

TiDB 会使用统计信息来选择索引,统计信息的健康度影响到索引的使用,从而影响到SQL的执行效率,本文先简单介绍了统计信息原理,然后讲解 TiDB 如何查看统计信息,如何收集,以及加快收集的方法,最后介绍下统计信息收集可能遇到的问题以及解决办法。
一、统计信息原理简介
TiDB主要采用直方图和Count-Min Sketch来进行统计信息的收集和维护。
1、直方图简介
直方图是一种对数据分布情况进行描述的工具,从而让数据库知道它含有哪些数据,它会按照数据的值大小进行分桶,并用一些简单的数据来描述每个桶,比如落在桶里的值的个数。大多数数据库都会选择用直方图来进行区间查询的估算。根据分桶策略的不同,常见的直方图可以分为等深直方图(也叫等高直方图)和等宽直方图。等宽直方图每个桶(bucket)保存一个值以及这个值累积频率,等深直方图每个桶需要保存不同值的个数,上下限以及累计频率等。
在 TiDB 使用的是等深直方图,主要在 range 查询场景中用到,所谓的等深直方图,就是落入每个桶里的值数量尽量相等。举个例子,比方说对于给定的集合 {1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5},并且生成 4 个桶,那么最终的等深直方图就会如下图所示,包含四个桶 [1.6, 1.9],[2.0, 2.6],[2.7, 2.8],[2.9, 3.5],其桶深均为 3。
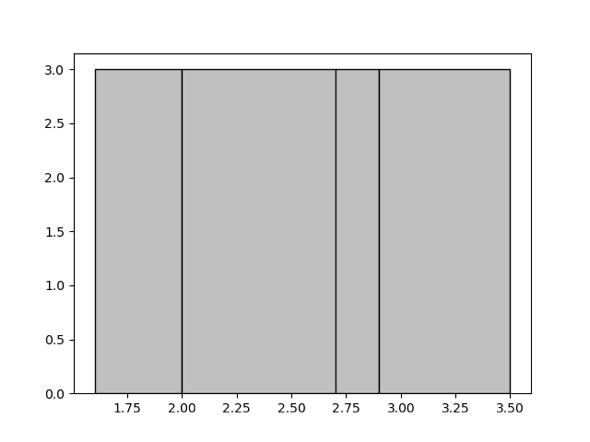
估算逻辑
- 当一个查询完全覆盖了一个 bucket,这个 bucket 的高度就是 row count 的值。
- 当一个查询覆盖了一个 bucket 的一部分,我们只需要计算这个 range 占整个 bucket 的比例,然后与桶深相称即可。
比如 (2.00, 2.75) 是一个 bucket,当查询的范围是 (2.15, 2.50) 时,rowCount(2.15, 2.5.0) = (2.50 - 2.15) / (2.75 - 2.00) * rowCount(2.00, 2.75) - 当一个查询覆盖了多个 bucket,计算方法与上面类似。
最佳实践
analyze table执行收集统计信息时可以添加:WITH NUM BUCKETS 参数来用于指定生成直方图的桶数量上限,当桶数量越多,直方图的估算精度就越高,不过也会同时增大统计信息的内存使用,可以视具体情况来做调整。
2、Count-Min Sketch 简介
Count-Min Sketch 是一种主要用于点查的数据结构,并且可以提供较强的准确性保证。
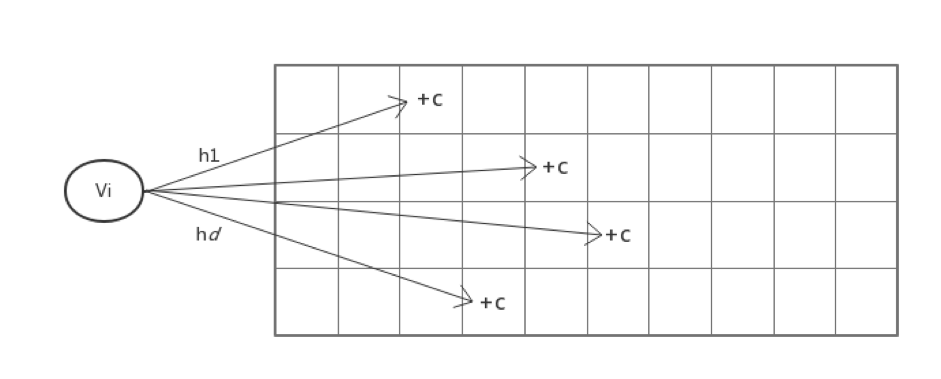
算法流程
- 选定 d 个 hash 函数,开一个 dxm 的二维整数数组作为哈希表
- 对于每个元素,分别使用 d 个 hash 函数计算相应的哈希值,并对 m 取余,然后在对应的位置上增 1 ,二维数组中的每个整数称为 sketch
- 要查询某个元素的频率时,只需要取出 d 个 sketch , 返回最小的那一个(其实 d 个 sketch 都是该元素的近似频率,返回任意一个都可以,该算法选择最小的那个)
最佳实践
基于哈希结构的Count-Min Sketch,有概率出现 hash 碰撞,analyze table时适当调大深度和宽度的参数( WITH NUM CMSKETCH DEPTH / WITH NUM CMSKETCH WIDTH ) 这两个参数来降低冲突的概率,参数调整会影响到内存使用,需要根据具体情况而定。
想要了解更多原理可以参考:
Synopses for Massive Data: Samples,Histograms, Wavelets, Sketches
二、查看统计信息
1、show stats_meta
查看表的统计信息 meta 信息,主要关注:update_time ( meta 信息最新更新时间)
、 modify_count (修改的行数)、row_count (总行数),该语句也可以通过 where 条件过滤结果,如下:
mysql> show stats_meta where Db_name='ad_dianjing17' and table_name='ad_search_keywords';
+---------------+--------------------+----------------+---------------------+--------------+-----------+
| Db_name | Table_name | Partition_name | Update_time | Modify_count | Row_count |
+---------------+--------------------+----------------+---------------------+--------------+-----------+
| ad_dianjing17 | ad_search_keywords | | 2020-10-09 16:42:37 | 0 | 67317176 |
+---------------+--------------------+----------------+---------------------+--------------+-----------+
1 row in set (0.49 sec)
2、show stats_healthy
查看表的健康度信息,主要关注 healthy (健康度),该语句也可以通过 where 条件过滤结果,如下:
mysql> show stats_healthy where Db_name='ad_dianjing17' and table_name='ad_search_keywords';
+---------------+--------------------+----------------+---------+
| Db_name | Table_name | Partition_name | Healthy |
+---------------+--------------------+----------------+---------+
| ad_dianjing17 | ad_search_keywords | | 100 |
+---------------+--------------------+----------------+---------+
1 row in set (0.01 sec)
健康度计算方式:
当 modify_count >= row_count 时,健康度为 0;当 modify_count < row_count 时,健康度为 (1 - modify_count / row_count) * 100。
3、SHOW STATS_HISTOGRAMS
可通过 SHOW STATS_HISTOGRAMS 来查看索引或者数据列的不同值数量以及 NULL 值数量等信息,主要关注 update_time (最新更新时间)、 distinct_count (去重数量)、null_count (NULL 值数量)、avg_col_size (列平均长度),该语句也可以通过 where 条件过滤结果,如下:
mysql> show stats_histograms where Db_name='ad_dianjing17' and table_name='ad_search_keywords';
+---------------+--------------------+----------------+----------------+----------+---------------------+----------------+------------+--------------+-------------+
| Db_name | Table_name | Partition_name | Column_name | Is_index | Update_time | Distinct_count | Null_count | Avg_col_size | Correlation |
+---------------+--------------------+----------------+----------------+----------+---------------------+----------------+------------+--------------+-------------+
| ad_dianjing17 | ad_search_keywords | | ad_user_id | 0 | 2020-10-09 16:39:59 | 48608 | 0 | 5.67 | 0.438685 |
| ad_dianjing17 | ad_search_keywords | | ad_group_id | 0 | 2020-10-09 16:39:56 | 368320 | 0 | 5.66 | 0.520494 |
| ad_dianjing17 | ad_search_keywords | | keyword | 0 | 2020-10-09 16:39:59 | 24412160 | 0 | 16.63 | 0.041397 |
| ad_dianjing17 | ad_search_keywords | | create_time | 0 | 2020-10-09 16:40:03 | 331968 | 0 | 8 | 0.61165 |
| ad_dianjing17 | ad_search_keywords | | id | 0 | 2020-10-09 16:39:55 | 67317176 | 0 | 8 | 0 |
| ad_dianjing17 | ad_search_keywords | | status | 0 | 2020-10-09 16:40:08 | 8 | 0 | 2 | 0.033228 |
| ad_dianjing17 | ad_search_keywords | | idx_group_user | 1 | 2020-10-09 16:42:37 | 1024980 | 0 | 0 | 0 |
+---------------+--------------------+----------------+----------------+----------+---------------------+----------------+------------+--------------+-------------+
7 rows in set (0.04 sec)
4、SHOW STATS_BUCKETS
可通过 SHOW STATS_BUCKETS 来查看直方图每个桶的信息,主要关注 count (所有落在这个桶及之前桶中值的数量)、repeats (最大值出现的次数)、lower_bound (最小值)、upper_bound (最大值),如果表数据量比较大会有大量的桶信息,该语句也可以通过 where 条件过滤结果,如下:
mysql> show stats_buckets where table_name='ad_ocpc' and db_name='ad_dianjing17';
+---------------+------------+----------------+--------------------+----------+-----------+-------+---------+-------------+-------------+
| Db_name | Table_name | Partition_name | Column_name | Is_index | Bucket_id | Count | Repeats | Lower_Bound | Upper_Bound |
+---------------+------------+----------------+--------------------+----------+-----------+-------+---------+-------------+-------------+
| ad_dianjing17 | ad_ocpc | | id | 0 | 0 | 1 | 1 | 1 | 1 |
| ad_dianjing17 | ad_ocpc | | id | 0 | 1 | 2 | 1 | 2 | 2 |
| ad_dianjing17 | ad_ocpc | | id | 0 | 2 | 3 | 1 | 3 | 3 |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| ad_dianjing17 | ad_ocpc | | status | 0 | 0 | 71 | 71 | -1 | -1 |
| ad_dianjing17 | ad_ocpc | | status | 0 | 1 | 129 | 58 | 0 | 0 |
| ad_dianjing17 | ad_ocpc | | status | 0 | 2 | 254 | 125 | 1 | 1 |
| ad_dianjing17 | ad_ocpc | | ad_user_id | 0 | 0 | 4 | 4 | 25972245 | 25972245 |
| ad_dianjing17 | ad_ocpc | | ad_user_id | 0 | 1 | 155 | 151 | 160185657 | 160185657 |
+---------------+------------+----------------+--------------------+----------+-----------+-------+---------+-------------+-------------+
271 rows in set (3.85 sec)
5、统计信息相关系统表
- stats_buckets 统计信息的桶
- stats_histograms 统计信息的直方图
- stats_meta 表的元信息,比如总行数和修改数
- stats_feedback 定期更新统计信息情况
三、统计信息收集
在 TiDB 中执行 ANALYZE TABLE 语句比在 MySQL 耗时更长。因为MySQL是基于采样少量的页面生成统计信息,但 TiDB 会扫描大量的 region 完全重构一系列统计信息。另外,执行 ANALYZE TABLE 时,TiDB 可能不包含最近提交的更改,如果正在对表执行大量的更新和写入,建议这些DML操作后再收集。
##1、手动收集
通过执行 ANALYZE 语句来收集统计信息。
analyze table ad_search_keywords;
对于分区表的使用,可以对单独的分区进行收集:
analyze table ad_search_keywords partition p20201009;
2、自动收集
(1)run-auto-analyze
该参数自动收集统计信息的开关,默认true(开启)。
(2)表统计信息自动收集需要同时满足以下条件
- 表中至少 1000 行数据
- 表从未被 analyze 过,至少在默认 1 分钟( 20 * stats-lease )内无 DML 操作
- 如果表被 analyze 过,那么当累计到足够的修改,即当某个表的修改行数与总行数的比值(modify_count / row_count)大于 tidb_auto_analyze_ratio,并且当前时间在 tidb_auto_analyze_start_time 和 tidb_auto_analyze_end_time 之间时,后台会自动执行 analyze 语句
(3)索引统计信息的自动收集需要同时满足以下条件
- 表中至少 1000 行数据
- 新增索引从未被 analyze 过
- 跟表的自动收集触发条件一样,自动 analyze 也会收集索引列的统计信息
(4)自收集相关参数
-
tidb_auto_analyze_ratio,默认值 0.5。
-
tidb_auto_analyze_start_time 和 tidb_auto_analyze_end_time,默认值分别为 00:00 和 23:59,建议设置为业务低峰期时间,注意这2个参数默认为 UTC 时间,比如需要凌晨00点开始执行,需要执行:
set global tidb_auto_analyze_start_time='16:00 +0000' -
stats-lease,默认值3(单位秒)。在执行 DML 语句时,TiDB 会自动更新表的总行数以及修改的行数。这些信息会定期自动持久化,更新周期默认是 1 分钟(20 * stats-lease)
3、提升 ANALYZE 执行速度
执行 ANALYZE 语句的时候,你可以通过一些参数来调整并发度或者操作的region数量,以取得TiDB集群负载和执行性能的平衡。
(1)tidb_build_stats_concurrency
默认值:4
说明:目前 ANALYZE 执行的时候会被切分成一个个小的任务,每个任务只负责某一个列或者索引。调整该参数 可以控制同时执行的任务的数量。
如果一个表索引数量为4个时,需要收集列和4个索引统计信息,在4个并发收集线程的情况下,肯定会有一个统计信息收集处于pending状态,需要
等待其他统计信息收集完毕后才能收集这个统计信息,相当于统计信息收集的时间会变2倍,这时如果调整该参数并行度到5,就可以同时收集该表
的所有的统计信息,节省统计信息收集的时间。
注意:当这个变量被设置得更大时,会对集群的SQL执行性能产生一定影响
(2)tidb_distsql_scan_concurrency
默认值:15
说明:这个变量用来设置 scan 操作的并发度。OLAP 类应用适合较大的值,OLTP 类应用适合较小的值。对于 OLAP 类应用,最大值建议不要
超过所有 TiKV 节点的 CPU 核数。
在执行分析普通列任务的时候,调大该参数可以用于控制一次读取的 Region 数量。
注意:这个参数不是给统计信息收集专用的,调整该参数会对所有SQL中涉及scan操作都有影响。
(3)tidb_index_serial_scan_concurrency
默认值:1
说明:这个变量用来设置顺序 scan 操作的并发度,OLAP 类应用适合较大的值,OLTP 类应用适合较小的值。
因为索引本身是有序的,在执行分析索引列任务的时候,调整该参数可以用于控制一次读取的Region 数量。
注意:当这些变量被设置得更大时,会对集群的SQL执行性能产生一定影响。
(4)tidb_enable_fast_analyze
默认值:0(快速分析关闭)
说明:如果需要快速抽样收集统计信息:将 tidb\"_enable\"_fast\"_analyze (默认值为 0)设置为1 来打开快速分析功能。
注意:该功能会随机采样1万行数据来构建统计信息,如果数据分布不均或者数据量较少会导致准确度低,从而影响执行计划中最优索引的选择。
使用SQL如下:
set @@tidb_enable_fast_analyze = 1;
analyze table ad_search_keywords;
4、查看统计信息收集执行状态
收集统计信息过程中,可以通过 show analyze status 语句查询执行状态,但是 show analyze status 是 session 级别的,需要登录执行 analyze 的 tidb server 执行该命令才能查看 analyze 进度,这里要吐槽下,该语句也可以通过 where 条件过滤结果,如下:
mysql> show analyze status where Table_schema='ad_dianjing17';
+----------------------+--------------------+----------------+------------------------------+----------------+---------------------+---------+
| Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | State |
+----------------------+--------------------+----------------+------------------------------+----------------+---------------------+---------+
| ad_dianjing17 | ad_search_keywords | | analyze index k_user_id_kw | 0 | NULL | pending |
| ad_dianjing17 | ad_search_keywords | | analyze index idx_kid | 0 | NULL | pending |
| ad_dianjing17 | ad_search_keywords | | analyze index idx_group_user | 9691435 | 2020-10-09 16:39:03 | running |
| ad_dianjing17 | ad_search_keywords | | analyze index keyword | 9380872 | 2020-10-09 16:39:03 | running |
| ad_dianjing17 | ad_search_keywords | | analyze index ad_group_id | 9779389 | 2020-10-09 16:39:03 | running |
| ad_dianjing17 | ad_search_keywords | | analyze columns | 20489585 | 2020-10-09 16:39:03 | running |
+----------------------+--------------------+----------------+------------------------------+----------------+---------------------+---------+
四、 删除统计信息
可通过执行 DROP STATS 语句来删除统计信息。语句如下:
mysql> DROP STATS ad_search_keywords;
五、统计信息导入导出
有时候跟TiDB官方技术人员一起排查SQL问题时,需要看下统计信息是否准确,以及执行计划基于这个统计信息是否出现偏差,从而推测是否是 CBO 优化器的问题,在这种需求下需要导出和导入对应 table 的统计信息。
1、统计信息导出
通过以下命令可以获取数据库 ${db_name} 中的表 ${table_name} 的 json 格式的统计信息:
curl -G "http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}" > dxl.log`
如果想获取指定时间上的 json 格式统计信息,可以通过下面2种方式:
curl -G "http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}" > dxl.log
curl -G "http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyy-MM-dd HH:mm:ss}" > dxl.log
注意:指定时间需要在 tikv_gc_safe_point (select * from mysql.tidb where VARIABLE_NAME=‘tikv_gc_safe_point’)这个gc时间之后。
2、统计信息导入
将统计信息导出接口得到的 json 文件导入数据库中:
mysql> LOAD STATS ‘file_name’;
file_name 为被导入的统计信息文件名。
六、相关问题解决
1、慢查询不走合适的索引,可能是统计信息问题
(1)explain查看SQL的执行计划,show stats_healthy;show stats_meta; show stats_histograms;查看统计信息情况,然后手动收集统计信息:analyze table
(2)如果上面仍然解决不了问题,可以通过sql binding来指定SQL的执行计划
2、PD stats leader无法选举问题
问题描述
在升级集群时,tidb日志中有出现:[stats] /tidb/stats/owner ownerManager相关的失败报错,说明stats owner没有选举成功。
[2020/08/25 05:08:42.830 +08:00] [INFO] [manager.go:267] ["failed to campaign"] ["owner info"="[stats] /tidb/stats/owner ownerManager c111a58f-829a-48a2-81f6-453defay082c"] [error="lost watcher waiting for delete"]
[2020/08/25 05:08:42.830 +08:00] [INFO] [manager.go:239] ["etcd session is done, creates a new one"] ["owner info"="[stats] /tidb/stats/owner ownerManager c111a58f-829a-48a2-81f6-453defay082c"]
[2020/08/25 05:08:43.669 +08:00] [WARN] [manager.go:170] ["failed to new session to etcd"] [ownerInfo="[stats] /tidb/stats/owner ownerManager c111a58f-829a-48a2-81f6-453defay082c"] [error="rpc error: code = Canceled desc = grpc: the client connection is closing"]
[2020/08/25 05:08:43.869 +08:00] [INFO] [manager.go:243] ["break campaign loop, NewSession failed"] ["owner info"="[stats] /tidb/stats/owner ownerManager c111a58f-829a-48a2-81f6-453defay082c"] [error="rpc error: code = Canceled desc = grpc: the client connection is closing"]
[2020/08/25 05:08:44.687 +08:00] [INFO] [manager.go:292] ["revoke session"] ["owner info"="[stats] /tidb/stats/owner ownerManager c111a58f-829a-48a2-81f6-453defay082c"] [error="rpc error: code = Canceled desc = grpc: the client connection is closing"]
解决方案:
重启大法好,重启后还是不行,稍微麻烦并且安全的方案就是新搞一个空集群,把数据迁移过来。
3、在高写入并发的集群中慎用analyze(需要调整到低峰执行),因为analyze操作对造成较高的写入延迟。
PS:文章格式跟MacDown还是有些区别,下面有md格式的文章可以自取。
TiDB统计信息.md (19.7 KB)