

1. 背景
数据库监控作为数据库配套建设不可或缺的一环,可以及时发现机器和数据库性能问题,并帮助止损。伴鱼早期借助开源prometheus系统对数据库和机器进行监控,来满足我们日常的监控告警需求,但在这过程中,我们还是发现一些使用不太方便的地方,主要体现在以下几个方面:
- 数据库以集群为单位,集群成员的变动需要修改prometheus对应的监控配置文件,无法自动修改
- 机器指标和数据库指标采集分属不同的exporter,难以以集群和机器维度同时展示两类指标
- 集群或机器告警配置差异化以及告警时间段抑制,配置不太灵活
- 日常巡检和监控大盘难以定制
基于以上监控告警需求,并结合在对prometheus、阿里云数据库监控等一些优秀的监控系统架构调研的基础上,设计了伴鱼数据库监控系统。相比其它监控系统,新系统包含以下核心功能:
- 基于集群维度的机器和数据库指标采集,集群成员变动,无需修改配置
- 支持集群和机器维度的机器指标和数据库性能指标数据的同时展示
- 通过报警模版,支持报警的差异化配置
- 支持报警时间段抑制和灵活的报警策略
- 灵活定制监控大盘,方便巡检需求
下面从数据库监控整体架构详细介绍下监控各组件设计以及背后设计的一些想法。
2. 监控整体架构
伴鱼数据库监控整体架构,如下图所示。
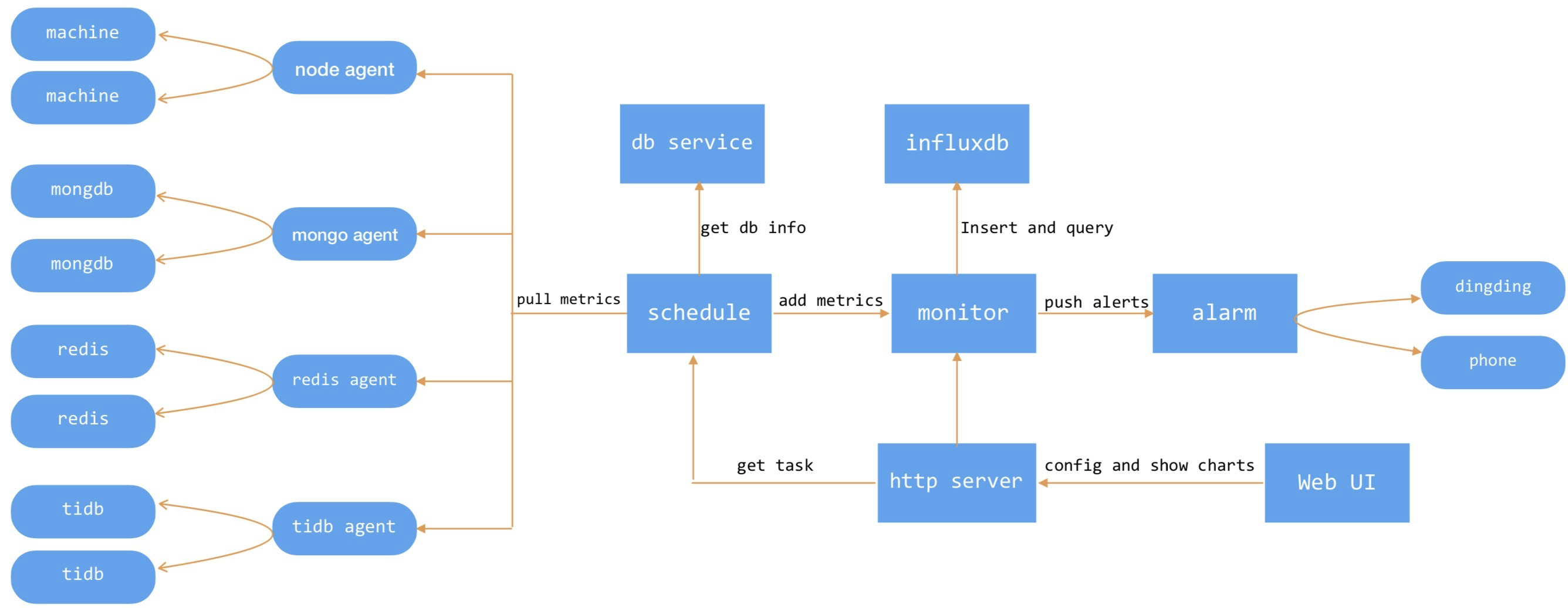
各组件的功能,说明如下:
- agent模块,功能类似prometheus exporter组件,暴露metric接口,接收请求采集数据
- schedule模块,获取监控任务,并根据集群名从db service服务获取具体的集群信息,然后按照监控任务配置的采集时间间隔,定时到对应的agent拉取metrics
- monitor模块,负责监控数据存储/查询、数据分析和规则报警
- alarm模块,公司内部报警服务,支持钉钉和电话报警
- http server模块,负责监控任务、报警模版和报警规则的配置以及监控数据的查询展示
2.1 数据采集
伴鱼的数据库监控,目前主要分数据库服务监控和主机监控两类,对应着数据采集分主机指标采集和数据库性能指标采集两种。监控具体采集哪些指标,我们参照了业界一些优秀开源监控系统,比如阿里云数据库服务监控,来采集我们的监控指标数据。
- 主机指标,包含CPU利用率、磁盘IO使用率、磁盘空间使用率、磁盘空间使用量、机器负载和内存使用率
- Mongodb服务指标,包含连接数、读写队列长度、服务进出流量、游标数量和请求量等
- Redis服务指标,包含内存使用率、请求数、服务进出流量、每秒失效key个数和key查找命中率等
- TiDB服务指标,通过读取tidb自带的prometheus获取数据,目前获取的指标包含raft-store cpu、comprocessor cpu和durition等
针对具体的数据采集,我们设计了四种agent,其中node agent负责采集机器指标数据,因为机器某些指标采集需要在本机执行系统命令,所以node agent在机器初始化时部署。数据库服务agent部署在公司内部的k8s容器内,多副本方式,支持采集指标动态添加。比如TiDB指标的采集,如下图所示,如果想增加某个指标采集,只需动态添加对应的指标项和查询语句即可。

2.2 任务调度
schedule任务调度模块负责监控任务的调度执行,如下图所示。程序在启动时加载监控任务,在指定采集时间间隔,通过集群名称从db service获取对应的集群信息(包括ip、端口和集群角色),调度对应的任务执行metric信息采集。每个集群任务成功采集后,会通知monitor模块进行报警分析。
2.3 数据存储
监控数据存储我们选用了当前流行的时序数据库InfluxDB,主要基于以下几点考虑:
- InfluxDB部署简单,无需任何外部依赖即可独立部署
- 提供类似于SQL的查询语言,接口友好,使用方便
- 提供灵活的数据保存策略(Retention Policy)来设置数据的保留时间
- 高性能写入,最新的数据都保存在内存中,标签允许对列进行索引实现快速查询
2.4 报警规则
通过监控任务,灵活配置数据采集时间间隔,在采集到监控数据后,我们可以做细粒度的报警策略。报警规则如何设计,我们做了如下考虑:
- 集群报警配置应尽可能简单
- 集群报警支持差异化配置
- 报警粒度灵活配置
基于以上要求,我们从报警模版、报警指标和报警策略三个方面设计了报警规则。
2.4.1 报警模版
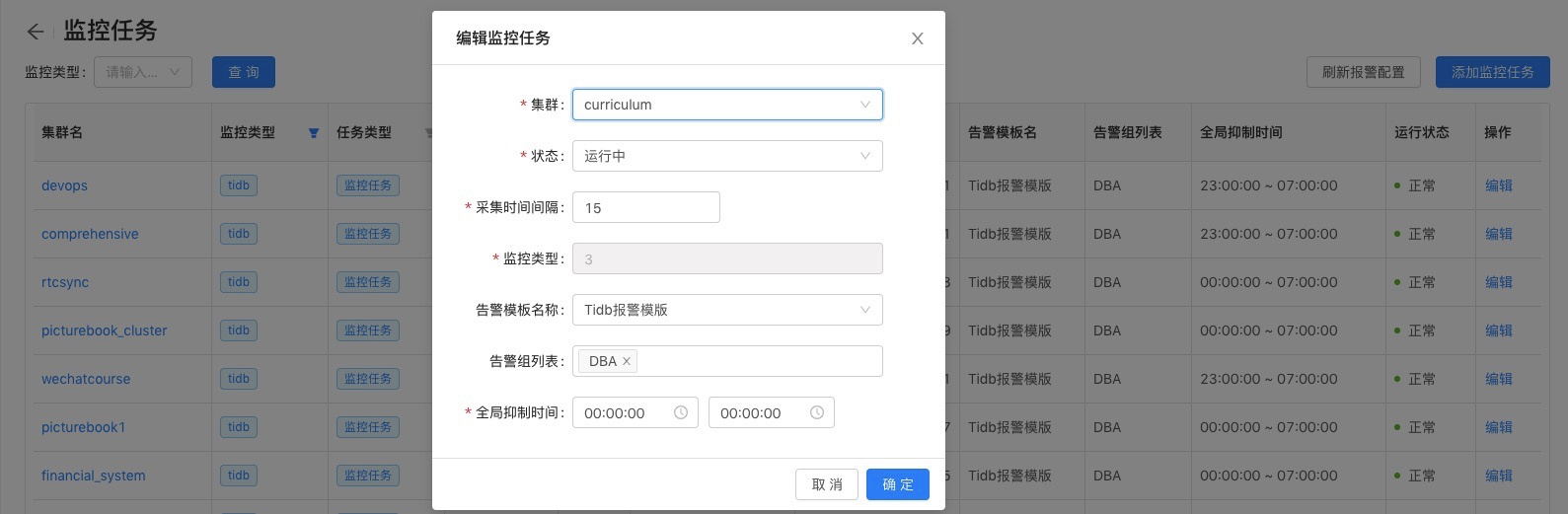
报警模版由规则名称、角色、指标、阀值和策略五个部分组成,如下图所示。

通过服务报警模版,我们可以很方便的将报警指标和策略拼接成规则应用到各服务集群进行报警,同时还可以轻松实现个别集群报警的差异化配置。报警模版应用到服务集群,如下图所示。

模版中一条规则,简单点说,其实就是报警触发条件。如何执行报警,其实就是将一条规则映射成一条数据库查询语句,查询满足的条件的数据是否达到报警阀值。比如下面这条规则,简单介绍下是如何做映射的。

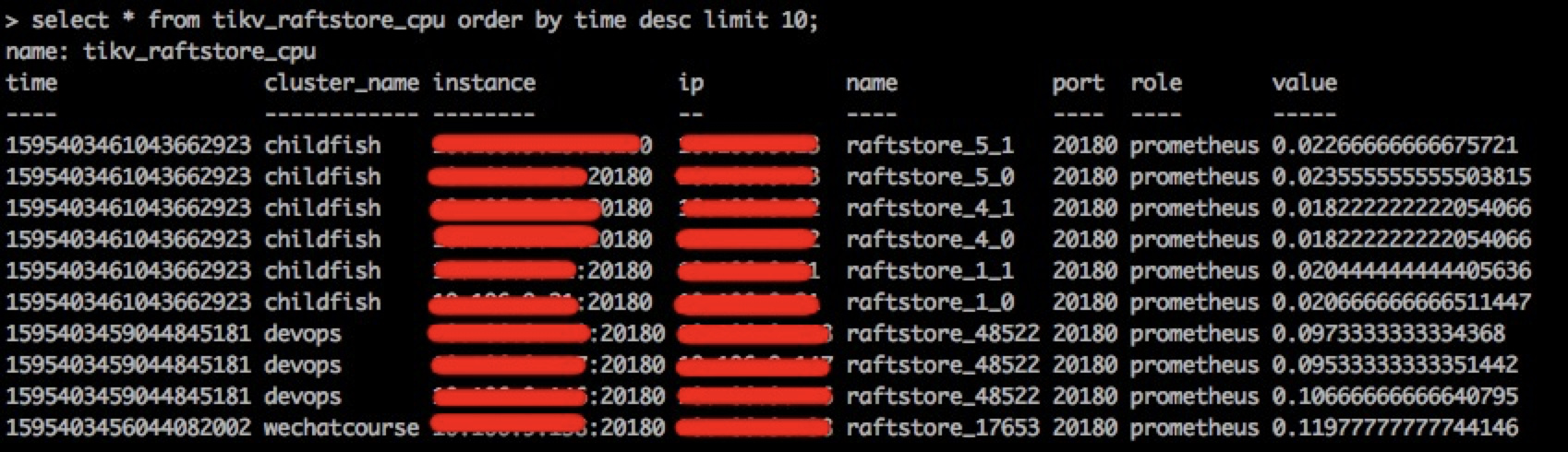
首先,我们看一下监控表中已经采集到对应指标的监控数据,如下图所示。
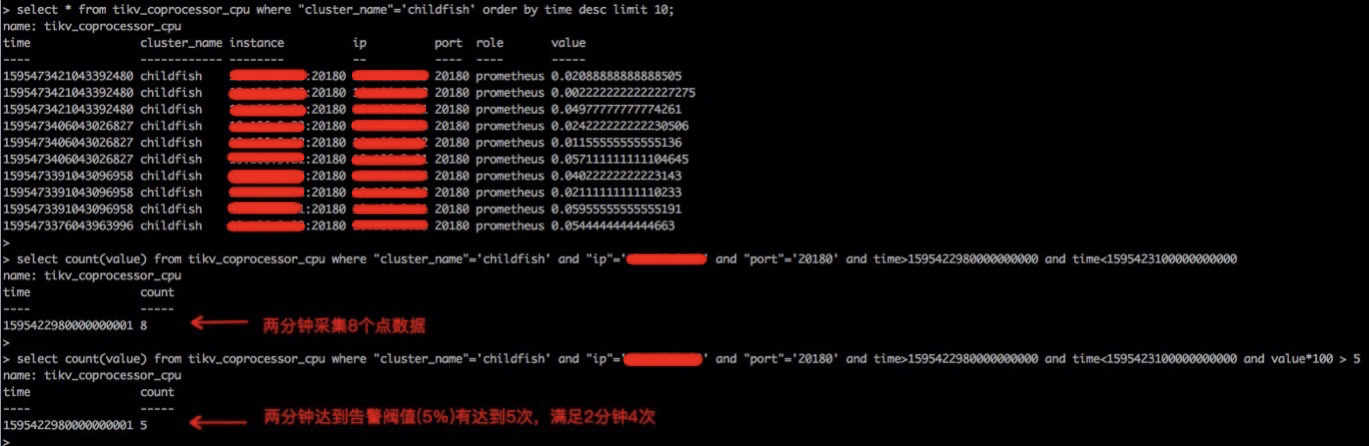
其次,集群在任务采集时,我们可以拿到具体的集群信息,包括ip、端口和角色。报警服务根据报警模版里的规则,将具体的规则映射成的查询语句,如下图所示。
最后,把满足报警规则的服务,按照集群、主机和角色维度告警出来,如下图所示
2.4.2 报警指标
报警指标可以理解为我们需要监控的项目,比如CPU使用率、机器负载和磁盘空间等,如下图所示。
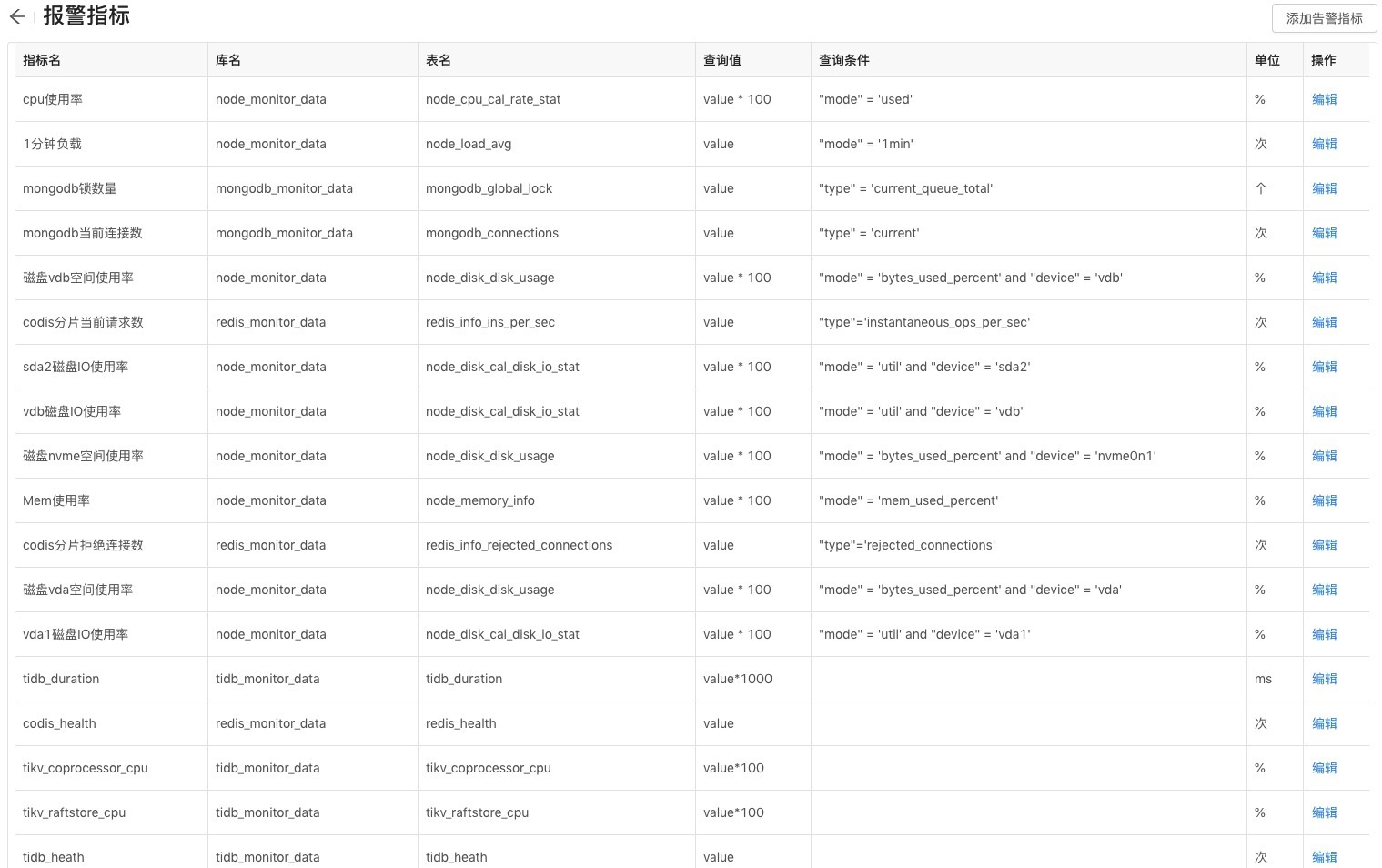
数据指标采集项比较多,我们可以选择我们关心的或者能快速反应服务问题的指标作为报警指标。这里的指标名称与报警模版中的规则名称一一对应,即将规则名称与数据库表及查询条件映射起来。
2.4.3 报警策略
目前,报警策略分为两种,如下图所示。每次采集完数据,都会通知monitor模块触发规则分析,检查是否达到报警阀值。报警每触发一次,都会检查上一次报警时间,保证在报警时间间隔内,不会重复报警。

- 2分钟内,8次(每分钟采集4次数据)中有4次满足条件,钉钉报警
- 2分钟内,8次(每分钟采集4次数据)中有4次满足条件,钉钉和电话同时报警,配置如下图所示

2.5 监控数据展示
数据监控不仅可以为我们提供准实时状态展现,还能帮助做故障回溯、风险预测和大盘监控。日常问题处理和故障复盘,我们希望在一个页面既能查看一个集群各角色的机器指标,又能看到各角色的数据库性能指标,而不用在各个指标页面来回跳转,如下图所示。
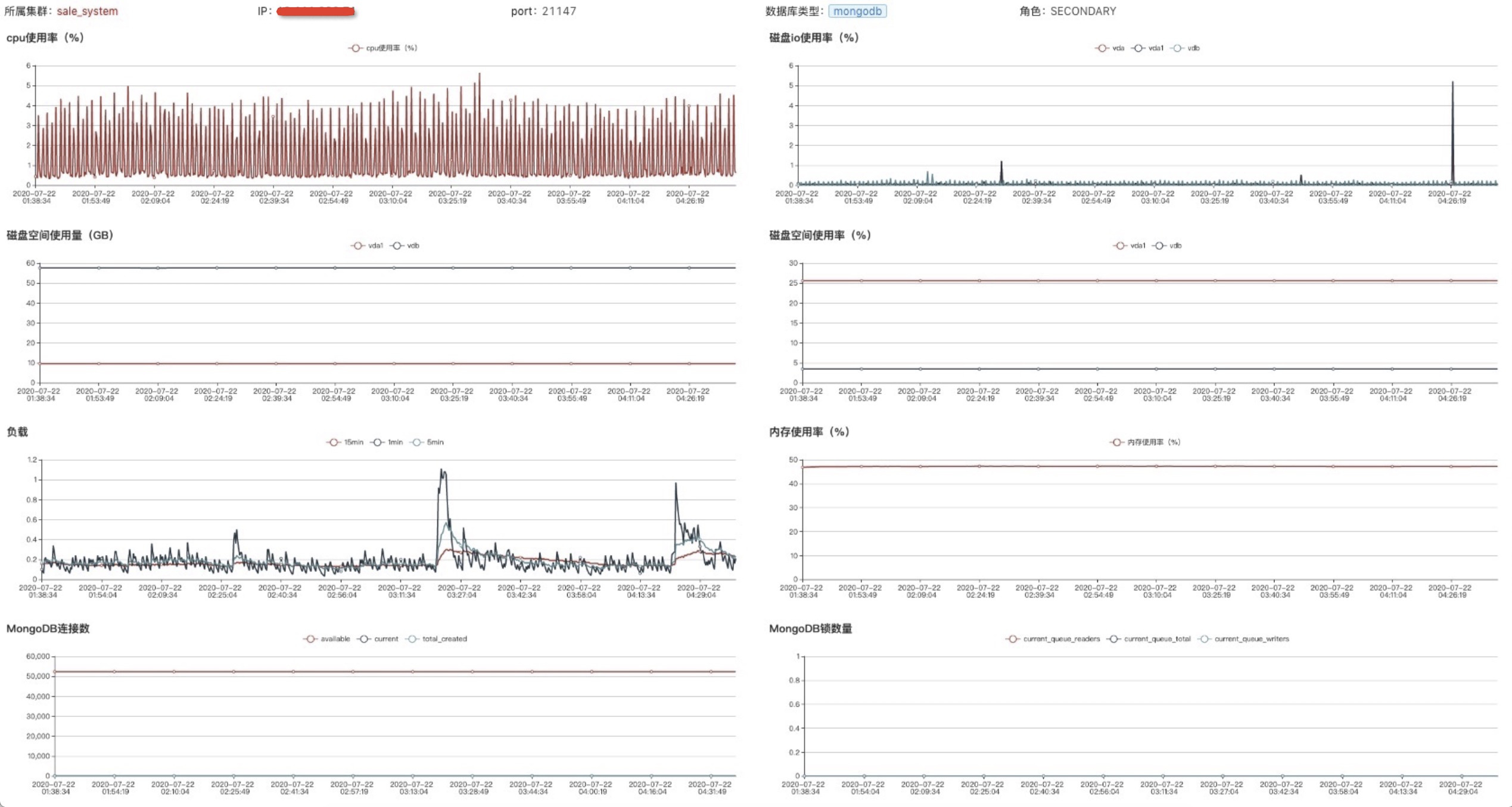
同时,我们可以利用采集的监控数据,定制我们的监控大盘。有了监控大盘,我们可以做日常巡检,及时发现性能风险,如下图所示。



3. 总结
伴鱼数据库监控系统已经运行近半年,在这期间,日常巡检和报警帮助我们发现了多起数据库性能问题,并及时得到解决。目前,监控系统还有一些待完善的地方,比如告警收敛、时序数据库高可用等问题。未来,我们将继续深挖监控系统的潜力,为伴鱼数据库保驾护航。