4. 切换
使用“mysql/tidb/rollback mysql”框架中的功能标记执行原子切换:
- 暂停对 Aurora 的写入,允许复制完全赶上。
- 在 TiDB 上翻转并重新启用读取。
- 执行安全性和正确性验证。
- 在 TiDB 上翻转并重新启用写入。
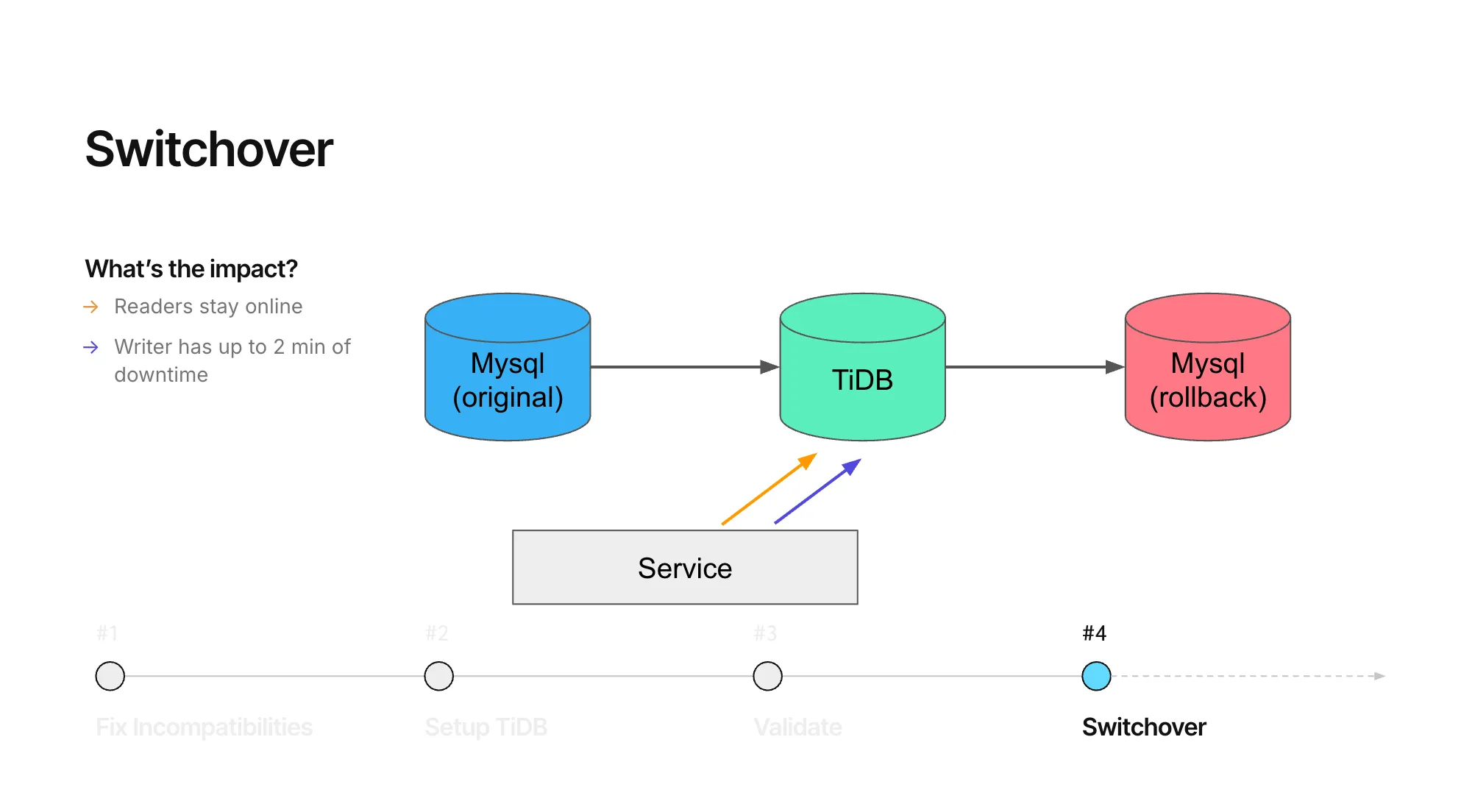
这种方法避免了在两个活动数据库上同时进行读写所带来的可靠性和一致性问题。如果切换后出现问题,Plaid 可以向前故障转移到专用的回滚 MySQL 集群。整个切换过程可以在约 60 秒的写入停机时间内完成,而读取在整个过程中保持可用和一致。
加速
随着仍有数十个服务在排队,而存储团队规模较小,Plaid 改进了他们的策略:
- 标准化一切
- 自动化常见操作(例如,动态运行手册)
- 集中工作
- 批量处理常规步骤
- 首先解决最困难的服务
- 始终有回滚计划
- 原则
- 规划
- 工具
下面,Plaid 详细阐述了两个原则:集中工作和动态运行手册。
集中工作
最初,Plaid 要求客户团队处理一些过渡步骤(例如,在开发环境中切换到 TiDB,应用数据库更改)。但 Plaid 意识到上下文切换的开销太高。Plaid 将这些任务转移到存储团队。这使客户团队摆脱了复制或环境设置的复杂性,并使 Plaid 能够以统一的方式自动化重复任务。Plaid 发现这提高了整个组织的效率并减少了客户团队的挫败感。
动态运行手册
动态运行手册通过将书面文档的清晰度与可执行脚本的强大功能相结合,彻底改变了 Plaid 的操作。Plaid 的团队不再需要在静态 Google Docs 之间切换并手动跟踪每个步骤,现在可以在 Jupyter 笔记本中直接将 Markdown 指令与 TypeScript 代码交错。这种方法提供了明确、自我更新的流程文档,同时使工程师能够在上下文中运行命令,显著减少了人工工作量和错误。
Plaid 采用这些运行手册是出于必要。Plaid 过去为每次新操作克隆一个单独的 Google Doc,并每次精心修订命令。
作为团队负责人,Zander 研究了替代方案,并从一家大公司的同事那里了解到动态运行手册的概念。在等待长时间运行的任务完成时,他原型化了一些解决方案,并最终确定了一个优雅而简单的解决方案,构建了一个 CLI 来支持设计模式,然后让队友帮助构建他们的内部 SDK,抽象了 Aurora 集群或 TiDB 集群等概念,并简化了执行复杂集群命令的接口。
Plaid 选择 Deno 作为 Jupyter 集成的核心语言,因为它具有以下优势:
- 团队/公司对 TypeScript 的熟练掌握
- 通过内联声明进行依赖管理
- 没有虚拟环境的复杂性
- 内置类型安全,适用于他们的 6,000 多行运行手册支持代码
- 强大而简洁的 shell 执行包装器:dax
- 与 Deno 和 NPM 库的广泛兼容性
通过动态运行手册,Plaid 可以创建一个模板运行手册,概述步骤,设置参数,并引用他们的内部 SDK 进行执行步骤。将所有内容集中在一个地方,使每个工程师能够重复遵循并建立最佳实践。操作更顺畅、更快且无错误,因为每个步骤都有文档记录并且可以即时执行。
Plaid 的运行手册 CLI 工具帮助协调参数输入,他们的 SDK 将每个单元格的执行记录在 Slack 中以供审计。这消除了流程中的版本漂移,并为团队提供了正在进行的工作的实时可见性。自实施动态运行手册以来,Plaid 直接提高了速度和正确性。
Plaid 的方法使切换阶段的执行速度加快了 5 倍,服务过渡到 TiDB 的速度加快了 3-4 倍(200 个步骤)。Plaid 在非常标准的服务上或约 80% 的服务上注意到最大的速度提升。
Plaid 强烈鼓励其他寻求现代化运营工作流程的组织采用这种模式。
经验教训
做得好的方面:
- 性能:Plaid 在迁移到 TiDB 之前的基准测试非常准确地反映了他们在 TiDB 上的实际性能表现。
- 滚动升级和扩展:Plaid 在一周内升级了六个生产集群,零停机时间,与 Aurora 的六个月工程时间和数十分钟的停机时间形成鲜明对比。Plaid 的第二次 TiDB 升级只用了两天而不是一周,同样实现了零停机时间。
- 在线模式更改:Plaid 已经进行了模式修改,这在 MySQL 中需要维护窗口。在 TiDB 上,即使在 5+TB 数据和数十亿到数百亿行的表上,也不需要停机时间。
- 供应商支持:PingCAP 的工程师(特别感谢 Michael Zhang)提供了及时的支持,包括新补丁和建议。Plaid 希望所有供应商都能达到这种运营卓越和客户支持水平。
- 沟通:Plaid 从 Aurora MySQL 到 TiDB 的成功过渡得益于清晰的沟通和将项目目标与合作伙伴团队需求对齐。通过强调改进的可靠性、降低的 KTLO 和显著的成本效率等好处,并解决可扩展性和维护负担等关键痛点,Plaid 在团队中获得了强烈的认可和优先级。在概念验证阶段的早期胜利和积极的利益相关者参与进一步确保了操作的对齐和支持。
可以做得更好的方面:
- 生态系统工具的完善度:复制(DM、TiCDC)和导入(TiDB Lightning)各有边缘情况的错误,需要补丁。PingCAP 是一个很好的合作伙伴,但每个错误都消耗了工程时间进行分类和测试。
- 离线导出管道:构建离线导出管道以替换某些 ETL 作业比预期花费了更长的时间。
- 查询计划差异:TiDB 偶尔会选择与 Aurora 不同的执行计划。一些查询最终进行了全表扫描,Plaid 通过双读程序发现了这一点。Plaid 通过查询提示来缓解了这一问题。
- 资源隔离:TiDB 的资源控制很好,但并不完美,Plaid 发现了一些边缘情况,它们不足以保护他们的系统进行工作负载隔离。
- 配置复杂性:TiDB 具有很好的调优灵活性,但也很难理解多个配置值之间的相互作用。Plaid 需要阅读源代码以更好地理解并推荐更简化的最佳实践指导。
结论
通过创建动态运行手册、细致的规划和团队的运营卓越,Plaid 的切换现在平均每项服务约一周(从 3-4 周缩短),写入停机时间不到 60 秒(从约 5 分钟缩短)。这使 Plaid 能够在不牺牲可靠性的情况下更快地过渡服务。从与行业同行的交流来看,Plaid 正在以行业领先的速度采用。
随着 Plaid 扩展到最后一批 MySQL 工作负载,他们还有更多工作要做。但他们的过渡成功验证了他们从 TiDB 寻求的核心优势:无中断的横向扩展、安全的 DDL、更好的可观测性和更简单的操作。最重要的是,Plaid 的工程团队晚上睡得更安稳,减少了分页,并且在进行常规 DDL 更改时感到安全。
没有数据库平台更换是容易的,但通过仔细的规划、自动化和迭代,Plaid 已经证明这不需要花费数年时间。如果其他公司正在考虑 TiDB 或任何其他现代分布式 SQL 数据库,Plaid 的建议如下:
- 彻底规划并尽早测试:包括数据正确性和性能的验证。
- 自动化重复任务:标准化方法,减少手动步骤,并保持回滚路径。
- 首先解决棘手的边缘情况:从长远来看,这将带来回报。
- 全力以赴进行沟通:与客户团队、领导层和供应商进行沟通。
在 Plaid,他们对 TiDB 在未来 5 到 10 年满足他们存储需求的前景感到兴奋。他们知道大规模运行数据库是具有挑战性的,但他们乐观地认为他们可以避免大多数或所有维护窗口,拥有工具来缓解或避免生产事件,以及让团队快速构建客户喜爱的产品的灵活性是任何工程工作的最终胜利。
在 9 月,Plaid 的存储团队(由 Zander Hill 和 Andrew Chen 领导)在 PingCAP 的 2024 年 HTAP 峰会上分享了他们与 TiDB 的经验。他们很荣幸在峰会上发表主题演讲,分享他们快速过渡的经验和迁移到 TiDB 的实用、战术建议。会议参与者的积极反馈进一步证实了他们方法的独特性,尤其是在速度和可靠性方面。