

版权声明 ©
【是否原创】是
【首发渠道】TiDB 社区,转载请注明出处
概述
最近做了一下TiSpark On Kubernetes的实践,在开发环境中走通了TiSpark On Kubernetes的整个过程。此文介绍测试TiSpark On Kubernetes的step by step过程。
背景介绍
做此次探索,是源于一次讨论,(详情:https://asktug.com/t/topic/274926/12)。讨论解决方案的过程中 @Kongdom 同学表示,客户资源比较紧张,没有资源搭建独立的Spark运行环境。联想到最近遇到的一些项目有一些共同特点:
- 项目初期资源规划按照应用+数据库做了规划,有一些资源比较紧张的项目,都有所谓先跑起来的说法。
- 需求越提越多,项目经理需求控制的不好,其中一些需求,会给数据库造成较大的压力,基于种种原因,必须要做。
- 很多的企业系统,晚上是没有访问的,资源闲置。
基于以上情景的总结,诞生了一个想法,如果晚上复用k8s的资源跑计算,利用Spark的计算能力解决一些TiDB计算瓶颈问题,是不是可以解决以上的困局。
在官方的图上稍作修改,架构图如下:
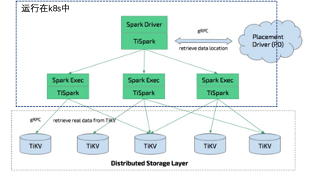
适用读者范围
- 有现成的k8s测试环境和TiDB测试环境
- 有一定的k8s运维基础
- 运算资源比较紧张,有合理利用资源的需求
资源描述
- 一个TiDB集群,只是用来测试,满足最低部署要求就可以,版本为5.3.0。
- 一个k8s集群,我的k8s集群版本是v1.18.20
- 下载Spark代码,版本3.0.3,参考连接:https://github.com/apache/spark/archive/refs/tags/v3.0.3.tar.gz
- 克隆https://gitee.com/a-i-c/tisparkonk8sshell.git
关键解释
- k8s地址为k8s的api server地址如果实在搞不明白,可以直接把k8s的第一个master地址带入,端口默认8443
- 我本机的java环境是java version “1.8.0_251”,spark-2.4.5 on k8s在此环境下是有问题的,而TiSpark集成Spark3.0.X环境,我始终未调通,所以运行环境用spark-3.0.3,编译环境是spark-2.4.5,镜像也依赖spark-2.4.5。
实践过程
A. 准备Spark运行环境
解压下载的v3.0.3.tar.gz,并导入IDEA,克隆tisparkonk8sshell项目到IDEA中,拷贝tisparkonk8sshell中的shells/init_spark_on_k8s.sh到spark项目根目录下并执行。在k8s中创建spark命名空间。
B. 准备数据环境
在TiDB上构建两个库,建库脚本参考:tisparkonk8sshell项目中sqlfile/init.sql,其中sbtest.sbtest_o为原始表,数据读取表,sbtest2.sbtest_t为目标表,数据导入表。sbtest.sbtest_o需要初始化数据,可以直接source sqlfile/data.sql。
C. 快速体验
拷贝tisparkonk8s中的shell/quick_start_sparkonk8s_245.sh到spark项目根目录下。
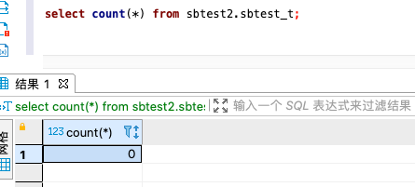
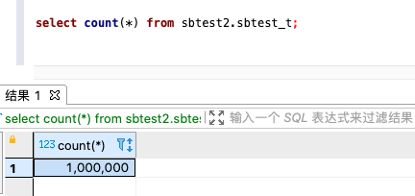
跑任务之前,检查sbtest2.sbtest_t的数据量:
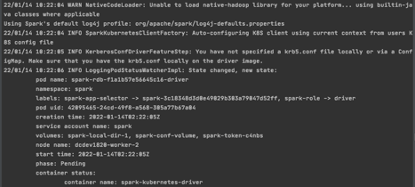
执行sh quick_start_sparkonk8s_245.sh xxx.xxx.xxx.xxx,其中xxx.xxx.xxx.xxx修改为k8s地址,项目正常开始运行会见到如下的日志:
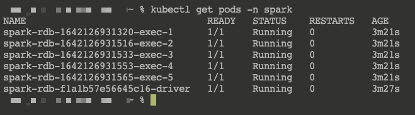
使用kubectl查看spark空间中的pod,如下:
跑任务之后,检查sbtest2.sbtest_t的数据量:
总结
这次实践只是做了一次poc,离真正的生产运行还差很远,Spark如果在k8s上部署history server,后续的任务跟踪会更方便,这一块程序如果可以读取对象存储上的sql列表,直接进行计算和写入,使用起来门槛会更低。下一步准备做一个类似的框架,并开放出来,开放出来的代码包含上述测试所用代码。