

如果说生成式 AI 是一本包罗万象的食谱,那么 AI Agent 就是那位能为你量身定制晚餐的私厨。它会记得你上周抱怨过海鲜过敏,会注意到你家冰箱还剩半颗西兰花,甚至记得你说过"下次别放香菜"。这位私厨的价值不在于单次的烹饪技巧,而在于持续的记忆与适应。而这,恰恰是当下 AI 演进的核心战场。
O'Reilly 最新发布的《Agentic AI 数据架构》报告毫不客气地指出:企业 AI 的瓶颈早已不是模型参数大小,而是如何让AI"记住事儿" 。当这场记忆革命来临时,PingCAP 的 TiDB 正从一个"分布式数据库"悄然演变为 AI Agent 的"数据基座"。

01. AI Agent 的"健忘症":传统数据架构为何撑不住?
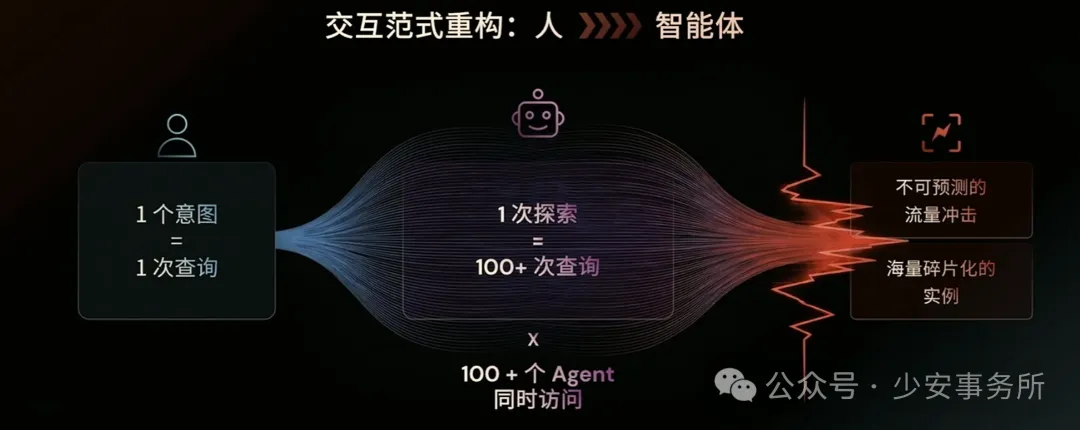
报告开篇就戳破了 AI 落地的一层窗户纸:现在的 AI 系统很聪明,但也很"金鱼脑"。ChatGPT 能妙笔生花,但关掉窗口就忘了你们聊过啥。这种"stateless"(无状态)特性在聊天场景还行,可一旦进入真正的 Agentic AI 那种能自主规划、调用工具、跨系统协作的智能体,记忆就成了生死线。
问题出在哪儿?传统数据架构是为一锤子买卖设计的。关系型数据库存的是静态快照,比如"2025年Q3订单金额3.2亿",它擅长记录"这一刻的真相"。但 AI Agent 需要的是"流动的意识流":它要跟踪任务执行到第几步,要比较用户今天和上周的说法有啥差异,还要在几百个并行任务间共享上下文。这就像用相机拍照来拍电影——每张照片都很清晰,但拼不成连贯的故事。

更麻烦的是数据孤岛。报告里提到,企业里结构化数据只占20%,却锁在SQL里;剩下80%的文档、日志、对话躺在各种向量数据库、对象存储、数据湖里。一个 AI Agent 想查"客户上次投诉时说了啥",得先从SQL调出客户ID,再去向量库搜聊天记录,最后可能还得查日志看当时系统状态。每跳一次,延迟就涨一截,一致性就弱一分。报告毫不客气地称这种状况为"碎片化记忆栈"(fragmented memory stacks),导致的直接后果就是:Agent 推理时像喝醉了酒,东一榔头西一棒子,最后说出的话自己都圆不上。一本正经的胡说八道。
还有个要命的问题:波动性负载。传统数据库跑的是朝九晚五的 OLTP,峰值可以预测。但 AI Agent 的工作模式是"一阵风",可能半小时没动静,突然因为一个用户请求,瞬间触发几百个子任务,每个都要读历史、写日志、查向量、做聚合。传统架构要么被这浪涌打趴,要么为了保证新鲜度牺牲吞吐量。就像报告里说的:"Legacy systems...cannot elastically scale to meet sudden peaks, nor can they prioritize the freshness of data needed for inference."
02. TiDB 的"记忆基建":凭什么能当AI的"数字海马体"?
报告的作者之一 Ed Huang 是 PingCAP 联合创始人,他显然带着答案来写问题。在第二章,报告提出了核心观点:分布式 SQL 是 Agentic AI 记忆层的最佳拍档。而 TiDB,正是这个赛道的头部玩家。
分布式SQL有啥不一样?简单说,它把传统关系型数据库的"铁律"(ACID事务、强一致性)和云原生的"弹性"(水平扩展、分区容错)结合起来了。就像给一位严谨的老会计(少安事务所)配上了马拉松运动员的体能——既能保证账目分毫不差,又能随叫随到、永不掉线。

对 AI Agent 来说,TiDB 的价值体现在四个层面:
1) 统一检索底座:让"事实"和"语义"握手言和
传统架构把SQL和向量搜索当两件事:SQL管"WHERE status='active'"这种精确过滤,向量库管"找意思相近的文档"。但 AI Agent 经常要同时干这两件事,"找出所有活跃客户里,最近投诉语气最激烈的案例"。TiDB 通过内置向量检索能力(或扩展),让一条SQL语句里既能做精确的事务性筛选,又能做语义的相似度搜索。报告里管这叫"Semantic-Transactional Join",说白了就是让两个世界的人说上了同一种语言。
这事儿为啥重要?因为 AI Agent 最怕"似是而非"。向量搜索可能返回语义相近但业务上无效的结果,比如搜"涨价"返回了"降价促销"的文档。TiDB 能在向量召回后立刻用SQL条件过滤,既保证了相关性,又守住了业务底线。报告引用的研究证实,这种混合搜索能显著提升精度,同时让结果更可解释、可审计。
2) 混合负载处理:HTAP的"时光机"魔法
TiDB 的看家本领是HTAP(混合事务/分析处理),这在 AI 时代成了"时光机"。报告第三章详细拆解了这个能力:AI Agent 既需要OLTP提供的"当下真相"(用户刚点的按钮、刚下的订单),又需要OLAP给出的"历史规律"(过去30天这类用户的转化率)。传统架构得搞两个系统,再通过ETL同步,数据新鲜度至少延迟几小时。
TiDB 通过Raft协议保证事务一致性的同时,用列式引擎支撑实时分析。Agent 在同一个系统里,既能读到毫秒级新鲜的订单状态,又能同时查到历史聚合指标。报告里举了个例子:反欺诈 Agent 判断一笔交易时,既要看到"这笔交易刚刚发生",又要对比"该IP过去5分钟内的失败登录次数"。TiDB 的"滑动窗口上下文"模式让这俩操作在一个查询里完成,延迟压到几十毫秒。这种能力被报告称为"mixed workload processing",是 Agentic AI 的刚需。
3) 弹性与隔离:让Agent们"互不打扰"
AI Agent 的工作方式像"快闪",突然来一群人,闹腾完就走。TiDB的云原生架构恰好对这种模式免疫。数据自动分片、计算存储分离,意味着Agent可以瞬间拉起一个隔离的"数据沙箱"做实验,用完即焚。报告里提到:"Distributed SQL systems...can create lightweight, isolated data environments on demand." 这对多 Agent 协作尤其关键:几十个Agent同时探索不同方案,各自读写自己的分支(branch),最后合并最优结果,整个过程对主系统零干扰。
更妙的是资源隔离。TiDB 支持多租户和资源配额,确保一个Agent的"发疯查询"不会拖垮整个集群。报告特别强调了"noisy neighbor"问题,在共享环境里,某个Agent批量更新向量索引可能吃光I/O,导致其他Agent查询超时。TiDB通过工作负载隔离和智能限流,让每个Agent都有"专属车道"。

4) 治理内置:把合规"焊"进数据库
AI Agent 的黑盒特性让审计成了噩梦。它为啥做这个决定?从哪查的数据?有没有越权?报告第四章直指痛点:治理不能靠应用层外挂,必须"Baked-In, Not Layered on Top"。
TiDB的答案是:把访问控制、审计日志、数据血缘做进数据库内核。每次检索事件,谁在查、查什么、时间戳、是否授权,自动写进不可篡改的审计日志。配合 temporal table(时态表),系统能回答"去年12月3日下午2点,这个Agent看到的客户数据是什么版本",满足金融、医疗等强监管场景。报告里管这叫"Temporal Consistency Retrieval",说白了就是给数据装上"行车记录仪"。
03. TiDB 在 AI 战场:从"存储工具"到"记忆合伙人"
报告最精彩的部分,是第三章列出的那些"Patterns for Agentic Memory"(Agent记忆模式)。这些模式把TiDB从一个"数据库"升格为"记忆合伙人":
模式一:长期记忆(Long-Term Memory, LTM)的"智能归档"
AI Agent 不能啥都记,否则上下文窗口爆炸。TiDB通过摘要生成+重要性评分+分层存储实现智能归档。对话结束后,系统自动生成摘要,用启发式规则判断哪些信息值得存(用户多次提及、明确说"记住这个"),然后分层存放:高频访问的事实扔SQL表,语义相关的摘要扔向量区,冷门数据归档到对象存储。下次对话时,Agent像人类回忆一样,先查"近期记忆"(TiDB缓存),再翻"深度记忆"(向量存储),最后才挖"档案馆"。
模式二:情景记忆(Episodic Memory)的"会话录像"
针对单次任务,TiDB维护滚动窗口日志。比如用户说"接着刚才的优化方案继续",Agent能立刻从TiDB里调出上文的步骤、参数、失败记录,像"倒带"一样续上思路。报告里强调 episodic memory 通常"expires after session",TiDB通过TTL(生存时间)自动清理过期数据,避免存储爆炸。
模式三:多Agent共享内存(Multiagent Shared Memory)的"协同指挥中心"
复杂任务需要多个Agent协作,比如一个Agent负责爬虫,一个做数据分析,一个写报告。TiDB的共享表+原子提交机制成了它们的"指挥中心"。爬虫Agent写入新数据,分析Agent的向量查询立刻能发现语义相关的内容,报告Agent则通过SQL锁定任务状态防止重复处理。报告引用的 CAMEL 项目证明,这种共享内存模式让多Agent协同效率提升数倍。
模式四:增量事实同步(Incremental Fact Synchronization)
这是最酷的部分。传统RAG最怕数据滞后,数据库里的订单状态已变更,向量索引里的数据还没更新。TiDB通过 CDC(变更数据捕获)实时监听行级变更,自动触发 embeddings 重新生成,保证向量索引与事务数据"毫秒级同步"。Agent永远不会读到"过期的知识",这解决了RAG系统最大的痛点。

四、TiDB的"角色定位":AI数据层的"瑞士军刀"
通读全文,报告给TiDB的定位已经超越"数据库"范畴。在AI时代,TiDB实际上在扮演四重角色:
角色1:记忆的"物理层"
就像大脑海马体储存神经元连接,TiDB用分布式SQL+向量扩展构建了记忆的物理 基座。它既不偏袒结构化事实,也不歧视非结构化语义,而是提供统一接口让Agent按需存取。这种"多模态存储"能力,让Agent的记忆不再是东拼西凑的补丁。
角色2:推理的"加速器"
AI Agent的每次推理都伴随多次检索。TiDB通过HTAP和近似索引,把检索延迟压到毫秒级。报告引用的TiDB反欺诈案例显示,系统能在100毫秒内完成"事务读取+向量相似度+历史聚合"三步操作,这种速度让Agent的"思考"不会卡在数据等待上。
角色3:协作的"总线"
多Agent系统的最大挑战是状态同步。TiDB的强一致性事务和轻量级隔离,让Agent可以安全地共享状态、竞争资源、回滚实验。它不仅是存储,更是分布式协调器,让上百个Agent像微服务一样各司其职又步调一致。
角色4:成本的"调节器"
AI Agent的自主生成任务特性,可能导致成本失控。TiDB的细粒度计量和资源配额功能,能把成本信号暴露给Agent本身。Agent发现查询太烧钱,会自动调整策略,比如压缩向量维度、延迟非关键任务。这种"经济反馈"让AI系统从野蛮生长走向精耕细作。
05. 结语:当数据库开始"思考"
O'Reilly 这份报告的潜台词很直白:Agentic AI 的胜负手,不在模型,在基建。当AI开始拥有记忆、学会协作、持续进化,支撑它的数据系统也必须从"被动记录"升级为"主动服务"。
TiDB的演进路径恰好印证了这个判断。它从解决MySQL扩展性问题起家,到扛起HTAP大旗,如今又在AI战场找到自己的"第二曲线"。报告里,PingCAP CTO Ed Huang 和他的合作者 Blaize Stewart 用大量实践表明:分布式 SQL 不是 AI 时代的可选项,而是必选项。
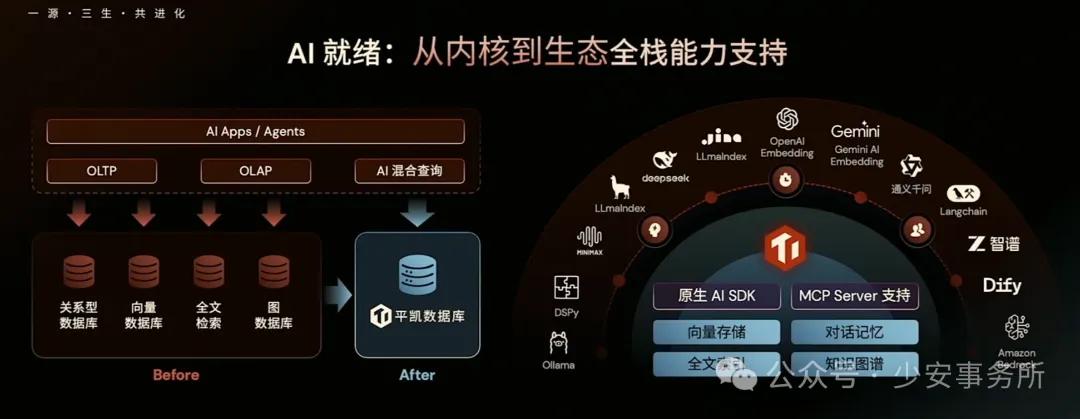
当然,挑战依然存在。如何让向量检索性能逼近专用向量库?如何支持更复杂的时序推理?如何降低多租户隔离的开销?这些问题在报告里只开了个头。但可以确定的是,当 AI Agent 成为企业生产力的核心,像 TiDB 这样"能存事实、懂语义、有弹性、带治理"的记忆基座(memory substrate),将不再是后台的"管道工",而是前台业务的"合伙人"。
毕竟,一个会思考的系统,必须要搞定"记得住、管得清、反应快、靠得住"这四门功课。而 TiDB 已将其写进内核,可安心使用 TiDB 这个 AI 的永久记忆卡。
注:文中部分截图来自于2026 平凯数据库(TiDB 企业版)新品分享会
“
关注公众号:(少安事务所) ,回复【 tidb20160122 】获取报告电子版【O'Reilly Report Agentic AI Data Architectures】

Have a nice day ~ ☕
🌻 往期内容 ▼
📚 碎碎念 | 2026年的Flag | 📚 议程官宣|2026 平凯数据库(TiDB 企业版)新品分享会 | | 📚星辰资讯 | Ti 星球新鲜事(2025.12) | Meta以数十亿美元收购AI智能体公司Manus,TiDB是其数据存储基座 | TiDB X: 以对象存储为核心要素构建全新AI原生数据库
👉 欢迎关注我的视频号

👉 这里有得聊
如果对国产基础软件(操作系统、数据库、中间件)感兴趣,可以加群一起聊聊。关注微信公众号:(少安事务所),后台回复[群],即可看到入口。如果这篇文章为你带来了灵感或启发,请帮忙『点赞、推荐、转发』吧,感谢!ღ( ´・ᴗ・` )~