

本文根据路希在【PingCAP DevCon 2021】上的演讲整理而成。
- 视频回顾: https://www.bilibili.com/video/BV17A411P7vj
- 讲义下载: 爱奇艺-路希-TiDB 在爱奇艺实时分析场景的应用实践.pdf (959.7 KB)
随着业务的规模化发展, 数据实时处理的能力成为了限制企业数据变现的重要关口之一 。本文结合爱奇艺在实时分析场景的实践经验,分享了传统实时分析架构的不足,以及 TiDB 在安全风控和 BI 运营分析系统中部署的经验,最后介绍了 TiDB 5.0 版本在订单交易系统中的测试结果和对未来的展望。
与 TiDB 携手的五年
爱奇艺早在 2017 年就和 TiDB 结缘。随着爱奇艺业务规模的不断地扩大,MySQL 单机性能和容量的瓶颈越来越明显,急需一款分布式兼容 MySQL 协议的数据库,TiDB 的出现让我们看到了曙光。TiDB 作为一款分布式 NewSQL 数据库 具备水平的弹性扩展能力,支持 ACID 事务,同时兼容 MySQL 协议 ,这就是我们所渴望的数据库。
在 2017 年年中,我们开始对 TiDB 进行调研和测试,并陆续在测试环境以及内部系统上线了 TiDB 集群。在随后的几年中,TiDB 每一个新版本的发布都给我们带来了不同的惊喜,我们也紧跟着 TiDB 社区的步伐及时地对新版本进行测试,同时也对线上的集群进行同步升级。
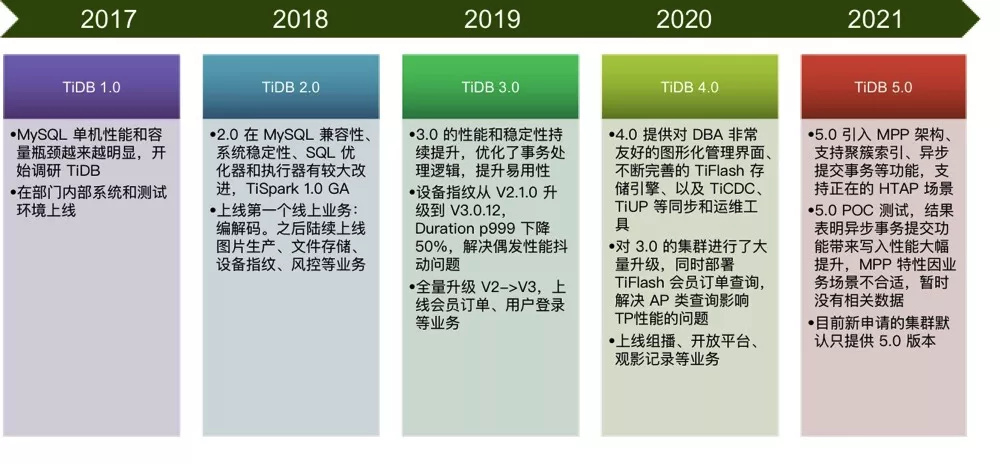
截至目前,已经有大量的 TiDB 集群支撑着爱奇艺各条业务线的稳定运行,这要感谢 PingCAP 同学们对我们及时的响应和支持。历经五年的时间, 爱奇艺内部 TiDB 集群的规模已经超过 500 台服务器,总计有 100 多个 TiDB 集群服务 30 多条业务线 。

传统实时分析架构的痛点
谈到实时分析不得不提到当前比较经典的两个架构,一个是 Lambda 架构,另外一个就是 Kappa 架构。
Lambda 架构的主要思路就是在离线数仓的基础上加上实时数仓。 离线数仓作为批处理层,而实时数仓作为速度层。实时数仓里面的数据存储在 Kafka 里面,通过像 Flink、Spark Streaming 这样的计算引擎对数据进行计算,把离线批处理层和实时数据进行汇总,再将数据存到 MySQL、Redis 应用层数据库中,供业务进行查询和展示。
Kappa 架构其实是在 Lambda 架构的基础上去掉了离线数仓的部分,只保留了实时数仓,通过调整 Kafka 中数据的保留期将历史数据进行留存。 如果说我们要对离线数据进行重新处理的话,那就要去重置 Kafka 日志消费的偏移量,然后再对数据进行重新计算,最终计算的结果也是存储到 MySQL 或者是 Redis 这些应用层数据库中,供业务进行查询和展示。
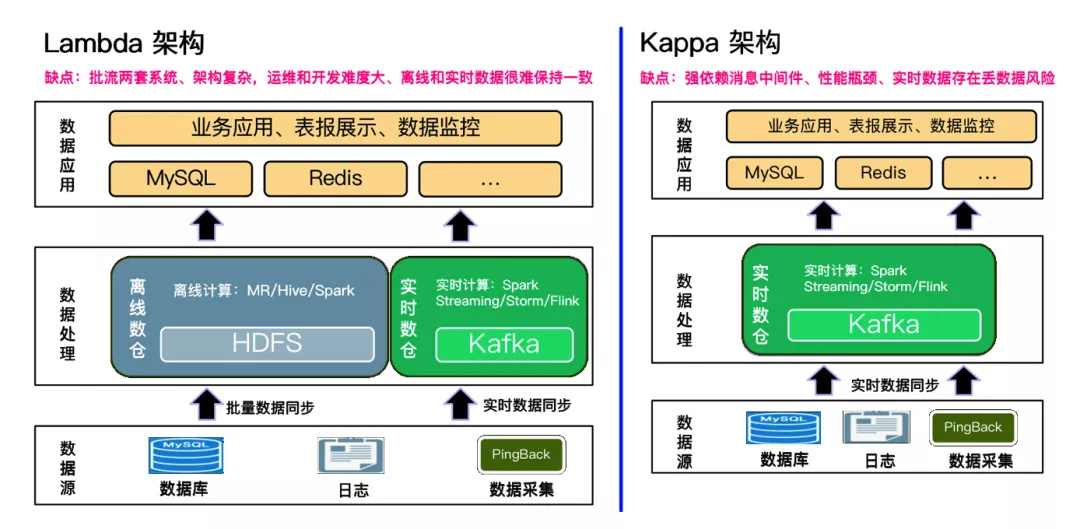
虽然这两种架构是经典的,但这两种架构还是存在不同的痛点: Lambda 架构相对来说比较复杂 ,需要去维护流、批两套系统,对于运维和开发人员来说难度相对比较大,离线数据和实时数据也很难保持一致; 对于 Kappa 架构来说,它对消息中间件是强依赖的 ,这就注定其性能是有瓶颈的,另外,这个架构下还存在丢数据的风险。
TiDB 在安全风控和 BI 运营系统中的应用
了解 Lambda 和 Kappa 架构现存的一些痛点后,再来看看爱奇艺在实际应用中如何使用 TiDB 来做分析。
首先是爱奇艺内部的安全风控数据服务系统,它主要的功能是提供统一的标签服务, 类似于一个风控系统的数据仓库 ,并且需要满足 OLTP 和 OLAP 两类查询。标签的实时数据写入并存在 TiDB 里面,然后通过解析 Binglog 的方式或是通过手动触发的方式支持标签上浮,存储到服务层的 Cache 里面,用风控引擎进行一些实时的查询。ETL 模块通过跑 Spark job 的方式把 TiDB 的数据放到 Hive 里面,确保 TiDB 和 Hive 里面都存有全量的数据。
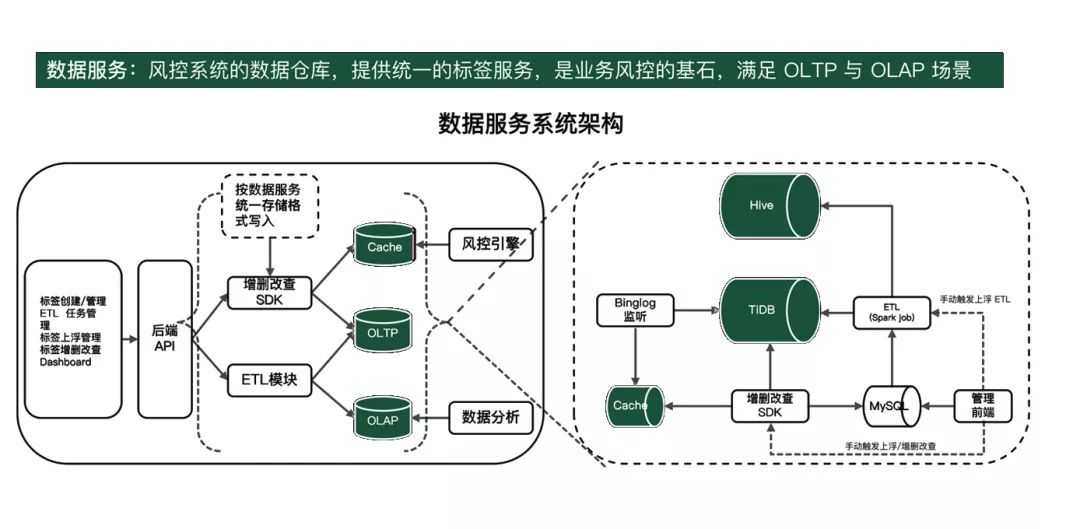
下面是安全风控系统中 TiDB 的部署架构。通过 TiSpark SQL 将 TiDB 中的标签数据存入 Hive ,用来支持离线的 OLAP 数据分析,TiDB 支持 OLTP 类场景的查询。可以看出这种架构和 Lambda 架构是有些类似,也存在一定的缺陷,架构稍显复杂,对 Hive 有依赖,同时还需要维护两边数据的一致性。

BI 运营系统主要目的是帮助运营人员去分析站内剧集上线后的综合表现,包括流量、导流、收入以及质量等,对多个维度的数据进行统计分析。这个系统的主要功能是提供站内榜单的监测、剧集详情查询、内容质量分析以及剧集的对比等。
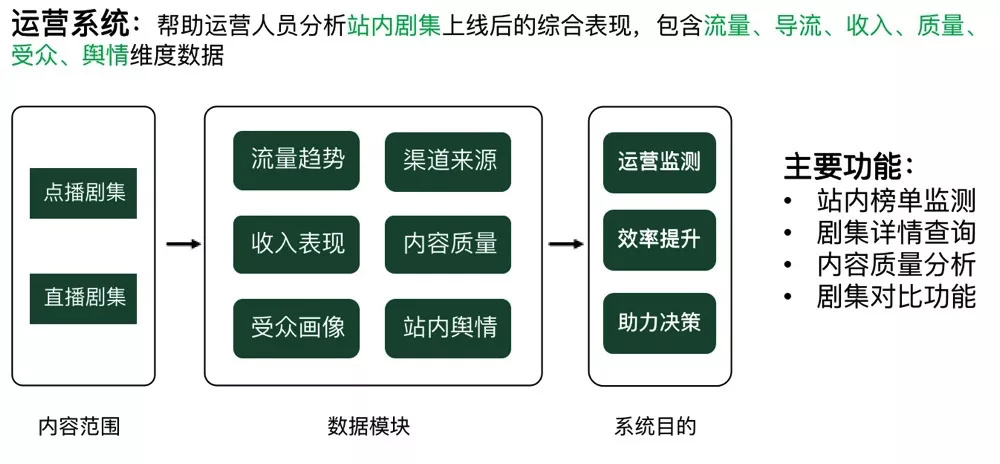
这是 BI 运营系统场景下 TiDB 的部署架构图,可以看到 BI 运营系统的数据源来自内部的内容数仓以及用户画像的数据,通过 Spark 和 Hive 的清洗存到服务层,比如 ClickHouse 和 TiDB 里面。TiDB 负责详情页的查询,为某专辑或者是视频展示详细的统计数据,数据可以展示每日的详情,也可以展示该时段的实时数据统计。该系统目前的数据量比较大,大概有十几个 T,TiDB 不但要满足 OLAP 类的查询,还需要满足 OLTP 类的查询。

先前我们部署了一个 TiKV 集群,发现上面跑的 OLAP 类的查询会影响到 OLTP 的查询,后来我们又部署了一个三节点的 TiFlash 集群。业务 SQL 方面,通过加 hint 的方式,把查询 SQL 打到 TiFlash 集群上。通过这个改造升级,OLAP 类的查询和 OLTP 的查询互相没有干扰,同时 OLAP 查询的性能也有一定的提升。
TiDB 5.0 测试情况
今年 4 月 TiDB 发布了 5.0 版本,相较于 4.0 版本, 5.0 版本新增了 TiFlash MPP 、异步事务提交、聚簇索引等一系列新特性。 经过和 PingCAP 同学的沟通交流,我们启动了对 TiDB 5.0 的 POC 测试。爱奇艺内部有一个订单交易系统,架构如图所示,通过 sharding jdbc 把 MySQL 分为了 16 个分库,然后再通过内部的数据同步工具把 16 个分库里面的数据汇总到 TokuDB、MongoDB 和 TiDB 中。TokuDB 主要是为 BI 提供抽数用的,TiDB 是提供运营后台的查询统计分析以及订单历史的查询,前端 16 个分库的 MySQL 主要是支持实时的交易系统。

我们在 TiDB 4.0 的使用过程中存在一些痛点,例如在非 UID 维度查询的情况下效率偏低,不能满足业务的需求。同时 TiFlash 的效率不是很高,因此使用率也高。目前 BI 是从 TokuDB 里面抽数的,但我们希望 BI 后续可以从 TiDB 里面抽数,这样的话,就可以把 TokuDB 省掉,减少整个架构的复杂度。此外,订单交易系统中的 MongoDB 是为一个较老的运营后台提供查询使用的,我们也希望使用 TiDB 来进行替换。
为了解决业务的痛点,我们制定了相应的测试目标。 首先是要满足业务 HTAP 的查询需求 ,并且在不影响实时业务的场景下,实现 BI 从 TiDB 里面去抽数。第二,评估 TiDB 5.0 的性能, 在不增加机器的情况下,提升写入的性能 。我们陆续进行了基准测试,新特性测试以及业务 SQL 的测试。
这里列了部分的测试结果数据。 在基准测试方面,我们做了 Sysbench、TPC-C、TPC-H 等测试,总体来说,TiDB 5.0 的性能比 4.0 有大幅的提升。 比如在 TPC-C 超高并发(500)下,平均执行的延迟降低超过 50%,毛刺基本消除了。异步提交事务开启的情况下,SQL 的平均延迟降低了 40% 以上,写入的 QPS 也提升了 70%。此外,测试业务的 SQL 性能也提升了 20% 到 40% 不等。

因为数据量和业务场景的关系,我们在测试中没有用到 MPP 的特性。同时 BI 的抽数也没有走 TiFlash,还是走了 TiKV,这和测试之前的制定的目标不太一样。后续,我们还会评估和验证 TiDB 5.0 在 BI 抽数的场景中,走 TiKV 抽数的情况下对业务 SQL 的影响。
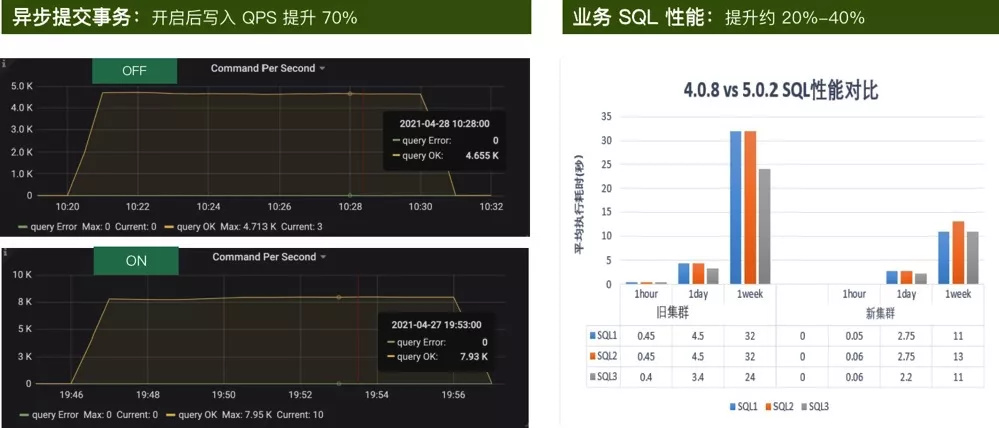
整体来说 TiDB 5.0 的性能提升是有目共睹的,并且支持真正的 Real Time HTAP 场景, 目前爱奇艺线上的轻集群已经升级到了 TiDB 5.0 版本。
未来展望
最后是对 TiDB 的展望。首先是大事务场景下,集群有时会出现性能抖动或者是 OOM 的问题。第二是 BR 备份带来额外的负载,不太容易控制。第三就是索引统计信息不及时或者缺失导致执行计划错误或者不稳定,目前我们是采用跑定时任务的方式去做索引信息的统计。希望 TiDB 后续的版本在这几个方面可以有更大的提升。
未来,爱奇艺先是会推动业务尝试 TiFlash MPP 架构来落地 HTAP 场景,降低业务架构的复杂度, 就像刚才讲到的风控系统,后续计划升级到 TiDB 5.0,去除对 Hive 的依赖。 我们还将持续推进云原生的建设,进一步提高资源的利用率。