

项目背景:
将tidb的单云架构改造成多云架构,实现以下需求:
1.在专线网络抖动时集群可以正常对外服务,不影响读写服务
2.在单云故障时可以进行高可用切换并快速恢复对外提供服务(业务流量也需要业务侧进行云之间的切换)
本篇文章主要内容如下:
1. 多云方案选型:每个方案的优缺点
2. 选定ticdc 方案后的测试流程
3. 现有集群的使用情况介绍,以及使用ticdc 同步到新集群的操作流程
4. 进行多云之间的业务切换测试
5. 最近公司内部的报表业务从mysql 切换到tidb 的出现的问题以及心得总结
6.测试过程中发现的问题以及解决办法
Part 1: 多云方案选型
1.两个机房3副本的架构: 腾讯+百度(阿里)两个机房3副本
两个tikv节点在腾讯,读写入口都在腾讯,并把leader都调度到腾讯机房
- 网络抖动时: 腾讯机房副本数满足半数以上,可以正常提供读写服务
(此时如果在百度侧部署的服务则不能跨云访问)
config set label-property reject-leader dc bjali(禁止向异地机房调度 raft leader)
- 当腾讯机房整体故障时: 百度(阿里)侧机房只有一个副本,无法正常选举并提供服务此时需要通过
pd-recover以及tikv-ctl unsafe-recover来恢复pd以及tikv服务,并进行缩容,扩容操作
此方案的缺点:
当面对机房故障时,手动修复流程较为复杂,耗时长不太可控,也不太方便实现自动化
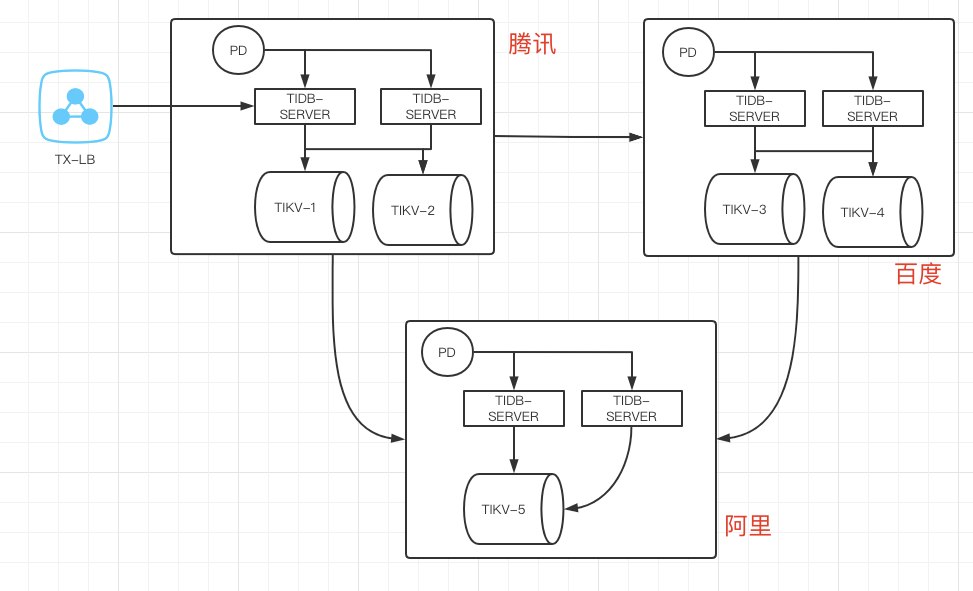
2.三个机房5副本的架构(见下图)
腾讯+百度+阿里副本分布为2-2-1.读写入口可以分布在腾讯和阿里,leader 调度在腾讯和阿里
- 单个机房网络抖动时(腾讯->百度),如果腾讯入口访问的leader 在百度机房,则访问会阻塞;
如果访问的leader 在腾讯机房则访问正常
- 多机房网络抖动时(腾讯侧内部正常,但是腾讯跟阿里,百度通信都断开了)
这种情况下业务可能不想切换流量入口依旧在腾讯,但是此时腾讯侧成为少数派,
如果网络抖动时间过长则会触发集群在百度和阿里侧重新选举。此时bd + ali 是一套正常的集群
- 单机房故障时,可正常选举并对外提供服务
此方案的缺点:
a.当主机房与另外两个机房都隔离开,但是业务侧访问主机房正常时,不能快速恢复对外提供服务
b.多个机房之间网络交互较多,集群整体吞吐能力降低
c.任意两个机房之间的网络抖动都可能造成写入的阻塞,对网络可靠性依赖太高
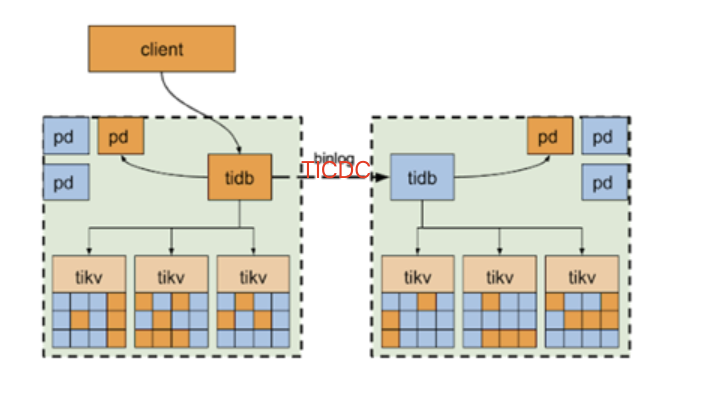
3.使用双机房,每个机房建立一套单独的集群,使用ticdc进行数据同步。如右图
- 机房之间网络抖动时:正常提供服务(异地机房部署的服务受影响)
- 单机房故障时:需要通过架构组切换service-name 对应的备用集群的LB_host:port 信息,使得业务流量切换到新集群
此架构缺点:
a.成本略高
b.需要关注ticdc的运行情况,尤其是当网络抖动时能够及时发出告警,并完善一般故障的自动处理
c.主机房故障后,有可能部分流量已经写入了旧的集群并未同步到新集群,需要研发人员手动修复数据
此架构的优点:
a.对于各种情况的网络抖动或者机房故障都能快速响应
b.相比其他多机房性能更好一些
业务目前的部署架构情况:
1.大部门业务主流量在单侧云(比如说腾讯)
2.多云之间的网络抖动情况高于单个机房的故障情况
结合以上分析最终决定选择第三种方案来做多云架构
Part 2: 使用TICDC 同步集群的测试(集群版本5.1.1)
1.DDL操作的延迟情况
- 增加索引: 上游索引创建完成之后, 下游才开始操作(ticdc监控上无延迟)
- 修改表字段:
Create Table: CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(150) DEFAULT NULL,
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
KEY `k_1` (`k`),
KEY `idx_x` (`k`,`pad`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin AUTO_INCREMENT=20363813
(1).alter table sbtest1 modify column c char(150);
(2).alter table sbtest1 change column k k varchar(20);
以上两种延迟情况跟表大小有关(4.0.9 的时候延迟的很严重)
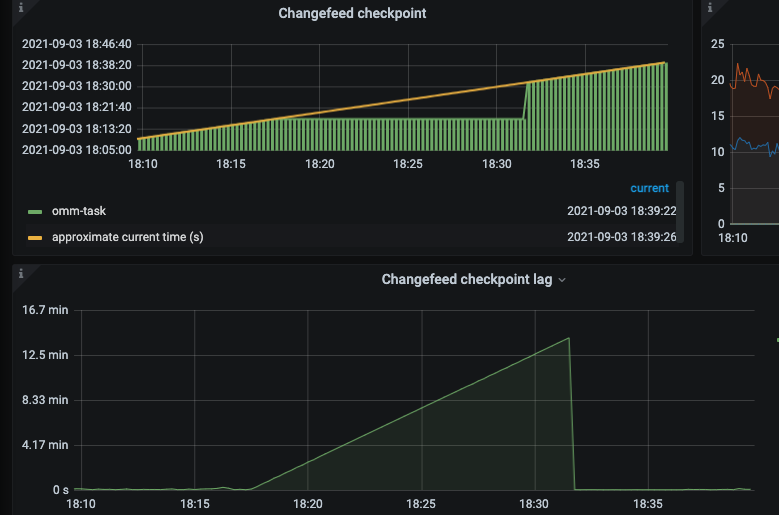
2.下游tidb 少数tikv 节点异常: ticdc 同步状态正常
3.下游tidb 多数tikv 节点异常: ticdc 同步出错,无法继续向下游同步数据
- 当下游tikv 恢复正常后,需要对ticdc 使用resume 命令使其恢复正常。数据可继续同步给下游
- 需要观察在异常时间较长的时候,在恢复 ticdc 要同步大量延迟的情况下使用的内存情况和CPU 的情况
(当前新可以使用--sort-engine="unified" 来避免内存暴涨)
4.大流量压测下ticdc的延迟情况
一次性update 50w sbtest1 无索引字段的表数据
- 延迟超过分钟级
- 需要调整大事务相关参数(默认100M)performance.txn-total-size-limit: 10485760000
5.数据延迟: 正常情况下cdc 的延迟在秒级别,在机房间切换可能会出现数据丢失的情况
- 需要跟业务方提前沟通业务对数据丢失的容忍情况,是否可以后期手动修复等
- DDL 以及大流量操作时要尽量在低峰期进行操作,避免集群间延迟过大
6.主备集群间的切换
- 切换演练时要提前做好方案,将切换后写入的数据流量也能同步到旧集群,方便业务再次切换回来
- 在实际故障切换时,当原机房恢复时,需要尽快恢复好主备集群之间的同步状态
Part 3: 当前我司使用tidb的情况
1.线上mysql 数据汇总到tidb中,作为一些研发人员查询使用,隔离开线上环境
2.部分mysql 业务数据量较多,使用dm 迁移到了tidb中,代替mysql 提供服务
3.一些流水操作日志等,数据量较大的使用场景
4.内部报表业务从mysql 迁移到了tidb(存储和性能都得到改善)
5.使用tidb 的tiflash 为查询频率较高的olap sql 提升性能
Part 4: 内部报表业务从mysql 迁移到tidb 的流程
1.上游mysql服务停写 -- 研发
2.检查上游是否有残留连接并停止数据同步dm -- dba
-- kill mysql残余连接,观察几分钟确认没有新连接进来
-- 停止从mysql到tidb的数据同步程序dm
3.重启tidb-server -- dba
- 对于表结构使用自增id 的情况一定要重启tidb server,否则会有自增id 冲突的情况
4.创建tidb 的数据同步到原来的mysql集群 -- dba
-- 增加tidb下游消费程序drainer(表的数据量较少建议使用ticdc)
-- 测试一张表的测试数据,查看binlog同步是否正常同步到原来mysql中
5.变更业务的写入 入口为tidb 集群 -- 研发
6.观察业务 以及 数据同步到下游的情况
总结:
1.在业务切换到tidb之前运行两到三周,观察是否有不兼容的情况(比如字段的修改)
2.最好能先将mysql的只读业务sql 提前切换到tidb 中观察sql 的兼容情况以及结果的正确性
(如果只读代码不好分离,则打开全量日志,搜集至少一周的查询 sql 去tidb中进行验证)
3.注意tidb 的sql mode, 原来mysql 中的group by 的使用情况,自定义变量的使用情况(跟mysql 中略有不同)
Part 5: 改造现有的集群架构,使用ticdc 进行同步,进行切换测试
— 待续,近两周内完成
Part 6 在测试期间遇到的一些问题:
1.ticdc 的几个bug
- 不能同步太多的表,比如1w 以上
- data lost after scale-in 3x tikv node https://github.com/pingcap/ticdc/issues/2400
- changefeed stuck, log has "etcdserver: request is too large...owner exited with error"
https://github.com/pingcap/ticdc/issues/2083
- Optimization for DDL execution https://github.com/pingcap/ticdc/issues/866
https://github.com/pingcap/ticdc/issues/2391
https://github.com/pingcap/ticdc/issues/2224
2.唯一索引的加锁问题导致耗时增加较多(5.0.0)
https://github.com/pingcap/tidb/issues/25659(5.1.1 会 fix 这个 bug ~;5.0 版本是 5.0.4 fix ~)
3.自定义变量的问题
SELECT @cdate := DATE_ADD(@cdate,INTERVAL - 1 DAY) AS bw_dt FROM
(SELECT @cdate := DATE_ADD( '2021-09-05', INTERVAL + 1 DAY ) FROM
aaaaa where id<=1000 order by id desc )a WHERE @cdate > '2021-08-23'
表aaaa 只有单列id,从1 到20000.
- 以上sql 在tidb 和mysql 中结果不一致,经官方人员排查结论如下:
{变量的计算顺序在 mysql 那边是个未定义行为( mysql 文档中也警告了使用依赖用户变量计算顺序的 sql 的问题), tidb 这边的计算框架是以 chunk为单位,默认是1024行}
- 解决办法为研发人员改写了这部分sql
4.group by 的问题:
尽量使用完全group by,如果使用非完全group by 则出现的结果集跟mysql 可能会不同