

【是否原创】是
【首发渠道】TiDB 社区
【目录】
【正文】
一、引言
大家都知道 TiDB 几乎完全兼容了 MySQL 协议。一方面,是连接协议方面的兼容,简单点说,也就是支持 MySQL 连接的客户端工具都能连接到 TiDB Server。另一方面,TiDB 也支持了MySQL的绝大部分语法。
Parser 模块在整个 TiDB 生态中担任 SQL 解析的任务。TiDB 兼容 MySQL 也有赖于 Parser 对使用 MySQL 语法构造出的 SQL 语句的解析。这篇文章会首先简单聊一下 Parser 解析中比较重要的词法解析与语法解析两个过程。然后说说如何修改Parser 模块以兼容新的关键字,这也算是理解 Parser 模块的原理之后的一点实践。
二、词法解析与语法解析简介
我们这里拿一句 SQL 举例看一下 Parser 模块词法分析的大致过程。例如:“SELECT * FROM employee WHERE id = 1”。那么在词法分析过程中,会从左向右去读整个字符串,每读到一个单词就提取出来。这里具体来说,我们讲读到这些单词:“SELECT”、“*”、“FROM”、
“employee”、“WHERE”、“id”、“=”、“1”。现在可以用标准一点的叫法,称这些单词为 Token。这些 Token 又可以分为两种。一种是“SELECT”,“FROM”这种SQL语法规定的单词,也叫做关键词。另一种是“employee”,“id”用户自定义的Token。我们编写规则文件,赋予这些Token不同的意义,比如关键词、字符、数字、运算符等。当扫描对应的字符串时,就会返回对应的Token给我们。
继续说语法分析的过程。在经过词法分析后,我们就获得了一堆Token,而且我们也都知道这些Token的意义,因为是我们自己定义的,下面就是将他们组装成一句话,看看这句话到底什么意思,他到底想要我们干什么,简单的说,我们要开始寻找主谓宾,“SELECT” 代表他是一个查询语句,“FROM” 后面需要接表名,从那张表中查询,“WHERE” 后面接限定条件,这些都是我们赋予这些短语的含义,一句查询 SQL 的结构需要有哪些 Token ,他们的顺序如何,这都是我们接下来需要定义的规则了,通过这个规则来解读这些 Token,并形成有对应含义的结构供我们使用,也就是语法分析的过程。
对于词法分析和语法分析有所了解后,我们其实就可以总结一下这个过程是什么,往简单的地方说就是定义规则,定义Token,然后定义Token的组合方式,很简单,有了这些规则,我们就可以去创建各种语言了。接下来,我们需要有东西帮我们去解析,依赖这些规则帮我们解析成我们能接受的样子,到程序中,也就是需要有东西依靠我们定义的规则解析一个字符串,解析成我们在程序中可以使用与辨别的形式,这个形式就是语法树,也就是开始讲的抽象语法树,而这个帮我们解析的东西也就叫词法分析器和语法分析器。
说到词法分析器和语法分析器,我们就要到程序中去实现,这个过程非常复杂,毕竟一种语言,必定涉及到各种Token 和 组合规则,语言有多复杂,规则就有多么复杂,这个时候就需要一个工具去帮我们生成分析器,这里就要介绍一个工具了 Lex & Yacc: The LEX & YACC Page (compilertools.net)
直接看Lex&Yacc 也是非常硬核的一件事(大部分人可能点进去后又退了出来),这个不适合我们新手来学习,所以我们知道他是帮我们生成分析器的工具就好了,后面在具体代码中会讲到这个过程。我们看张图简单的理解下:
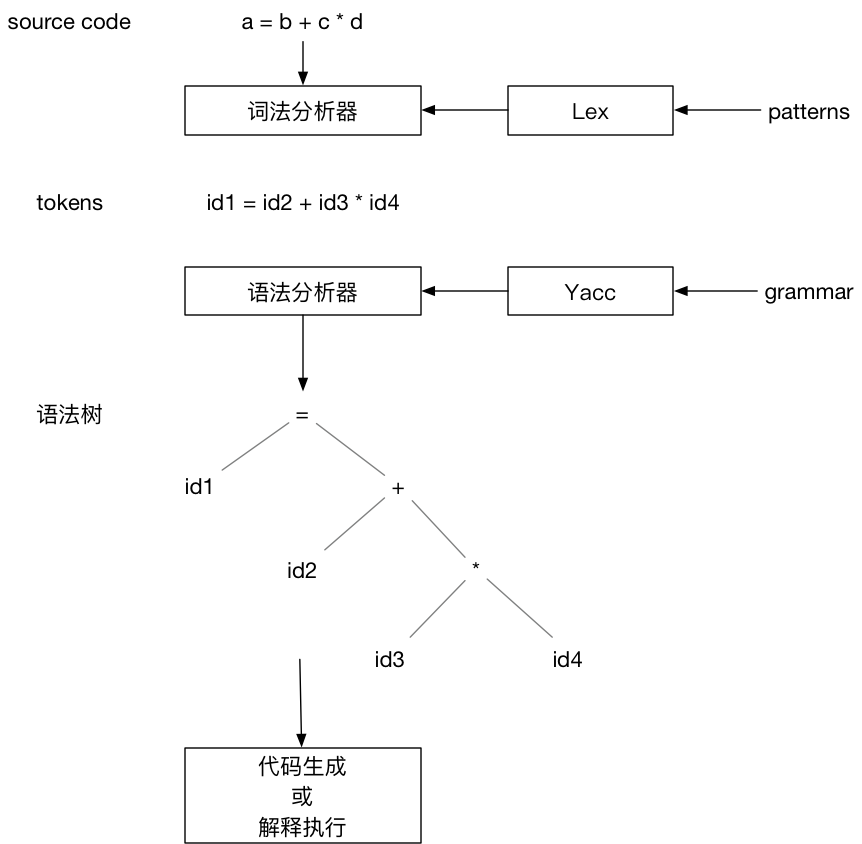
最右边的这个Patterns和Grammar就是我们定义的词法规则和语法规则了,重点,下面问题来了,具体我们要怎么去定义这个规则呢?看下面这个形式(lex 和 yacc 的规则定义格式相同)
... definitions ...
%%
... rules ...
%%
... subroutines ...
通过%%分为三个部分,最上面是定义的名称,例如各种Token,表达式啥的,中间是规则,也就是重点关注的位置,这部分在词法和语法中都非常的重要,官方文档中提供的例子我们看看,先看下Lex的配置文件:
... definitions ...
%%
/* 变量 */
[a-z] {
yylval = *yytext - 'a';
return VARIABLE;
}
/* 整数 */
[0-9]+ {
yylval = atoi(yytext);
return INTEGER;
}
/* 操作符 */
[-+()=/*\"n] { return *yytext; }
/* 跳过空格 */
[ \"t] ;
/* 其他格式报错 */
. yyerror("invalid character");
%%
... subroutines ...
这个是词法中的规则,看的就很直接,左边定义了扫出的字符串内容,利用正则,如果字符串匹配左边的正则,则进行右边的大括号中的程序运行,比如整数那里,如果匹配了,就会将扫描出来的字符串整体作为一个 INTEGER Token 来返回, 我们就相当于获取了一个整数的Token。第三个部分是空的,我们暂时不用管。
下面继续看一看Yacc配置文件的例子:
%token INTEGER VARIABLE
%left '+' '-'
%left '*' '/'
...
%%
program:
program statement '\"n'
|
;
statement:
expr { printf("%d\"n", $1); }
| VARIABLE '=' expr { sym[$1] = $3; }
;
expr:
INTEGER
| VARIABLE { $$ = sym[$1]; }
| expr '+' expr { $$ = $1 + $3; }
| expr '-' expr { $$ = $1 - $3; }
| expr '*' expr { $$ = $1 * $3; }
| expr '/' expr { $$ = $1 / $3; }
| '(' expr ')' { $$ = $2; }
;
%%
...
在Yacc的规则中,前面先定义了不同种类的Token,中间有一个%left,是指的左结合,那为什么又有两个left,是为了区分优先级,越往下优先级越高,所以’*‘,’/‘的优先级高于’+‘,’-‘。
中间则是规则,通过规则将Token 不断的结合成一个表达式,形成一棵树。语法规则是BNF定义的(巴科斯范式可以百度下,这里不多讲)我们来简单看一下规则的结构,有三个产生式,这里问题又来了,这个地方的产生式是什么,又回到了大学编译原理了,这里还是老规则,不做过多理论解释,简单了解下:
产生式一般就是左边是一个非终结符(非终结符就是可以被再分的),右边则是非终结符和终结符相结合的式子(终结符就是不可再分),整体意思就是左边的非终结符可以转换成右边的表达式(同理右边的表达式也能转成左边的非终结符),那么基于非终结符和终结符的特性,我们可以将一个非终结符根据产生式一直分解为由终结符组成的一串表达式,同理一串由终结符组成的式子我们也可以通过产生式转成某一个非终结符。
回到最上面的列子中,“Select”, “*”, “from”, “student” ,这是我们通过语法分析获取到的Token,都是终结符,他们是不可能在分的,那么下面定义下产生式来组合一下:
// 我们先来定义下产生式 双引号引着的我们就代表是终结符.反之则是非终结符
// 第一个产生式是SelectStmt,也就是一个查询表达式
SelectStmt:
// 可以变成下面这个表达式, 从什么表中拿什么字段
SelectFiled FromTable
SelectFiled:
// 可以是一个字段列表
"Select" FieldList
// 可以是所有字段 *
| "Select" "*"
FromTable:
// 从那个表中
"From" TableList
FieldList:
// 可以是一个字段
"Field"
// 可以是多个字段, 这个地方可以使用递归思想,也就是可以扩展无数个字段
| FieldList "," "Field"
TableList:
// 可以是一个表名
"Table"
// 可以是多个表名,同字段
| "TableList" "," "Table"
// 好了,下面开始解析我们上面那句SQL,记住从左往右依次来,"."代表我们读到的位子
Select . * From student
// Select 匹配到,是终结符,没有相关表达式转换,不变
=》Select * . From student
// 读到"*"发现 "Select" "*" 可以变成转换式 SelectFiled 于是转换
=》SelectFiled . From student
// 继续读发现到from 没有可以转换的产生式,不变
=》SelectFiled From . student
// 继续右边移,发现到student 可以匹配成TableList,转换
=》SelectFiled From TableList .
// 继续往右发现没了,于是重读,发现 From TableList 可以转换
=》SelectFiled FromTable .
// 最后这两个可以继续匹配成SelectStmt
=》SelectStmt
通过一系列的转换,最后我们获得了一个SelectStmt的表达式,这个过程也就是一棵树,我们根据树的结构就可以处理这句SQL了
这个例子只是一个很简单的列子,真实的结构会相当复杂
更加具体的内容可以参考官方博客:https://pingcap.com/blog-cn/tidb-source-code-reading-5/
三、自定义关键词
TiDB 所兼容的 MySQL 协议和语法已经较为丰富。但如果我们要想使 TiDB 兼容新的关键字和语法,该当如何呢?首先就要从 Parser 模块改起。因为只有经过 Parser 的解析,将SQL语句解析成AST,才能进行下一步构造计划,执行计划,数据写回的一系列过程。所以下面我们就讲讲自定义关键词的过程。
首先我们需要了解 Parser 模块是作为一个单独的项目维护的。其 Github 地址为:https://github.com/pingcap/parser。一般如果我们本地调试运行过 TiDB,我们的本地开发环境下都会自动下载了 Parser 项目的源代码。一般都在GoPath下的pkg目录下。进入项目源代码目录。有几个重要的文件需要注意。一个是 parser.y,它声明了语法解析的规则。举例看一下一条规则的大致组成。
DeleteWithoutUsingStmt:
"DELETE" TableOptimizerHints PriorityOpt QuickOptional IgnoreOptional "FROM" TableName PartitionNameListOpt TableAsNameOpt IndexHintListOpt WhereClauseOptional OrderByOptional LimitClause
{
// Single Table
tn := $7.(*ast.TableName)
tn.IndexHints = $10.([]*ast.IndexHint)
tn.PartitionNames = $8.([]model.CIStr)
join := &ast.Join{Left: &ast.TableSource{Source: tn, AsName: $9.(model.CIStr)}, Right: nil}
x := &ast.DeleteStmt{
TableRefs: &ast.TableRefsClause{TableRefs: join},
Priority: $3.(mysql.PriorityEnum),
Quick: $4.(bool),
IgnoreErr: $5.(bool),
}
if $2 != nil {
x.TableHints = $2.([]*ast.TableOptimizerHint)
}
if $11 != nil {
x.Where = $11.(ast.ExprNode)
}
if $12 != nil {
x.Order = $12.(*ast.OrderByClause)
}
if $13 != nil {
x.Limit = $13.(*ast.Limit)
}
$$ = x
}
以上面 DeleteStmt 的部分声明作为举例。首先紧接着 DeleteStmt 的是匹配规则。符合该规则的 sql 语句将进入到其实际处理逻辑中。例如,此时一个 sql 语句为 delete from t2 where id > 99。这句话中的 “delete” 匹配规则中的 “DELETE”。TableOptimizerHints,PriorityOpt,IgnoreOptional 等这些规则在 sql 并没有找到对应。但继续往后匹配,"from"匹配上了 “FROM”。解析继续。紧接着 “t2” 匹配到规则中的 “TableName”。"where id = 1"将匹配WhereClauseOptional规则。通过一系列匹配规则的判断。我们进入到实际处理逻辑当中。也就是上面代码中花括号包含的代码。首先创建了了一个 DeleteStmt 结构体。这个语法类似于 go。其中成员赋值需要使用 sql 中的信息时,使用游标顺序的数字就可以获取。数字游标以 1 开始。比如成员 Quick 对应的就是 规则中 QuickOptional 携带的信息。使用游标数值 4 并且转换类型赋值给 Quick 成员即可。通过一些列成员赋值,逻辑判断,最终构造出的结构体将作为 AST 返回值的原型。它与计划构造时传入的AST node节点对象有着直接联系。当使用 goyacc 编译工具将parser.y文件编译成parser.go文件时,对应语法解析返回的结果就是 DeleteStmt 节点,它是也一个AST对象。
那么现在就来说说怎么自定义关键字吧,我们以比较常见的 returning 语句作为示例。目标是要使 Parser 能够解析 “delete from t2 where id > 1 returning * " 其功能就是在执行这个 sql 后,返回删除的各行的所有列数据。而不是只返回受影响行数。要实现这个功能,首先就要修改 Parser 模块以兼容 ”returning“ 语法。接下来还需要修改计划,执行逻辑等部分代码。当然,我们现在只关注 parser模块修改,要实现的功能就是能解析 returning 子句并且将要求返回的字段保存起来作为 DeleteStmt 的成员。
首先,需要修改 update 语句的规则,添加解析 returning 子句的规则。第一步,在规则后面添加 ReturningStmt SelectStmtFieldList 使其能够解析”returning * “ 或者是"returning id, name"这要返回部分字段的语句。添加之后,规则如下所示。
"DELETE" TableOptimizerHints PriorityOpt QuickOptional IgnoreOptional "FROM" TableName PartitionNameListOpt TableAsNameOpt IndexHintListOpt WhereClauseOptional OrderByOptional LimitClause “RETURNING” SelectStmtFieldList
其中 “RETURNING” 是新声明的规则,匹配 sql 中的 returning 字段。后面的 SelectStmtFieldList 是公用规则,表示需要返回的字段。“RETURNING” 需要在misc.go文件中声明为 token 才能使用。
在修改了规则之后,再修改内部逻辑。我们准备构造一个子查询对象作为 DeleteStmt 的成员将需要查询的信息全部保存在其中。那么首先就是要修改DeleteStmt 的结构,添加一个 SelectStmt 结构作为其成员。然后开始修改花括号内的逻辑,添加如下逻辑。
tn := $7.(*ast.TableName)
tn.IndexHints = $10.([]*ast.IndexHint)
tn.PartitionNames = $8.([]model.CIStr)
join := &ast.Join{Left: &ast.TableSource{Source: tn, AsName: $9.(model.CIStr)}, Right: nil}
subSelect := &ast.SelectStmt{
Fields: $15.(*ast.FieldList),
From: &ast.TableRefsClause{TableRefs: join},
}
if $11 != nil {
subSelect.Where = $11.(ast.ExprNode)
}
if $2 != nil {
subSelect.GroupBy = $12.(*ast.GroupByClause)
}
这样就将需要查询的信息包装成结构体作为成员保存到了DeleteStmt 节点中了。到这一步还没有完,我们只是修改了parser,y文件。实际程序编译运行依靠的是parser.go 文件。所以我们使用 goyacc 工具编译 parser.y 文件,编译产物就是 parser.go 文件。命令如下
goyacc -o parser.go parser.y
那么全部操作完成之后,启动TiDB,输入命令测试:
delete from t2 where id > 1 returning *
测试结果如下图;
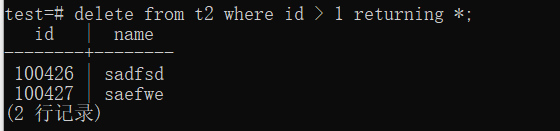
可以看到delete语句后面带上 returning 子句并没有报错,说明系统解析到了这个句式。下面返回删除的行有赖于对计划的修改,由于篇幅以及主题的关系,这一部分将留到下篇再讲。
TiDB官方博客也对如何修改 Parser 增强语法兼容做出了示例,具体可以参考 https://pingcap.com/blog-cn/30mins-become-contributor-of-tidb-20190808/