

背景说明
在日常使用和管理TiDB集群的时候,通常是业务出现了访问性能、延迟出现抖动或者其他故障问题时,我们才会去针对性解决对应的问题。数据库的安全稳定运行,正如一个人身体健康,天天吃好睡好一样,二者是有相通之处的。数据库的管理员,包括但不限于DBA,就是数据库的专属医生,排查和分析数据库的问题与医生需要对病人望闻问切一样异曲同工。经验丰富的资深DBA,就是数据库的专家级医生,当数据库生病时(遇到问题、故障),由于管理员的能力水平差异,治好的时间和效果也会不同,最终导致不一样的业务损失。我们当前尽量避免这种情况的出现,宁愿事发前花数倍的时间精力去琢磨如何避免,也不愿意半夜处理过多的意外性问题。所以,需要提前规避突发性、临时性的、危急性的情况发生,尽量做到一切尽在掌控中。

(图片来源于网络)
我们会定期去做体检以检查有无健康问题,对于数据库,同样期望对它去做定期的“体检”,这样就可以提前发现潜在的风险和隐患,避免病状来临时情况危急,可以提前解决隐患问题,保证数据库健康、安全稳定运行。
通常我们可以借助工具可以实现TiDB数据库的诊断,比如官方推荐的PingCAP Clinic 诊断服务与 Clinic Server 云诊断平台,它们实现远程定位集群问题和本地快速检查集群状态。第三方工具,如DBdoctor等,也是一个考虑的选项。
本文更多地从朴素的思考维度结合常用的命令分享日常的运维管理经验,让大家能在无法使用工具的场景,如离线环境、对安全有苛刻要求的私有云场景、部分模块的深度检查等方面,有所参考借鉴。
核心要点
- 【基础】集群健康状态检查
- 【基础】集群组件参数配置检查
- 【基础】硬件资源和配置检查
- 【高级】网络及操作系统内核配置检查
- 【高级】数据库性能检查
- 【高级】灾备及高可用
深度检查介绍
方法概要
本次巡检主要包括数据库
- 服务器操作系统配置
- 数据库配置
- 网络配置
- 磁盘配置
- 数据库性能分析
- 备份、高可用等。
根据所收集时间点的相关数据来评估主要的配置情况,提供建议使性能加以优化。
注意说明,在执行深度的业务巡检时由于营运系统是一个复杂的系统工程,牵涉到主机,操作系统,网络,数据库,中间件等,还有系统的核心内容,即业务应用。任何方面导致的故障问题、调整都可能造成系统的变化。
本次巡检主要针对系统前一段时间和目前的一些运行情况进行检查,会根据收集的信息进行分析并指出系统的运行情况及存在隐患,同时给出适当的建议。
从预防的角度看,着重于避免已知故障的重演,同时对保持系统良好运行提出建议。大家平时常见的数据库bug,也是在特定情况、特定场合触发的故障问题,它事先不是一定有症兆的,所以有时我们做健康检查也无法百分百能提前发现所有的问题。
使用工具
本次数据库性能检查的工具说明:
- TiDB Dashboard、Prometheus、Grafana 进行系统信息收集
- 操作系统工具和命令检查操作系统
- SQL 命令检查数据库配置
- TiDB Dashboard、Prometheus、Grafana 进行数据库性能资料的收集
系统配置深度巡检[标准项]
数据库系统拓扑概况
1)登陆集群中控机,执行命令:
tiup cluster list
tiup-cluster 支持使用同一个中控机部署多套集群,而命令 tiup cluster list 可以查看当前登录的用户使用该中控机部署了哪些集群。输出含有以下字段的表格:
● Name:集群名字
● User:部署用户
● Version:集群版本
● Path:集群部署数据在中控机上的路径
● PrivateKey:连接集群的私钥所在路径
2)查看集群概况,执行下面命令
tiup cluster display <cluster-name>
初步从整体把控集群的概括、节点总数和部署拓扑等内容。
操作系统最佳实践配置检查
登录TiDB集群中控机,执行官方推荐的验命令一键检查:
tiup cluster check {cluster-name} --cluster
结果会输出selinux 、swap 、network 、THP 、CPU使用模式等诸多内容检查项,常规的检查通过此方法已经可以满足。如果机器环境都符合要求,则不会存在fail项内容(warn项看情况可选修复)。如果存在fail项内容,可以再参考下面官方推荐的命令进行自动修复:
tiup cluster check {cluster-name} --cluster --apply
如果上述自动修复执行仍存在fail项内容,请联系业务环境相关的负责人处理,直到无fail项检查内容。
如果遇到更加精细化的深度巡检,需要对每个内核系统项逐一检查,则可以参考下述内容。
操作系统版本
执行命令:
tiup cluster exec <cluster-name> --command 'uname -a'
结果样例:
节点 IP 地址 |
系统操作内核 |
版本 |
|---|---|---|
样例:IP1 |
样例:4.19.90-2102.2.0.0062.ctl2.x86_64 |
样例:CentOS 7 |
样例:IP2 |
样例:4.19.90-2102.2.0.0062.ctl2.x86_64 |
样例:CentOS 7 |
|
|
|
内核参数配置
登陆每一台机器,执行命令检查:
# 文件描述符最大数量
cat /proc/sys/fs/file-max
# 网络连接队列最大长度
cat /proc/sys/net/core/somaxconn
# IPv4的TCP SYN Cookie设置
cat /proc/sys/net/ipv4/tcp_syncookies
# 系统最小保留内存
cat /proc/sys/vm/min_free_kbytes
# 内存交换
cat /proc/sys/vm/swappiness
# 内存超分配策略
cat /proc/sys/vm/overcommit_memory
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
样例: fs.file-max = 1000000 net.core.somaxconn = 32768 net.ipv4.tcp_syncookies = 0 vm.min_free_kbytes = 1048576 vm.swappiness = 0 vm.overcommit_memory = 1 |
已满足最佳实践,无需修改。 fs.file-max = 1000000 net.core.somaxconn = 32768 net.ipv4.tcp_syncookies = 0 vm.min_free_kbytes = 1048576 vm.swappiness = 0 vm.overcommit_memory = 1
|
样例:IP2 |
样例: fs.file-max = 1000000 net.core.somaxconn = 32768 net.ipv4.tcp_syncookies = 0 vm.min_free_kbytes = 1048576 vm.swappiness = 0 vm.overcommit_memory = 1 |
已满足最佳实践,无需修改。 fs.file-max = 1000000 net.core.somaxconn = 32768 net.ipv4.tcp_syncookies = 0 vm.min_free_kbytes = 1048576 vm.swappiness = 0 vm.overcommit_memory = 1
|
|
|
|
Ulimit参数配置
检查 /etc/security/limits.conf 中各项 limit 值。执行命令:
tiup cluster exec <cluster-name> --command 'cat /etc/security/limits.conf | grep -v "#"'
检查 /etc/security/limits.conf 中各项 limit 值:
<deploy-user> soft nofile 1000000
<deploy-user> hard nofile 1000000
<deploy-user> soft stack 10240
其中 <deploy-user> 为部署、运行 TiDB 集群的用户,最后一列的数值为要求达到的最小值。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
样例: tidb soft stack 32768 tidb hard stack 32768 |
tidb soft nofile 1000000 tidb hard nofile 1000000 tidb soft stack 32768 tidb hard stack 32768 |
样例:IP2 |
样例: tidb soft stack 32768 tidb hard stack 32768 |
tidb soft nofile 1000000 tidb hard nofile 1000000 tidb soft stack 32768 tidb hard stack 32768 |
|
|
|
swap分区状态
检查部署机是否启用 Swap 分区:建议禁用 Swap 分区。执行命令:
tiup cluster exec <cluster-name> --command 'cat /proc/swaps'
若文件内容为空或仅有标题行,则 Swap 未启用。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
样例:4095m |
off |
样例:IP2 |
样例:4095m |
off |
样例:IP3 |
样例:off |
已满足最佳实践,无需修改 |
|
|
|
透明大页配置
检查部署机是否启用透明大页:建议禁用透明大页。
执行命令:
tiup cluster exec <cluster-name> --command 'cat /sys/kernel/mm/transparent_hugepage/enabled'
如果结果不是 never,参考使用 grubby --update-kernel=ALL --args="transparent_hugepage=never" 修改。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
never |
已满足最佳实践,无需修改 |
|
|
|
NTP服务状态
检查部署机是否配置了时间同步服务:即 ntpd 是否在运行
执行命令:
tiup cluster exec <cluster-name> --command 'sudo systemctl status ntpd.service'
如果输出 running 表示 NTP 服务正在运行。若返回报错信息 Unit ntpd.service could not be found.,请尝试执行以下命令,以查看与 NTP 进行时钟同步所使用的系统配置是 chronyd 还是 ntpd。
tiup cluster exec <cluster-name> --command 'sudo systemctl status chronyd.service'
若发现系统既没有配置 chronyd 也没有配置 ntpd,则表示系统尚未安装任一服务。此时,应先安装其中一个服务,并保证它可以自动启动。
1)如果安装的是NTP,则执行 ntpstat 命令检测是否与 NTP 服务器同步
tiup cluster exec <cluster-name> --command 'ntpstat'
如果输出 synchronised to NTP server,表示正在与 NTP 服务器正常同步,如果输出unsynchronised表示 NTP 服务未正常同步,输出Unable to talk to NTP daemon. Is it running? 表示NTP 服务未正常运行。
2)如果安装的是Chrony 服务,则执行 chronyc tracking 命令查看 Chrony 服务是否与 NTP 服务器同步。
tiup cluster exec <cluster-name> --command 'chronyc tracking'
如果该命令返回结果为 Leap status : Normal,则代表同步过程正常。如果返回Not synchronised表示同步过程出错。如果返回506 Cannot talk to daemon则表示 Chrony 服务未正常运行。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
N/A |
未采集到NTP同步信息,请确认时间同步状态 |
|
|
|
磁盘挂载参数
检查 ext4 分区的挂载参数:确保挂载参数包含 nodelalloc,noatime 选项。
执行命令:
tiup cluster exec <cluster-name> --command 'cat /etc/fstab'
确认数据盘包含 nodelalloc,noatime 选项。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
nodelalloc、ext4 |
已满足最佳实践,无需修改 |
|
|
|
防火墙运行状态
执行命令:
tiup cluster exec <cluster-name> --command 'sudo systemctl status firewalld.service'
检查 FirewallD 服务是否启用:建议用户禁用 FirewallD 或为集群各服务地址和端口添加允许规则。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
inactive (dead) |
已满足最佳实践,无需修改 |
|
|
|
3.2.9 SELinux
SELinux必须关闭或设置为 permissive 模式。
执行命令:
tiup cluster exec <cluster-name> --command 'sestatus'
在输出中查找SELinux如果是disabled或permissive,则满足要求。如果 SELinux 未关闭,请打开 /etc/selinux/config 文件,找到以 SELINUX= 开头的行,并将其修改为 SELINUX=disabled。修改完成后,需要重启系统,因为从 enforcing 或 permissive 切换到 disabled 模式只有在重启后才会生效。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
disabled |
已满足最佳实践,无需修改 |
|
|
|
irqbalance
检查 irqbalance 服务是否启用:建议用户启用 irqbalance 服务。
执行命令:
tiup cluster exec <cluster-name> --command 'systemctl status irqbalance'
若显示 Active: active (running),表示服务已启用。若显示 Active: inactive (dead),表示服务未运行。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
Active: active (running) |
已满足最佳实践,无需修改 |
|
|
|
CPU运行模式
执行命令:
tiup cluster exec <cluster-name> --command 'cpupower frequency-info'
在输出中查找 current policy 或 current governor 字段,若显示 performance,则表示 CPU 处于高性能模式。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
performance |
已满足最佳实践,无需修改 |
|
|
|
3.2.12 系统时间
检查部署机系统时间是否同步:将部署机系统时间与中控机对比,偏差超出某一阈值(500ms)后报错。
执行命令:
tiup cluster exec <cluster-name> --command 'date +%s%3N'
在输出时间与中控机时间对比,计算出时间差。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
与中控机时间差在100ms |
满足最佳实践,无需修改 |
|
|
|
系统时区
检查部署机系统时区是否同步:将部署机系统的时区配置进行对比,如果时区不一致则报错。
执行命令:
tiup cluster exec <cluster-name> --command 'date +"%Z"'
在输出时区与中控机对比,确认是否一致。
结果样例:
节点 IP 地址 |
检查结果 |
修改意见 |
|---|---|---|
样例:IP1 |
CST |
与中控机一致,无需修改 |
|
|
|
网络配置
执行命令:
tiup cluster exec <cluster-name> --command ' ethtool bond0'
查看网卡支持的最大速度、当前协商速率及双工模式。建议是万兆网卡。
结果样例:
节点 IP 地址 |
网卡名 |
Bonding Mode |
速率 |
修改意见 |
|---|---|---|---|---|
样例:IP1 |
bond0 |
fault-tolerance (active-backup) |
10000Mb/s |
已满足最佳实践,无需修改 |
|
|
|
|
|
服务器配置
内存大小
检查部署机的内存大小:建议生产集群总内存容量 >= 32Gb。
执行命令:
tiup cluster exec <cluster-name> --command 'free -h'
结果样例:
节点 IP 地址 |
网卡名 |
Bonding Mode |
速率 |
修改意见 |
|---|---|---|---|---|
样例:IP1 |
bond0 |
fault-tolerance (active-backup) |
10000Mb/s |
已满足最佳实践,无需修改 |
|
|
|
|
|
CPU 核心数
检查部署机 CPU 信息:建议生产集群 CPU 逻辑核心数 >= 16
执行命令:
tiup cluster exec <cluster-name> --command 'lscpu'
结果样例:
节点 IP 地址 |
网卡名 |
Bonding Mode |
速率 |
修改意见 |
|---|---|---|---|---|
样例:IP1 |
bond0 |
fault-tolerance (active-backup) |
10000Mb/s |
已满足最佳实践,无需修改 |
|
|
|
|
|
CPU 是否开启超线程
lscpu | grep -e "Thread(s) per core"
● Thread(s) per core:
○ 若为 1,表示超线程未开启。
○ 若为 2,表示超线程已启用。
执行命令:
tiup cluster exec <cluster-name> --command 'uname -a'
结果样例:
节点 IP 地址 |
网卡名 |
Bonding Mode |
速率 |
修改意见 |
|---|---|---|---|---|
样例:IP1 |
bond0 |
fault-tolerance (active-backup) |
10000Mb/s |
已满足最佳实践,无需修改 |
|
|
|
|
|
磁盘使用量
执行命令
tiup cluster exec <cluster-name> --command 'df -TH'
结果样例:
节点 IP 地址 |
网卡名 |
Bonding Mode |
速率 |
修改意见 |
|---|---|---|---|---|
样例:IP1 |
bond0 |
fault-tolerance (active-backup) |
10000Mb/s |
已满足最佳实践,无需修改 |
|
|
|
|
|
也可以登陆TiDB Dashboard,查看集群信息,可以确认:
● CPU架构、CPU配置
● 物理内存
● 磁盘文件系统、磁盘容量
数据库集群[标准项]
系统service清单
登录Grafana查看Overview面板,Services Port Status,确认各个节点服务是否正常。
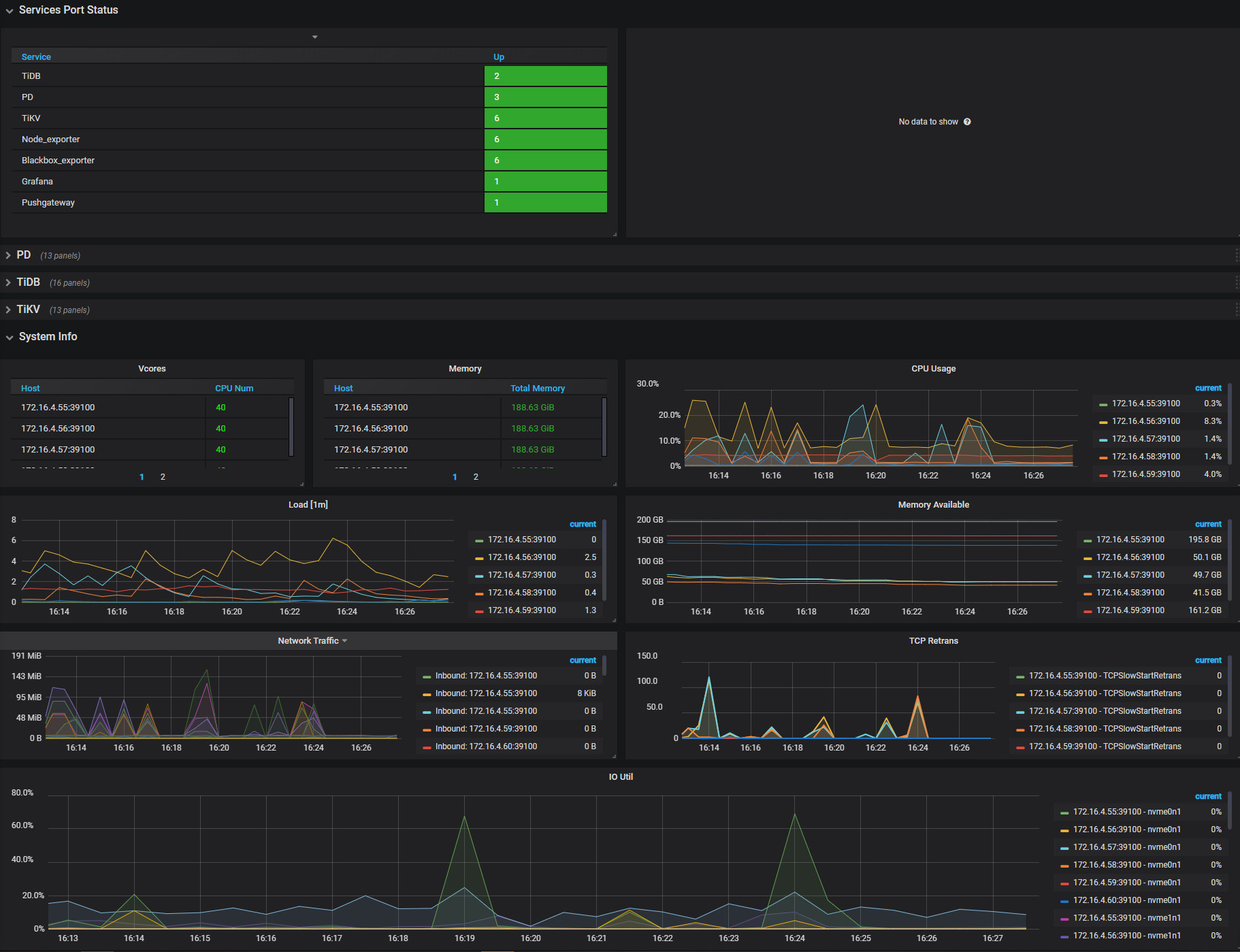
以上面板展示常见的负载、内存、网络、IO 监控。发现有瓶颈时,推荐扩容或者优化集群拓扑,优化 SQL、集群参数等。
集群组件清单
- TiDB : 与应用进行交互负责 SQL 逻辑,通过 PD 寻址到实际数据的 TiKV 位置,进行 SQL 操作。
- TiKV : 负责数据存储,是一个提供完整ACID事务的分布式 Key-Value 存储引擎;
- PD : 负责管理调度,如数据和 TiKV 位置的路由信息维护、TiKV 数据均衡,TiDB通过pd获取tso
数据库检查
软件组件版本
登陆TiDB Dashboard,查看集群信息,选择实例,可以确认组件版本情况。

集群检查 [高级]
集群存储拓扑
集群拓扑lable
replication.location-labels:
- region
- zone
- rack
- host
- node
集群拓扑level:isolation-level:[]
集群副本replicas:max-replicas=3
结论:当前集群isolation-level为空,且副本数为3,副本保障级别是host,满足3副本高可用要求。
集群参数
tiup edit-config 查看集群的配置内容,输出和判断结果样例:
角色 |
参数名称 |
当前值 |
建议值 |
说明 |
|---|---|---|---|---|
tidb |
log.file.max-days |
30 |
90 |
日志最大保留的天数。 |
tidb |
log.file.max-backups |
7 |
50 |
保留的日志的最大数量。 |
tidb |
tmp-storage-path |
<操作系统临时文件夹>/<操作系统用户ID> _tidb/xx=/tmp-storage |
/tidb-data1/tmp |
单条 SQL 语句的内存使用超出系统变量 tidb_mem_quota_query 限制时,某些算子的临时磁盘存储位置。 |
tidb |
tmp-storage-quota |
-1 |
10737418240 |
tmp-storage-path 存储使用的限额。 |
tidb |
performance.max-procs |
0 |
TiDB服务器的最低cores * 0.9 / 单机TiDB 数量 |
TiDB 的 CPU 使用数量。默认值为 0 表示使用机器上所有的 CPU。 |
tidb |
plugin |
dir: /app/htap/tidb-4000/bin/plugin load: audit-1 |
关闭 |
TiDB审计目录及plugin名称。 |
tikv |
readpool.unified.max-thread-count |
MAX(4, CPU quota * 0.8) |
TiKV服务器的最低cores * 0.8 / 单机TiKV 数量 |
统一处理读请求的线程池最多的线程数量,即 UnifyReadPool 线程池的大小。 |
tikv |
storage.block-cache.capacity |
系统总内存大小的 45% |
TiKV服务器的最低memory * 0.45 / 单机TiKV数量 |
共享 block cache 的大小。 |
tikv |
log.file.max-days |
30 |
90 |
日志最大保留的天数。 |
tikv |
log.file.max-backups |
7 |
50 |
保留的日志的最大数量。 |
pd |
replication.location-labels: |
[ - region - zone - rack - host - node] |
|
TiKV 集群的拓扑信息。 |
pd |
log.file.max-days |
30 |
90 |
日志最大保留的天数。 |
pd |
log.file.max-backups |
7 |
50 |
保留的日志的最大数量。 |
pd |
schedule |
enable-cross-table-merge: true leader-schedule-limit: 32 max-pending-peer-count: 32 max-snapshot-count: 32 merge-schedule-limit: 32 split-merge-interval: 24h30m
|
建议删掉,使用默认配置 |
enable-cross-table-merge:设置是否开启跨表 merge,默认值:true leader-schedule-limit:同时进行 Region 调度的任务个数,默认值:2048 max-pending-peer-count:控制单个 store 的 pending peer 上限,调度受制于这个配置来防止在部分节点产生大量日志落后的 Region,默认值:64 max-snapshot-count:控制单个 store 最多同时接收或发送的 snapshot 数量,调度受制于这个配置来防止抢占正常业务的资源,默认:64 merge-schedule-limit:同时进行的 Region Merge 调度的任务,设置为 0 则关闭 Region Merge,默认值:8 split-merge-interval:控制对同一个 Region 做 split 和 merge 操作的间隔,即对于新 split 的 Region 一段时间内不会被 merge,默认:1h
|
PD概览
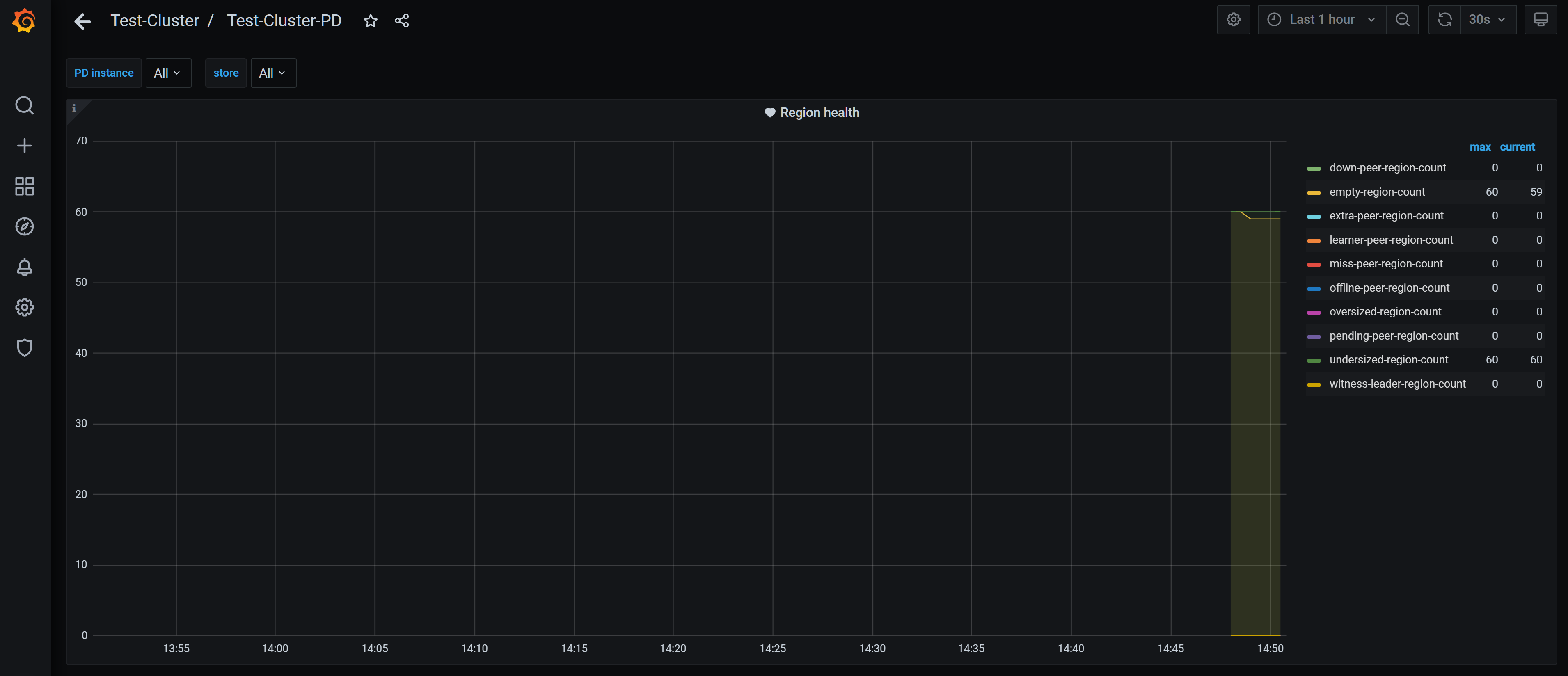
原则上来说,该监控面板偶尔有数据是符合预期的。但长期有数据,需要排查是否存在问题。
- 查看Grafana TiDB 监控面板概览
结果样例:Storage capacity : 300TB
Current storage size : 合理范围
Region Health : empty-region count 50k
结论:判断集群容量充足,空region较多。
- 查看Grafana PD健康面板,获取TiKV的打分信息
结果:Store capacity : 各区域内 Store 容量基本一致
Store available: 各区域内 Store 容量基本一致
Store Region score : 各区域内 Store 打分基本一致
Store leader score : 各区域内 Store 打分基本一致
结论:各区域内Store打分基本一致,不同区域因配置原因差异较大。
TiDB概览
- 查看Grafana TiDB 监控面板概览
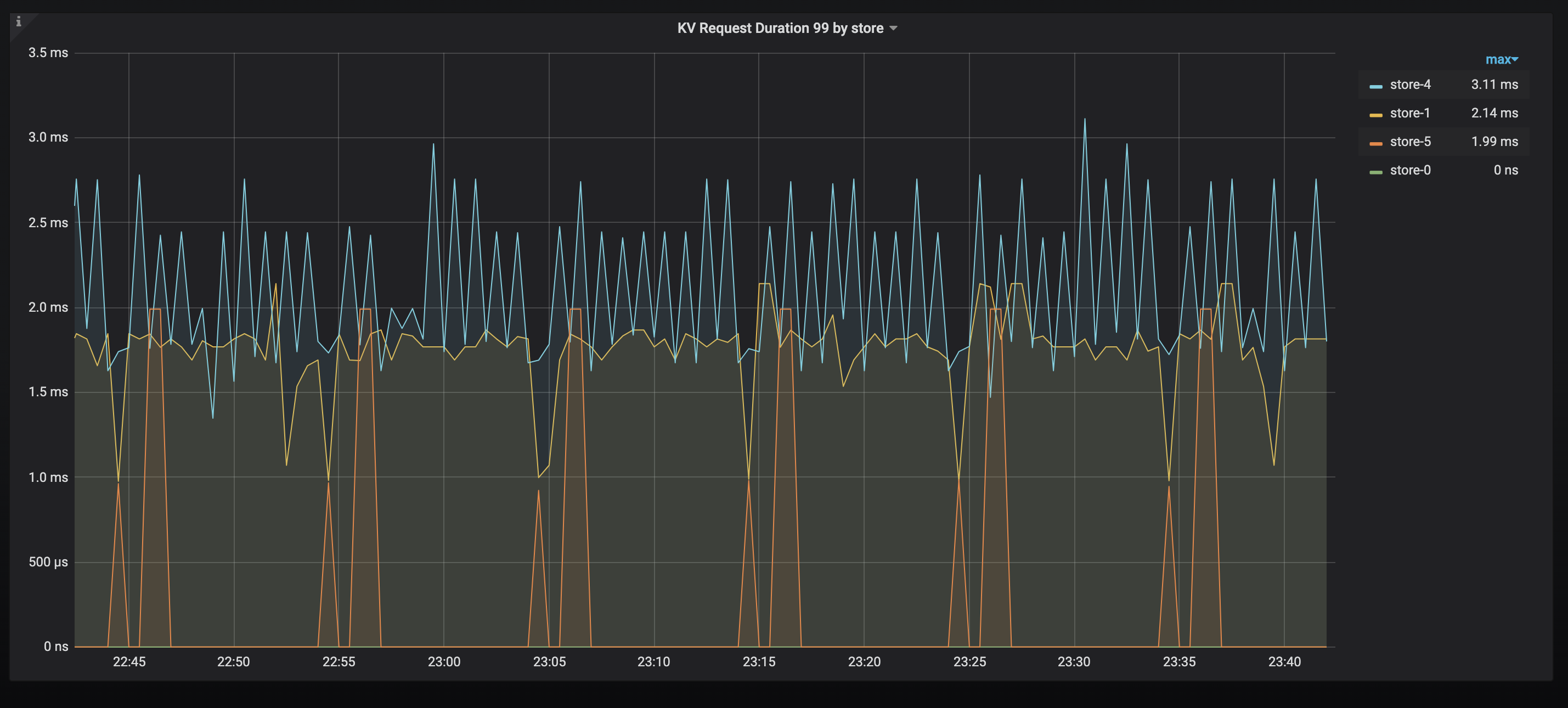
TiKV 当前 .99(百分位)的响应时间。如果发现有明显高的节点,可以排查是否有热点,或者相关节点性能较差。
结果:Statement OPS : 单类SQL 操作次数合理
Duration :99% 的 SQL 延时较高
CPU :各节点CPU使用率较低
Memory :各节点内存使用率较低
结论:判断是否Duration 较高,如果较高则建议结合业务情况分析慢SQL
TiKV概览
- 查看Grafana TiKV Details监控CLuster面板概览
结果样例:
leader : 各节点 Region Leader 分布差异较大
region : 各节点 Region分布不均
结论样例:leader 分布不均匀,Region 分布不均匀,主要为空region较多、各区域配置不同、数据导数等原因导致,以各区域region score为主。
系统信息概览
查看Dashboard里主机监控信息面板概览

结果样例:CPU Usage : TiDB、TiKV、PD 各节点占用 CPU 在 较低
Memory Available : TiDB节点、TiKV节点可用内存充足
Network Traffic : 网络流量未达到瓶颈
IO Util : 各磁盘平均使用率基本都在 40%以下
结论: 操作系统侧资源负载居于正常水平
数据库性能[高级]
GC状态
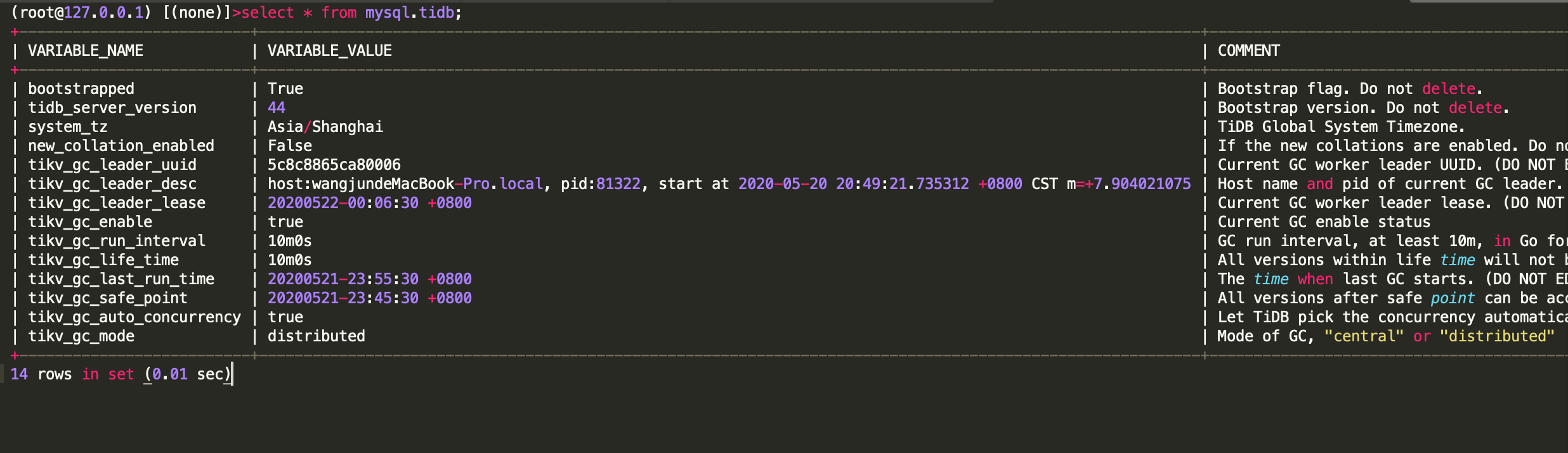
通过查看系统表 mysql.tidb 可以检查到最后 GC(垃圾清理)的时间,观察 GC 是否正常。
如果 GC 发生异常,可能会造成历史数据存留过多,进而可能影响访问效率。
SQL性能概况
- 查看TiDB Dashboard 查看TOP SQL。
- 结论样例:当前集群主要负载为压测SQL,分别为全表扫描以及update更新同一条数据导致锁冲突,可以尝试优化压测逻辑,建立合适索引。

慢查询分析
- 查看TiDB Dashboard 查看慢查询界面,分析慢日志,分析执行计划。

- 结论样例:统计信息过期,需要进行更新统计信息。
灾备及高可用[高级]
全量备份

- 全量备份的方法使用官方推荐的BR工具实现,通常是快照备份。可以通过查看BR的备份日志 backup.log 日志或者查看S3上的数据情况,确认备份成功情况。
- 结果样例:备份成功。
增量备份
-
在v6.5之前的增量备份可以是TICDC备份到S3,在v6.5之后的版本是通过PITR功能实现备份。
-
结果样例:
- 如果是TICDC,可以通过 Grafana查看TICDC-Overview项中的dataflow面板,查看 changefeed的延迟情况。
- 如果是PITR增量备份,可以通过查看PD 持久化日志备份任务状态确认,可以通过
br log status查询。
TiCDC同步状态

-
如果有搭建异地灾备集群,即主从集群,可以通过确认TICDC的实时同步延迟情况,确认TICDC是否正常。也可以使用命令行查询 Changefeed 是否正常运行。使用
changefeed query命令可以查询特定同步任务(对应某个同步任务的信息和状态),指定--simple或-s参数会简化输出,提供基本的同步状态和 checkpoint 信息。不指定该参数会输出详细的任务配置、同步状态和同步表信息。 -
结果样例:
- 如果是TICDC,可以通过 Grafana查看TICDC-Overview项中的dataflow面板,查看 changefeed的延迟情况。
- 确认同步正常
深度巡检报告模板
本次对xxx系统生产数据库为xxx版本的TiDB数据库,本次深度检查发现了一些问题,具体描述和建议如下面的报告。
检查方面 |
上次检查/发现情况 |
本次检查/发现情况 |
|---|---|---|
OS相关最佳实践配置 |
|
样例:OS参数不符合官方推荐,详情可查xx章节 |
操作系统性能 |
|
样例:资源利用率正常 |
数据库配置 |
|
样例:数据库配置不符合官方推荐,详情可查xx章节 |
数据库性能 |
|
样例:数据库性能压测逻辑及SQL建议优化,详情可查xx章节 |
备份状态 |
|
样例:集群未开始备份,建议开启定期全备 |
高可用架构 |
|
样例:集群拓扑结构建议优化,详情可查xx章节 |
设备状态 |
|
样例:服务器配置建议优化,详情可查xx章节 |
集群运行状态 |
|
样例:集群各组件运行正常 |
如上为检查的结果情况,如果在检查中发现TiDB 运行状态的问题,对检查范围内的情况进行记录,给出整改的建议。
总结
本文通过从常用的命令和监控入手,分享日常的深度巡检指引,让大家能在无法使用其他工具的场景,如离线环境、对安全有苛刻要求的私有云场景、部分模块的深度检查等方面,也能够如期开展深度检查工作,哪怕只有一个点能起到帮助作用,也发挥出它的价值了。
望与君共勉!