

【是否原创】是
【首发渠道】TiDB 社区 or 其他平台
【首发渠道链接】其他平台首发请附上对应链接
【目录】
- 环境配置
- 测试负载及初始结果
- gogc参数优化
- NUMA绑定优化
- 结论
【正文】
1.环境配置
测试使用了三台物理机,每个节点上都部署PD、TiKV和TiDB,并在其中一个节点上部署alertmanager、grafana和prometheus。
| TiDB | TiKV | PD | altertmanager | grafana | prometheus | |
|---|---|---|---|---|---|---|
| node1 | 1 | 1 | 1 | 1 | 1 | 1 |
| node2 | 1 | 1 | 1 | |||
| node3 | 1 | 1 | 1 |
服务器硬件配置:
| 配置 | |
|---|---|
| CPU | Intel Xeon 6252 (24c48t) x 2 |
| 内存 | DDR4 192 GB (16GB x 12) |
| 硬盘 | SATA SSD 800GB x 1 |
NVMe SSD 2TB x 1|
|网络|10 Gbps|
软件配置:
| 配置 | |
|---|---|
| OS | CentOS 8.3.2011 |
| TiDB | V5.1.0 |
参考官方文档,使用tiup安装、配置TiDB集群,确实很方便。
2. 测试负载及初始结果
由于我们测试的主要目的是为了解TiDB对CPU的使用情况。为了排除磁盘I/O对性能的影响,我们选择sysbench oltp_read_only作为测试负载。文档有关于使用Sysbench对TiDB进行测试的介绍。
同时,我们测试使用的数据集也比较小,目的是确保测试过程中数据可以被缓存在操作系统的page cache中,而不需要实际读取磁盘。我们测试使用了30张表,每张表1,000,000条数据。
初始测试时,我们使用了TiDB默认的参数,并且使用sysbench只对其中一个TiDB节点进行测试。得到的Sysbench OLTP_Read_Only结果是 TPS: 4365, QPS: 69838 。
这是我们使用的测试脚本:
sysbench --config-file=sysbench-config oltp_read_only --threads=512 --tables=30 --table-size=1000000 run
sysbench-config文件的配置为:
mysql-host=10.10.10.207
mysql-port=4000
mysql-user=root
mysql-password=p0o9i8u&
mysql-db=sbtest
time=240
report-interval=10
db-driver=mysql
下一步,我们将基于这个配置对性能进行优化。
3. gogc参数优化
使用文档的方法收集火焰图,用来分析程序执行的热点。执行命令:
go-torch -u http://localhost:10080 -t 30 -f tidb_default.svg
得到的火焰图是这样子滴:
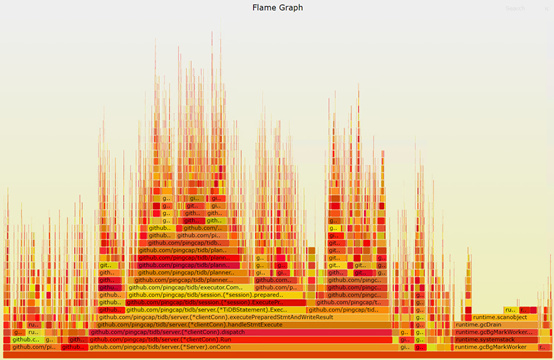
通过火焰图,我们发现runtime.gcBgMarkWorker占比15.33%。通过查阅文档,我们了解到这个函数和golang的gc实现有关。可以通过调整参数gogc的值来优化它,gogc值越大,gc的间隔越长,一般来说可以提升go应用的性能,付出的代价是需要占用更多的内存。使用默认gogc参数(100)时,tidb占用的内存还不到2GB,系统还有大量的空闲内存。因此,尝试增大gogc的值。通过反复试验,发现在我们的测试环境中gogc=1000可以得到比较好的结果,此时TiDB的内存占用大约是16GB。如果设置的值再大,虽然可以少许提高TPS值,但性能的抖动会变的很大。调整gogc参数后,得到的Sysbench OLTP_Read_Only结果是 TPS: 7205, QPS: 115274 ,相比默认配置,性能提升了65%。
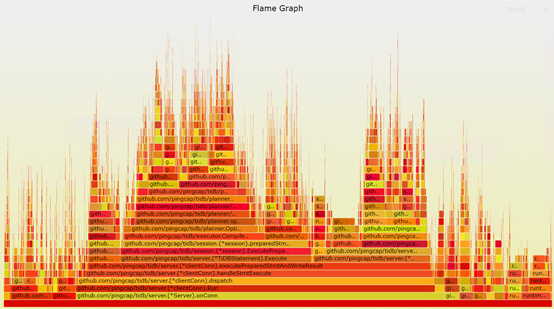
这时的火焰图是下面这样子滴,runtime.gcBgMarkWorker的占比下降到2.43%。
4. NUMA绑定优化
通过我们的分析工具,我们发现TiDB访问local NUMA memory的比例只有50%左右,这说明golang或者TiDB没有对NUMA访问进行优化。由于访问remote NUMA memeory的延时一般是local NUMA memory的1.5倍左右。高比例的remote NUMA memory访问,对内存延时敏感的应用的性能会有较大影响。
因此,我们尝试通过修改TiDB的启动脚本run_tidb.sh,用numactl将TiDB绑定到一个NUMA node上,来观察性能的变化。
我们在run_tidb.sh中添加了 “numactl -N 0”,修改后的脚本,变成了下面这样:
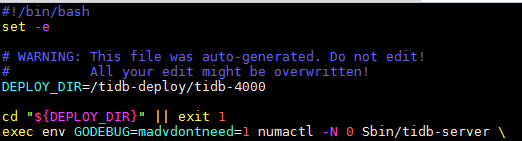
需要说明的是,使用numactl的方式,可以使TiDB对内存的访问全部变成local NUMA memory access,但付出的代价是TiDB只能使用机器上一半的CPU核。
再次使用Sysbench OLTP_Read_Only进行测试,得到的测试结果是 TPS: 8635, QPS: 138154 。相比默认配置,性能提升了98%;相比只调整gogc参数优化的结果,提升了20%。同时,相比只调整gogc参数时,大约85%的cpu利用率,绑定NUMA的方式的cpu利用率降低到69% (虽然TiDB只能使用一半的cpu核,但TiKV、PD、Kernel还可以使用另一半的核)。
再次抓取火焰图,对比之前调整gogc的火焰图,两者基本差不多。
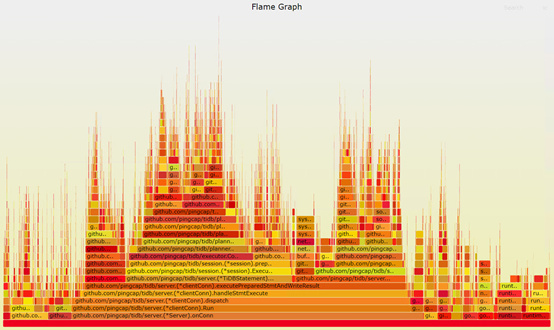
那么有没有函数明显受益于NUMA绑定呢?通过使用perf top抓取运行时的热点,发现在绑定NUMA之前,函数runtime.heapBitsSetType的占比是17.25%。
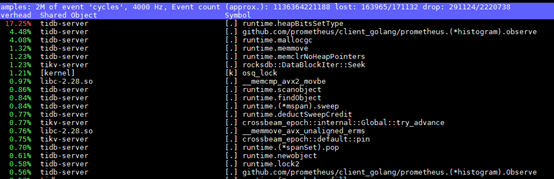
而在绑定NUMA后,runtime.heapBitsSetType的占用降低到6.45%。

这说明runtime.heapBitsSetType函数对NUMA访问非常敏感。它应该是TiDB性能无法在多Socket架构上进行扩展的一个关键因素。
这个问题在火焰图中看不出来,是因为在火焰图中runtime.heapBitsSetType的占比没有按照汇总的方式统计,它被分散在了62个不同的地方,每处的占比都很小,导致没有被发现。
5. 结论
通过这次的优化实践,我们发现调整gogc参数和进行NUMA绑定,能够提升TiDB的性能。因此,一个比较好的部署方式是在一台两路的服务器上部署两个TiDB实例,每个TiDB实例部署在一个Socket上以获得更好的性能。
此外,如何优化runtime.heapBitsSetType方法,使之对NUMA访问友好,从而使TiDB能够在多Socket架构上进行性能扩展,还需要做进一步的研究。
参考文档:
- 如何做TiDB BenchmarkSQL测试: 如何做 TiDB BenchmarkSQL 测试
- TiDB 性能测试最佳实践:TiDB 性能测试最佳实践
- 如何用sysbench测试TiDB: https://docs.pingcap.com/zh/tidb/dev/benchmark-tidb-using-sysbench