

TiDB集群qps抖动后续之gc失效
一、背景
在上次insert导致大批量的冲突引发qps骤降的案例后,业务改为insert ignore解决了qps骤降和duration升高的问题,但紧接着第二天就出现了GC_can_not_work的报警。集群版本是从3.0.2做过升级到3.0.5。
集群配置
集群版本:v3.0.5
集群配置:普通SSD磁盘,128G内存,40 核cpu
tidb21 TiDB/PD/pump/prometheus/grafana/CCS
tidb22 TiDB/PD/pump
tidb23 TiDB/PD/pump
tidb01 TiKV
tidb02 TiKV
tidb03 TiKV
tidb04 TiKV
tidb05 TiKV
tidb06 TiKV
tidb07 TiKV
tidb08 TiKV
tidb09 TiKV
tidb10 TiKV
tidb11 TiKV
tidb12 TiKV
tidb13 TiKV
tidb14 TiKV
tidb15 TiKV
tidb16 TiKV
tidb17 TiKV
tidb18 TiKV
tidb19 TiKV
tidb20 TiKV
wtidb29 TiKV
wtidb30 TiKV
二、现象和尝试的处理方案
我们首先收到了如下报警,报警中后续其他报警陆续恢复,仅剩GC_can_not_work
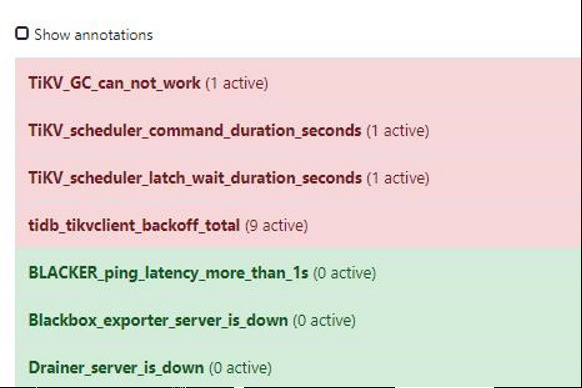
尝试的解决方案
1.将gc_life_time从24h调整到10m(无果,重启会导致gc leader漂移)
2.重启tidb(无果)
3.重启pd(无果)
4.将gc_life_time从10m调回24h(无果)
官网手册关于gc_can_not_work有如下描述
TiKV_GC_can_not_work
• 报警规则:
sum(increase(tidb_tikvclient_gc_action_result{type=“success”}[6h])) < 1
注意:
由于 3.0 中引入了分布式 GC 且 GC 不会在 TiDB 执行,因此 tidb_tikvclient_gc_action_result 指标虽然在 3.* 以上版本中存在,但是不会有值。
• 规则描述:
在 6 小时内 Region 上没有成功执行 GC,说明 GC 不能正常工作了。短期内 GC 不运行不会造成太大的影响,但如果 GC 一直不运行,版本会越来越多,从而导致查询变慢。
• 处理方法:
- 执行 select VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME=“tikv_gc_leader_desc” 来找到 gc leader 对应的 tidb-server;
- 查看该 tidb-server 的日志,grep gc_worker tidb.log;
- 如果发现这段时间一直在 resolve locks(最后一条日志是 start resolve locks)或者 delete ranges(最后一条日志是 start delete {number} ranges),说明 GC 进程是正常的。否则需要报备开发人员 support@pingcap.com 进行处理。
这种情况一般是前一轮的GC还没结束,那么下一轮的GC就不会开始
这时我们应当先看一下gc leader的日志,gc leader可以通过查询mysql.tidb里的tikv_gc_leader_desc列得知
本案例中是tidb21机器
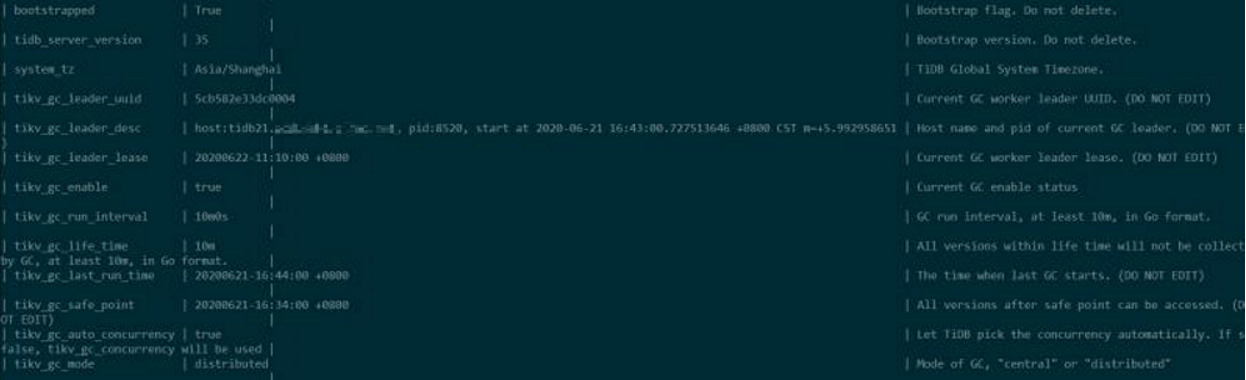
从上图得知,是21日16:44分开始的,后面一直就没有看到过显示完成,一直因为未完成,所以日志里一直报still running
其中通过tikv_gc_last_run_time/tikv_gc_safe_point分别指:
• tikv_gc_last_run_time:最近一次 GC 运行的时间(每轮 GC 开始时更新)
• tikv_gc_safe_point:当前的 safe point (每轮 GC 开始时更新)
gc一共分为3个阶段,分别是:
1.reslove lock
2.delete range
3.do gc
其详细的原理如下:
Resolve Locks(清理锁)
TiDB 的事务是基于 Google Percolator 模型实现的,事务的提交是一个两阶段提交的过程。第一阶段完成时,所有涉及的 key 都会上锁,其中一个锁会被选为 Primary,其余的锁 (Secondary) 则会存储一个指向 Primary 的指针;第二阶段会将 Primary 锁所在的 key 加上一个 Write 记录,并去除锁。这里的 Write 记录就是历史上对该 key 进行写入或删除,或者该 key 上发生事务回滚的记录。Primary 锁被替换为何种 Write 记录标志着该事务提交成功与否。接下来,所有 Secondary 锁也会被依次替换。如果因为某些原因(如发生故障等),这些 Secondary 锁没有完成替换、残留了下来,那么也可以根据锁中的信息取找到 Primary,并根据 Primary 是否提交来判断整个事务是否提交。但是,如果 Primary 的信息在 GC 中被删除了,而该事务又存在未成功提交的 Secondary 锁,那么就永远无法得知该锁是否可以提交。这样,数据的正确性就无法保证。
Resolve Locks 这一步的任务即对 safe point 之前的锁进行清理。即如果一个锁对应的 Primary 已经提交,那么该锁也应该被提交;反之,则应该回滚。而如果 Primary 仍然是上锁的状态(没有提交也没有回滚),则应当将该事务视为超时失败而回滚。
Resolve Locks 的执行方式是由 GC leader 对所有的 Region 发送请求扫描过期的锁,并对扫到的锁查询 Primary 的状态,再发送请求对其进行提交或回滚。这个过程默认会并行地执行,并发数量默认与 TiKV 节点个数相同。
Delete Ranges(删除区间)
在执行 DROP TABLE/INDEX 等操作时,会有大量连续的数据被删除。如果对每个 key 都进行删除操作、再对每个 key 进行 GC 的话,那么执行效率和空间回收速度都可能非常的低下。事实上,这种时候 TiDB 并不会对每个 key 进行删除操作,而是将这些待删除的区间及删除操作的时间戳记录下来。Delete Ranges 会将这些时间戳在 safe point 之前的区间进行快速的物理删除。
Do GC(进行 GC 清理)
这一步即删除所有 key 的过期版本。为了保证 safe point 之后的任何时间戳都具有一致的快照,这一步删除 safe point 之前提交的数据,但是会对每个 key 保留 safe point 前的最后一次写入(除非最后一次写入是删除)。
在进行这一步时,TiDB 只需要将 safe point 发送给 PD,即可结束整轮 GC。TiKV 会自行检测到 safe point 发生了更新,会对当前节点上所有作为 Region leader 进行 GC。与此同时,GC leader 可以继续触发下一轮 GC。
注意:
TiDB v2.1 以及更早的版本中,Do GC 这一步是通过由 TiDB 对每个 Region 发送请求的方式实现的。在 v3.0 及更新的版本中,通过修改配置可以继续使用旧的 GC 方式,详情请参考 GC 配置。
三、排查步骤
去观察tidb日志里有如下两类:
[2020/06/21 16:45:00.745 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cb582e33dc0004]
[2020/06/21 16:44:00.749 +08:00] [INFO] [gc_worker.go:277] ["[gc worker] starts the whole job"] [uuid=5cb582e33dc0004] [safePoint=417524204365938688] [concurrency=22]
[2020/06/21 16:44:00.749 +08:00] [INFO] [gc_worker.go:773] ["[gc worker] start resolve locks"] [uuid=5cb582e33dc0004] [safePoint=417524204365938688] [concurrency=22]
gc不运行:
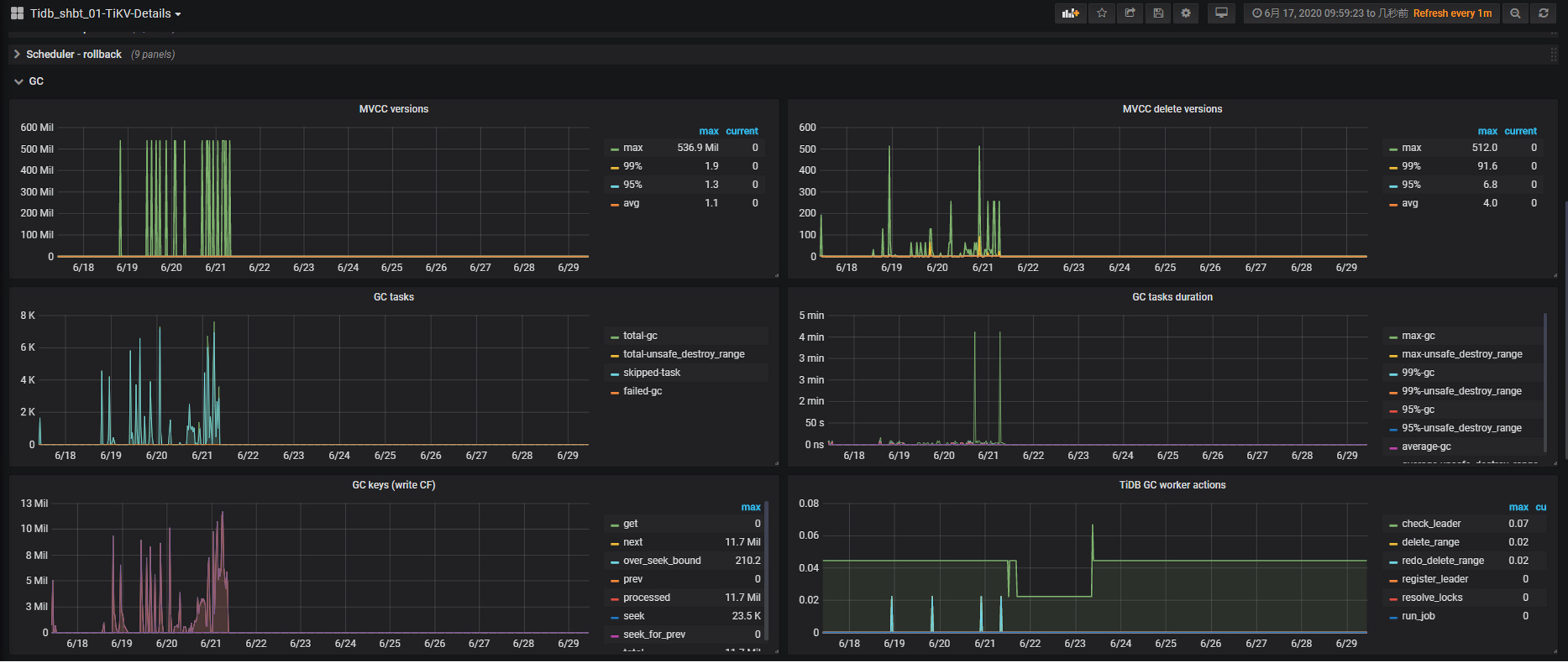
Region number持续上涨
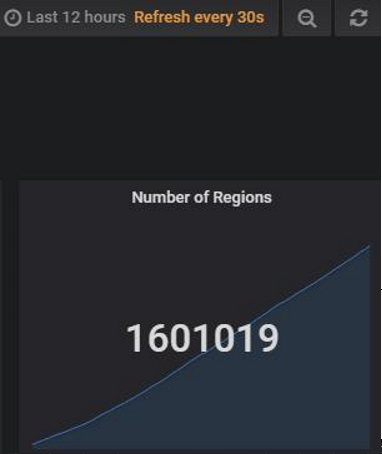
gc speed没速度了,虽然gc没速度,但集群整体的qps和duration都很稳定
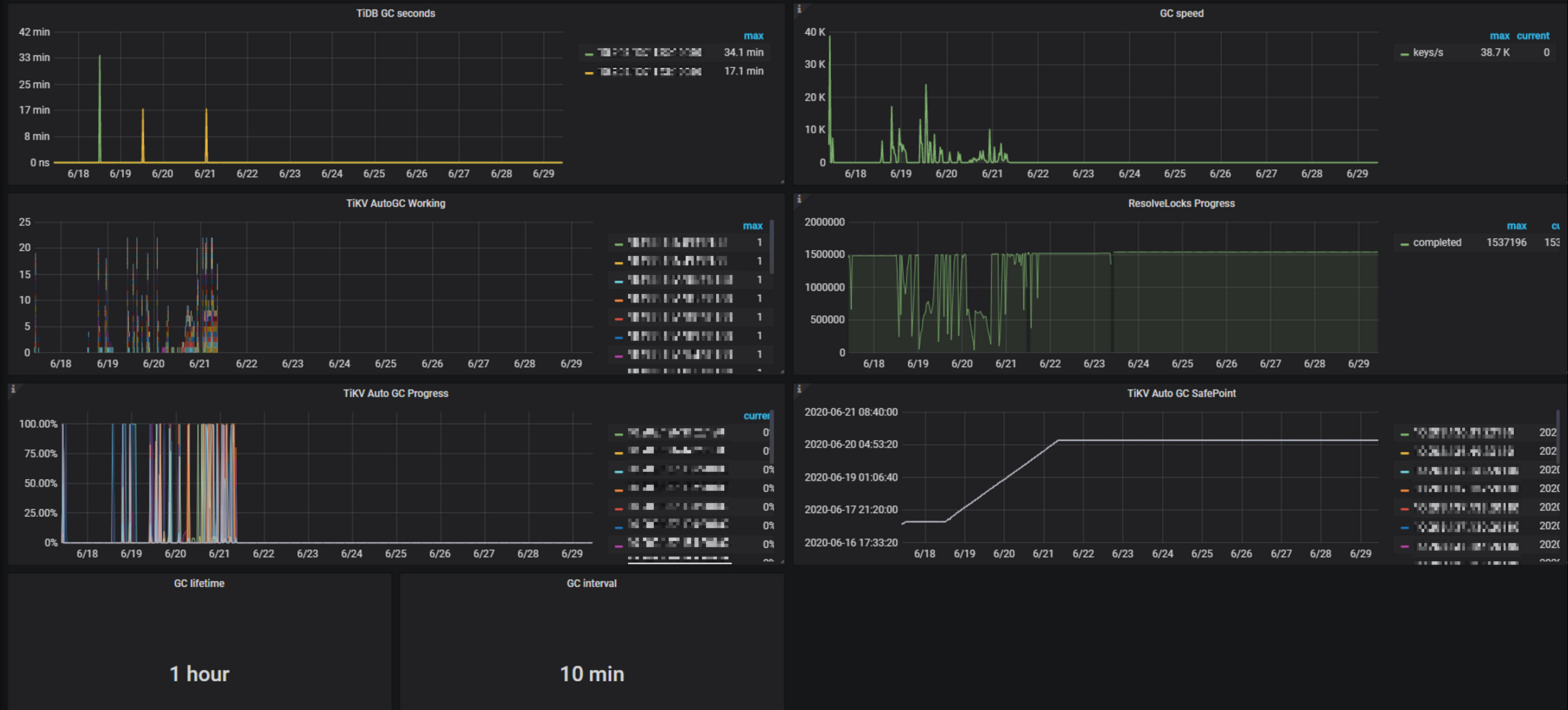
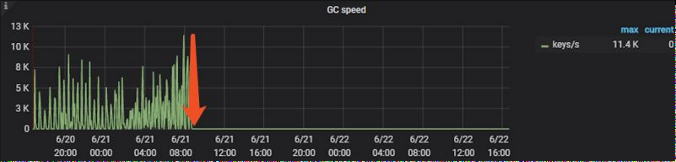
放大后得知具体的时间在21日8:44分
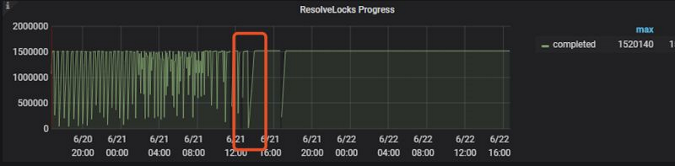
而之前的insert导致qps抖动问题,业务修改为insert ignore时间是21日下午14点左右
到这里还是怀疑之前写写冲突严重,导致这些region上残留的lock非常的多,reslove起来也很慢
而在上午8点多gc speed无速度时,业务还没有调整insert 为insert,此时的tidb gc日志为:
[2020/06/21 16:42:41.938 +08:00] [ERROR] [gc_worker.go:787] ["[gc worker] resolve locks failed"] [uuid=5cb549336b40001] [safePoint=417520979457343488] [error="loadRegion from PD failed, key: \""t\"\"x80\"\"x00\"\"x00\"\"x00\"\"x00\"\"x01m\"\"xcb_r\"\"xf8\"\"x00\"\"x00\"\"x00\"\"x01\"\"x8f\"\"xd7;\"", err: rpc error: code = Canceled desc = context canceled"] [errorVerbose="loadRegion from PD failed, key: \""t\"\"x80\"\"x00\"\"x00\"\"x00\"\"x00\"\"x01m\"\"xcb_r\"\"xf8\"\"x00\"\"x00\"\"x00\"\"x01\"\"x8f\"\"xd7;\"", err: rpc error: code = Canceled desc = context canceled\"ngithub.com/pingcap/tidb/store/tikv.(*RegionCache).loadRegion\"n\"tgithub.com/pingcap/tidb@/store/tikv/region_cache.go:621\"ngithub.com/pingcap/tidb/store/tikv.(*RegionCache).findRegionByKey\"n\"tgithub.com/pingcap/tidb@/store/tikv/region_cache.go:358\"ngithub.com/pingcap/tidb/store/tikv.(*RegionCache).LocateKey\"n\"tgithub.com/pingcap/tidb@/store/tikv/region_cache.go:318\"ngithub.com/pingcap/tidb/store/tikv.(*RangeTaskRunner).RunOnRange\"n\"tgithub.com/pingcap/tidb@/store/tikv/range_task.go:147\"ngithub.com/pingcap/tidb/store/tikv/gcworker.(*GCWorker).resolveLocks\"n\"tgithub.com/pingcap/tidb@/store/tikv/gcworker/gc_worker.go:785\"ngithub.com/pingcap/tidb/store/tikv/gcworker.(*GCWorker).runGCJob\"n\"tgithub.com/pingcap/tidb@/store/tikv/gcworker/gc_worker.go:492\"nruntime.goexit\"n\"truntime/asm_amd64.s:1357"] [stack="github.com/pingcap/tidb/store/tikv/gcworker.(*GCWorker).resolveLocks\"n\"tgithub.com/pingcap/tidb@/store/tikv/gcworker/gc_worker.go:787\"ngithub.com/pingcap/tidb/store/tikv/gcworker.(*GCWorker).runGCJob\"n\"tgithub.com/pingcap/tidb@/store/tikv/gcworker/gc_worker.go:492"]
上面的日志说明gc的时候要load region信息,但是像pd请求的时候超时了
重启tidb节点后,日志和之前一样:
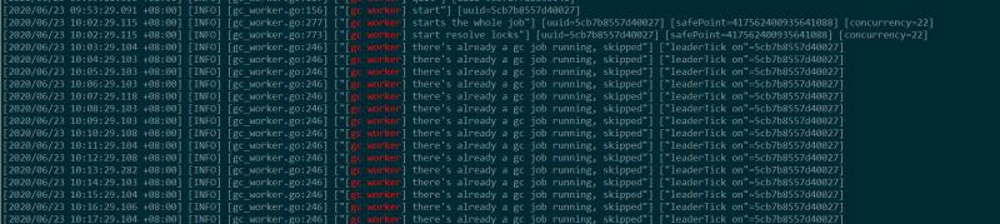
resolveLocks Progress的completed持续一个值,正常应该有抖动才对
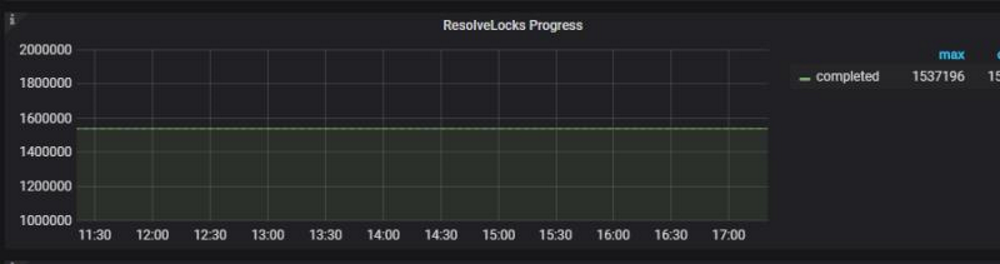

集群已使用70%,后续原本计划drop部分表来释放空间被耽搁
那么是不是region本身除了问题呢,我们用如下命令检查region是否有缺少副本的情况:
进到pd-ctl里面执行命令
region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | length>=$total-length) }"
检查后发现没有缺失,说明region副本无异常
pd监控面板,region health一直没变过
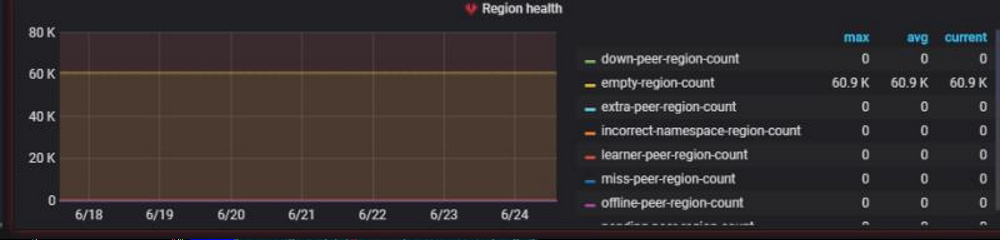
abnormal store也都是正常

分析:
scan lock 和 get txn status 时都可以成功,但是耗时会超过 40 分钟,因为超过 40 分钟了, resolve lock 时 region cache 过期了(10 分钟没有访问),失败重试又会从 scan lock 开始。
然后就进入了循环,出现上面的问题~
region cache 是 10 分钟没有访问,就会 从 pd load 一遍
通过官方给的补丁定位,发现region 8026632存在异常,其分布在tidb05,tidb06,tidb09上
因此怀疑是个别的region gc失败,导致gc一直停留在reslove lock阶段
[sync360@tidb21 bin]$ curl http://192.168.1.1:10080/regions/8026632
{
"region_id": 8026632,
"start_key": "dIAAAAAAAW3LX2mAAAAAAAAACQQZpqoETwAAAAPQAAAAAlq4bA==",
"end_key": "dIAAAAAAAW3LX2mAAAAAAAAACQQZpqpxnwAAAAOgAAAAAmnitw==",
"frames": [
{
"db_name": "snapshot",
"table_name": "table_info_202006",
"table_id": 93643,
"is_record": false,
"index_name": "idx_check_time",
"index_id": 9,
"index_values": [
"1848351632564158464",
"5764607523073734764"
]
}
]
}
[sync360@tidb21 bin]$ ./tikv-ctl --host 192.168.1.1:20160 raft region -r 8026632
region id: 8026632
region state key: \"001\"003\"000\"000\"000\"000\"000zz\"010\"001
region state: Some(region { id: 8026632 start_key: 748000000000016DFFCB5F698000000000FF0000090419A6AA04FF4F00000003D00000FF00025AB86C000000FC end_key: 748000000000016DFFCB5F698000000000FF0000090419A6AA71FF9F00000003A00000FF000269E2B7000000FC region_epoch { conf_ver: 740 version: 61000 } peers { id: 8026633 store_id: 7 } peers { id: 8026634 store_id: 11 } peers { id: 8026635 store_id: 8 } })
raft state key: \"001\"002\"000\"000\"000\"000\"000zz\"010\"002
raft state: Some(hard_state {term: 6 vote: 8026633 commit: 6 } last_index: 6)
apply state key: \"001\"002\"000\"000\"000\"000\"000zz\"010\"003
apply state: Some(applied_index: 6 truncated_state { index: 5 term: 5 })
[sync360@tidb21 bin]$ ./tikv-ctl --host 192.168.1.1:20160 size -r 8026632
region id: 8026632
cf default region size: 0 B
cf write region size: 60.042 MB
cf lock region size: 14.039 MB
我们定位到这个region是对应的一个索引

3.0.5起支持通过 region-cache-ttl 配置修改 Region Cache 的 TTL #12683
tikv_client:
region-cache-ttl: 86400
region cache ttl 的话,如果调大,那么这个时候,只是 cache 的信息在不访问的情况下,过期时间拉长了,真要访问到的 region 信息过期了,只会增加 backoff 的时间,原则上没有其他影响
官方日志记录不全,后又补充了一个工具打印:
可以看出,前面resolveLocks耗时1小时,紧接着region cache TTL fail,说明cache TTL这块有问题
2020/06/28 20:02:39.214 +08:00] [INFO] [lock_resolver.go:215] ["BatchResolveLocks: lookup txn status"] ["cost time"=59m56.324274575s] ["num of txn"=1024]
[2020/06/28 20:02:39.214 +08:00] [WARN] [region_cache.go:269] ["region cache TTL fail"] [region=8026632]
[2020/06/28 20:02:39.214 +08:00] [WARN] [region_request.go:92] ["SendReqCtx fail because can't get ctx"] [region=8026632]
[2020/06/28 20:02:39.219 +08:00] [WARN] [lock_resolver.go:245] ["BatchResolveLocks: region error"] [regionID=8026632] [regionVer=61000] [regionConfVer=740] [regionErr="epoch_not_match:<> "]
[2020/06/28 20:05:12.827 +08:00] [INFO] [lock_resolver.go:215] ["BatchResolveLocks: lookup txn status"] ["cost time"=1h2m29.730427002s] ["num of txn"=1024]
[2020/06/28 20:05:12.828 +08:00] [WARN] [region_cache.go:269] ["region cache TTL fail"] [region=8019447]
[2020/06/28 20:05:12.828 +08:00] [WARN] [region_request.go:92] ["SendReqCtx fail because can't get ctx"] [region=8019447]
[2020/06/28 20:05:12.828 +08:00] [WARN] [lock_resolver.go:245] ["BatchResolveLocks: region error"] [regionID=8019447] [regionVer=60980] [regionConfVer=683] [regionErr="epoch_not_match:<> "]
[2020/06/28 20:05:13.439 +08:00] [INFO] [lock_resolver.go:215] ["BatchResolveLocks: lookup txn status"] ["cost time"=1h2m30.135826553s] ["num of txn"=1024]
于是决定调整region-cache-ttl参数,默认是600,调整到86400,在tidb.yml里,调大的目标是为了能够让scan_lock执行后不至于失败重来,以此来绕过这个问题,并把gc_life_time调整为10分钟,让尽快的触发gc。
调整完后gc一开始还是没有speed,且resolvelock也跟之前一样,没有波动
调整后cache后,偶尔可以看到complete了
cat tidb.log |grep “[2020/06/29”|grep -e ‘gc_worker’ -e ‘range_task’ -e ‘lock_resolver’
[2020/06/29 15:13:23.698 +08:00] [INFO] [gc_worker.go:156] ["[gc worker] start"] [uuid=5cbfbb183740041]
[2020/06/29 15:18:44.482 +08:00] [INFO] [gc_worker.go:187] ["[gc worker] quit"] [uuid=5cbfbb183740041]
[2020/06/29 15:19:03.159 +08:00] [INFO] [gc_worker.go:156] ["[gc worker] start"] [uuid=5cbfbc63b5c00cc]
[2020/06/29 15:25:03.395 +08:00] [INFO] [gc_worker.go:277] ["[gc worker] starts the whole job"] [uuid=5cbfbc63b5c00cc] [safePoint=417703369985753088] [concurrency=22]
[2020/06/29 15:25:03.395 +08:00] [INFO] [gc_worker.go:773] ["[gc worker] start resolve locks"] [uuid=5cbfbc63b5c00cc] [safePoint=417703369985753088] [concurrency=22]
[2020/06/29 15:25:03.395 +08:00] [INFO] [range_task.go:90] ["range task started"] [name=resolve-locks-runner] [startKey=] [endKey=] [concurrency=22]
[2020/06/29 15:26:03.445 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:27:03.307 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:28:03.172 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:29:03.173 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:30:03.434 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:31:03.677 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:32:03.173 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:33:03.186 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:34:03.174 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:35:03.220 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:35:03.395 +08:00] [INFO] [range_task.go:133] ["range task in progress"] [name=resolve-locks-runner] [startKey=] [endKey=] [concurrency=22] ["cost time"=10m0.000165232s] ["completed regions"=496646]
[2020/06/29 15:36:03.498 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:37:03.173 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:38:03.175 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:39:03.173 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:40:03.200 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:41:03.174 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:42:03.181 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:43:03.209 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:44:03.359 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:45:03.179 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:45:03.407 +08:00] [INFO] [range_task.go:133] ["range task in progress"] [name=resolve-locks-runner] [startKey=] [endKey=] [concurrency=22] ["cost time"=20m0.011628551s] ["completed regions"=987799]
[2020/06/29 15:46:03.173 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:47:03.170 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:48:03.291 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:49:03.188 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:50:03.239 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:51:03.175 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:52:03.437 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:53:03.574 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:54:03.525 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:55:03.213 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
[2020/06/29 15:55:03.401 +08:00] [INFO] [range_task.go:133] ["range task in progress"] [name=resolve-locks-runner] [startKey=] [endKey=] [concurrency=22] ["cost time"=30m0.005813553s] ["completed regions"=1579411]
[2020/06/29 15:56:03.190 +08:00] [INFO] [gc_worker.go:246] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=5cbfbc63b5c00cc]
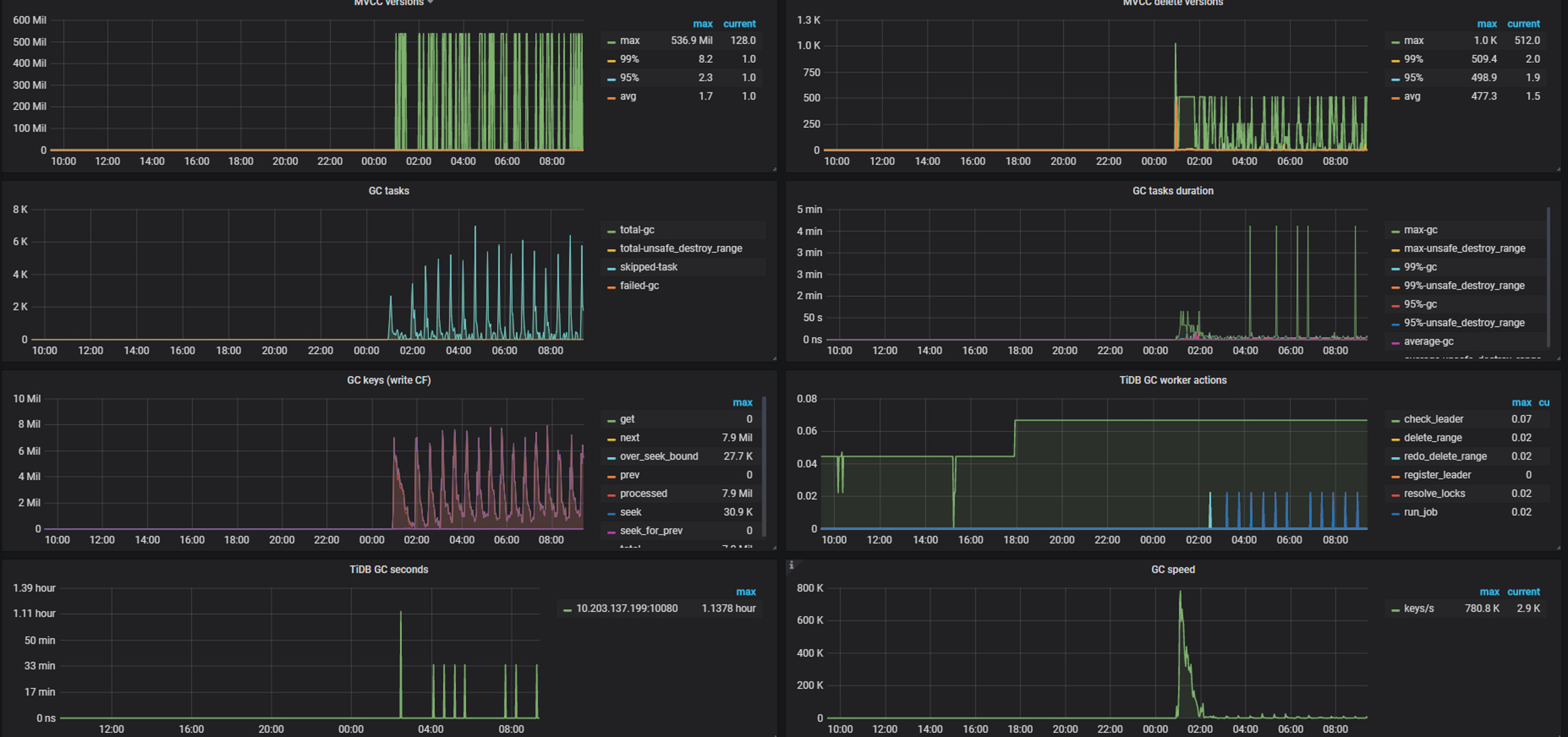
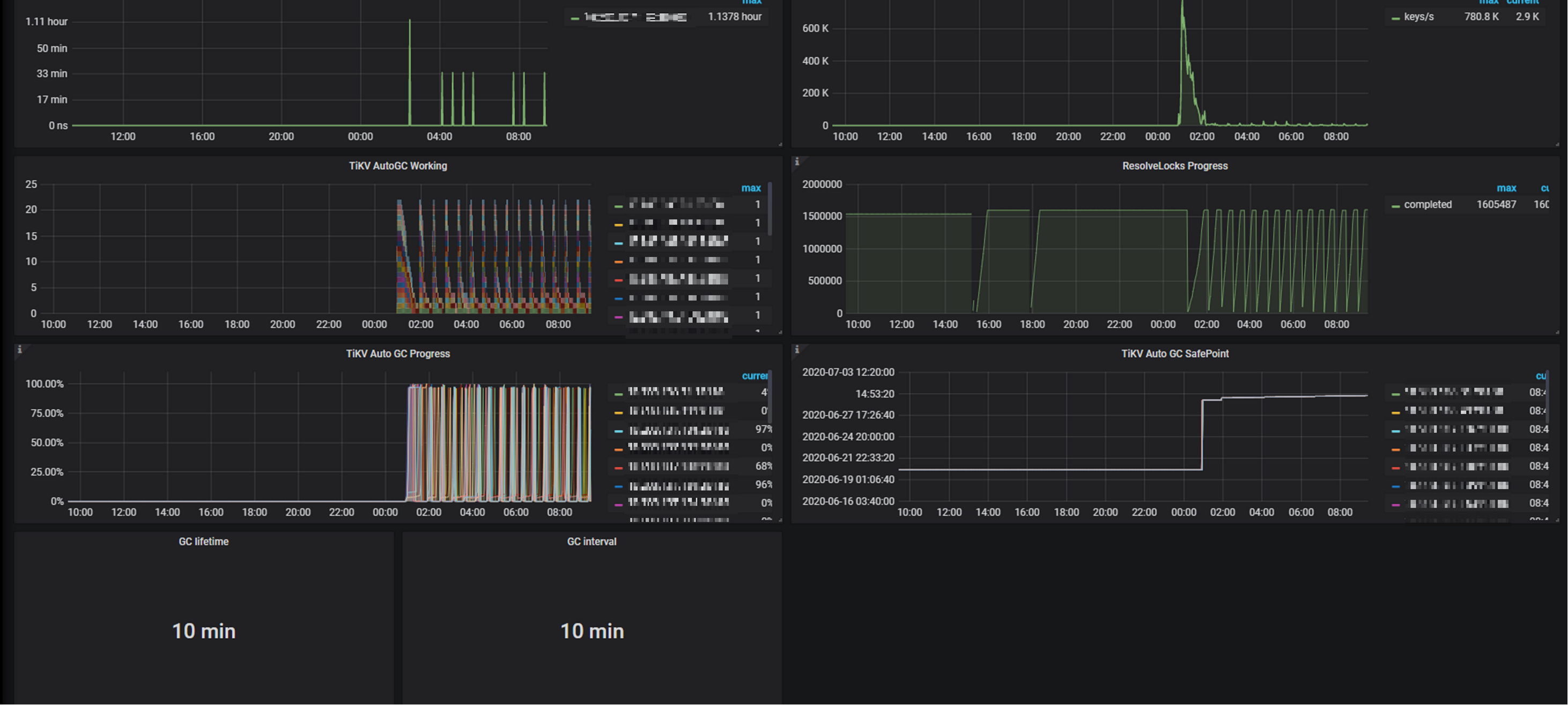
但速度还是很慢,直到30日凌晨1点的时候gc speed完全恢复了正常
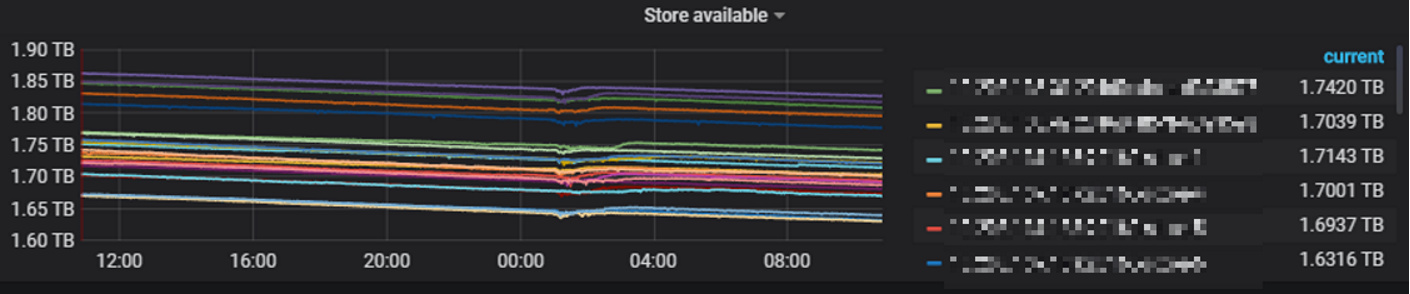
gc生效后,可以看到空间释放出现拐点
四、总结
如果对gc原理理解不够深入,且参数不够熟悉的话,这个案例还是处理起来很费时间的,希望看完本文能够加深您对GC的理解,后续因为这个案例又引发了新的案例,之后会为大家继续带来分享~