

前言
记录一次低版本 TiDB bug,以及处理问题的心路历程
发现问题
早上准备出门,有业务方给我打电话,说业务有报错,pd 无法连接,当时我心里一惊这么明显的报错不会是 pd 都挂了吧
我立刻从厕所跑出来,打开电脑,发现我们数据库的延迟非常的高,可以看到如下图所示
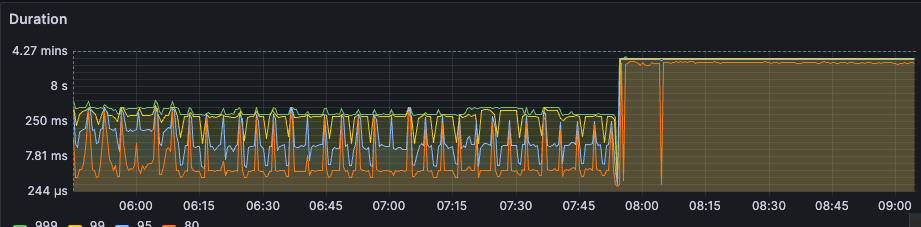
当时数据库的状态是这样的,画外音:我的心是拔凉拔凉的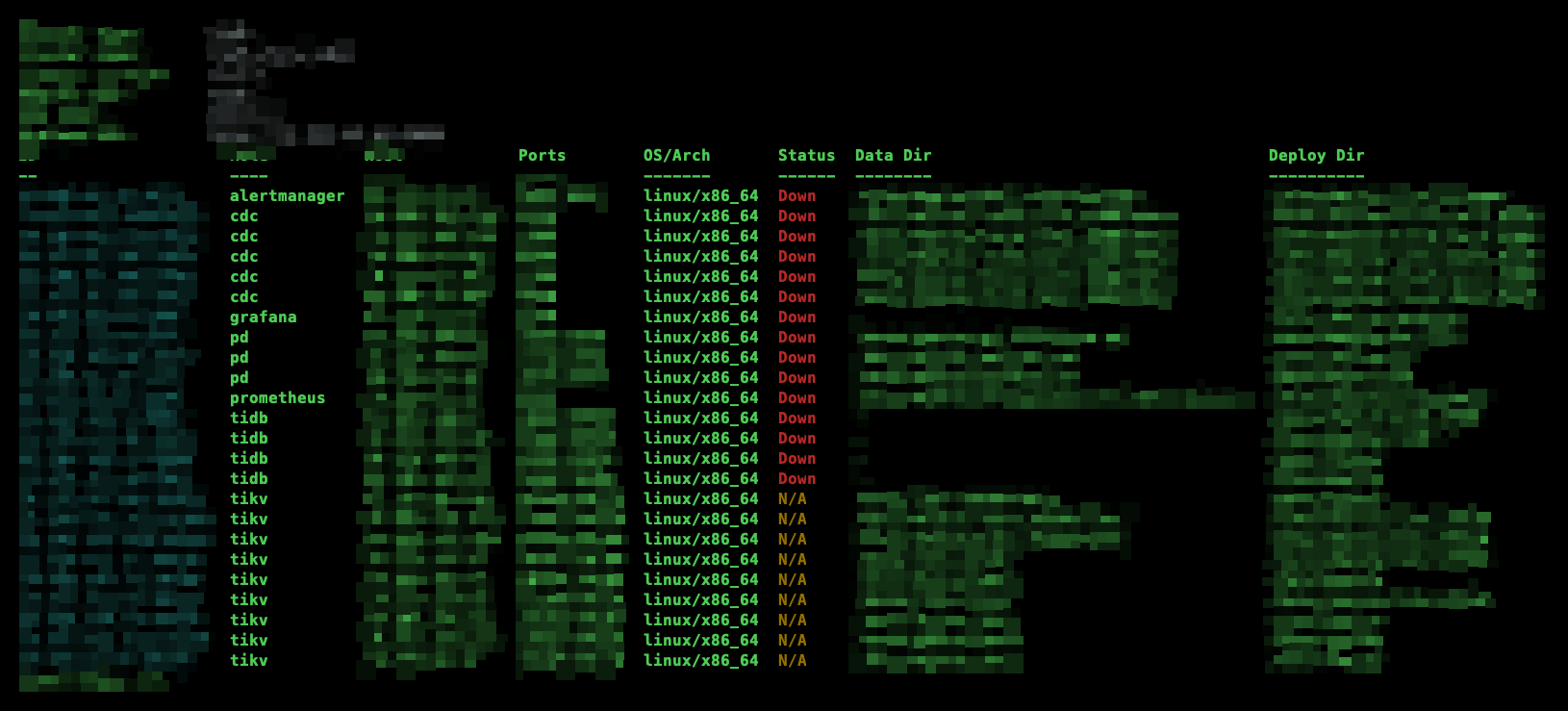
尝试修复(未果)
于是我尝试重启 TiDB 集群,但是也没有启动成功,如下图:

定位问题
看到了 space exceeded 这个报错以后,我的第一反应是不是磁盘空间满了导致了space的这个报错?因为熟悉 Linux 的同学都会知道,报错包含了 space 这个关键字,基本上就是和空间有关系了,于是我检查了所有 pd 的磁盘空间,发现这些空间基本上都用了 50% 左右,所以不是磁盘空间的问题,接着我拿着这个报错,去 TiDB 的官方文档上搜了一下,发现了如下的线索

这个集群的数据库版本是 V5.1.1 的版本,也是官方建议到的 V4.0.9 以后的一个版本,但是也是复现出了同一个问题, 那么我的第一反应是:TiDB 在低版本并未修复的一个bug
就此补充一个背景,原数据库集群是 v5.1.1 的版本,一直跑了很多年都没有问题,直到我们上周接入了 TiCDC 的组件, 并对表进行了复制与同步, 我们第一天的下午调整了 GC 时间,为 72 小时, 17 个小时之后忽然整个集群就挂了,
ok,背景介绍完毕,我们再回到这次故障,从监控我们可以看到在 8:00 左右的时候,etcd 的使用率直接飙到了 8.59G 和这个参数设置的最大值是保持一致的
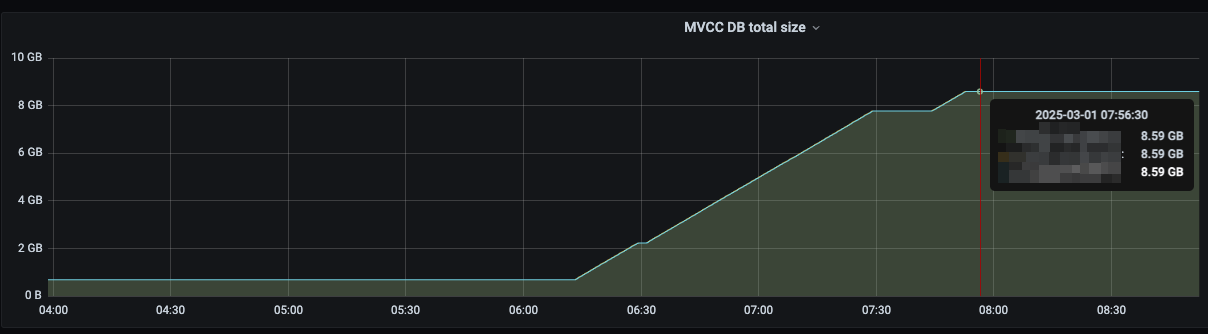
于是我登录到 pd 组件的家目录,去查数据库的在文件中的大小,于是发现了他确实满了 画外音: 这个 etcd 的大小受 quota-backend-bytes 参数的控制(不过,原厂不建议修改)

https://docs.pingcap.com/zh/tidb/stable/pd-configuration-file/#quota-backend-bytes

解决问题
基本定位了问题,下面就是如何解决,对于 etcd 来说,作为 dba 处理这样的问题的机会不是很多,关于 etcd 的处理方法,并不在 tidb 的官方文档上,而是连接到了 etcd 的一个连接上
而 etcd 是整个 pd 的核心组件,对这个组件的调整还是需要和原厂工程师沟通一下的,因为我比较担心调整参数后组件无法启动。 画外音: etcd 的文档就像一个大的故障合集,里面告诉了你各种问题的处理方法,这里吹一波 tidb 的文档建设,故障分类确实很细致。
因为当时是个周六的早上,原厂同学接到了电话后还可以听见打哈欠的声音,但是我说明了问题以及定位了问题之后,社区支持的同学响应速度是非常快的,一起拉起周六的开发值班人员支持我们的线上紧急 case
我们的第一次尝试是,是否可以去扩大 quota-backend-bytes,也就是给 etcd 扩容,我们尝试由 8 G 扩展到了 16G,又由 16G 扩展到了 64G, 这两次调整都没有有启动成功,我们的操作步骤是在 tiup edit-config 中调整大小后,虽然在启动 pd 节点时都可以看到配置生效,但登录到 pd 节点上单独启动 pd 服务时 (systemctl start pd-2379) 还是有相同的 mvcc 报错 画外音:此次故障处理有个收获,如果 pd 全挂就登录到 pd 做在的主机上一台一台启,先让他选出一个 leader,后续的 follower 再逐步加入集群,这样可以拆分启动步骤,逐步定位问题
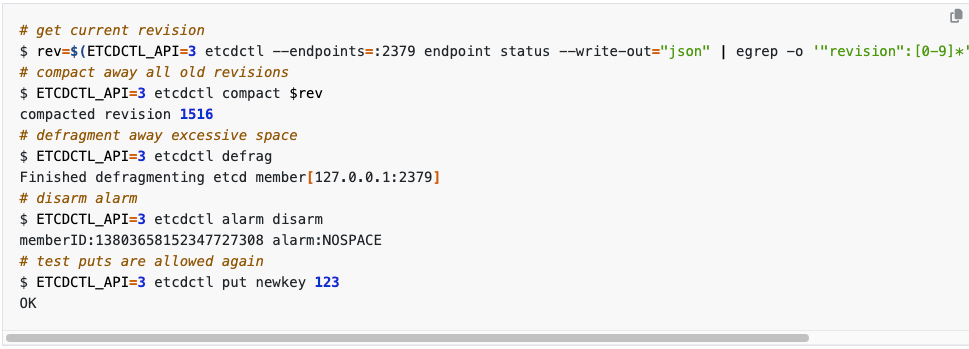
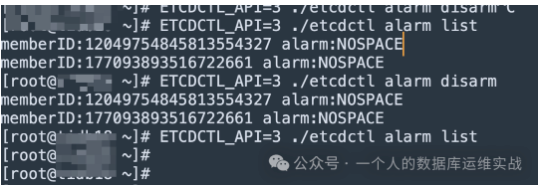
调整 etcd 无果后,我们把目光去转向到了处理 etcd,想办法对他进行压缩或者碎片整理, 通过 etcd 网站给出的线索,我们需要使用 etcdctl 这个组件,先做 defrag (碎片整理),在做 etcd alarm clear (报警清除) 画外音:虽然这两条命令非常简单,但是故障处理时,还是浪费了不少时间 etcdctl 这个工具在: /home/tidb/.tiup/components/ctl/v5.1.1/
使用 tiup ctl:v7.5.5 etcd --endpoints=xxx version 也可以调用 etcd 这个命令
下面是我们处理的详细步骤
# 要把我们的 pd 节点停下来
systemctl stop pd-2379
# 检查 etcd 的大小,以便对比
ls -lrt {pd_datadir}/member/snap/db
# 从中控机上拷贝 etcdctl 到目标端
scp /home/tidb/.tiup/components/ctl/v5.1.1/etcdctl xxxx@1.1.1.1:/home/tidb/ (假设我们拷贝到了这个目录)
# 整理 etcd 碎片
ETCDCTL_API=3 ./etcdctl defrag --data-dir {pd的数据目录}
# 清理 etcd alarm (这点非常重要如果报警还存在的话,那么ET CD也无法正常工作)
ETCDCTL_API=3 ./etcdctl alarm disarm
# 修改ETC地址数据库的权限
chown tidb.tidb {pd_datadir}/member/snap/db
# 启动 PD 节点
systemctl start pd-2379
# 对剩下的 2 个 pd 重复上面的操作
经过一系列操作之后, pd 也终于可以正常的拉起那么随之而来的是数据库也恢复了正常
总结
etcd 也是一个分布式键值存储数据库,其内部也会有多版本并发控制(即:MVCC),而 ticdc 会实时的记录对数据变更时的 tso 等信息,这部分信息会记录到 etcd 中,当遇到洪峰流量时 etcd 会造成大量的 mvcc 的版本信息,虽然 etcd 会每小时清理一次碎片,但是当洪峰流量到达时,etcd 则来不及进行碎片回收,这个情况在 v5.4 得到了改善,但这个 feature 真正得到改善是在 6.5 以后
一、 经过次事件,我们增加了 etcd 的监控,etcd 默认值是 8GB, 我的监控策略是 4G 发送 oms 报警,6G 直接打电话来避免相应问题的发生
二、 同时还要加强对 duration 的监控,因为当数据库不可用时(无论是 TiDB bug 还是业务侧的 SQL),这个值一定会升高,那么我们的策略有两个策略,第一个策略:限制固定的阈值,比如说固定阈值根据业务线优先级不得超过X秒,第二个策略:还要增加24小时之前的环比,如24小时之前搜索想要时间为500毫秒,那么此时如果响应超过了 1秒则进行报警(这个有可能就是业务突增了),重点监控参数: tidb_server_handle_query_duration_seconds_bucket
三、最后还有一个使用 ticdc 分享,在同步大批量数据时,尽量使用蚂蚁搬家的方式按照批次进行,比如说我有一个 1T 的数据库,那么按照规划的大小 100G 一个批次,划分 10 批,这样做的好处是业务可控,有问题能及时处理