

【是否原创】是
【首发渠道】TiDB 社区
作者:陈青松 易车资深研发工程师
彭召静 易车DBA
1.背景介绍
易车公司成立于2000年,于2010年在美国纽交所挂牌上市。 并于2020年11月完成私有化,成为腾讯大家庭一员。 作为中国汽车互联网平台企业,易车公司为中国汽车用户提供专业、丰富的互联网资讯服务,并为汽车厂商和汽车经销商提供卓有成效的互联网营销解决方案。《超级818汽车狂欢夜》是浙江卫视联合易车App推出的汽车主题超级“晚”,由浙江卫视节目中心超级晚工作室制作。晚会把汽车的速度与激情,与科技创新、时尚潮流融合,配合台网跨屏互动体验,呈现一场展现汽车工业魅力的大秀。
2.业务场景介绍
易车818狂欢节,tidb应用场景比较多,818汽车狂欢数据看板是tidb主要的应用业务之一,看板实时展示818购车节的专题、活动、流量、线索、互动等数据表现。其中摇一摇(红包,半价车,易车币)和主会场分会场直播节目投票是用户参与度最高,数据流量最大的环节。在整个活动中,不仅要求数据库能够存储海量的数据,同时能够应对高并发,低延迟场景,不仅作为数据的存储介质,还会作为实时计算的数据源头,配合流量数据,实现秒级数据实时播报。数据库和flink是整个系统中非常重要的两个组件,flink的数据来源包括数据库和业务流量数据,所以数据库不仅要满足数据秒级实时推送,还要支持flink高并发的读(维表)写(结果表)请求,经过严格的压测及各种线上场景的模拟,最终选择了tidb作为大屏展示核心业务的数据库。

3.数据库选型
818活动期间,我们对数据库提出的要求是:
- 需要具备海量数据存储的能力
- 提供高并发,低延迟的读写能力
- 服务稳定,易扩展
最初,MYSQL仍然是数据库的首选方案,为了应对流量暴涨及可能遇到的突发情况,我们进行了多次模拟压测。压测过程中,为了保证计算结果的实时性,实时任务会频繁的对数据库进行大批量的数据写入,MYSQL主从延迟升高,极端情况下引起MYSQL主从切换,切换时间过长,导致数据库出现短暂不可用状态。同时实时任务会持续写入大量数据,引起磁盘爆满。TIDB最初作为备选方案,在多次压测之后,我们考虑采用TIDB作为主方案,在PingCAP 技术同学的帮助下,对现有版本进行了升级,排查和优化TIDB在使用过程中的问题,经过多次压测后,TIDB能够完全满足在各个场景下的需求。
红包摇一摇业务方采用MYSQL作为主要方案,在压测过程中,MYSQL基本满足需求,为了避免由于业务流量暴涨引起MYSQL不可用的情况,业务方选用TIDB作为容灾方案,TIDB通过DM将数据实时同步到TIDB中,当MYSQL不可用时,业务方直接将数据库切换为TIDB。
4.tidb架构
818汽车狂欢数据看板业务:
在整个业务中,实时计算的数据源包括MYSQL、TIDB、SQLSERVER和流量日志。为了保证实时计算的稳定,大数据相关组件都有主备两个方案。
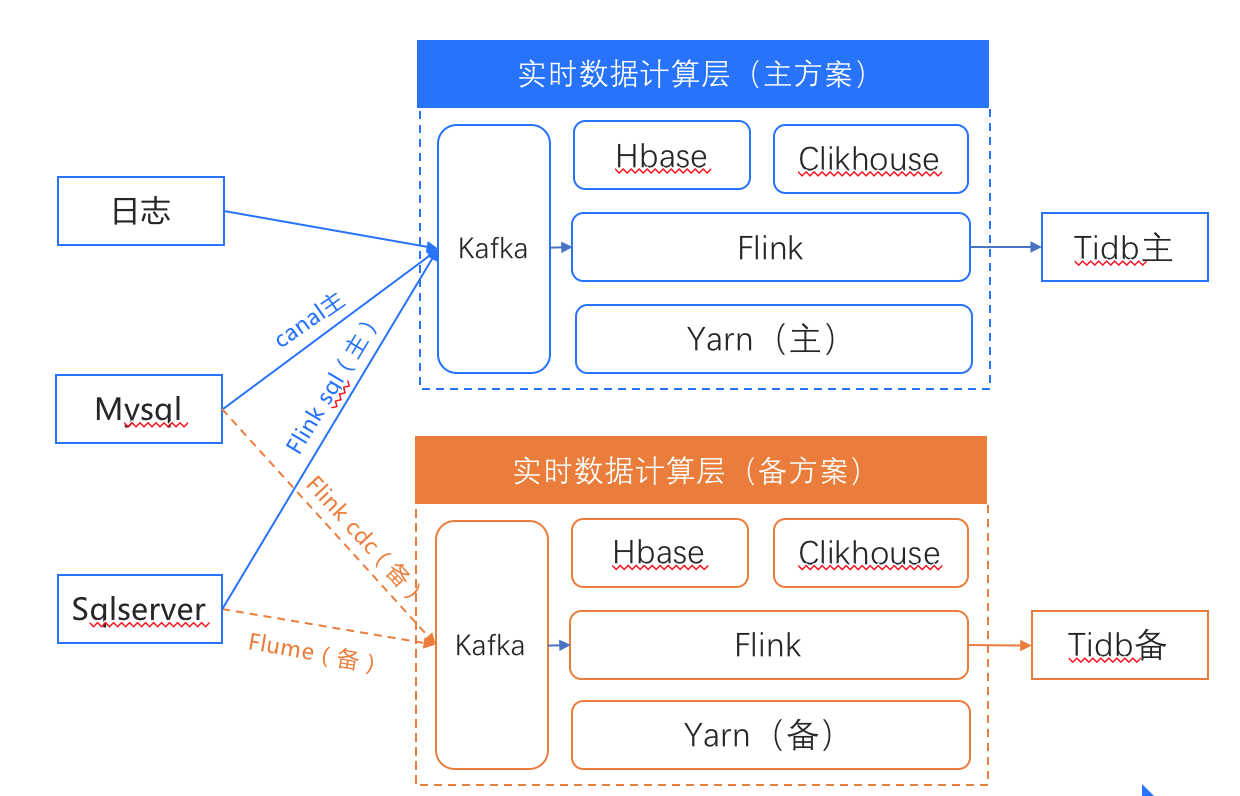
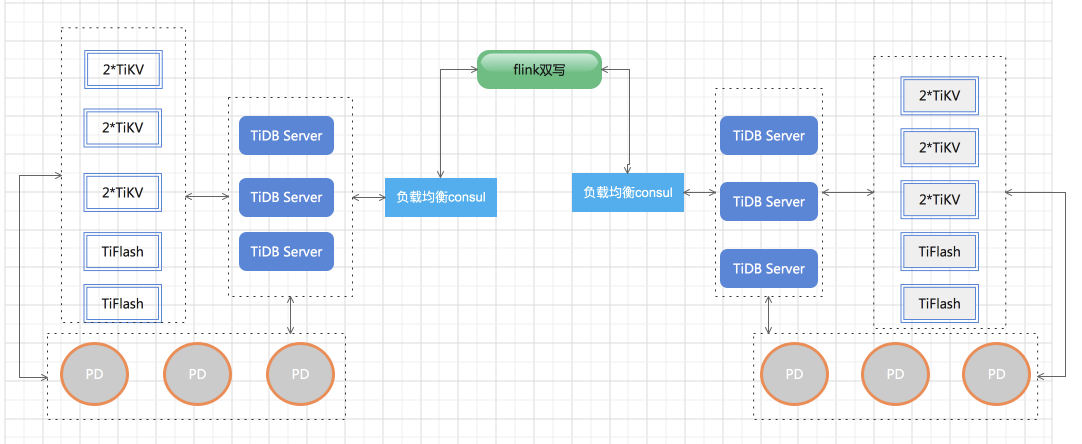
TIDB作为其中的关键组件,我们也准备了两个集群,和实时计算的主备方案一一对应,业务研发通过双写的方式把数据同时写入两个集群,一部分业务的查询连接集群1,另一部分业务的查询连接集群2,当其中一个集群出现问题,应用端切换到另外一个集群。两个TiDB集群都是部署3个TiDB server用consul做负载均衡对外提供服务,3个pd server,存储节点有2块数据盘所以采用单机双节点部署TiKV,2个Tiflash节点,另个我们还准备了4台机器做扩容以免数据量暴涨集群支撑不了。TiDB版本选择v4.0.14,架构图如下:
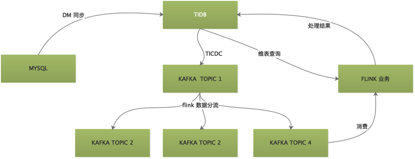
红包摇一摇业务:
TIDB在整个业务中需要作为数据源、实时计算维表和实时计算结果存储引擎三个角色。TIDB通过TICDC将数据实时推送到KAFKA中,为了保证TICDC稳定高效,我们为TIDB中的每个库创建了一个TICDC任务,将数据实时推送到指定KAFKA中,然后FLINK负责将同一个TOPIC中的属于不同库表的数据进行解析,分流到库表对应的TOPIC中,提供给实时计算业务使用。实时计算任务消费KAFKA中的TIDB数据进行业务逻辑计算,同时还需要从TIDB中查询对应的维度数据,最终将计算结果再输出到TIDB中。具体架构图如下:
5.遇到的问题及解决方案
1)4.0.12版本bug
前期测试期间,最初tidb的版本采用的是v4.0.12,总是收到increase(tidb_server_panic_total[10m]) > 0的警告,通过查看tidb server的日志发现有大量的analyze worker panic的错误日志,具体信息如下:
[ 2021 / 08 / 11 17 : 29 : 03.989 + 08 : 00 ] [ERROR] [update.go: 796 ] [ "[stats] auto analyze failed" ] [sql = "analyze table %n.%n" ] [cost_time = 4.247917467s ] [error = "analyze worker panic" ]
[ 2021 / 08 / 11 17 : 29 : 07.872 + 08 : 00 ] [ERROR] [analyze.go: 172 ] [ "analyze worker panicked" ] [stack = "goroutine 20458702777 [running]:\"ngithub.com / pingcap / tidb / executor.
经过官方小伙伴的确认,此报错为v4.0.12的bug #20874,当集群配置了new_collations_enabled_on_first_bootstrap: True新的排序规则后此bug会出现。
解决方案:升级版本,跟研发同学确认升级时间后,将tidb集群版本升级到v4.0.14,解决此问题,
2)执行计划变化
818晚会期间集群慢日志中出了一个慢sql,如下:
SELECT id, report_dt, user_id, avatarpath, interact_type, reward_type_id, show_name, reward_name, city_name, winning_create_time, winning_time_str, create_time, update_time, version
FROM table_name
WHERE report_dt = ‘’ AND reward_type_id = ‘’ ORDER BY winning_create_time DESC LIMIT 1;
执行时长:
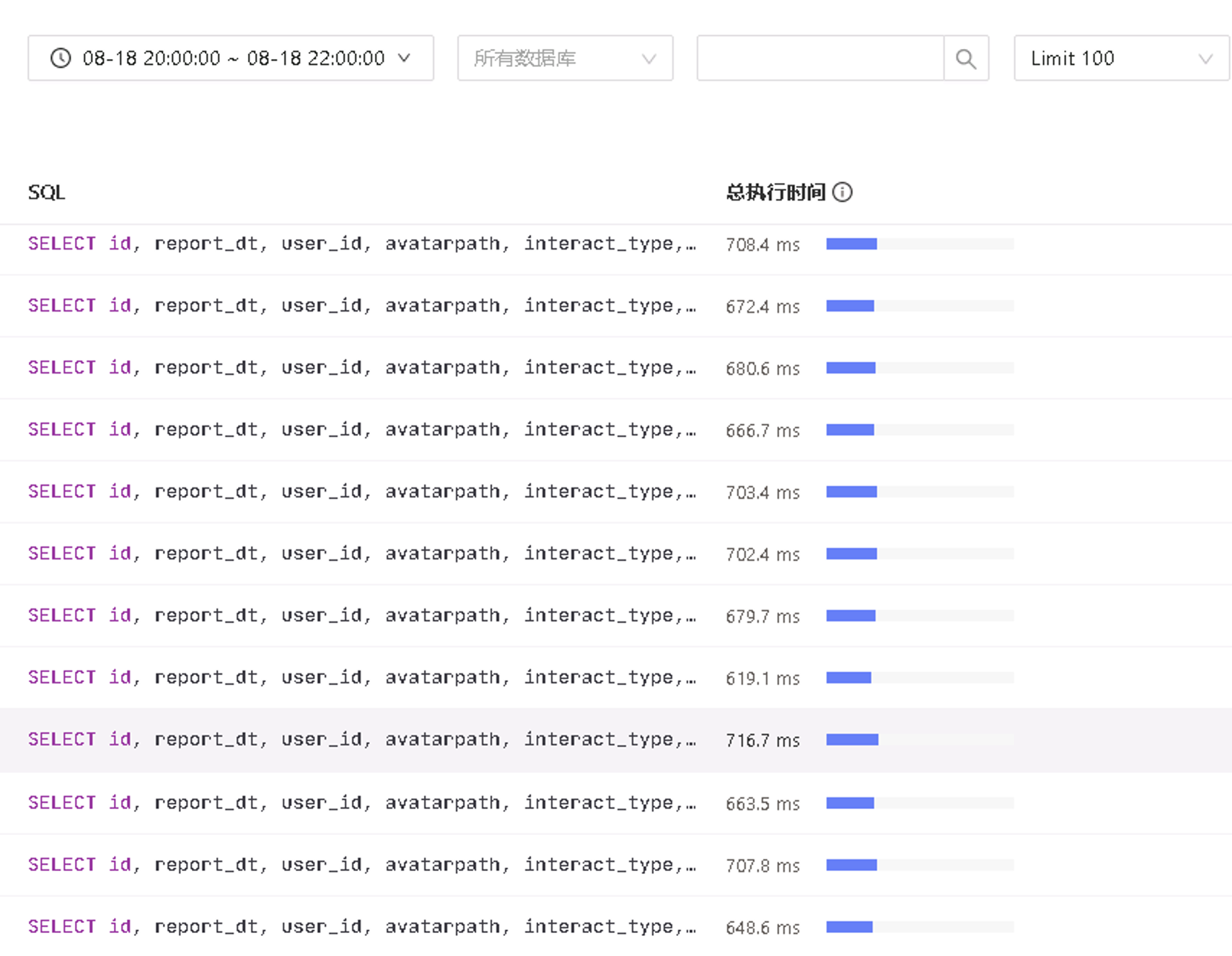
通过查看执行计划发现活动最开始的一小时此查询走的是单字段winning_create_timep索引的IndexFullScan,随着活动期间数据量越来越多,执行计划变为TableScan,定位问题流程如下:
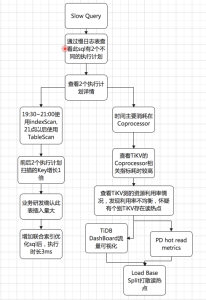
通过查看执行计划各环节的耗时发现SQL的等待耗时主要集中在TiKV侧的coprocessor,并且SQL扫描了大量的Key,从21点开始该SQL扫描的Key数量是之前的2倍,跟业务研发确认此表插入量比较大。通过查看TiDB侧监控发现TiKV侧Coprocessor相关指标耗时高;再接着查TiKV侧的Unified read pool CPU、Coprocessor Detail→Wait duration、Coprocessor Handle duration的监控发现个别TiKV资源利用率高,怀疑有读热点;通过查看TiDB DashBoard流量可视化流量部分可以看到明显的读热点现象,PD监控的hot read显示每个TiKV交替出现读热点:

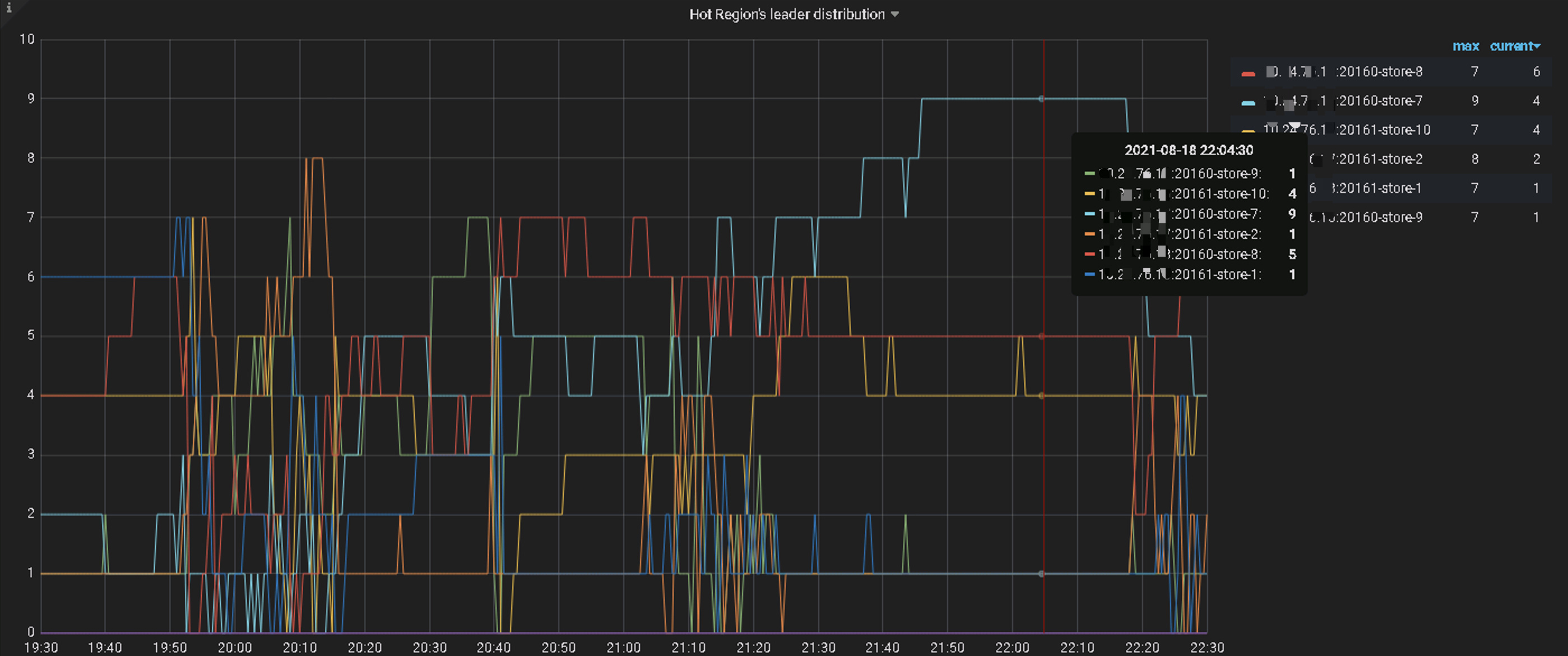

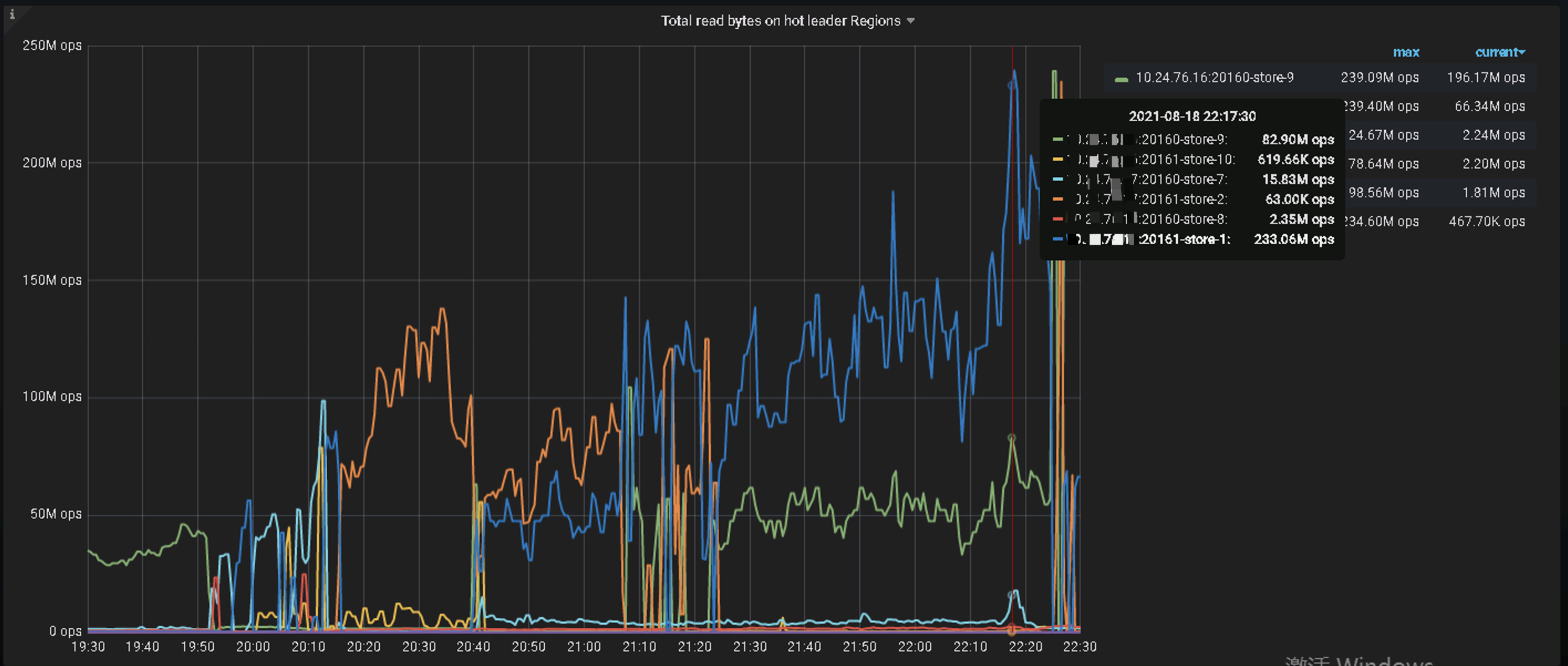
解决方案:
a.使用Load Base Split打散读热点
b.添加联合索引
3)TiCDC遇到的问题及需要注意的点
a.报错1:Error: [CDC:ErrKafkaNewSaramaProducer]dial tcp 64.70.19.203:9092: i/o timeout,是由于TiCDC的命令行中kafka的地址只写了一个,TiCDC找不到kafka的地址,解决办法:把kafka集群的3个ip都添加到命令行后此问题解决
b.业务研发要求kafka接入的数据必须是canal格式,否则不能正常使用,这里需要在命令行设置protocol=canal-json,并且配置文件中配置enable-old-value=true
c.报错2:CDC:ErrKafkaAsyncSendMessage]kafka: Failed to produce message to topic bigdata_test: kafka server: Message was too large, server rejected it to avoid allocation error.此报错是因为kafka接收的单次数据过大不能写入的,解决办法:修改发送消息的最大数据量为1M,max-message-bytes=1048576
d.研发反馈数据只能分发到一个kafka分区,解决方案:以rowid做hash计算做并行分发,问题解决
主要配置文件及ticdc同步命令如下:
# test.conf ticdc配置文件
enable - old - value = true
[ filter ]
rules = [ 'bigdata_test.*' ]
[sink]
dispatchers = [
{matcher = [ 'bigdata_test.*' ,], dispatcher = "rowid" },
]
同步命令:
tiup ctl:v4. 0.14 cdc changefeed create - - pd = http: / / 10.20 . 20.20 : 2379 - - sink - uri = "kafka://10.10.10.1:9092,10.10.10.2:9092,10.10.10.3:9092/bigdatatest?kafka-version=2.6.1&partition-num=3&max-message-bytes=1048576&replication-factor=1&protocol=canal-json" - - changefeed - id = "bigdata_test" - - config = / home / tidb / cdc_conf / test.conf
6.性能表现
TiDB集群运行稳定
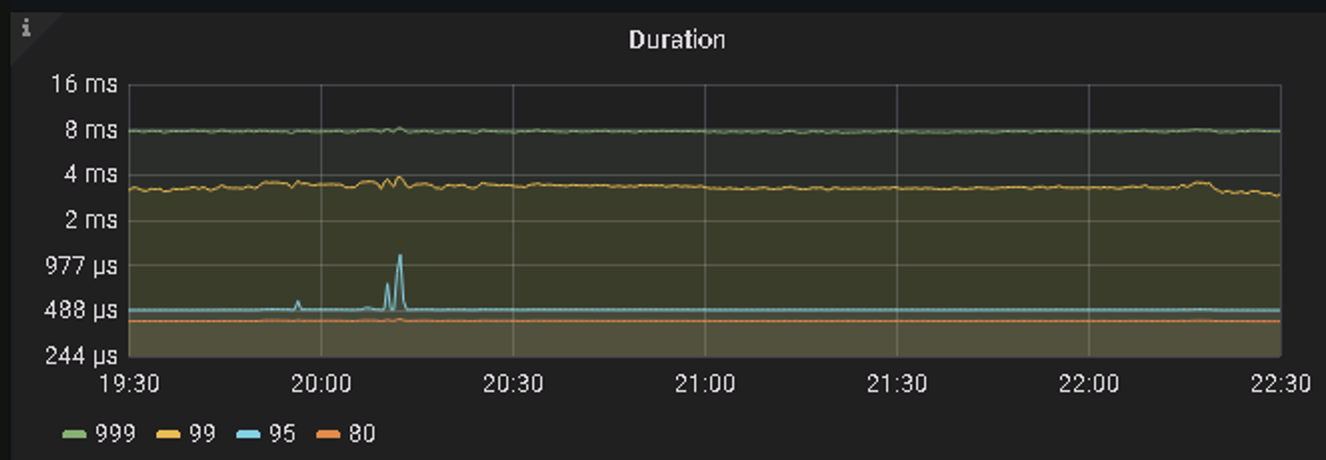
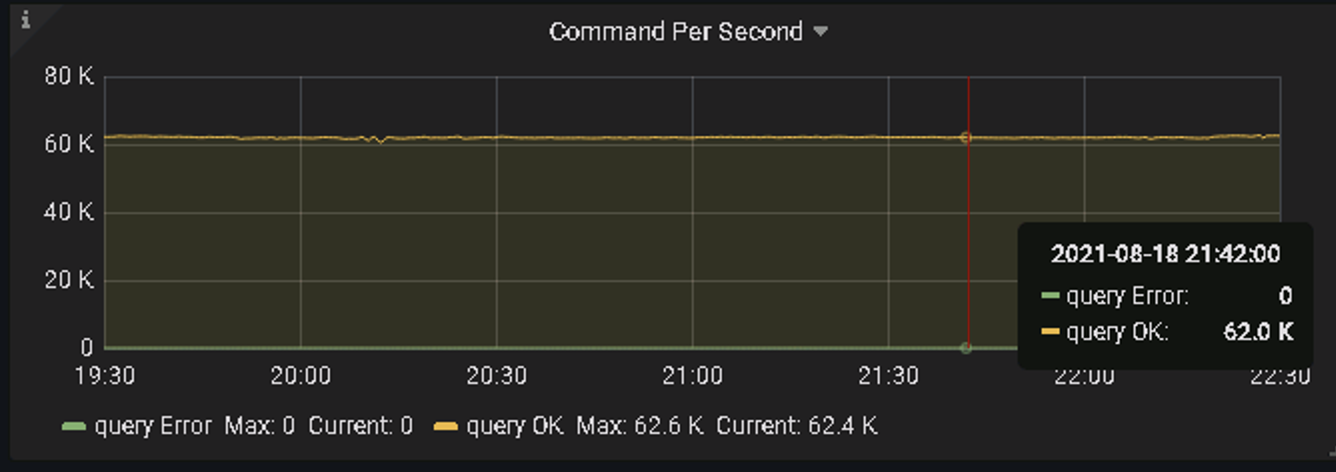
- 818汽车狂欢数据看板业务SQL 999在8ms以内,SQL 99在3ms左右,qps达到62k
2)红包摇一摇灾备业务:TiCDC在前期压测期间,单表数据向下游kafka分发会有同步延迟情况,多表数据同步向下游kafka分发延迟可以忽略不计。818晚会期间为多表分发,未出现延迟。
7.改进计划与建议
818过后,易车要实行去sqlserver计划,其中会有部分数据量较大业务将由sqlserver迁移到TiDB,比如新闻、粉丝、IM等,有了前期的经验对于后续业务的使用也提供了一些改进计划:
a.表的自增主键AUTO_INCREMENT修改为AUTO_RANDOM随机主键,AUTO_RANDOM(n) n的值设置越大则打散的程度越大,默认值为5。此属性可以避免写入热点。
b.主键索引最好使用聚簇索引,聚簇索引与非聚簇索引在存储上的区别为:
聚簇索引:
主键列数据库(键)--行数据(值)
非聚簇索引:
tidb rowid(键) – 行数据(值)
主键列数据(键值) – __tidb_rowid(值)
聚簇索引的性能和吞吐量都有较大优势,插入数据或根据主键查询数据时会减少一次或多次网络连接。
c.JDBC连接器要使用较新版本,否则程序端会报Coult not retrieve transaction read-only status from server的问题。JDBC连接时需要设置userConfigs=maxPerformance来避免额外开销。
d.建议官方在TiCDC单表数据向下游同步的延迟问题方面做进一步改进。
8.感谢
非常感谢高振娇、王晓阳、苏丹、东玫等PingCAP小伙伴多次到场支持,提出了很多切实可用的调优建议,帮助解决了前期测试当中遇到的问题和Bug,并于818当天晚会期间现场支持,在此表示最衷心的感谢。