

本文系上海 TUG “TiDB+Cloud” 活动演讲实录整理而成,作者:上海 TUG Co-Leader 王志广

TiDB Operator 是 Kubernetes 上的 TiDB 集群自动运维系统,提供包括部署、升级、扩缩容、备份恢复、配置变更的 TiDB 全生命周期管理。借助 TiDB Operator,TiDB 可以无缝运行在公有云或私有部署的 Kubernetes 集群上。现在分享另外一种有别于官方的 TiDB 容器化解决方案。
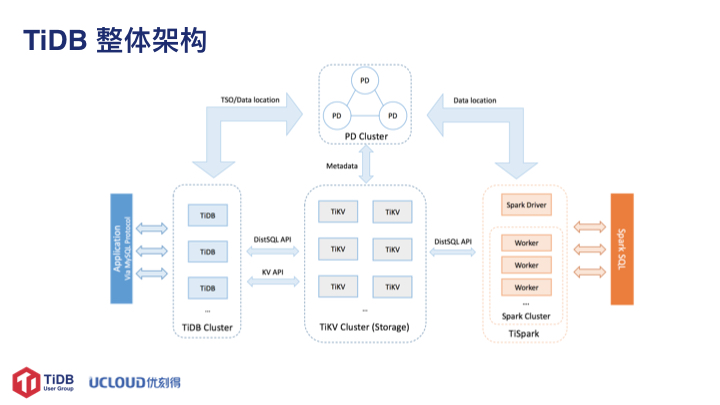
上图是 TiDB 的整体架构。TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件。从架构图中可以看出 TiDB 作为分布式数据库,其结构是相对复杂的。而分布式系统本身的复杂性引起手工部署和运维的成本是比较高的,并且容易出错。传统的自动化部署运维工具如 Puppet / Chef / SaltStack / Ansible 等,由于缺乏状态管理,在节点出现问题时不能及时自动完成故障转移,需要运维人员人工干预。有些则需要写大量的 DSL 甚至与 Shell 脚本一起混合使用,可移植性较差,维护成本比较高。

TiDB 在生产中有以下需求:1、快速部署;2、动态容量调整;3、提高资源使用率;4、自动化运维的要求。这些也是 TiDB 容器化的必然性的结果,同样其他数据库也有类似的要求。
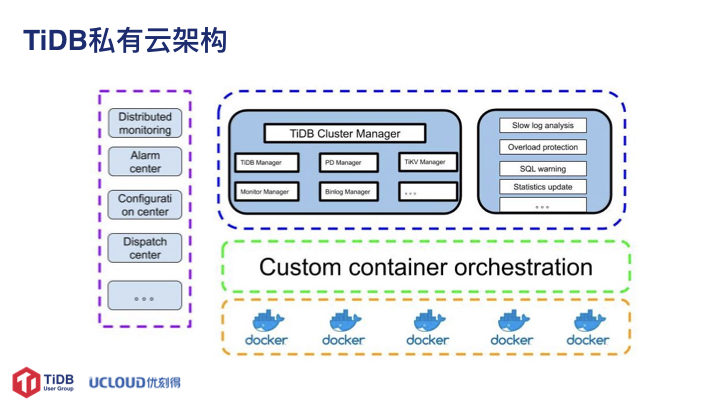
针对上述的需求,我们开发了 TiDB 的私有云。从图中可以看出,最底层是基础的容器环境,中间是自研的容器管理系统,为什么自研容器管理系统将在下面讲解。再上一层是针对 TiDB 的特性和实际使用中遇到的问题点,针对性地设计了 TiDB 的编排、统一管理、辅助系统等。最左边是通用的一些系统如分布式监控系统、告警中心、配置中心、调度中心。
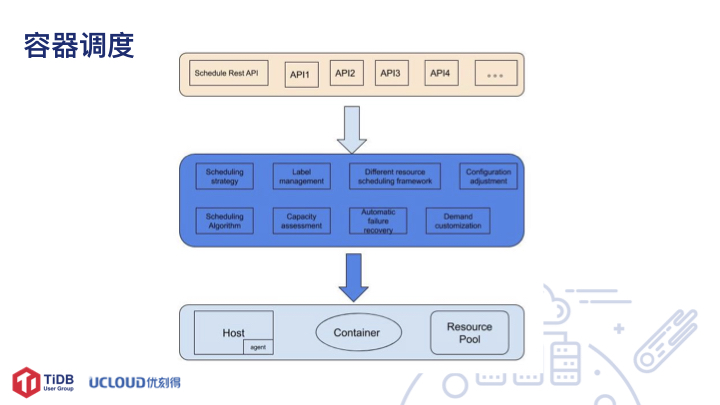
Kuberbetes 曾是我们容器调度的首选解决方案,但 TiDB 作为数据库服务需要将数据库存储到本地磁盘,在当时 Kuberbetes 对 Local Storage 是不支持的。针对 TiDB 的特性和业务需求,我们决定自己实现一套容器编排系统,实现如下功能:
支持 LocalStorage,解决数据存储问题
基于 cpuset-cpus 实现 CPU 资源的随机均衡分配
定制化,支持 label,实现特定服务运行在特定宿主机上
容器的主动发现和通知,以便将之前未管理的宿主机接入统一管理
容器的全生命周期的管理
容器异常的修复和通知
容量规划
不同类型资源的调度
…

调度的基本是:主机和容器的过滤、策略选择。过滤器分为主机和容器。通过对主机的可用性、标签、分组来筛选合适的主机资源;通过对容器的亲和性和反亲和性进一步的过滤主机资源。调度的核心策略是通过对筛选后的主机的内存和不同属性的容器数量进行打分,剔除资源不足的主机。为什么只针对内存来计算?通过对线上服务器资源的统计分析,各个服务器的 CPU 是充裕的,资源不足的瓶颈主要是是内存。调度的算法相对简单,就是将评分后的合适的主机按照评分从高到低排列。
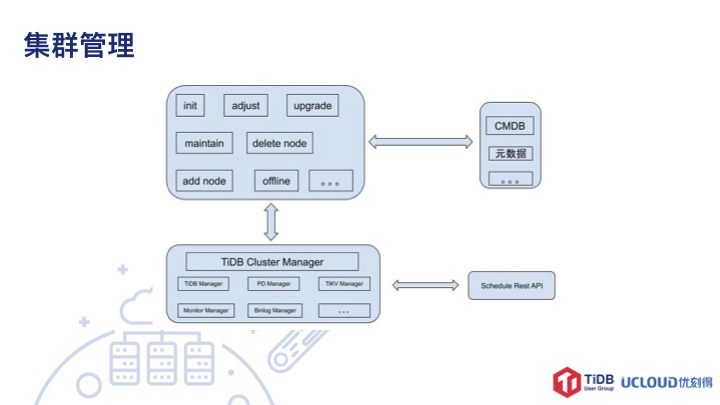
因为是自研的容器管理系统,所以集群管理的模块不同于 Kuberbetes Operator 的实现。整个集群的管理包含了以下几个模块:日常操作模块、类似 TiDB Operator 的集群管理模块、与其他系统(如:CMDB、元数据、统一配置等)交互模块、与自研容器管理系统交互模块。其中日常模块包含了初始化、调整、升级、维护、离线、节点调整等功能;集群管理模块封装了针对 TiDB 集群、各个节点:TiDB、TiKV、PD、Binlog、Monitor的编排功能。

编排的算法和策略遵循以下规则:同一类型:FIFO;不同类型:亲和性、反亲和性、依赖性;各个节点的编排顺序:TIKV>TiDB(应用)>PD>TiDB(其他)>Pump>Drainerz>DM,为什么 TiDB 有不同的标签?在实际使用中会针对不同的需求分配不同的TiDB来满足特定需求
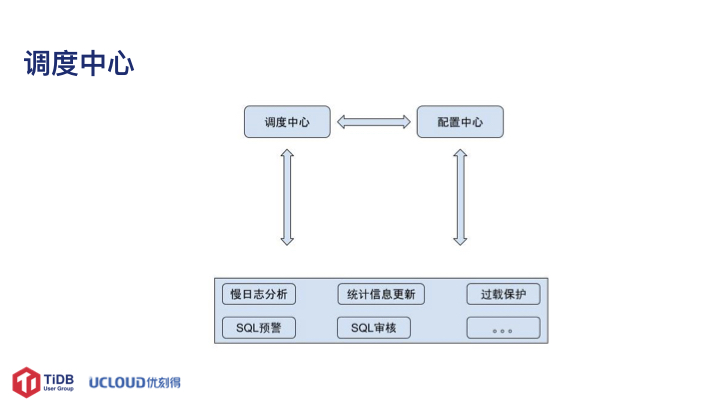
调度中心是另外的一个核心功能模块,通过与配置中心的结合,实现诸如慢日志分析、统计信息更新、过载保护、SQL 预警、SQL 审核等功能
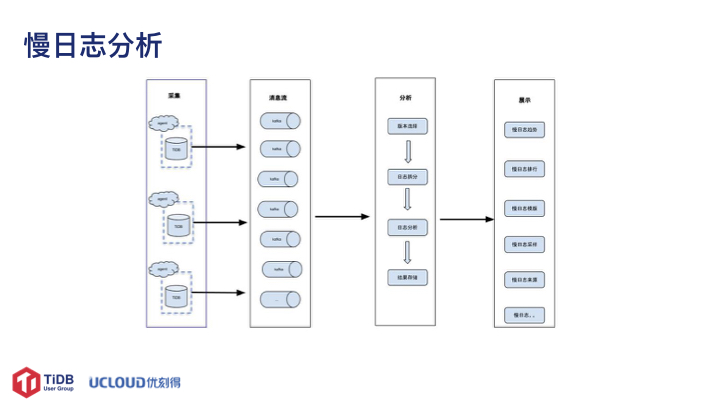
慢日志分析这块的功能架构和大家常见 MySQL 慢查询分析架构类似。配置中心和调度中心判断那些 TiDB 的节点需要收集慢日志信息。通过对 Filebeat 的二次开发,使其元数据的系统互通将慢日志信息增加集群的基础信息;数据分析时会先进行版本的判断,然后选择合适的日志拆分器、做版本判断的原因是在 TiDB 2.1.8 之前慢日志格式每个版本都是不同,故需要开发不同的日志拆分器满足不同版本的慢日志分析需求。
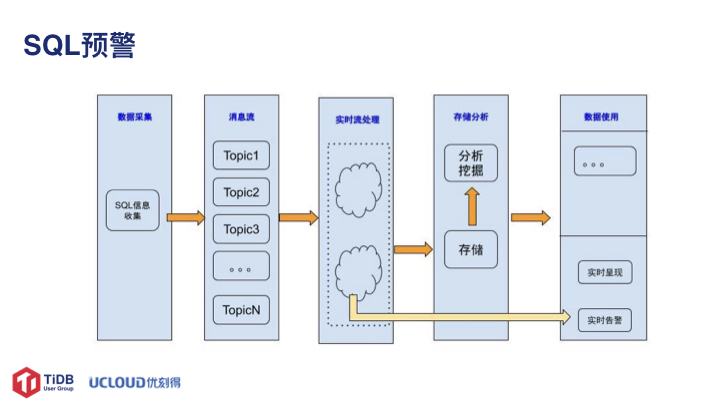
SQL 信息包含两块:慢查询 SQL 和全量 SQL。慢查询 SQL 通过慢日志分析流程将结果存储到 kafka 集群。对全量日志的收集分为两种模式:基于 360 mysql-Sniffer 和修改 TiDB 源码。基于 mysql-sniffer 的方式存在信息收集不全等问题;实际使用时主要通过对 TiDB 的源码修改来实现。
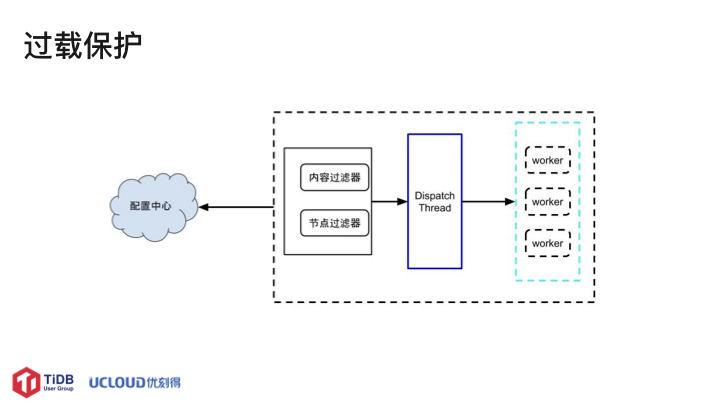
过载保护和统计信息更新架构类似,这里主要讲下过载保护。过载保护的功能在最新版的 TiDB 有实现类似。通过内容过滤器和节点过滤在需要的节点上运行过载保护程序,以满足日常的绝大部分需求。
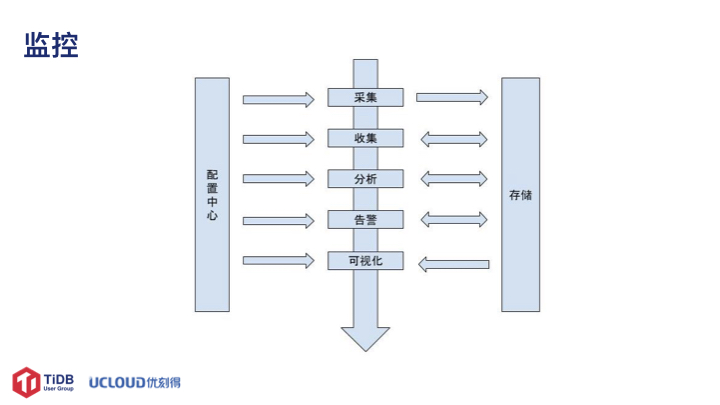
监控数据的采集一部分依赖于现有监控系统中的数据,如 zabbix 之类;一部分通过 TiDB 的 API 获取,一部分是开源的收集器。因采集方式的不同导致原始数据存储在不同类型的数据库,通过开发的同步工具,将上述数据同步独立部署的 TiDB 集群,以便后续的数据分析。可视化的实现主要基于 grafana 来完成。告警模块针对 TiDB 需求进行开发和实现的,并将告警信息推送到部门统一的告警中心。
如果你对王志广老师的分享有任何疑问或是想与作者交流,都欢迎在评论区留言哦~