

Raft 浅析
一. Raft 简介
概括成一句话:保证 log 完全相同地复制到多台服务器上。
只要每台服务器的日志相同,那么在不同服务器上的状态机以相同顺序从日志中执行相同命令,所得到的结果必然相同。
Raft 共识算法的工作就是管理这些日志。
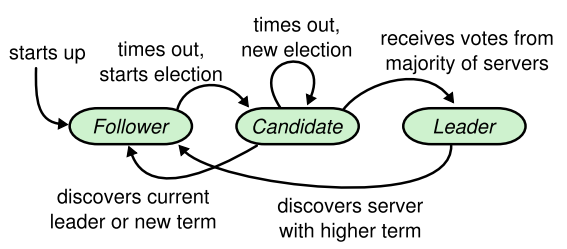
1. 角色状态
- Leader:处理所有客户端请求、日志复制。同一时刻最多只能有一个可行的 Leader;
- Follower:完全被动的(不发送 RPC,只响应收到的 RPC)——大多数服务器在大多数情况下处于此状态;
- Candidate:用来选举新的 Leader,处于 Leader 和 Follower 之间的暂时状态;
系统正常运行时,只有一个 Leader,其余都是 Followers。
状态转换化图:
2. 任期
时间被划分成一个个的任期(Term),每个任期都由一个数字来表示任期号,任期号单调递增并且永远不会重复。
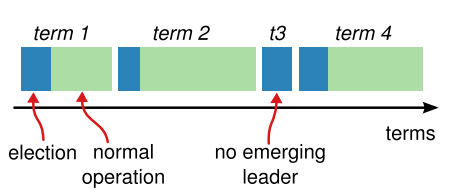
一个正常的任期至少有一个 Leader,通常分为两部分:
- 任期开始时的选举过程;
- 正常运行的部分;
有些任期可能没有选出 Leader(如图 Term 3),这时候会立即进入下一个任期,再次尝试选出一个 Leader。
每个节点维护一个currentTerm变量,表示系统中当前任期。currentTerm必须持久化存储,以便在服务器宕机重启时将其恢复。
任期能够帮助 Raft 识别过期的信息。例如:如果currentTerm = 2的节点与currentTerm = 3的节点通信,我们可以知道第一个节点上的信息是过时的。只会使用最新任期的信息。
3. RPC
Raft 中服务器之间所有类型的通信通过两个 RPC 调用:
- RequestVote:用于选举;
- AppendEntries:用于复制 log 和发送心跳;
二. Leader 选举
1. 启动
-
节点启动时,都是 Follower 状态;
-
Follower 被动地接受 Leader 或 Candidate 的 RPC;
-
如果 Leader 想要保持权威,必须向集群中的其它节点发送心跳包(空的AppendEntries RPC);
-
等待选举超时(electionTimeout,一般在 100~500ms)后,Follower 没有收到任何 RPC:
- Follower 认为集群中没有 Leader
- 开始新的一轮选举
2. 选举
当一个节点开始竞选:
-
增加自己的currentTerm
-
转为 Candidate 状态,其目标是获取超过半数节点的选票,让自己成为 Leader
-
先给自己投一票
-
并行地向集群中其它节点发送RequestVote RPC索要选票,如果没有收到指定节点的响应,它会反复尝试,直到发生以下三种情况之一:
- 获得超过半数的选票:成为 Leader,并向其它节点发送AppendEntries心跳;
- 收到来自 Leader 的 RPC:转为 Follower;
- 其它两种情况都没发生,没人能够获胜(electionTimeout已过):增加currentTerm,开始新一轮选举;
3. 图例说明
3.1. 节点均正常
- 开始启动,节点都是 Follower 状态:

- s4 先到达选举超时时间成为candidate,当前任期currentTerm从1变为为2,并向其他节点发起RequestVote RPC请求
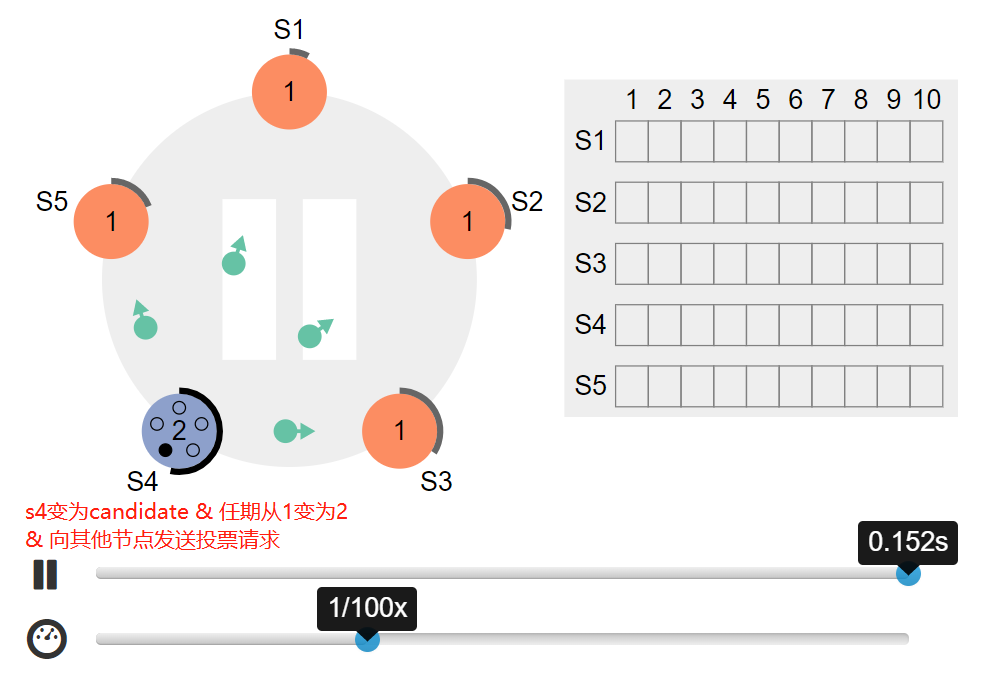
- 其他节点收到 s4 的投票请求后,投出赞同票(其他节点在收到 S4 的投票前都没有出现选举超时的情况)

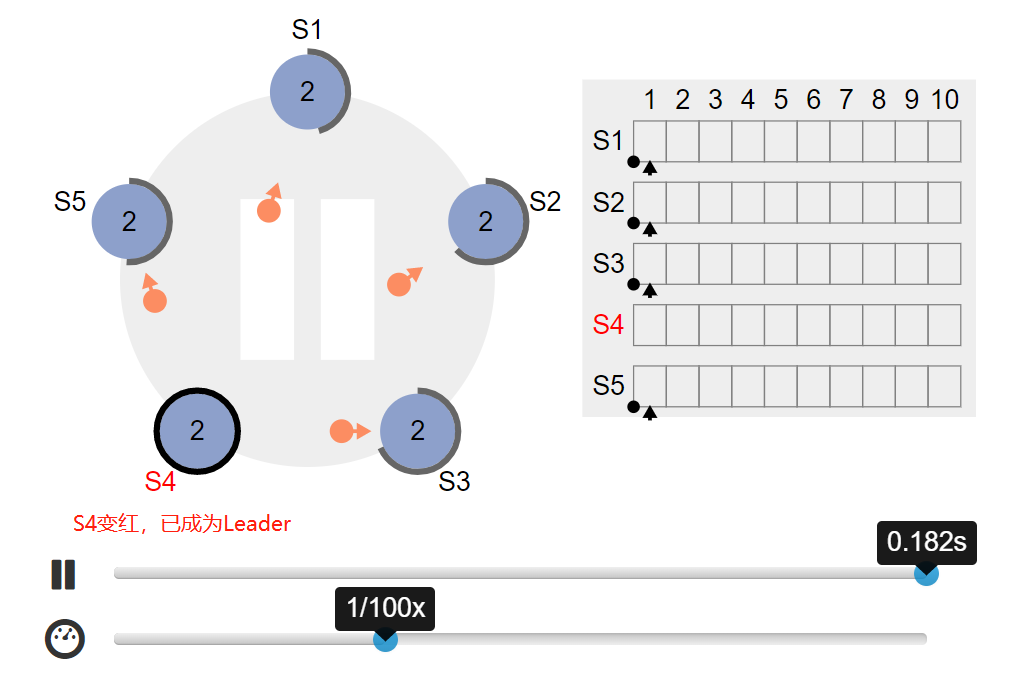
- s4 成为 Leader,并开始向其他节点发送心跳包:
3.2. Leader 节点故障
再来看下 Leader 节点故障了,剩下四个节点参与选举。
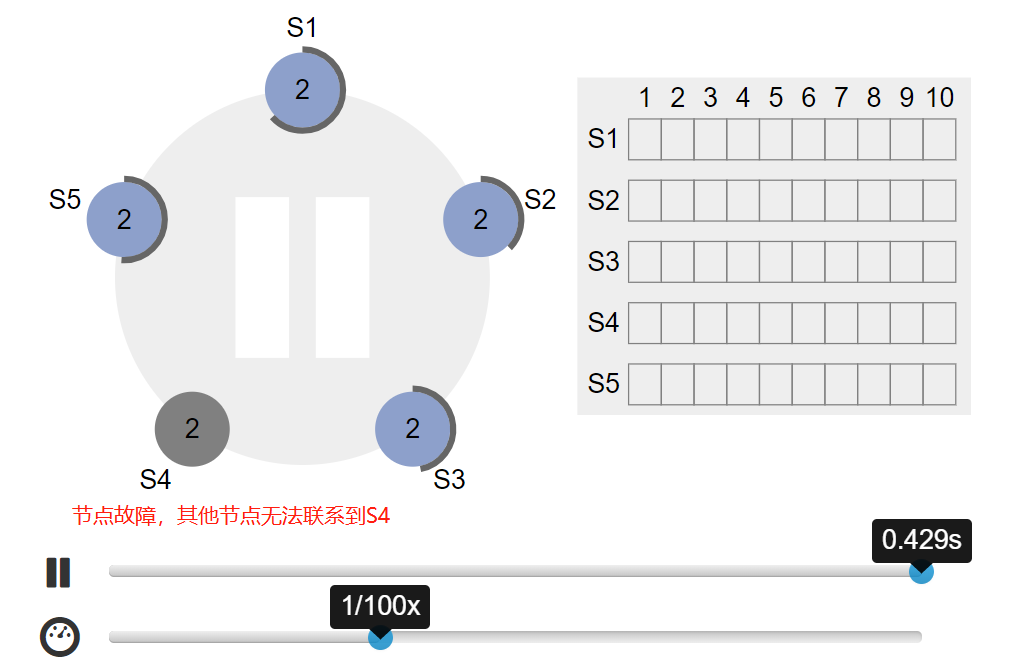
- s4 故障,其他 follower 节点选举超时:
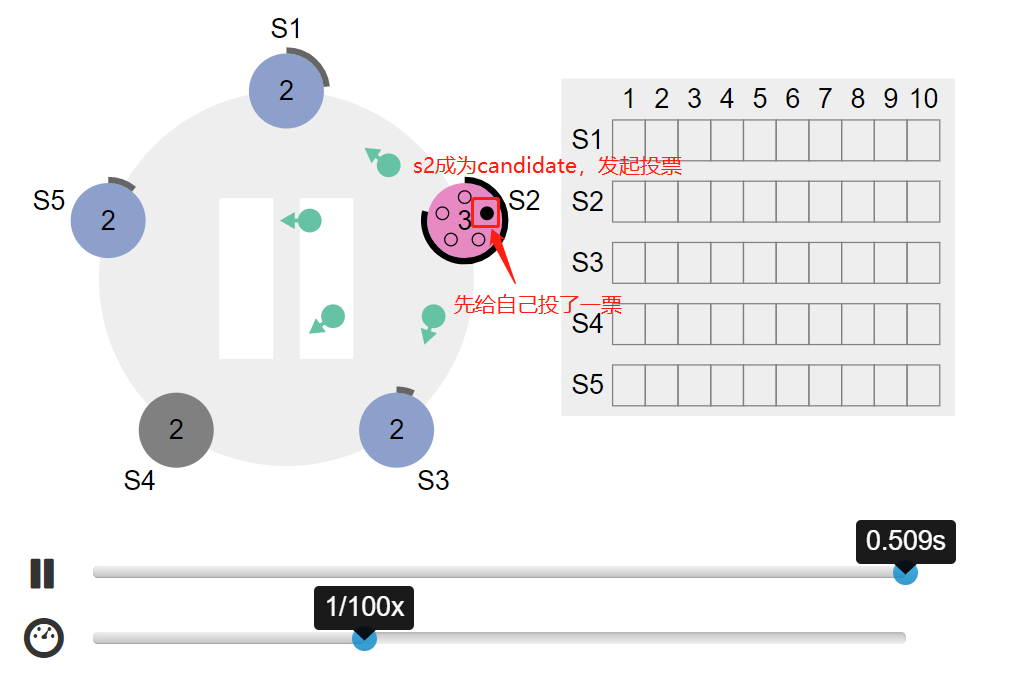
- s2 达到选举超时时间,变为 candidate,任期从2变为3,给自己投一票,并发起投票请求:
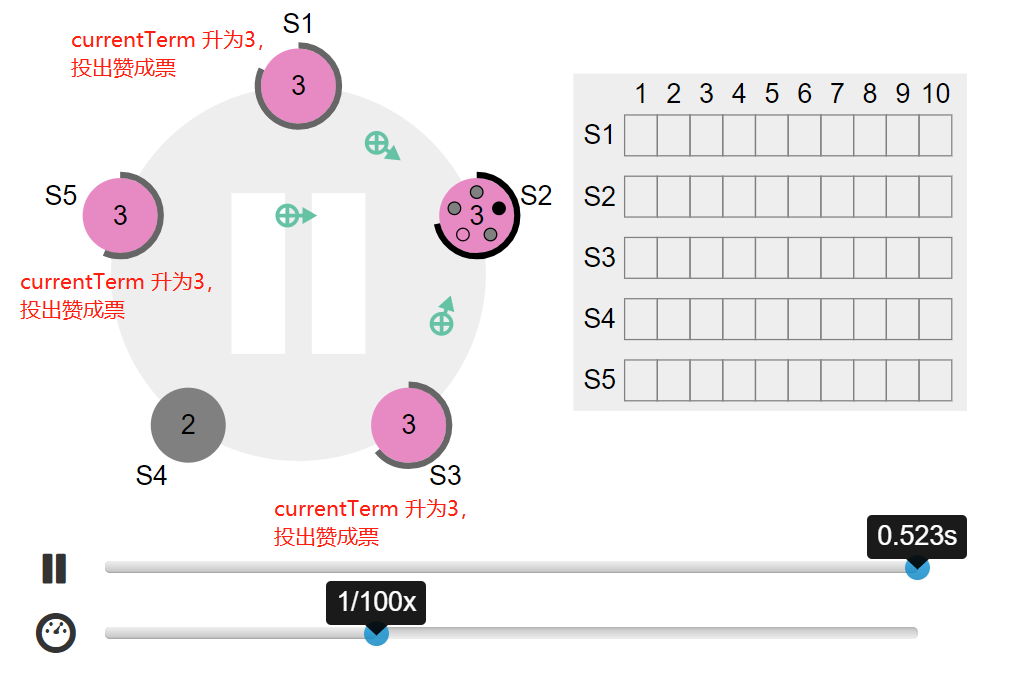
- s1,s3,s5 的 currentTerm 都是2,收到 s2 的请求后发现 s3 的 currentTerm 是3,于是把自己的 currentTerm 升为3,并投出赞成票:
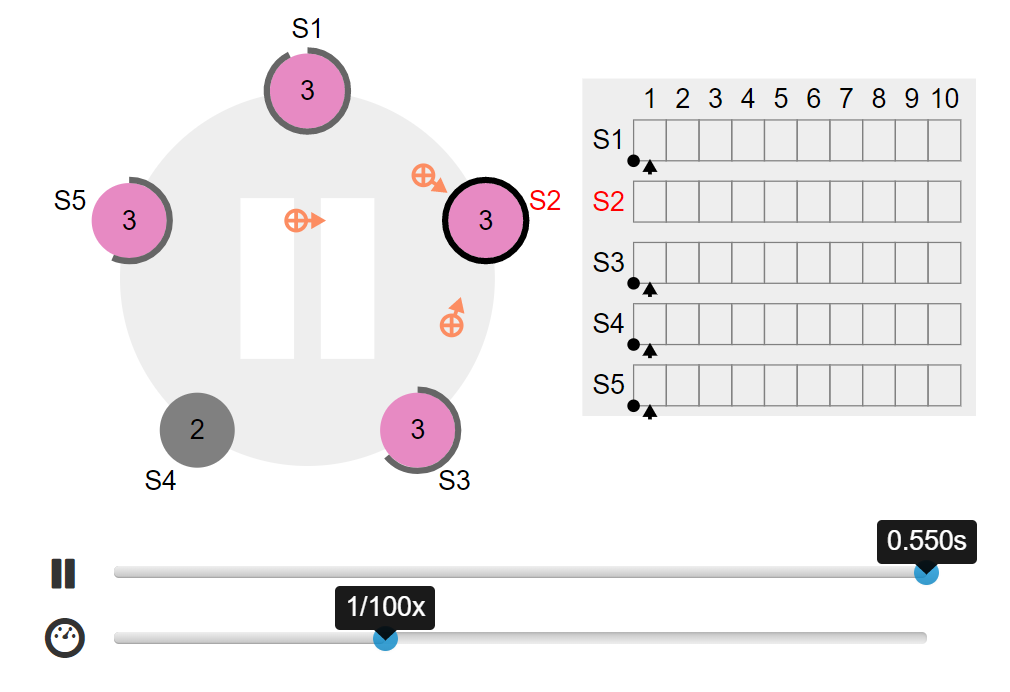
- s2 成为 leader 发心跳包,其他 follower 节点回包:
三. 日志复制
1. 日志结构
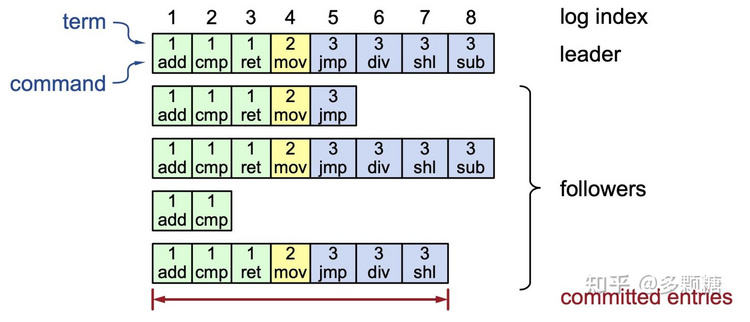
每个节点存储自己的日志副本(log[]),每条日志记录包含:
- 索引:该记录在日志中的位置
- 任期号:该记录首次被创建时的任期号
- 命令
日志必须持久化存储。一个节点必须先将记录安全写到磁盘,才能向系统中其他节点返回响应。
如果一条日志记录被存储在超过半数的节点上,我们认为该记录已提交(committed)——这是 Raft 非常重要的特性!如果一条记录已提交,意味着状态机可以安全地执行该记录。
2. 运行流程
-
客户端向 Leader 发送命令,希望该命令被所有状态机执行;
-
Leader 先将该命令追加到自己的日志中;
-
Leader 并行地向其它节点发送AppendEntries RPC,等待响应;
-
收到超过半数节点的响应,则认为新的日志记录是被提交的:
- Leader 将命令传给自己的状态机,然后向客户端返回响应
- 此外,一旦 Leader 知道一条记录被提交了,将在后续的AppendEntries RPC中通知已经提交记录的 Followers
- Follower 将已提交的命令传给自己的状态机
-
如果 Follower 宕机/超时:Leader 将反复尝试发送 RPC;
-
性能优化:Leader 不必等待每个 Follower 做出响应,只需要超过半数的成功响应(确保日志记录已经存储在超过半数的节点上),一个很慢的节点不会使系统变慢,因为 Leader 不必等他;
3. 日志一致性
Raft 尝试在集群中保持日志较高的一致性。
Raft 日志的 index 和 term 唯一标示一条日志记录。
- 如果两个节点的日志在相同的索引位置上的任期号相同,则认为他们具有一样的命令;从头到这个索引位置之间的日志完全相同;
- 如果给定的记录已提交,那么所有前面的记录也已提交;
4. 图解
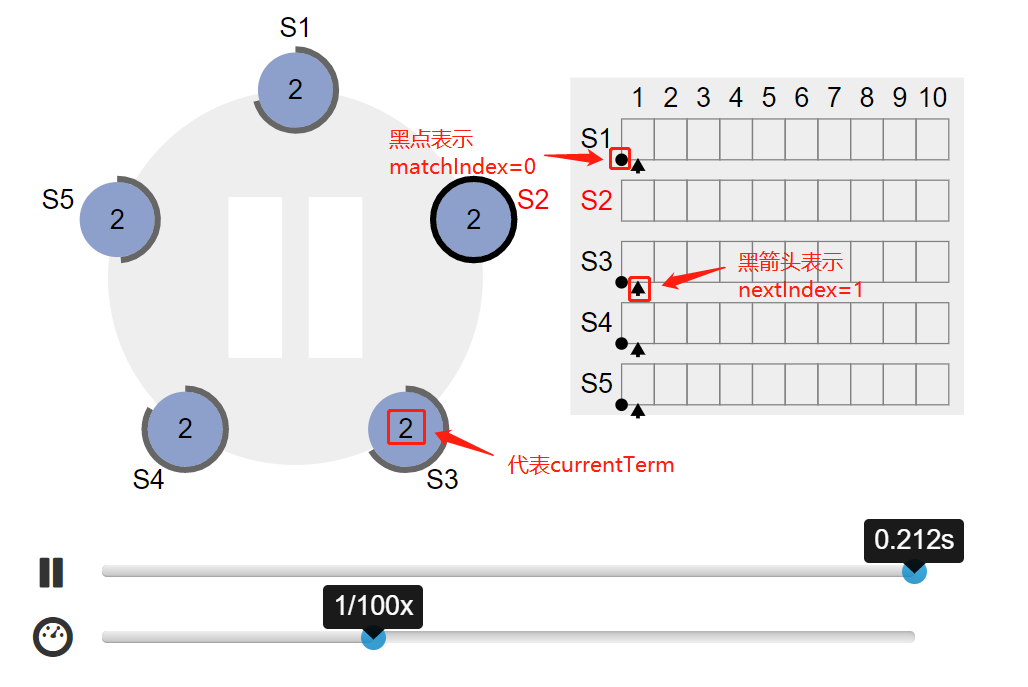
4.1. 选举结束,s2 成为 leader,当前 currentTerm 为2,follow 节点的 matchIndex=0,nextIndex=1,commitIndex=0,lastApplied=0:
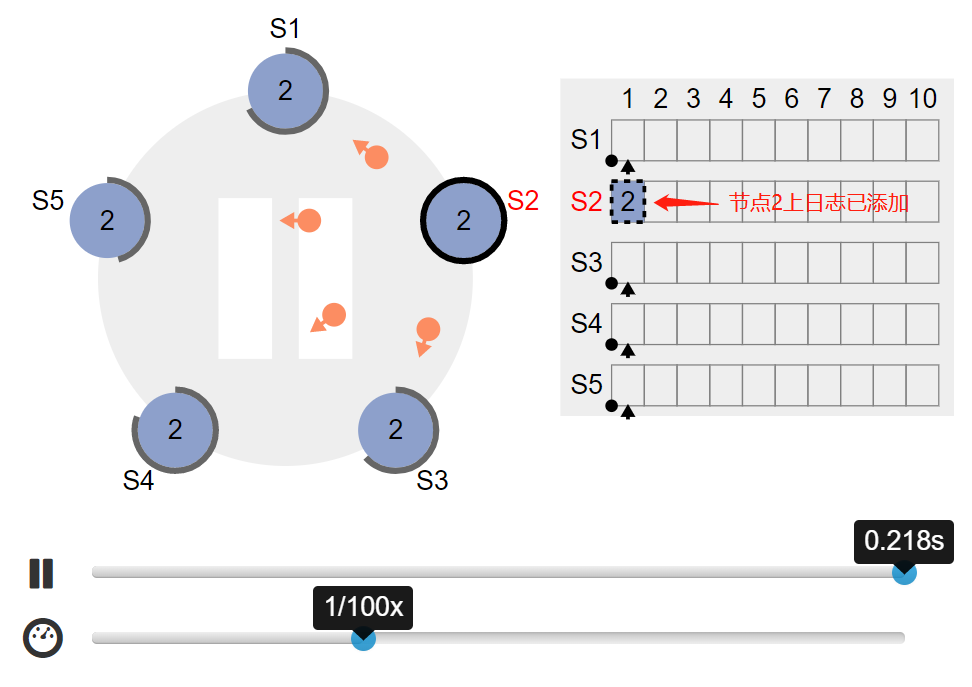
4.2. leader 节点 s2 接收到客户端请求,将命令封装成日志,然后在该节点添加日志记录,并将复制日志请求发给其他 follower:
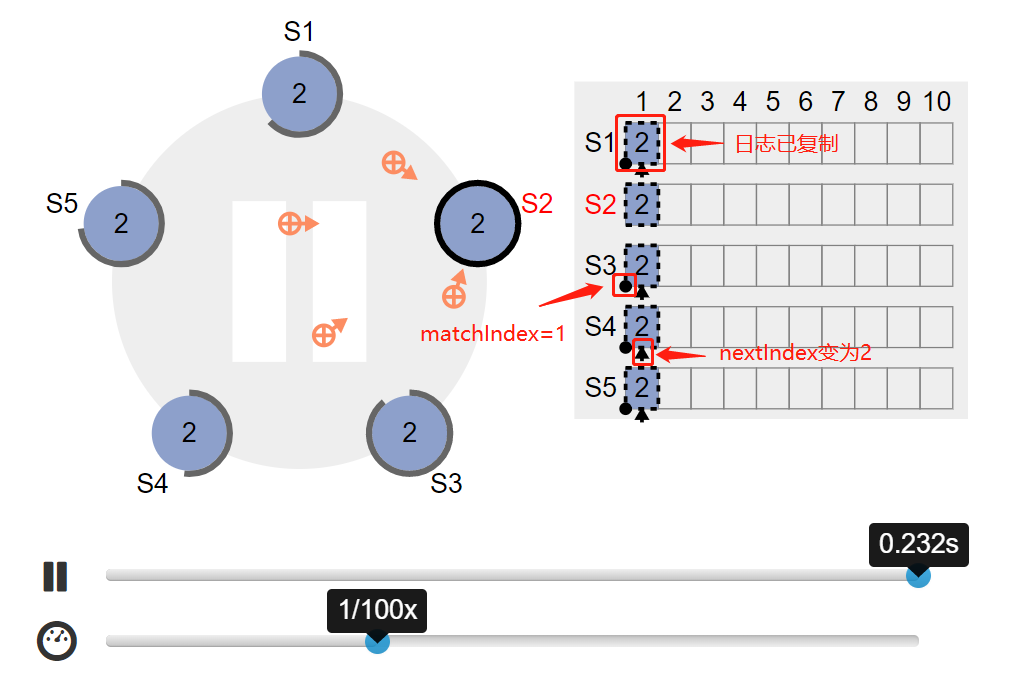
4.3. 所有 follower 接收日志完成复制工作,这些节点的 matchIndex变为1,nextIndex变为2:
4.4. leader 确认提交,并告知所有 follower:
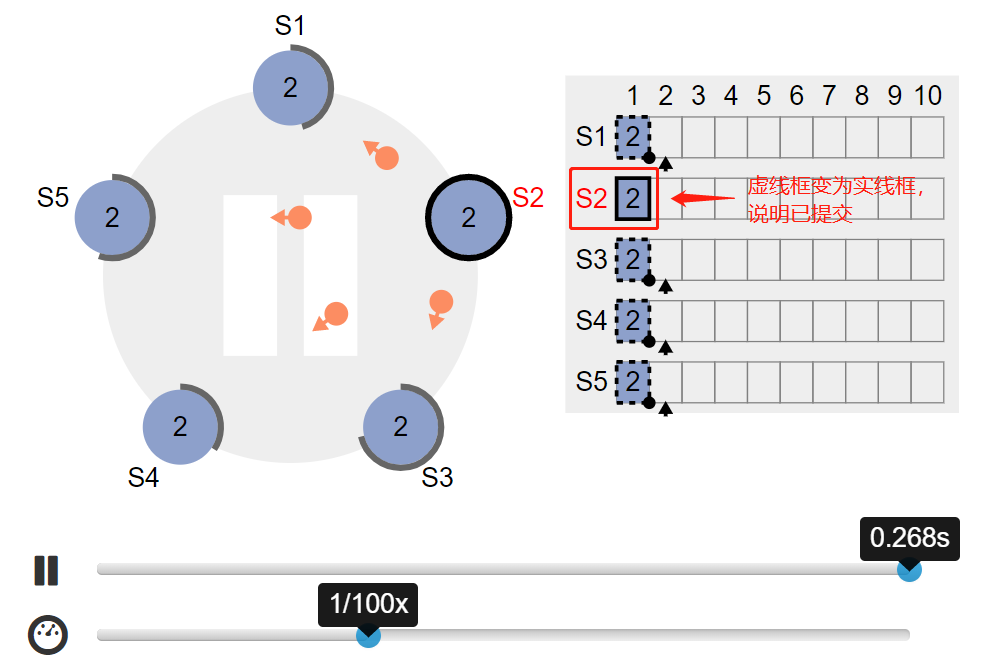
此时 leader 的 commitIndex 为 1:
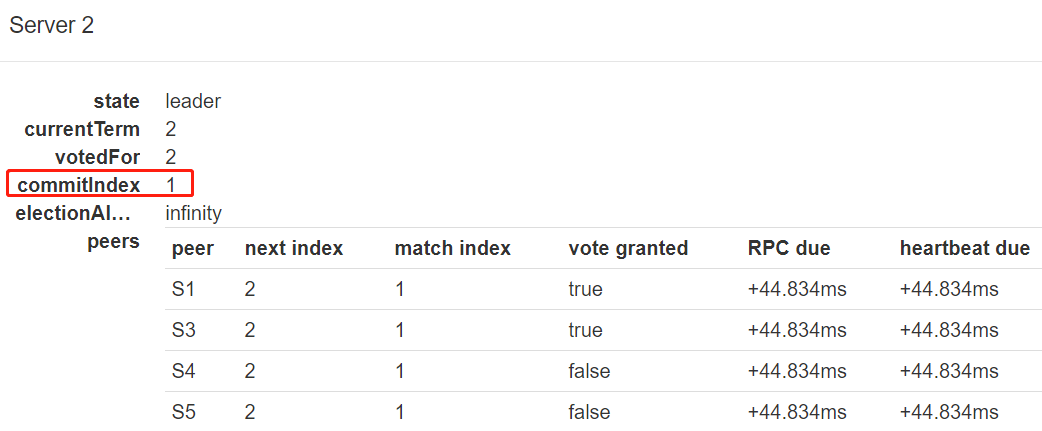
而 follower 的 commitIndex 为 0:
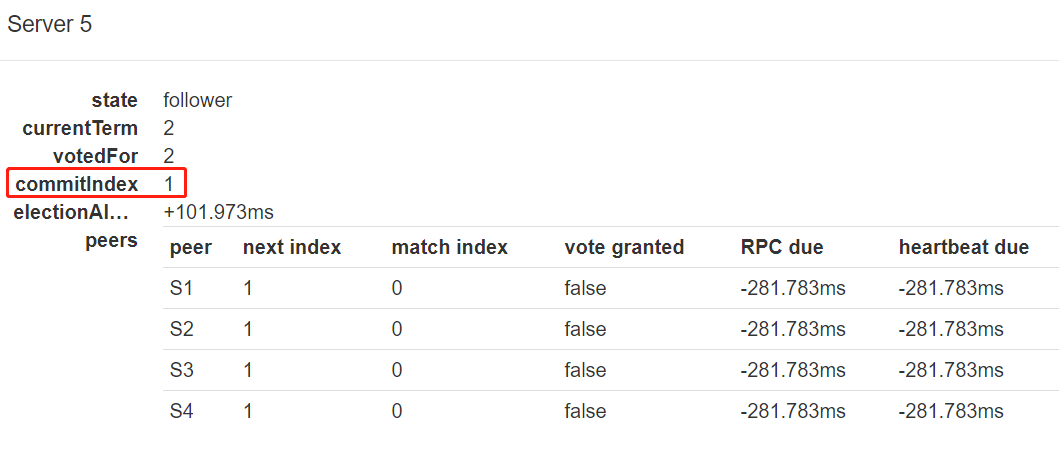
4.5. 所有 follower 收到 leader 提交的请求,修改 commitIndex,表示已处于已提交状态:

此时可以看到 follower 的 commitIndex 变成 1:
5. 一致性检查
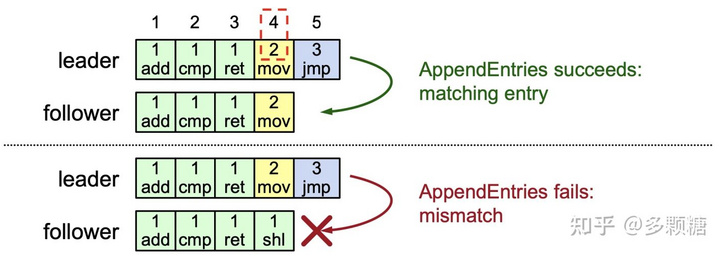
Raft 通过 AppendEntries RPC 来检测。
- 对于每个
AppendEntriesRPC包含新日志记录之前那条记录的索引(prevLogIndex)和任期(prevLogTerm); - Follower 检查自己的 index 和 term 是否与
prevLogIndex和prevLogTerm匹配,匹配则接收该记录;否则拒绝;
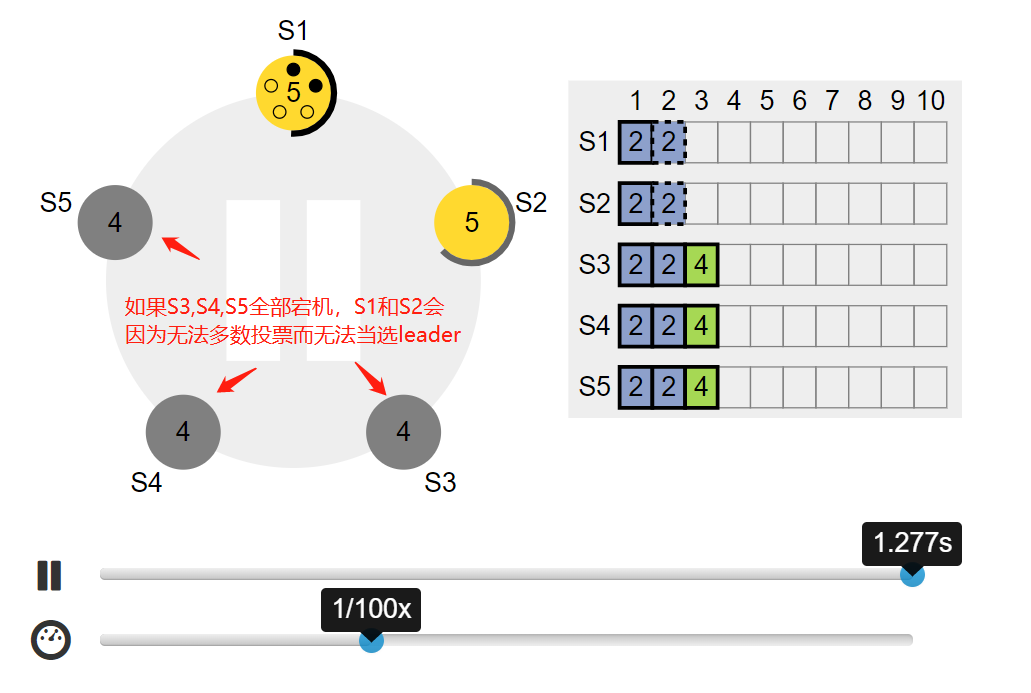
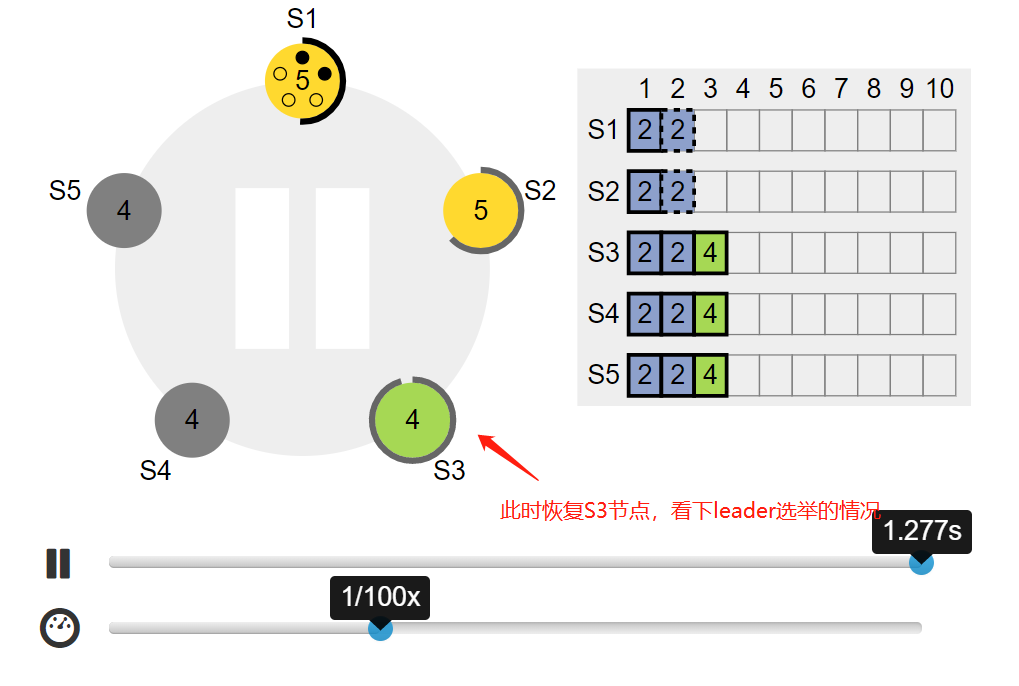
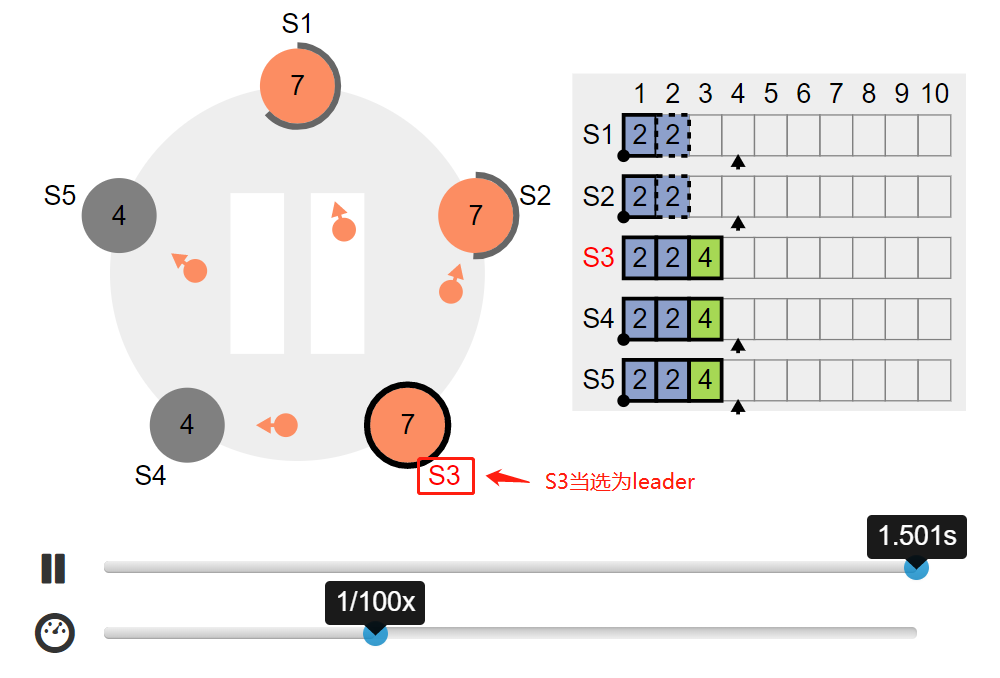
四. Leader 当选条件
leader 的竞选资格:拥有最新的已提交的log entry的Follower才有资格成为Leader。

五. Raft 与 Multi-Paxos
MySQL 8.0 MGR 实现数据一致性用的是 Paxos 算法,两者其实都是基于 leader 的一致性算法。
Raft 与 Multi-Paxos 中的概念:
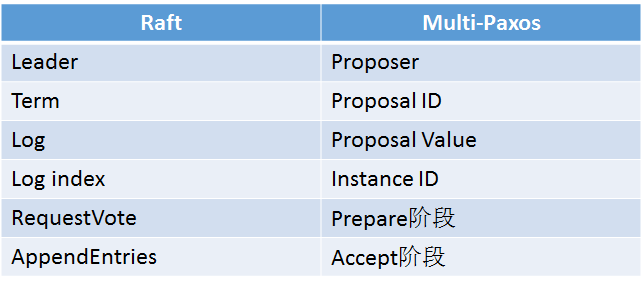
Raft 与 Multi-Paxos 的不同点:

六. 总结
Raft 还有许多功能点比如它的日志压缩、客户端交互等值得深入学习,这边就不一一去研究了。接下来还是把更多的时间放在 TiDB 原理的研究和使用测试上。
最好的 Raft 参考文档:
Raft 论文:https://raft.github.io/raft.pdf
Raft 中文版:https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md#51-raft-基础
条分缕析 Raft 算法:https://segmentfault.com/a/1190000039264427