

性能问题排查常用操作
基本原则
应用压测目标
当前机器拓扑和资源下
- 测试出压测程序压测 TiDB 集群,QPS 和 TPS 的 “天花板”
- 平均响应时间和最高响应时间满足需求
常见优化思路
- 热点优化,当前主键热点可以使用 shard bits 的方式进行优化
- 对于索引热点暂时无法优化,后期可以使用离散列做分区表,可以解决该问题
- 业务逻辑冲突优化,比如会有同时修改一行的场景。
- 按照压测场景进行参数调优
- 按照压测场景进行集群拓扑调整
注意事项
- 每次压测性能到达瓶颈,需要确认瓶颈,并且判断是否有优化空间
- 热点问题:是否可以打散
- 写堆积问题:是否可以调整并发写配置、调整调度相关配置来减轻写堆积
- 单线程是否成为瓶颈
- 多线程是否默认配置不足,比如 grpc 默认 4 线程,是否达到瓶颈等
- 压测方式或者程序逻辑是否符合最佳实践
- 每次提交,batch 多少
- 并发调整多少
- 短连接还是长连接
- SQL 是否非常复杂,导致 parser 解析代价较高
了解压测基本原则后,我们需要:
- 了解客户测试目的
- 需要多少 QPS、TPS、Latch
- 是否接受集群扩容
- 是否接受表结构调整等
- 定位瓶颈
- CPU、Memory、网络、IO成为瓶颈
- 压测程序成为瓶颈
- 负载成为瓶颈
- 提高压测性能
- 调整集群拓扑,比如点查场景,扩容多个 TiDB
- 调整系统参数压测
以上为压测常见的原则和优化方向。具体如何处理,下文继续讨论。
压测相关
QPS 理论值计算
作用
使用 QPS 理论值计算之后,可以和实际压测的 QPS 进行对比,一般有几何倍差距,那么可以断定在程序端或者负载耗时较长,TiDB 暂时没有到达瓶颈。
理论值公式
QPS = 活跃连接数 * (1000ms/平均 duration)
解释
- 活跃连接数,可以看监控中 TiDB/Server 中的 Connection count 的变化,其中变化量多数场景下就是活跃连接数。
- 平均 duration 是指压测过程中,SQL 的平均响应时间
平均 duration 的获取方式
监控中编辑出相关监控:
sum(rate(tidb_server_handle_query_duration_seconds_sum[1m])) / sum(rate(tidb_server_handle_query_duration_seconds_count[1m]))

注意
- 有的框架会有对系统信息进行确认,比如 select @@sql_mode,如果这类 SQL 较多,在监控中是看不出来的,那么就会影响 QPS 理论值计算,因为这类 SQL 执行是非常快的。那么需要开启跟踪日志来确认程序实际打到 TiDB 的内容。
- 实际活跃连接数并非等于当前连接数,需要结合实际情况来分析
Sysbench 压测
当定位压测性能,调大并发等操作没有明显效果、并且 TiDB 没有发现明显时,可以尝试手动抓取相关业务 SQL,进行 Sysbench 压测。
当发现压测机器 CPU 无法打满,或者和其他服务器差异较大,可以用 Sysbench 压测性能
作用
- 可以排除程序内部有瓶颈的干扰,比如程序中有和 redis 交互的逻辑,在高并发下,redis 成为了瓶颈
- 便于调试
数据库压测操作方法
安装
sudo yum install sysbench
编写压测脚本
vi config
mysql-host=172.16.4.51
mysql-port=4000
mysql-user=root
mysql-db=acrm
time=1800
threads=1024
db-driver=mysql
report-interval=10
vi test.lua
pathtest = string.match(test, “(.*/)”)
function thread_init(thread_id)
db_connect()
end
function event(thread_id)
local rs
local rs1
local rs2
local rs3
local rs4
local rs5
local rs6
– db_query(“begin”)
rs = db_query(“SELECT * FROM ms_cust_prdt_day_pft_d WHERE pty_id=‘A000000002761250’ AND ccy= ‘401156’ AND data_dt BETWEEN ‘20180101’ AND ‘20180106’”)
rs1 = db_query(“SELECT * FROM ms_cust_prdt_day_pft_d WHERE pty_id=‘A000000002861250’ AND ccy= ‘401156’ AND data_dt BETWEEN ‘20190101’ AND ‘20190106’”)
rs2 = db_query(“SELECT * FROM ms_cust_prdt_day_pft_d WHERE pty_id=‘A000000022761250’ AND ccy= ‘401156’ AND data_dt BETWEEN ‘20180201’ AND ‘20180206’”)
rs3 = db_query(“SELECT * FROM ms_cust_prdt_day_pft_d WHERE pty_id=‘A000000005761250’ AND ccy= ‘401156’ AND data_dt BETWEEN ‘20180301’ AND ‘20180306’”)
rs4 = db_query(“SELECT * FROM ms_cust_prdt_day_pft_d WHERE pty_id=‘A000000008761250’ AND ccy= ‘401156’ AND data_dt BETWEEN ‘20180401’ AND ‘20180406’”)
rs5 = db_query(“SELECT * FROM ms_cust_prdt_day_pft_d WHERE pty_id=‘A000000022761250’ AND ccy= ‘401156’ AND data_dt BETWEEN ‘20180501’ AND ‘20180606’”)
rs6 = db_query(“SELECT * FROM ms_cust_prdt_day_pft_d WHERE pty_id=‘A000000003761250’ AND ccy= ‘401156’ AND data_dt BETWEEN ‘20180701’ AND ‘20180706’”)
end
执行
sysbench --config-file=./config ./test.lua --threads=100 --time=10 run
服务器性能压测
CPU 压测
sysbench --test=cpu --threads=32 --cpu-max-prime=2000000 run >>cpu.test &
说明
可以调整 threads,来决定测试的 CPU 个数。
作用
- 可以确认各个服务器 CPU 的性能是否有差异性
- 可以确认极端情况下,是否是 CPU 有问题,导致性能打不上去
IO 压测
sysbench --test=fileio --num-threads=16 --file-total-size=1G --file-test-mode=rndrw prepare >>io.txt &
注意
- 会生成临时文件,在 data 盘上创建一个 tmp 目录临时测试
- 注意 io 性能消耗较高,避免影响线上业务
作用
可以确认各个服务器 IO 的性能是否有差异性
抓包
抓包工具较多,这里介绍一个 github 上一个开源的,MySQL 抓包工具 MySQL Sniffer
MySQL Sniffer 是一个基于 MySQL 协议的抓包工具,实时抓取 MySQLServer 端或 Client 端请求,并格式化输出。输出内容包括访问时间、访问用户、来源 IP、访问 Database、命令耗时、返回数据行数、执行语句等。有批量抓取多个端口,后台运行,日志分割等多种使用方式。
作用
可以在不同服务器中进行抓取,比如应用服务器中抓取,通过负载抓取,直连数据库抓取,查看每个 SQL 的执行效率等,可以对比整个压测链路下,各个部分的性能损耗,便于性能排查
说明
该工具需要编译安装,需要安装 cmake
安装
git clone https://github.com/Qihoo360/mysql-sniffer
cd mysql-sniffer
mkdir proj
cd proj
cmake …/
make
cd bin/
抓包命令
实时抓取某端口信息并打印到屏幕
输出格式为:时间,访问用户,来源 IP,访问 Database,命令耗时,返回数据行数,执行语句。
mysql-sniffer -i eth0 -p 3306
实时抓取某端口信息并打印到文件
-l 指定日志输出路径,日志文件将以 port.log 命名。
mysql-sniffer -i eth0 -p 3306 -l /tmp
实时抓取多个端口信息并打印到文件
-l 指定日志输出路径,-p 指定需要抓取的端口列表逗号分割。日志文件将以各自 port.log 命名。
mysql-sniffer -i eth0 -p 3306,3307,3310 -l /tmp
问题
- 有 lvs 环境下,如果 client IP 是保存在在每个连接阶段的tcp opt字段中,那么mysql-sniffer 提取的真实的 client IP 而不是 lvs 的 IP。
- 只能抓取新建的链接,如果是之前创建的链接将获取不到用户名和库名,并有一定几率丢包。
监控
Grpc
查看 Grpc 相关的监控,判断是否有热点问题、Grpc 是否成为了瓶颈等等。
请求数量监控添加
sum(rate(tikv_grpc_msg_duration_seconds_count{type!=“kv_gc”}[1m])) by (instance, job)
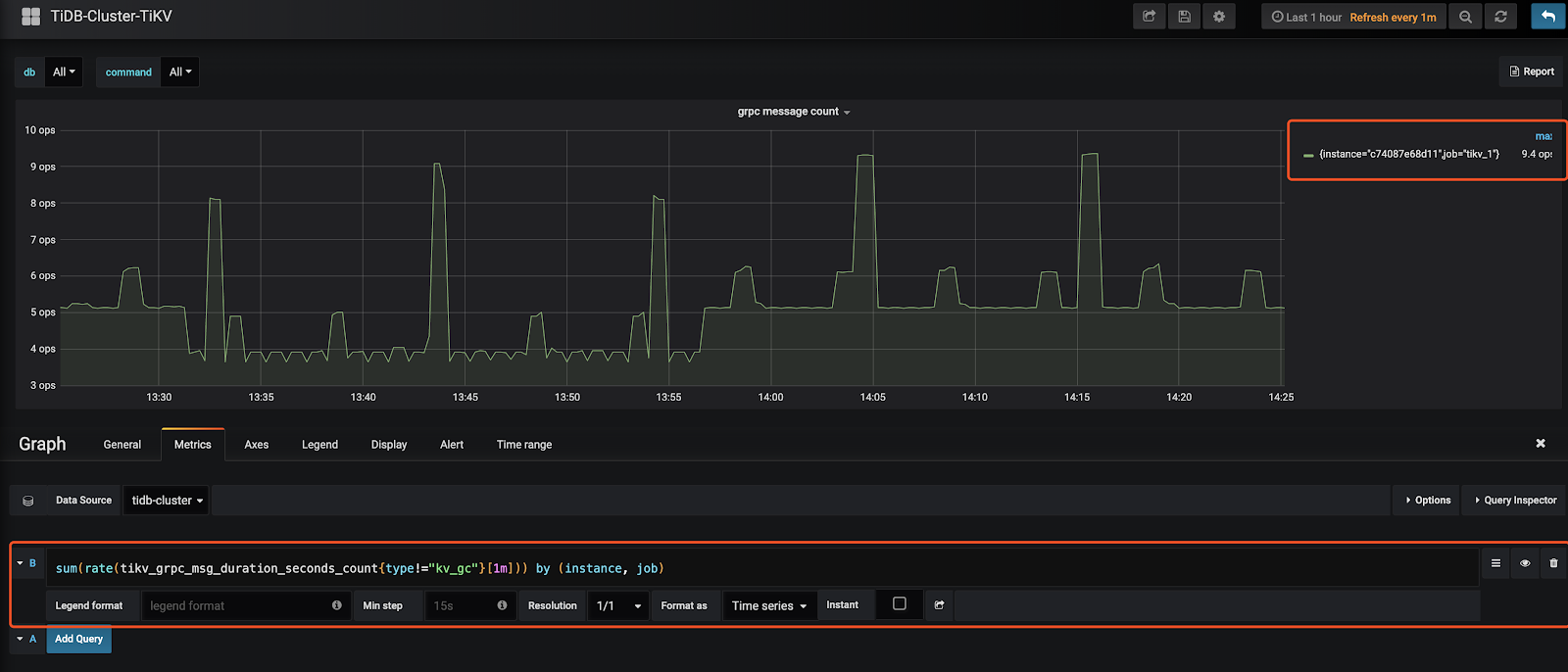
作用
- 监控中观察到每个 tikv 的 Grpc 请求数量不均衡的时候,可以判断有热点
- 如果压测过程中,发现提高并发,Grpc 数量没有随着增长,说明请求数没有到 TiKV
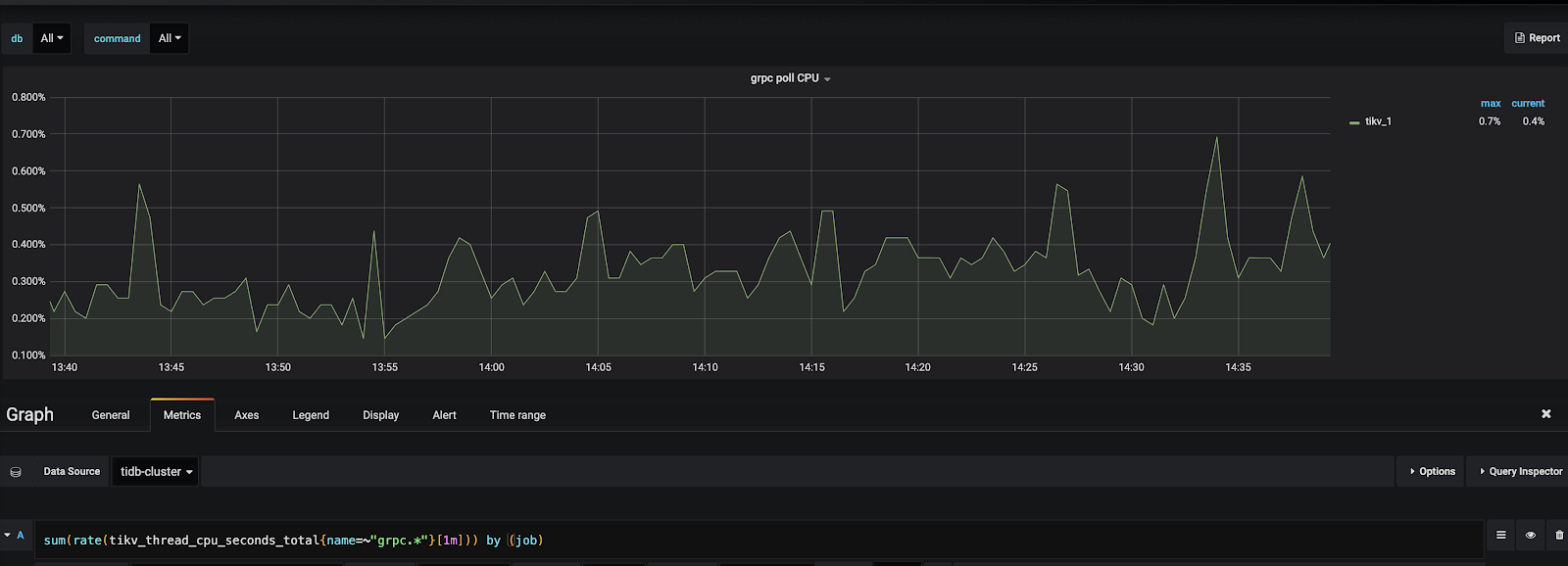
Grpc CPU
默认 Grpc 为 4 线程,如果发现 CPU 使用即将到 400%(比如超过了 320%),说明 Grpc 成为了瓶颈,需要修改配置。
监控路径:TiKV/Thread CPU/grpc poll CPU
大 Region
作用
当集群中有大 Region 时,会造成更多的请求打在这个服务器上,会造成集群性能波动较大。现有的监控中 TiKV/Server/approximate region size 。
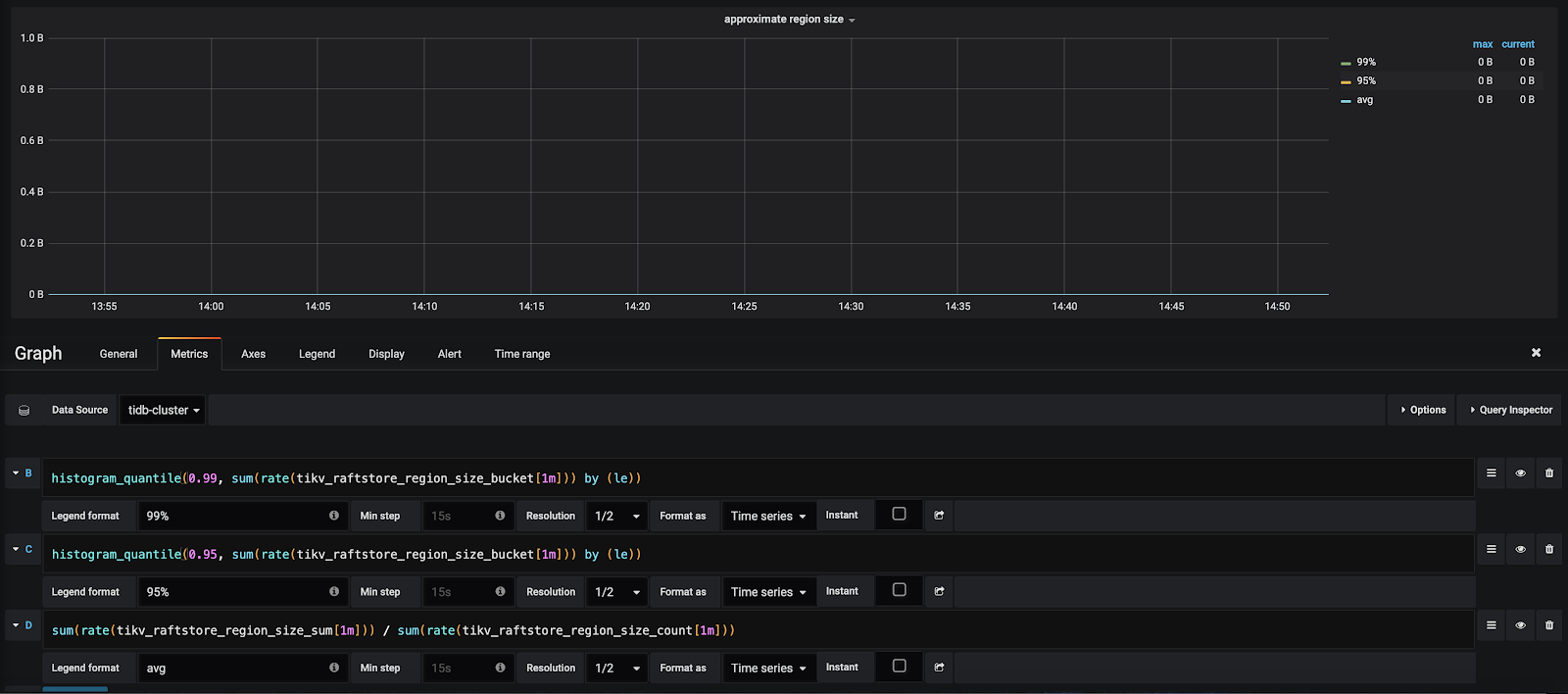
该监控会粗略的估计当前集群的 region 大小,当发现监控中数值较高时,集群中可能会有大 region 问题。batch split 功能完善后,大 Region 的出现概率降低。
处理方法
- 使用 pd-ctl 命令 region topsize 10 找到相关大 region
- 使用 pd-ctl 命令手动切割相关 region:operator add split-region 1 --policy=approximate // 将 Region 1 对半拆分成两个 Region,基于粗略估计值
热点
热点问题是 TiDB 中的常见问题,主要原因是数据写入或者读取比较集中,导致只能有 1-2 个 region 在高负载工作。当 TiDB 集群检测到热点,将会等待 15 min 之后,将热点进行调度开。
热点影响
- 无法充分使用集群性能,常常由于单个机器成为瓶颈导致性能无法压测上去
- 容易造成写堆积,导致集群性能波动较大
- 容易造成大 Region,导致集群性能波动较大
热点类型
- 主键热点,对于主键造成的热点,常见情况为自增主键和使用 UUID() 函数生成主键。对于这种表,如果写入压力较大,会有热点情况,可以使用 SHARD_ROW_ID_BITS 将主键打散
- 索引热点,对于索引写入热点,比如创建索引是时间列、手机号码等。对于这种场景,暂时没有很好的办法进行打散,后期可以使用 partition 表打散这种热点场景。并且在 3.0 rc2 版本中有打散热点索引命令 (需要后期测试)
- 小表热点问题。一个新表初始导入数据时,数据量较少,会导致导入数据大概率在一个 region 中,这样就会有一个小表的写入热点。或者当一个小表频繁被读取时,会造成热点读。对于这种情况,需要手动 split 该表并且调度开。后期支持创建表预分配region 可以解决这个问题。
判断方法
- 查看 TiKV/Thead CPU 监控中,各 CPU 的使用情况,当发现有明显的 CPU 使用率不平衡时,代表着有热点问题
- 查看 Grpc 监控,查看通信有明显差距,说明有热点问题。(参考上文 Grpc)
- 查看 Overview 监控面板中的 IO 使用率,如果有明显不均衡,说明有热点问题。
- PD 监控界面中有 HotRegion 监控面板
处理方法
- 查看监控(参考判断方法),判断是写热点,还是读热点,并且可以了解热点的 tikv store id 为多少
- 使用 pd-ctl 工具查看 TOP Write/Read hot region,根据 tikv store id 的信息来对比 top hot region 结果中的 store id 信息,找出出相关的 region id。相关命令:
- region topread [limit] // 用于查询读流量最大的 Region,limit 的默认值是 16
- region topwrite [limit] // 用于查询写流量最大的 Region,limit 的默认值是 16
- 找到 region id 后,使用 TiDB API,反推出相关表名。相关命令:
- curl http://{TiDBIP}:10080/schema?table_id={tableID}
- 结合客户需求、表结构、业务特点来判读热点类型,然后进行对应处理(参考上文热点类型)。
- 如果是小表热点,可以使用 pd-ctl 工具进行手动 split 和调度。相关命令:
- operator add split-region 1 --policy=approximate // 将 Region 1 对半拆分成两个 Region,基于粗略估计值
- operator add transfer-leader 1 2 // 把 Region 1 的 leader 调度到 store 2
调度
热点调度
TiDB 集群检测到有 hot region,并且热点 region 不均衡时,15 分钟后,将会进行热点调度,从负载高的 TiKV 调度 region 到负载较低的 TiKV 实例中。
leader/region 调度
- leader 和 region 的分布 都是根据 对应的 score来调度的,和 leader 和 region count 无关
- 影响 region score 的因素是 region 的 size 和 盘的剩余容量,这里的 size 是估值,大概占物理盘的大小和
- 影响 leader score 的因素是 leader 的 size 和 盘的剩余容量无关,这里的 size 是估值,大概占物理盘的大小和
- 最终目的是 score 均匀接近
异常判断和处理
-
当发现监控 PD leader/region ratio 的值较高,说明 leader 和 region 的分布不均匀
-
使用 pd-ctl 查看 store 信息,使用 weight 关键字进行匹配,确认 leader_weight 和 region_weight 每个 tikv 都相等,如果不是需要查看相关比例来确认 ratio 是否预期
-
如果非预期,需要查看每个 tikv 的盘容量是否相同,或者有大文件干扰
-
可尝试使用 pd-ctl 调大 leader-schedule-limit、region-schedule-limit、replica-schedule-limit,查看分布是否正常
-
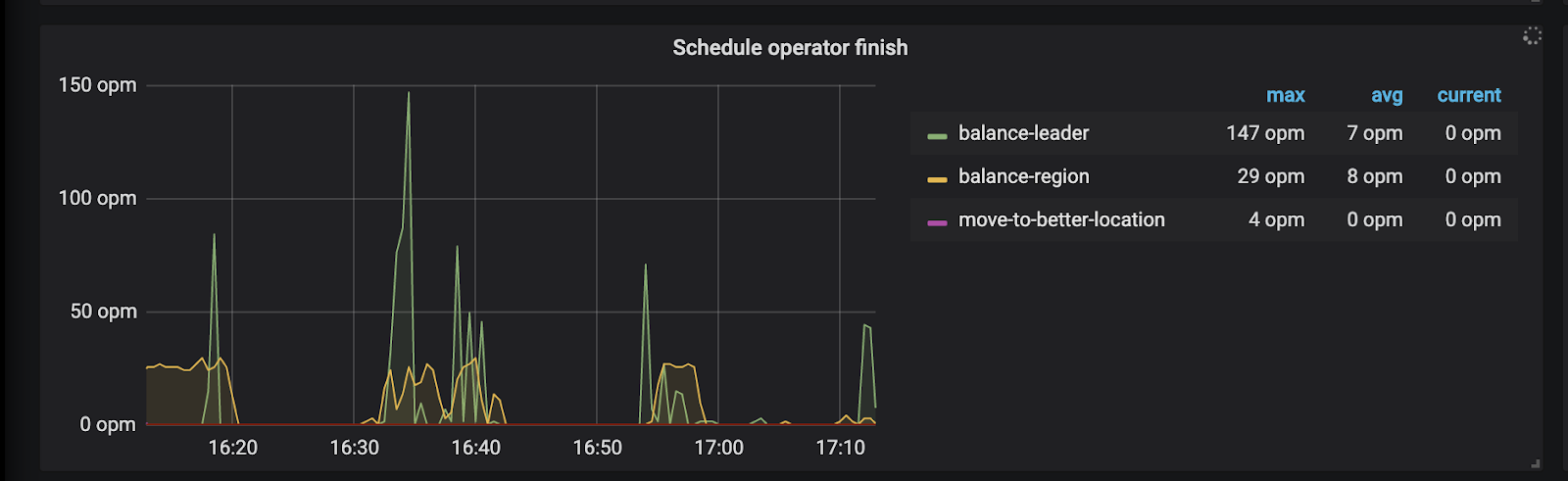
以上两点是 region/leader 分布不均匀异常,热点调度异常判断可查看监控 PD/Operator:
-
region/leader 调度请求是否上升:

-
已经成功的个数:

-
失败的个数(如果明显上升,需要查看 PD leader 日志,找到失败的原因):

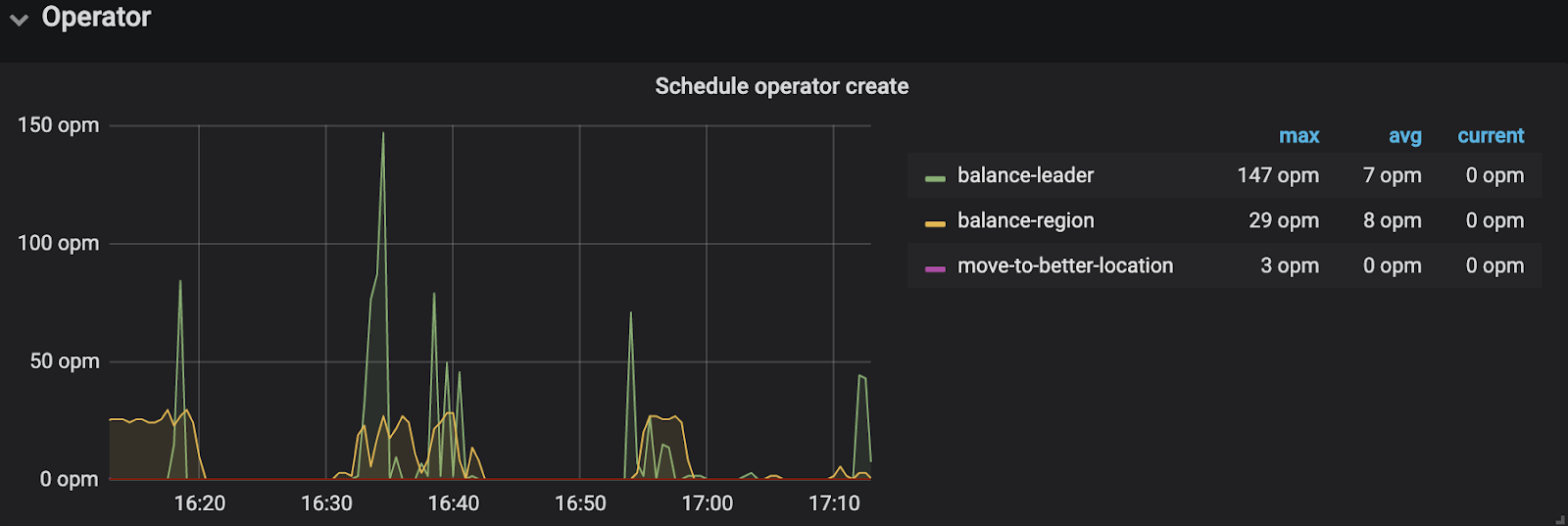
小技巧
当 TiKV 机器性能差距较大,可以使用 pd-ctl 配置 weight,人为让 leader/region 分布更为合理,避免单台 TiKV 服务器性能优先成为瓶颈,导致整体集群性能使用不充分。
写堆积
在高并发写入的场景下,可能会发生写堆积状况。在整体监控中,可能无法找到明显瓶颈,但是会发现写入 QPS 不稳定,有大幅度下降和上升过程,这时可能有写堆积,导致写入不稳定。
判断方法
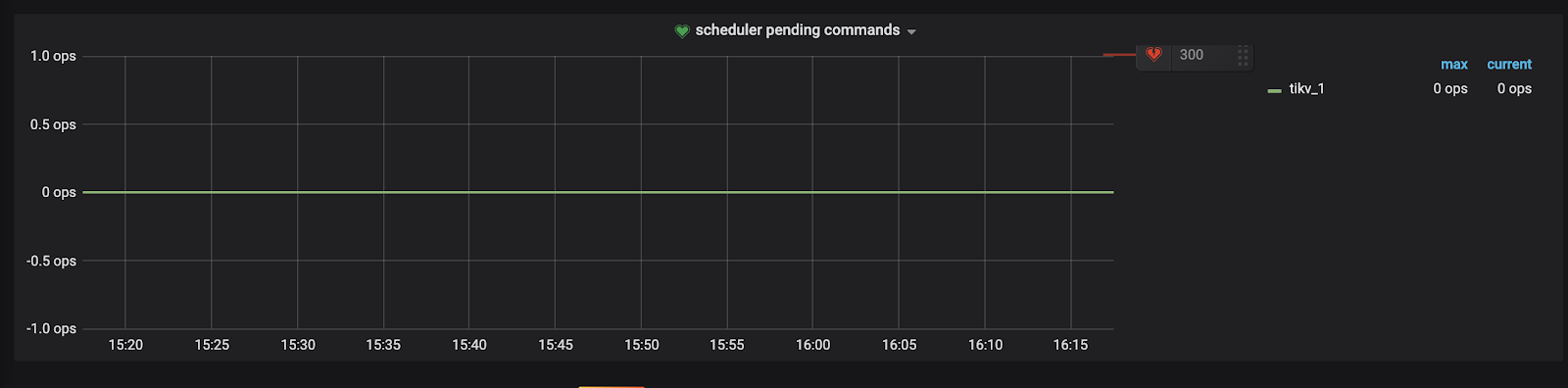
监控中 TiKV/Scheduler/scheduler pending commands 为每个 TiKV 实例上 pending 命令的个数。在高并发的写入场景下,比如 loader 导入数据等,该监控应该是上下波动的,如果向下波动无法到达 0,整体是向上趋势,那么说明写入有瓶颈,有排队。
当监控值超过了 300,会较快的到达 2000+,这时集群的整体性能会大幅度下降,QPS 会明显的减少,当写入处理完之后,会再次上升。
处理方法
- 如果单个 tikv 实例内存较大(比如 64G+),推荐调大 TiKV 并发控制相关配置:scheduler-concurrency: 2048000 (2.0.x 较低版本,该值默认较小)
- 可以测试写堆积的服务器的盘性能(参考上文 sysbench,或者安装 fio 命令测试)
- 可以视情况关闭 sync-log
- 可以查看监控,观察是否有写入热点,或者 hot region 不均衡:
- 按照上文调度内容进行判断,并且查看是否有 PD 是否有热点调度,并且成功,如若没有,非预期。
- 如果 PD 调度过慢,可以参考上文中热点调度方法,找到相关 region,手动 split 并且调度开
冲突
当程序逻辑中,可能会对同一行进行 update/insert/delete 操作时,就会产生冲突。对于主键插入冲突,在 TiDB 中不会重试,其他大多数冲突默认会重试 10 次。
当发生冲突时,TiDB 内部会回滚重试,代价较高,会影响压测性能。根本的解决方法推荐修改程序逻辑,保证先后顺序,避免冲突场景
判断方法
监控中可以查看到一些指标,查看是否有事务冲突,在 TiDB/Server/Failed Query OPM 中有相关错误码,当发现有 1062 关键字时,说明是主键冲突。
| 监控位置 | 含义 |
|---|---|
| TiDB/KV Errors/KV Backoff OPS | TiKV 返回错误信息的数量(事务冲突等) |
| TiDB/KV Errors/Lock Resolve OPS | 事务冲突相关的数量 |
| TiDB/Server/Failed Query OPM | 失败 SQL 的统计,例如语法错误、主键冲突等 |
冲突处理
- 当发现有冲突时,可以使用关键字 confict 对 tidb.log 进行冲突匹配,技巧:
- 在冲突记录的行中,有 txn 号全局唯一,可以匹配 txn 号找到相关 SQL
- 如果找不到相关 SQL,则大概率是 TiDB 内部冲突/异常,需要联系研发同学进行分析
- 确认冲突相关 SQL 后,反查相关业务,确认冲突场景是否可以避免
TiKV / Thread CPU
在进行压测分析时,没有发现服务器性能打到瓶颈,那么推荐快速查看 TiKV 的 Thread CPU 监控模块,其中有写单线程或者默认线程数较低的组件是否成为了瓶颈。
| 组件 | 用途 | 是否是瓶颈 | 首选解决方案 |
|---|---|---|---|
| grpc pool | 接收请求,发送响应 | 相关配置:server.grpc-concurrency |
默认配置是 4,CPU 打到 400% 就满了|把这个配置调大,比如 6 或更大| |storage readpool|处理写入和部分查询|相关配置:readpool.storage
默认配置是 4,CPU 打到 400% 就满了|把这个配置调大,比如 8 或更大| |coprocessor|处理 SQL 查询|相关配置:
readpool.coprocessor
默认配置:核数 * 0.8|加机器| |raftstore|处理写入请求|3.X 版本的相关配置:
raftstore.store-pool-size
默认值是 2,CPU 打到 200% 就满了|把这个配置调大,比如 4 或更大| |2.X 版本|加 TiKV 实例| |async apply|处理写入请求|3.X 版本的相关配置:
raftstore.apply-pool-size
默认值是 2|把这个配置调大,比如 4 或更大| |2.X 版本|加 TiKV 实例| |scheduler worker|处理事务请求|storage.scheduler-worker-pool-size,核数小于 16 时,默认配置是 4,即 CPU 达到 400% 就满了;核数大于等于 16 时默认为 8|把这个配置调大|
其他
连接数
TiDB 没有连接数限制,但是只会同时处理 1000 个请求,其余将会排毒,当发现监控中 TiDB / connect count 超过了 1000,那么可能需要调整相关参数:tidb-ansible/conf/tidb.yml 中的 token-limit: 1000。
日志
tidb.log 日志解析
关键字
- conflict // 冲突
- txn // 事务号
- SLOW_QUERY // 慢日志,新版本已经单独隔离出来
- Welcome // 启动关键字
- Out Of Memory Quota // OOM 关键字
技巧
- 开启 general log,根据 session 关键字匹配,可以看到同个 session 的所有操作内容,来确认程序到数据库,究竟做了什么
- tidb.log 默认所有 DDL 都会记录
- 可以确认 SQL 到 TiDB 的时间点
相关操作
- 修改日志级别
- 修改配置文件,进行滚动修改:
- vi tidb-ansible/conf/tidb.yml // 修改配置文件
- level: “debug” // 配置日志级别为 debug
- ansible-playbook rolling_update.yml --tags=tidb // 滚动 tidb-server
- 使用 API 修改(注意 TiDB 版本):
- curl -X POST -d “log_level=debug” http://{TiDBIP}:10080/settings // 修改 tidb 日志级别为 debug
- curl -X POST -d “log_level=info” http://{TiDBIP}:10080/settings // 修改 tidb 日志级别为 info
- 注意
- 将日志级别调高,比如 error 级别,理论上 tidb 性能会有一定提升
- 修改日志级别之后,一定要查看 tidb.log 的内容,确认修改成功
tidb_slow_query.log 日志解析
关键字
- Txn_start_ts
- Query_time // 实际执行时间
技巧
- 将慢日志阈值调整为 0,可以将所有 SQL 都打入慢 SQL 日志
- Query_time 是 SQL 在 tidb 中执行的时间,不包括 SQL parser 解析时间。