

作者:靳献旗,汽车之家 DBA
【是否原创】是
【首发渠道】TiDB 社区
【目录】
1.背景介绍
2.跨机房方案概述
3.工作原理
4.集群架构
5.部署步骤
6.线上使用情况
7.展望
【正文】
1. 背景介绍
公司要求对 0 级应用做跨机房部署,当 A 机房整体故障时,业务可以快速切到 B 机房继续提供服务。恰好也涉及到了几套 TiDB 集群相关业务,这里做一下总结和回顾,希望能够帮助需要的用户。本文主要涉及下面几项内容:
● 几种基于 TiDB 的跨机房部署方案及优缺点
● 基于 Binlog 跨机房双向复制的详细部署步骤
● 线上 TiDB 跨机房使用情况及展望
2. 跨机房方案概述
下面介绍下 TiDB 几种跨机房集群部署方案的优缺点:
| 序号 | 方案 | 优点 | 缺点 |
|---|---|---|---|
| 1 | 同城三中心 | 是完美适配TiDB的部署方式 1.提供单一中心故障的自动故障转移能力 2.同城多活,资源最大化利用,所有副本都能参与计算 3.较低的成本(同城裸光纤) | 绝大多数用户不具备同城三中心条件 |
| 2 | 同城双中心可用区方案(同中心的多个可用区在一定程度上物理隔离) | 1.提供单一可用区故障的自动故障转移能力 2.同城多活,资源最大化利用,所有副本都能参与计算 3.较低的成本(同城裸光纤) | 无法容忍包含多个可用区的机房整体故障 |
| 3 | 两地三中心 | 1.提供单一可用区故障的自动故障转移能力 2.同城双活 | 1.成本过高 2.收益低(高网络延迟,异地中心的部分不参与计算) 3.只依赖异地的副本无法恢复一致性(RPO=0)的数据,其异地容灾能力与主从集群方案差别不大 |
| 4 | 同城双中心 Raft 复制 | 1.提供灾备中心故障的自动故障转移能力 2.同城双活 3.资源最大化利用,所有副本都能参与计算 4.较低的成本(同城裸光纤) | 只能容忍灾备机房故障,缺乏实际意义 |
| 5 | 同城双中心自适应同步复制 | 1.提供灾备中心故障的自动故障转移能力 2.提供主中心故障时的灾备机房数据手工恢复的能力 3.同城双活 4.资源最大化利用,所有副本都能参与计算 5.较低的成本(同城裸光纤) | 方案还外部试点测试中,预计2021年下半年达到生产级别可用 |
目前公司是同城双中心,因此上述方案排除掉1、2、3方案,4方案缺乏实际意义,5方案还不成熟,所以4、5也排除掉。难道没有方案可用?下面还有两种方案没提到,这里从技术层面分析下两种方案的优缺点。
| 序号 | 方案 | 优点 | 缺点 |
|---|---|---|---|
| 6 | 基于 Binlog 双向复制 | 1.成熟稳定 | 1.Drainer 不具备高可用 2.并发处理不足 |
| 7 | 基于 TiCDC 双向复制 | 1.具备高可用 2.并发处理强 | 1.官方未 GA 2.内存使用较大 3.复制中断问题 |
经过分析,我们最终选择了过度方案 6 :基于 Binlog 双向复制部署跨机房集群。后续时间成熟,我们会升级到方案 7 或者 5。
3. 工作原理
下面简单描述下基于 Binlog 双向同步的工作原理
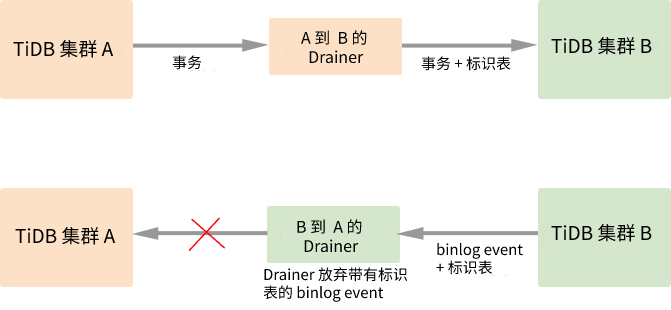
在 A 和 B 两个集群间开启双向同步,则写入集群 A 的数据会同步到集群 B 中,然后这部分数据又会继续同步到集群 A,这样就会出现无限循环同步的情况。如上图所示,在同步数据的过程中 Drainer 对 Binlog 加上标记,通过过滤掉有标记的 Binlog 来避免循环同步。详细的实现流程如下:
(1)为两个集群分别启动 TiDB Binlog 同步程序。
(2)待同步的事务经过 A 的 Drainer 时,Drainer 为事务加入 _drainer_repl_mark 标识表,并在表中写入本次 DML event 更新,将事务同步至集群 B。
(3)集群 B 向集群 A 返回带有 _drainer_repl_mark 标识表的 Binlog event。集群 B 的 Drainer 在解析该 Binlog event 时发现带有 DML event 的标识表,放弃同步该 Binlog event 到集群 A。
● 注意事项:
集群间双向同步的前提条件是,写入两个集群的数据必须保证无冲突,即在两个集群中,不会同时修改同一张表的同一主键和具有唯一索引的行。
更详细的内容请参考官方文档
4. 集群架构
集群信息如下:
集群 A (位于机房 A,ip 做了脱敏处理)
| IP | 版本 | 组件 | 配置 |
|---|---|---|---|
| 192.168.1.1 | 4.0.9 | TiDB/PD/Pump/Drainer | 内存:256G 硬盘:SATA SSD CPU:48核 网卡:万兆 |
| 192.168.1.2 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.1.3 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.1.4 | 4.0.9 | 2个TiKV | 内存:256G 硬盘:SATA SSD CPU:64核 网卡:万兆 |
| 192.168.1.5 | 4.0.9 | 2个TiKV | |
| 192.168.1.6 | 4.0.9 | 2个TiKV | |
| 192.168.1.7 | 4.0.9 | 2个TiKV |
集群 B (位于机房 B,ip 做了脱敏处理)
| IP | 版本 | 组件 | 配置 |
|---|---|---|---|
| 192.168.2.1 | 4.0.9 | TiDB/PD/Pump/Drainer | 内存:256G 硬盘:SATA SSD CPU:48核 网卡:万兆 |
| 192.168.2.2 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.2.3 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.2.4 | 4.0.9 | 2个TiKV | 内存:256G 硬盘:SATA SSD CPU:64核 网卡:万兆 |
| 192.168.2.5 | 4.0.9 | 2个TiKV | |
| 192.168.2.6 | 4.0.9 | 2个TiKV | |
| 192.168.2.7 | 4.0.9 | 2个TiKV |
集群架构如下
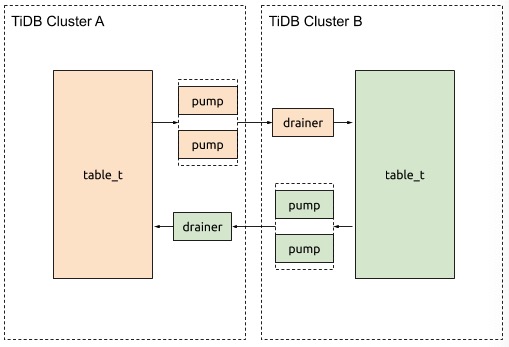
5. 部署步骤
本节详细介绍基于 Binlog 的跨机房部署步骤,这里以 TiDB 4.0.9 版本为例,对一个线上未开启 Binlog 的集群配置跨机房复制。主要分为两部分配置:A 集群配置,B 集群配置。
● A 集群配置步骤概要
(1)A 集群部署 Pump
(2)A 集群开启 Binlog
(3)A 集群导出全量数据,将全量数据导入 B 集群
(4)A 集群配置 drainer ,实现增量复制
● B 集群部署步骤概要
(1)B 集群部署 Pump
(2)B 集群开启 Binlog
(3)B 集群配置 drainer ,实现反向复制
5.1 A 集群部署步骤
【 A 集群部署 Pump 】
- 编写 Pump 扩容拓扑配置
vim scale_out_pump.yaml
pump_servers:
- host: 192.168.1.1
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3 #指定 binlog 可在本地存储的天数,超过指定天数的 binlog 会被自动删除
- host: 192.168.1.2
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- host: 192.168.1.3
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- 执行下面命令扩容 Pump
tiup cluster scale-out a_cluster scale_out_pump.yaml
- 查看 Pump 状态
tiup cluster display a_cluster
- 登录 TiDB 查看 Pump 状态
show pump status;
【 A 集群开启 Binlog 】
- 编辑 A 集群配置文件开启 Binlog
tiup cluster edit-config a_cluster
server_configs:
TiDB:
binlog.enable: true # 设置为 true 开启 Binlog
binlog.ignore-error: true # 建议设置为 true ,否则 Binlog 无法写入时会导致整个集群无法写入数据
- 滚动重启 TiDB-server
tiup cluster reload a_cluster -R tidb
- 登录 TiDB 确认当前集群是否开启 Binlog
show global variables like 'log_bin'; # 1 表示开启
【 A 集群导出全量数据,将全量数据导入 B 集群 】
1.A 集群导出全量数据
/data/tidb-tools/bin/dumpling -h 192.168.1.1 -P 4000 -u username -p password --params="TiDB_isolation_read_engines=tikv" --filetype sql --tidb-mem-quota-query 8589934592 --threads 2 -r 500000 -F 200MiB -o /data/bak_4000_20210522 -f 'sms_send.*' -f 'rcm_pool.*' --loglevel debug --logfile dumpling_20210522.log
2.将全量数据导入 B 集群
/data/tidb-tools/bin/loader -h 192.168.2.1 -P 4000 -u username -p password -t 4 -d /data/bak_4000_20210522
【 A 配置 Drainer 实现增量复制 】
- 编写 Drainer 扩容拓扑配置
vim scale_out_drainer.yaml
drainer_servers:
- host: 192.168.1.1
ssh_port: 22
port: 8249
commit_ts: 425112071610302470 #从上一步的 /data/tmp/bak_20210522/metadata 文件获取
deploy_dir: /data/drainer-8249
data_dir: /data/drainer-8249/data
log_dir: /data/drainer-8249/log
config:
syncer.loopback-control: true
syncer.channel-id: 123456 #互相同步的两个集群配置相同的 ID
syncer.sync-ddl: true #需要同步 DDL 操作
syncer.db-type: tidb
syncer.ignore-schemas: INFORMATION_SCHEMA,METRICS_SCHEMA,PERFORMANCE_SCHEMA,mysql,test
syncer.ignore-table: #忽略 checkpoint 表
- db-name: tidb_binlog
tbl-name: checkpoint
syncer.to.host: 192.168.2.1 #下游 TiDB 集群 ip
syncer.to.port: 4000 #下游 TiDB 集群 port
syncer.to.sync-mode: 1
syncer.to.password: password #下游用户的密码
syncer.to.user: drainer_user #下游用户,需要提前在下游 TiDB 集群创建
syncer.txn-batch: 200 #将 DML 分批执行,用于设置每个事务中包含多少个 DML
syncer.worker-count: 4 #指定并发数
- 执行下面命令扩容 Drainer
tiup cluster scale-out a_cluster scale_out_drainer.yaml
- 查看 Drainer 状态
tiup cluster display a_cluster
4.登录 TiDB 查看 Drainer 状态
show drainer status;
5.2 B 集群部署步骤
【 B 集群部署 Pump 】
- 编写 Pump 扩容拓扑配置
vim scale_out_pump.yaml
pump_servers:
- host: 192.168.2.1
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- host: 192.168.2.2
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- host: 192.168.2.3
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- 执行下面命令扩容 Pump
tiup cluster scale-out b_cluster scale_out_pump.yaml
- 查看 Pump 状态
tiup cluster display b_cluster
- 登录 TiDB 查看 Pump 状态
show pump status;
【 B 集群开启 Binlog 】
- 编辑 B 集群配置文件开启 Binlog
tiup cluster edit-config b_cluster
server_configs:
TiDB:
binlog.enable: true # 设置为 true 开启 Binlog
binlog.ignore-error: true # 建议设置为 true ,否则 Binlog 无法写入时会导致整个集群无法写入数据
- 滚动重启 TiDB-server
tiup cluster reload b_cluster -R TiDB
- 确认当前集群是否开启 Binlog
show global variables like 'log_bin'; # 1 表示开启
【 B 配置 Drainer 实现反向复制 】
- 编写 Drainer 扩容拓扑配置
vim scale_out_drainer.yaml
drainer_servers:
- host: 192.168.2.1
ssh_port: 22
port: 8249
deploy_dir: /data/drainer-8249
data_dir: /data/drainer-8249/data
log_dir: /data/drainer-8249/log
config:
syncer.loopback-control: true
syncer.channel-id: 123456 #互相同步的两个集群配置相同的 ID
syncer.sync-ddl: false #不需要同步 DDL 操作
syncer.db-type: tidb
syncer.ignore-schemas: INFORMATION_SCHEMA,METRICS_SCHEMA,PERFORMANCE_SCHEMA,mysql,test
syncer.ignore-table: #忽略 checkpoint 表
- db-name: tidb_binlog
tbl-name: checkpoint
syncer.to.host: 192.168.1.1 #下游 TiDB 集群 ip
syncer.to.port: 4000 #下游 TiDB 集群 port
syncer.to.sync-mode: 1
syncer.to.password: password #下游用户的密码
syncer.to.user: drainer_user #下游用户,需要提前在下游 TiDB 集群创建
syncer.txn-batch: 200
syncer.worker-count: 2
- 执行下面命令扩容 Drainer
tiup cluster scale-out b_cluster scale_out_drainer.yaml
- 查看 Drainer 状态
tiup cluster display b_cluster
4.登录 TiDB 查看 Drainer 状态
show drainer status;
5.3 测试双向复制
我们重点对下面几种场景做了测试:
| 序号 | 测试内容 | 测试结果 |
|---|---|---|
| 1 | A 集群数据同步到 B 集群是否正常 | 正常 |
| 2 | B 集群数据同步到 A 集群是否正常 | 正常 |
| 3 | A 集群 DDL 同步到 B 集群是否正常 | 正常 |
| 4 | B 集群 DDL 不能同步到 A 集群 | 无法同步 |
6. 线上使用情况
目前线上有3套 TiDB 集群做了跨机房部署,如下表所示:
| 集群信息 | 业务说明 | 跨机房部署说明 | 运行时间 |
|---|---|---|---|
| 集群1 | 短信业务 | 库级别双向复制 | 2020/10 — 至今 |
| 集群2 | 用户中心登录注册相关接口 | 库级别双向复制 | 2021/05 — 至今 |
| 集群3 | 资源池 | 集群级别双向复制 | 2021/05 — 至今 |
7. 展望
基于 Binlog 的跨机房部署方案运行比较稳定,但是存在一些缺点:并发处理能力不足,无法做到高可用。因此基于 Binlog 的方案目前属于过度方案,我们还是希望不久的将来能够使用基于 TiCDC 的方案替代 Binlog 方案,TiCDC 弥补了上述 Binlog 的不足,也是官方大力开发并支持的方案。
介于目前 TiCDC 的双向同步方案还没正式 GA,而且存在一些问题,例如使用内存较多,同步中断等。值得期待的是,官方正在大力推进测试,应该会在2021年第三季度可以GA。届时,我们将重点进行测试,让我们拭目以待。