

一、背景
以下是 MySQL 或 TiDB 常见的锁等待超时,熟悉 MySQL 的伙伴应该比较容易理解:
CREATE TABLE testA (
id bigint not null AUTO_INCREMENT PRIMARY KEY,
val VARCHAR(255) NOT NULL
);
-- 写 5000 行数据
session A |
session B |
|
T1 |
begin; |
begin; |
T2 |
|
|
T3 |
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction |
但目前有这么个场景,TiDB 只有两个会话 A 和 B:
会话 A 是短事务,单线程循环执行只读的 SELECT ... FOR UPDATE 语句; 会话 B 是长事务,仅执行一次更新操作,最终并未报 Lock wait timeout 错,而是报了 pessimistic lock retry limit reached。
只有两个会话时,第一感觉是会话 B 不会达到最大重试次数报错,而是锁等待超时。接下来进行复现并分析原因。
二、问题复现
由于 pessimistic lock retry limit reached 报错和 max-retry-count 配置有关。为更容易复现把配置 max-retry-count 改小,含义是:悲观事务中单个语句最大重试次数,重试次数超过该限制,语句执行将会报错:
tidb 6.5.8> show config where name like '%max-retry-count%';
+------+--------------------+---------------------------------+-------+
| Type | Instance | Name | Value |
+------+--------------------+---------------------------------+-------+
| tidb | xxx.xx.xx.xxx:4000 | pessimistic-txn.max-retry-count | 1 |
+------+--------------------+---------------------------------+-------+
通过大模型辅助生成的代码可轻松复现,以下是复现的 SQL。同样只有两个会话 A 和 B,会话 A 是短事务,会话 A 先单线程循环执行只读的 SELECT ... FOR UPDATE 语句:
-- 会话 A
begin;
SELECT val
FROM testA
WHERE id =(随机选取 1 到 5000 之间的整数)FOR UPDATE;
commit;
会话 B 是长事务,跑一次就有报错如下:
-- 会话 B
begin;
UPDATE testA
SET val = ?
WHERE id BETWEEN 1 AND 5000;
Error 1105 (HY000): pessimistic lock retry limit reached
三、报错如何产生?
TiDB 的悲观锁是在乐观事务基础上实现的,相比乐观事务的两阶段提交多了一个加锁阶段,pessimistic lock retry limit reached 报错是在加锁阶段出现的。写入时 TiDB 先从 PD 获取当前 tso(分布式全局递增时间戳)作为当前锁的 for_update_ts。悲观事务会用 for_update_ts 检查是否存在写冲突,效果等同于可更新的 start_ts,尝试写入并获取锁时检查 key 的 commit_ts,如果大于 for_update_ts 则出现写冲突,就会用当前冲突的 commit_ts(conflict_commit_ts)更新 for_update_ts 再重试 DML。当重试次数超 max-retry-count,就会向客户端返回报错 pessimistic lock retry limit reached。示意图:
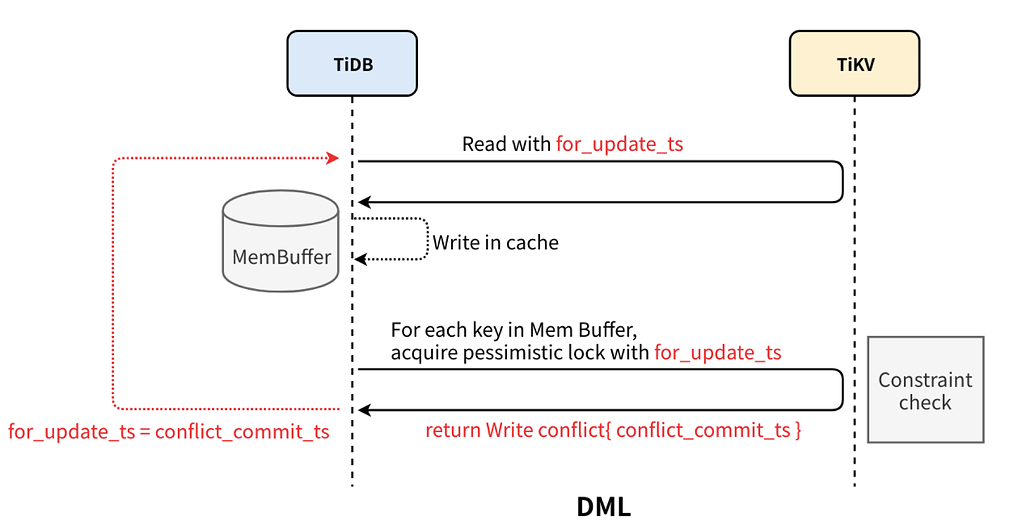
对于当前的例子:
会话 A 不断随机更新 5000 行数据中的某一行。
会话 B 要一次性 5000 行的锁,会话 B 加锁的 key 比会话 A 多,每次总有某行数据的 commit_ts 大于当前的 for_update_ts,所以只能不断重试,直到重试次数超 max-retry-count报错 pessimistic lock retry limit reached。在文章有介绍:https://tidb.net/blog/7730ed79 :

四、只读语句也会使版本变大吗?
我们再结合例子看一下,会话 A 不断循环以下:
begin;
SELECT val FROM testA WHERE id = 1 FOR UPDATE;
commit;
会话 B 是长事务,只跑一次:
begin;
UPDATE testA
SET val = ?
WHERE id BETWEEN 1 AND 5000;
假设最初会话 A 运行事务时,对于 id = 1 这行记录 commit_ts=100。
然后会话 B 获取到 for_update_ts = 101,且会话 B 尝试加锁时,发现这行数据已被会话 A 修改并提交,导致 commit_ts = 102,此时 commit_ts = 102 > for_update_ts = 101,会话 B 会进行悲观锁重试,更新 for_update_ts 为 conflict_commit_ts=102,重新读取数据,再次尝试加锁直到重试上限报错。那问题就来了,只读的 SELECT ... FOR UPDATE 会导致 commit_ts 变大吗?
答:是的,只读语句 SELECT ... FOR UPDATE 的处理和正常的写入处理并无差别,也会留下 MVCC 版本记录。因此,即使是只读语句,只要加了 FOR UPDATE,也会产生写入行为,从而推进版本号。
五、有时报锁超时有时报超重试次数?
为什么在实际使用过程中,有时报错 Lock wait timeout,有时报错 pessimistic lock retry limit reached?
对于文章开头的锁等待例子,会话 A 一直锁住某行数据不提交,会话 B 尝试更新这行数据。在 TiDB 中其实会话 B 会不断根据 wait-for-lock-timeout 重试,重试最大时间为 innodb_lock_wait_timeout。这里和重试最大次数 max-retry-count 无关。如果事务能在 innodb_lock_wait_timeout 内成功获取锁,则可以继续执行,否则报错 Lock wait timeout exceeded。innodb_lock_wait_timeout 和 max-retry-limit 两个参数无直接关联,TiDB 中哪个条件先达到,就报哪种错。
六、小结
本文通过对比 MySQL 和 TiDB,在锁等待报错机制上的差异,分析了 Lock wait timeout 与 pessimistic lock retry limit reached 两种常见错误的成因。尽管触发条件不同,但二者本质上都反映了当前事务存在严重的资源竞争或访问冲突。
对于此类问题,仅靠数据库参数调整(如增加 innodb_lock_wait_timeout 或 max-retry-count)无法根本解决。在实际业务中,更应从业务层面如避免大事务、调整粒度、热点、调整访问顺序、简化事务逻辑等方面入手。只有数据库参数优化与业务访问优化相结合,才能有效降低锁冲突概率,提升事务成功率与系统整体吞吐量。