

【是否原创】是
【首发渠道】TiDB 社区
【正文】
一、文章摘要
首先,声明本文目的是为了探究 “PD 如何实现 TiDB 全局数据调度” 而写,便于为日后学习留下可追溯的持久化信息,也可为相关爱好者提供一定阅读经验。
其次,阅读本文需要对 TiDB 中入 Region、Peer 等概念有一定了解。可通过 “二、Introduction” 部分简单了解,详细请通读并操作 PingCap TIDB 官网 文档介绍。
最后,通过阅读 PD v5.2.2 源代码介绍了 PD 如何全流程完成调度 Region 动作,部分监控也有所介绍,大致操作如下:
- 始于 PD 进程启动后,runScheduler()无限循环检测调度器获取 Operator ,流转至 Scheduler 内部;
- 深入 Scheduler 流转用多种 Filter 过滤掉不可用调度 Region,生成 Operator 操作;
- 流转至 Operator 处理以及 AddWaitingOperator 方法,将可调度 Region 加入等待队列;
- 等到来自 TiKV 的心跳信息,检查等待队列中 Region 通过 SendMsg() 发送给 TiKV 去执行;
二、概念简介
- Region : Region 是 TiDB 逻辑存储结构中的最小的逻辑单位,类似于 Oracle 中的 Block;
- Peer : Peer 是一个或多个 Region 的副本,一般为奇数个。多个 Peer 组成 Raft Group 提供存储层高可用,每个 Peer 均有如下不同角色,详情可阅读 Paxos 角色定义;
2.1 Leader : Group Leader 处理用户访问请求、同步数据给 Follower。如果 Leader 挂掉,其他 Follower 会被选为 Leader 保证对外的访问处理;
2.2 Follower : Group Follower 一般是多个,从 Leader 接收数据成为副本,提供数据冗余存储;
2.3 Learner : Group Leaner 仅提供数据复制、访问处理功能,不具有 Leader、Follower 的投票权利; - Store :Store 指的是集群中的存储节点,Store 与 TiKV 实例是严格一一对应的;
- Region Size :Region Size 表示 Store 上的所有 Region 的近似总数据量, v1 策略下以 MB 为单位,v2 策略下以 GB 为单位;
- Region Score :Region Score 表示在不同策略(v1/v2)下,基于不同打分公式计算所得 Store 打分.
三、代码思想
3.1 Schedule 运行时
追溯路径:
Start() --> runCoordinator() --> run() --> c.addScheduler() --> c.runScheduler()
首先,在集群初始化时 CreateServer() 通过 newHandler() 暴露一个 http 处理句柄可以在线增删 scheduler。同时,通过 DefaultSchedulers 从配置文件初始持久化 “balance-region”、“balance-leader”、“hot-region” 三个调度器。
随后,每次启动 PD 都会走上述追溯路径,运行 runScheduler(),并在函数内起一个 for{} 无限循环,不断将已启动的 scheduler 所对应 operator 加入到等待队列中。
最后,Coordinator() 会调起驱动 drivePushOperator() ,在每次接收到 tikv 心跳的时,将对应 operator 推到 region 所对应 tikv 中去执行。
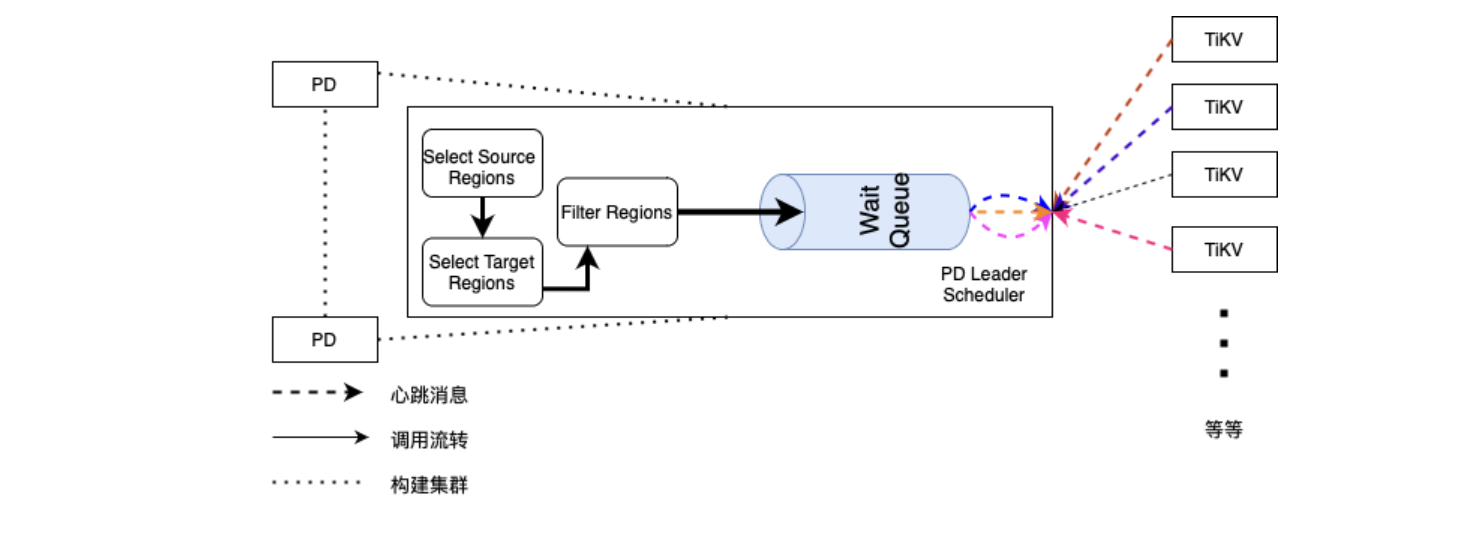
3.2 Schedule 策略
PD 调度平衡原则:拥有 Region 越多,所得 Score 越高,PD 将 Region 从高分向低分的 Store 迁移。RegionScore 函数 依据版本选择 V1 和 V2 两种不同调度策略,从 v5 版本以后引入新策略,如下详细介绍两种策略原理和区别。
3.2.1 V1 策略
v1 基本公式:
- v1 策略连接公式: y = k * x + b
- v1 策略存储公式:Capacity == Available + Used + Irrelative
- V1 放大因子公式:amplification = Region size / (Capacity - Irrelative - Available)
- v1 策略特殊点:
4.1 低占用空间打分: Y = X
4.2 高占用空间打分: Y = X + MaxScore - Capacity
4.3 连接区间打分:Y = k * X + b
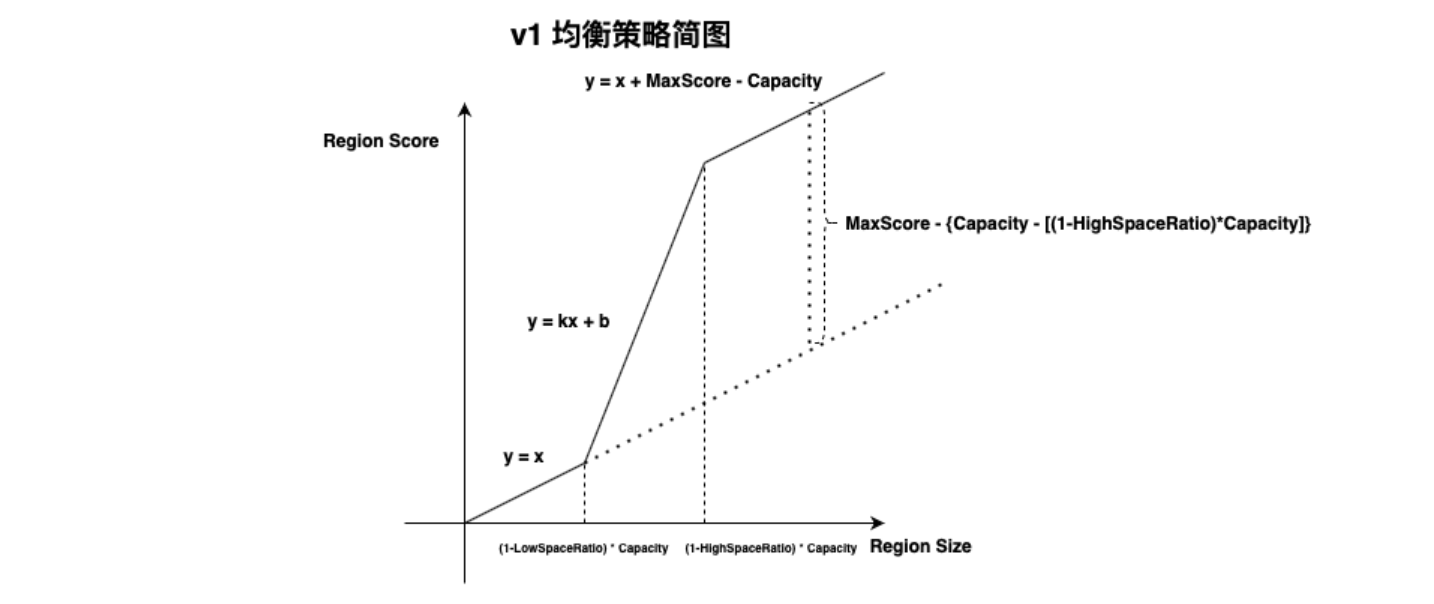
1. v1 均衡策略分别在可用空间充足和不足时使用两套均衡公式,当 Store 可用空间不足时,通过增加一个无穷大量 MaxScore 将可用空间充足时的打分函数上移。通过增大 Store 打分结果方式,尽量不再向该 Store 继续均衡数据。 hard code maxScore = 1024 * 1024 * 1024,相当于 1073741824MB 换算为 1024TB 。
2. 在 Store 可用空间充足时,忽略其他因素直接使用 RegionSize 代表 RegionScore。
3. 由于两个区间使用不同公式,便存在 HighSpace 和 LowSpace 两点间连续性问题,因此增加 y = k*x + b 的中间函数连接两点。因此,根据一元方程公式可得出如下公式系数:
k = [(maxScore - highSpaceRatio * Capacity) - (1 - lowSpaceRatio) * Capacity] / (lowSpacePoint X2 - highSpacePoint X1)
b = MaxScore - {Capacity - [(1-HighSpaceRatio)*Capacity]}
如下是代码细节实现了上述逻辑行为,值得一提的是在算出 RegionScore 后还会通过 score / math.Max(s.GetRegionWeight(), minWeight) 公式进行 Store 权重计算得到最终结果。minWeight 是 hard code “1e-06” 。
代码实现细节:
func (s *StoreInfo) regionScoreV1(highSpaceRatio, lowSpaceRatio float64, delta int64) float64 {
var score float64 // Store 得分变量定义;
var amplification float64 // 计算放大因子变量定义;
available := float64(s.GetAvailable()) / mb // 磁盘Available;
used := float64(s.GetUsedSize()) / mb // 磁盘已用空间;
capacity := float64(s.GetCapacity()) / mb // 磁盘总空间;
if s.GetRegionSize() == 0 || used == 0 { // 放大因子 由于 Rocks DB 压缩算法而产生,直接取
amplification = 1 // 用 Region Size 加和一般大于真实磁盘空间占用;
} else {
amplification = float64(s.GetRegionSize()) / used
}
highSpaceBound := (1 - highSpaceRatio) * capacity // Store 高占用空间配额,由 highSpaceRatio 计算得出;
lowSpaceBound := (1 - lowSpaceRatio) * capacity // Store 低占用空间配额,由 lowSpaceRatio 计算得出;
if available-float64(delta)/amplification >= highSpaceBound {
// 在 Available 高于 highSpaceBound 时,RegionScore = Available + delta,delta 表示正在变动的空间占用;
// 目的:空间充足时,基于 Region Size 调度;
score = float64(s.GetRegionSize() + delta)
} else if available-float64(delta)/amplification <= lowSpaceBound {
// 在 Available 低于 lowSpaceBound 时,RegionScore = MaxScore - Available;
// 目的:空间不足时,基于 Used Capacity 调度,扩大 Store Region Score 从而避免向该 Store 再继续调度数据;
score = maxScore - (available - float64(delta)/amplification)
} else {
// 算出磁盘少量占用时,点位的 x,y 值;
x1, y1 := (used+available-highSpaceBound)*amplification, (used+available-highSpaceBound)*amplification
// 算出磁盘高度占用时,点位的 x,y 值;
x2, y2 := (used+available-lowSpaceBound)*amplification, maxScore-lowSpaceBound
// 通过公式算出变化曲线斜率;
k := (y2 - y1) / (x2 - x1)
// 通过公式算出两线平行差;
b := y1 - k*x1
// 通过输入当前 Store 所有 Region Size ,计算出当前 Region Score 得分;
score = k*float64(s.GetRegionSize()+delta) + b
}
// 最终 Region Score 为计算所测得 Score / RegionWeight
return score / math.Max(s.GetRegionWeight(), minWeight)
}
3.2.2 V2 策略
在 TiDB v5 开始引入 HMA(hull-moving-average) 来计算动态均衡过程中的 Store 可用空间大小, 如下图 HMA 是移动均线的一种并具有实时性好的优点,很好降低其他均线均所带有的滞后性,如:简单滑动均线(SMA)。HMA 大致原理:先取滑动平均周期内均值点 4.5,再取缩短平均周期至一半取右端点 9 与 5 中点 7,再取两点差额 2.5 (2.5 = 7 - 4.5),最后 2.5 + 7 ~ 9.5,通过微过度补偿方式实现均线的准实时性。

v2 版本策略中摒弃了 v1 版本的 high-space-ratio 参数,在 Store 低占用空间时,计算了可用空间对打分的影响。当 Store 高度占用空间时,为实现减少向该 Store 数据移动的目的,删除了可用空间的影响。
当所有 Store 所省空间均低于 F (hard code 50GB)时,所有 Store 的打分会趋紧相同,剩余空间也会趋紧相同。
v2 基本公式:
- v2 策略平衡公式: Score = (K + M * (Log© - Log(A-F+1)) / (C - A + F - 1)) * R,K = 1,M = 256
- v2 策略特殊点:
2.1 低占用空间打分: Score = (K + M * (math.Log© - math.Log(A - F + 1)) / (C - A + F - 1 )) * R
2.2 高占用空间打分: Score = (K + M * math.Log© / C) * R + B * (F - A) / F
2.3 特殊情况(总空间 < 1GB 或 可用空间 >= 总空间)打分:score = R
代码实现细节:
func (s *StoreInfo) regionScoreV2(delta int64, lowSpaceRatio float64) float64 {
A := float64(s.GetAvgAvailable()) // 当前 Store 用赫尔平均计算出来准实时的 Available
C := float64(s.GetCapacity()) / gb // 当前 Store 容量,以 GB 为单位
R := float64(s.GetRegionSize() + delta) // 当前 Store 瞬时占用空间,以 Region 大小计算忽略 LSM 压缩因素
if R < 0 {
R = float64(s.GetRegionSize())
}
U := C - A // 当前 Store 已占用空间
if s.GetRegionSize() != 0 {
U = U + U*(float64(delta))/float64(s.GetRegionSize()) // 当前 Store 瞬时空间使用情况
if U < C && U > 0 {
A = C - U // “占用空间 < 容量” 且 “使用空间 > 0” 时,算出Available
}
}
var (
K, M float64 = 1, 256 // “经验值”,控制 Available 对 Region Score 权重影响
F float64 = 50 // “经验值”,防止过早耗尽磁盘
B = 1e7
)
F = math.Max(F, C*(1-lowSpaceRatio)) // 取 “参数 F ” 和 “高度空间占用分位点” 的最大值作为收敛值
var score float64
if A >= C || C < 1 {
// Available >= Store Capacity 或 Capacity < 1 G 时,Region Score == Store 瞬时占用空间
score = R
} else if A > F {
// Available > 收敛空间 F 时;
// 大量数据写入 Available 减少时, 增加 Region size 在 Region Score 中的权重;
// 理想情况下,所有节点最终收敛剩余空间于参数 F(默认 20GB);
// score = (K + M * (log总容量 - log(Available - 收敛容量 + 1)) / (Capacity - Available + 收敛空间 - 1) * 瞬时 Store Region Size
score = (K + M*(math.Log(C)-math.Log(A-F+1))/(C-A+F-1)) * R
} else {
// Available < 收敛参数 F 时;
// 当剩余空间小于参数 F 时表示, Region score 主要受Available影响;
// 当Available不足时,Region Score 会迅速增加,所有节点Available均不足时,会达到相似的分数;
// Region Score = (1 + (256 * Capacity 对数) / Capacity)* Store 瞬时空间占用 +
score = (K+M*math.Log(C)/C)*R + B*(F-A)/F
}
// 最终 Region Score 为计算所得 Score / RegionWeight
return score / math.Max(s.GetRegionWeight(), minWeight)
}
3.3 Schedule 调度实现
3.3.1 Filter 简介
展开具体代码流程前,先了解下 PD Filter 机制,Filter 主要职责是过滤掉符合不同规则的 Store。这里仅对 store-state-%s-filter 进行讲解,其他 Filter 请看 server/schedule/filter/filters.go 代码。我将 Store 简单分为外部状态、内部状态,Store 的外部可见状态简单理解如下图所示,此外,部分内部状态如 busy、exceed-remove-limit、exceed-add-limit、too-many-snapshot 等便于精细控制均衡 Region,通过 store-state-%s-filter 过滤器后,不能使用的 Store 会被排除在外避免出现 Region 少副本,性能降低等问题。

简单罗列 Filter 种类如下:
exclude-filter :排除指定的 store;
storage-threshold-filter :排除存储快慢的 Store;
distinct-filter :排除分数比自己高的 Store;
label-constraint-filter :排除不符合 label 规则的 store;
rule-fit-filter :开启 placement rules 后使用,确保隔离性,功能同 distinctScoreFilter;
rule-fit-leader-filter :开启 placement rules 后使用,transfer leader 时确保隔离性,功能同 distinctScoreFilter;
engine-filter :过滤出只保留被允许引擎的 store;
ordinary-engine-filter :过滤出只保留普通引擎的 store;
special-use-filter :过滤出特殊使用的 store,默认所有 store 均会被过滤出;
isolation-filter :对于给定隔离性,过滤出符合隔离界别的 store,如:Zone;
region-score-filter :过滤出所有 store score 高于被选定 store score 的 store;
store-state-%s-filter :过滤出以下状态中不能用于均衡 Region 的 Store;
"tombstone"
"down"
"offline"
"pause-leader"
"slow-store"
"disconnected"
"busy"
"exceed-remove-limit"
"exceed-add-limit"
"too-many-snapshot"
"too-many-pending-peer"
"reject-leader"
Panel路径:Cluster-name/PD/Scheduler:
- Filter Source: 通过 Filter 没被选为原端 Store 的原因;
- Filter Target: 通过 Filter 没被选为候选目标端 Store 的原因;

3.3.2 Scheduler 决策
追溯路径:
Start() --> runCoordinator() --> run() --> c.addScheduler() --> c.runScheduler() --> s.Schedule() --> s.Scheduler.Schedule(cacheCluster) --> Schedule()
下面详细讲解下处理流程,当检测需要处理的 Scheduler 时,Schedule() 函数处理前会通过 filter.SelectSourceStores(stores, s.filters, opts) 这个 Filter 过滤可以均衡的 Store。随后构建一个 Region 均衡计划,**该计划大致为:**首先选取一个高分 Store 、其次选取一个该 Store 的一个 Region、再选取一个目标 Store、最后在基于均衡计划构建 Operator。选取 Region 的优先原则如下:
- 随机选一个带有 PendingPeer 的 Region;
- 随机选一个带有 Follower 的 Region;
- 随机选一个带有 leader 的 Region;
- 随机选一个带有 leaner 的 Region;
- 如果被选出的 region 是 hot region ,则跳过;
- 如果被选出的 region 没有 leader ,则跳过;
代码实现细节:
func (s *balanceRegionScheduler) Schedule(cluster opt.Cluster) []*operator.Operator {
......
stores := cluster.GetStores() // 从 BasicCluster 以结构体类型数组保存所有 sotre 信息
opts := cluster.GetOpts() // 获取 PD 中持久化信息,如:pdServerConfig、schedule 等
stores = filter.SelectSourceStores(stores, s.filters, opts) // 选择 Source 端 Stores,通过
......
kind := core.NewScheduleKind(core.RegionKind, core.BySize) // 获取本次 Scheduler 的类型,leader 还是 Region,
// 以及用 Size、Count 哪个为协议标准均衡
plan := newBalancePlan(kind, cluster, opInfluence) // 开启一个均衡计划
sort.Slice(stores, func(i, j int) bool { // 在满足要求的所有 Store 中,从高到低排序 Store Score
iOp := plan.GetOpInfluence(stores[i].GetID())
jOp := plan.GetOpInfluence(stores[j].GetID())
// RegionScore 会根据所选用的策略获取当前 Region Score
return stores[i].RegionScore(opts.GetRegionScoreFormulaVersion(), opts.GetHighSpaceRatio(), opts.GetLowSpaceRatio(), iOp) >
stores[j].RegionScore(opts.GetRegionScoreFormulaVersion(), opts.GetHighSpaceRatio(), opts.GetLowSpaceRatio(), jOp)
})
......
for _, plan.source = range stores {
retryLimit := s.retryQuota.GetLimit(plan.source) // 获取当前还可 Retry 的次数,hard code 最大 10 次
for i := 0; i < retryLimit; i++ {
......
// 首先,选择 Source Store 中所选 Store,随机返回一个带有 Pending Peer 的 Region
plan.region = cluster.RandPendingRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthAllowPending(cluster), opt.ReplicatedRegion(cluster), allowBalanceEmptyRegion)
if plan.region == nil {
// 其次,选择 Source Store 中所选 Store,随机返回一个带有 follower 的 Region
plan.region = cluster.RandFollowerRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthRegion(cluster), opt.ReplicatedRegion(cluster), allowBalanceEmptyRegion)
}
if plan.region == nil {
// 然后,选择 Source Store 中所选 Store,随机返回一个带有 leader 的 Region
plan.region = cluster.RandLeaderRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthRegion(cluster), opt.ReplicatedRegion(cluster), allowBalanceEmptyRegion)
}
if plan.region == nil {
// 最后,选择 Source Store 中所选 Store,随机返回一个带有 leaner 的 Region
plan.region = cluster.RandLearnerRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthRegion(cluster), opt.ReplicatedRegion(cluster), allowBalanceEmptyRegion)
}
// 跳过当前频繁访问的 hot region,如果有打印日志并跳过,避免造成性能问题
if cluster.IsRegionHot(plan.region) {
log.Debug("region is hot", zap.String("scheduler", s.GetName()), zap.Uint64("region-id", plan.region.GetID()))
schedulerCounter.WithLabelValues(s.GetName(), "region-hot").Inc()
continue
}
// 跳过当前没有 leader 的 region,如果有打印日志并跳过,避免造成性能问题
if plan.region.GetLeader() == nil {
log.Warn("region have no leader", zap.String("scheduler", s.GetName()), zap.Uint64("region-id", plan.region.GetID()))
schedulerCounter.WithLabelValues(s.GetName(), "no-leader").Inc()
continue
}
// 正式基于 Plan 创建 Operator
if op := s.transferPeer(plan); op != nil {
s.retryQuota.ResetLimit(plan.source)
op.Counters = append(op.Counters, schedulerCounter.WithLabelValues(s.GetName(), "new-operator"))
return []*operator.Operator{op}
}
}
s.retryQuota.Attenuate(plan.source)
}
s.retryQuota.GC(stores)
return nil
}
3.3.3 Operator 生成
追溯路径:
Start() --> runCoordinator() --> run() --> c.addScheduler() --> c.runScheduler() --> s.Schedule() --> s.Scheduler.Schedule(cacheCluster) --> Schedule() --> transferPeer()
随着处理流程的深入,transferPeer 会从候选 Store List 中,选取一个最佳 Score 的 Store 去替换旧 peer,创建具体的 Operator。**值得注意:**的是 shouldBalance 函数会进行创建前的必要性检测,避免造成迁移过小或过大 Region 或均衡后分数 Store 打分反超等不必要问题,其他调度器也有该检测项,如:balance_laeder 等。
我在生产上遇到过单个节点两个 Store 存储 Region 相对较多,其他节点存储 Region 差不多开启 shuffle-region-scheduler 后,Cluster-name/PD/Scheduler/Filter-source 的 Skip 暴增的现象。
代码实现细节:
func (s *balanceRegionScheduler) transferPeer(plan *balancePlan) *operator.Operator {
// 分别初始化 ExcludedFilter、PlacementSafeguard、RegionScoreFilter、
// SpecialUseFilter、StoreStateFilter 不同过滤器
filters := []filter.Filter{
filter.NewExcludedFilter(s.GetName(), nil, plan.region.GetStoreIds()),
filter.NewPlacementSafeguard(s.GetName(), plan.cluster, plan.region, plan.source),
filter.NewRegionScoreFilter(s.GetName(), plan.source, plan.cluster.GetOpts()),
filter.NewSpecialUseFilter(s.GetName()),
&filter.StoreStateFilter{ActionScope: s.GetName(), MoveRegion: true},
}
// 候选 Store List 生成
candidates := filter.NewCandidates(plan.cluster.GetStores()).
FilterTarget(plan.cluster.GetOpts(), filters...).
Sort(filter.RegionScoreComparer(plan.cluster.GetOpts()))
// 正式开始
for _, plan.target = range candidates.Stores {
regionID := plan.region.GetID() // 选择均衡 Region ID
sourceID := plan.source.GetID() // 选择 Source Store ID
targetID := plan.target.GetID() // 选择 Target Store ID
log.Debug("", zap.Uint64("region-id", regionID), zap.Uint64("source-store", sourceID), zap.Uint64("target-store", targetID))
if !plan.shouldBalance(s.GetName()) { // 均衡必要性检查,避免迁移过小或过大 Region 或均衡后分数 Store 反超等问题
// 如果无法通过必要性检测,则跳过本次循环,不生成 MovePeerOperator
schedulerCounter.WithLabelValues(s.GetName(), "skip").Inc()
continue
}
oldPeer := plan.region.GetStorePeer(sourceID)
newPeer := &metapb.Peer{StoreId: plan.target.GetID(), Role: oldPeer.Role}
// 创建 Operator 均衡计划等待消费
op, err := operator.CreateMovePeerOperator(BalanceRegionType, plan.cluster, plan.region, operator.OpRegion, oldPeer.GetStoreId(), newPeer)
if err != nil {
schedulerCounter.WithLabelValues(s.GetName(), "create-operator-fail").Inc()
return nil
}
......
schedulerCounter.WithLabelValues(s.GetName(), "no-replacement").Inc()
return nil
}
3.3.4 Operator 消费
- Operator 的创建
追溯路径:
Start() --> runCoordinator() --> run() --> c.addScheduler() --> c.runScheduler() --> s.Schedule() --> s.Scheduler.Schedule(cacheCluster) --> Schedule() --> transferPeer() --> CreateMovePeerOperator()
通过上述追溯路径 CreateMovePeerOperator 构建 Operator 时会依据版本特性对 JointConsensus 做判断,总体来说是先加一个 peer 再删掉旧 peer 的方式在元数据层面记录修改。至于判断 JointConsensus 是因为 TiKV 在 Region 移动上有行为修正,详细可阅读 TIKV 作者之一对于 JointConsensus 的文章。
代码实现细节:
// CreateMovePeerOperator creates an operator that replaces an old peer with a new peer.
func CreateMovePeerOperator(desc string, cluster opt.Cluster, region *core.RegionInfo, kind OpKind, oldStore uint64, peer *metapb.Peer) (*Operator, error) {
return NewBuilder(desc, cluster, region).
RemovePeer(oldStore).
AddPeer(peer).
Build(kind)
}
- Operator 入队列
追溯路径:
Start(s Server) --> runCoordinator() --> run() --> patrolRegions() --> AddWaitingOperator()
大概通过上述的顺序,在 patrolRegions() 函数中起一个 for{} 无限循环,以一次处理 patrolScanRegionLimit 个 Region 的速度不断过滤出需处理的 Region 追加到 Operator 等待队列中。
- Operator 的消费
追溯路径:
Start(s Server) --> runCoordinator() --> run() --> drivePushOperator() --> PushOperators() --> Dispatch() --> SendScheduleCommand() --> SendMsg()
在 runScheduler 中起一个 for{} 无限循环监听,吊起 PushOperators() 会起一个 for{} 周期性压入 operator,并在 Dispatch()分发去 tikv 中执行以及检测执行状态;
代码实现细节:
func (oc *OperatorController) Dispatch(region *core.RegionInfo, source string) {
// 检查已存在的 Operator
if op := oc.GetOperator(region.GetID()); op != nil {
failpoint.Inject("concurrentRemoveOperator", func() {
time.Sleep(500 * time.Millisecond)
})
// 更新 Operator 状态: Stated 或 TimeOut
step := op.Check(region)
switch op.Status() {
case operator.STARTED:
......
case operator.SUCCESS:
......
case operator.TIMEOUT:
......
default:
......
}
}
}
3.4 Schedule 相关参数
- 参数 store-balance-rate :阅读源码时,会发现注释 “WARN: StoreBalanceRate is deprecated”。官网指出 store-balance-rate 4.0.2 版本之后(包括 4.0.2 版本)废弃了 store-balance-rate 参数。 该参数表示控制 TiKV 每分钟最多允许做 add peer 相关操作的次数,默认值 15,被废之后。引入 Store Limit 参数,继承 15 默认值。
- 参数 region-score-formula-version :region-score-formula-version 参数从 v5.0 版本开始引入,默认值:v2,相比于 4.0 之前 v1 空间回收引起的调度抖动得到改善,整体变化会更平滑。
- 参数 leader-weight 和 region-weight :leader-weight 和 region-weight 默认是 1,所有策略下 RegionScore 打分公式所得 Store 打分均会除以相应权重,在性能不同的 Store 上可以通过 region-weight 调整负载。
- 参数 high-space-ratio 和 low-space-ratio : high-space-ratio 仅在 v1 策略情况下生效, low-space-ratio 在 v1 和 v2 策略下均生效,主要目的是控制在 Store 快满的时候尽量减少该 Store 的数据量,增大 Store 打分。
- 参数 region-schedule-limit : region-schedule-limit 同时进行 Region 调度的任务个数,主要表示生成 Operator 的速度,具体增删 Peer 还会受到 Store Limit 消费速度的限制。
- 参数 scheduler-max-waiting-operator : scheduler-max-waiting-operator 用于控制每个调度器同时存在的 operator 的个数,默认值为 2048,对所有大小的集群都足够,不推荐自定义该参数。
- 参数 Store Limit : Store Limit 用于添加 learner/peer 和删除 peer 两种操作的速度,默认值 15,主要是 operator 的消费速度。
四、实验证明
实验环境采用 1T、16GB、8C 的 macbook pro m1 使用 tiup playground v5.2.2 --db 2 --pd 3 --kv 5 --monitor 起个 3 副本实验集群。并用如下 sysbench 语句分别灌入 6 张 sbtest 表。等待 Region Score 稳数据静止 5min 后,drop 掉其中 5 张表观察变化。v1 策略的测试使用 set config pd region-score-formula-version=‘V1’; 完成在线策略修改。
注意: 因为 tikv_gc_run_interval 和 tikv_gc_life_time 均是 10m0s 和一定的 GC 耗时,所以中间还需等待些时间才能看到变化。
sysbench /opt/homebrew/Cellar/sysbench/1.0.20_1/share/sysbench/oltp_read_write.lua \"
--mysql-host=127.0.0.1 \"
--mysql-port=4000 \"
--mysql-db=jan \"
--mysql-user=root \"
--mysql-password= \"
--table_size=5000000 \"
--tables=10 \"
--events=10000 \"
--report-interval=10 \"
--time=0 prepare
左侧为 v2 策略删除数据后曲线,右侧为 v1 策略删除数据后曲线,观察黄色选区 v2 确实在删除数据后得益于 HMA 的均线平滑特性,可以看出 Store Region Count 和 Store Region Size 均更加稳定,不会像 v1 策略一样存在一定时间的抖动。v2 很好解决了大数据量跑批测试时,经常出现的 truncate table 造成的抖动。
其次,从图中可观察出因为 Store 空间充足,无论使用 v1 还是 v2 都是用 Region Size 代表 Region Score,所以 Grafana 所示 Region Size 与 Region Score 几乎一致。
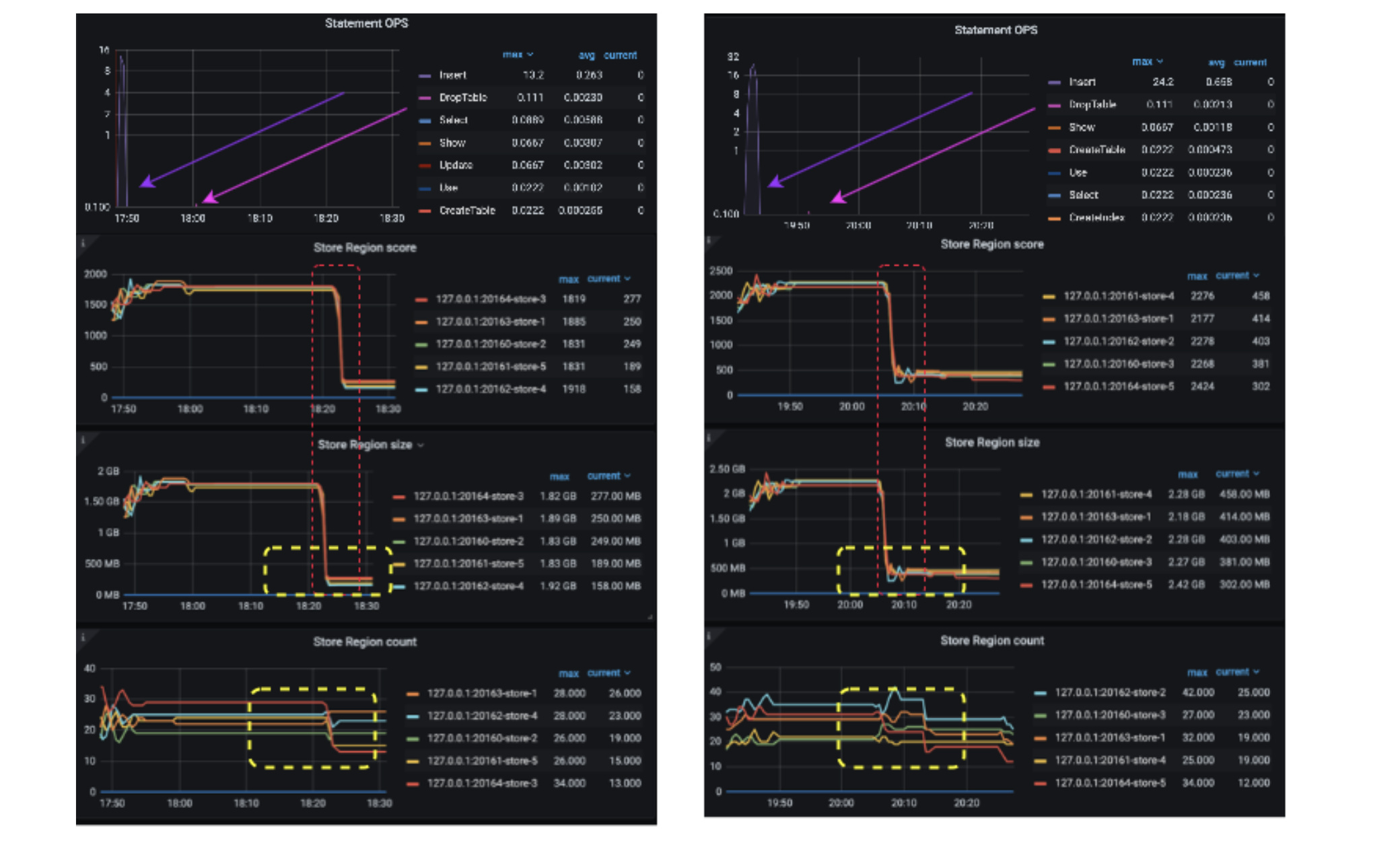
五、阅读结论
- v2 版本策略通过引入 HMA 赫尔移动均线很好解决了批量删除数据后 v1 策略引发的抖动问题。
- PD 进程拉起后,内部多个函数启动多个 for{} 不同阶段监测处理 Scheduler,通过 Scheduler 生成 Operator 入等待队列,等到相应 TiKV 的心跳消息后推到 TiKV 去执行。