价值几十万的TiDB优化
--2021-06-12 刘春雷
首先请大家理解我这次成为了“标题党”,违背了我每次的内容至上的追求;因为这次业务损失了几十万,所以就叫:价值几十万的TiDB优化
1、前言
58同城每年的年初为业务流量高峰,例如租房、找工作、本地服务等等,几乎所有的业务都会疯狂增长,对数据库来说是个很大的挑战。TiDB数据库同样压力山大~
TiDB很多重要的业务,年前都优化过,扩容过,也反馈给开发相关慢SQL、业务逻辑问题等,就是希望在年后能平稳度过业务高峰期。
然鹅,事与愿违,面对全业务线的高峰,TiDB某重点业务出问题了:3月初某天,业务反馈写入慢,导致部分订单损失,价值几十万,情况万分危急~
2、问题排查定位
【基础信息】:
TiDB版本:4.0.2
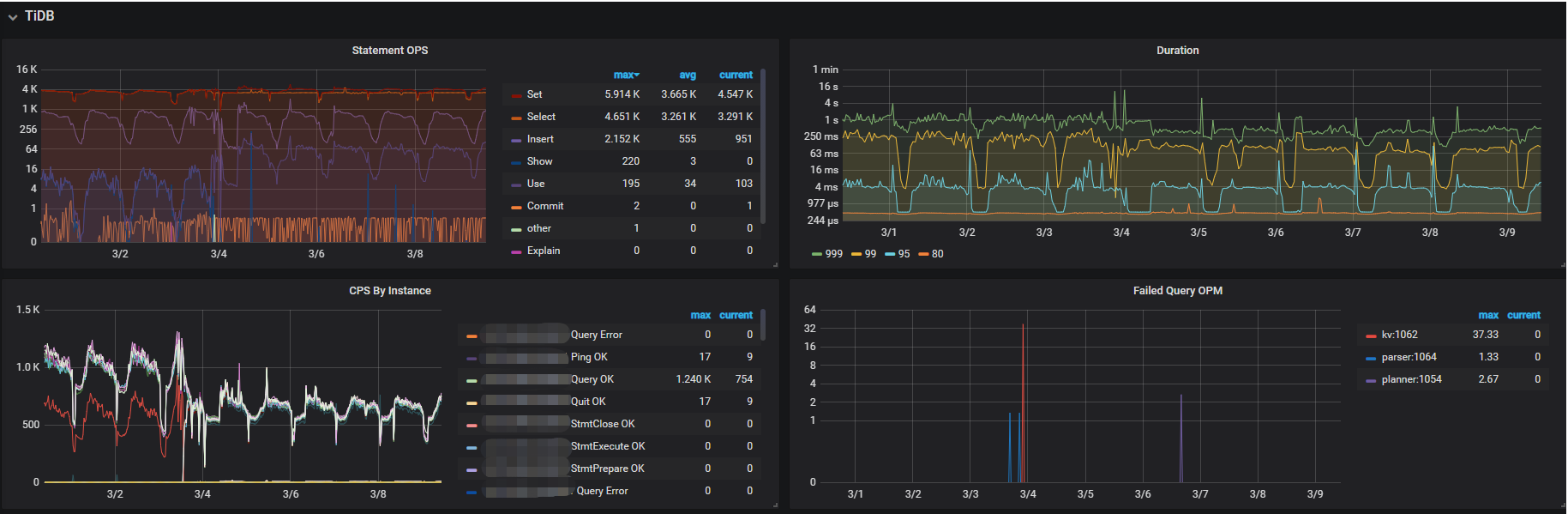
2.1、监控情况
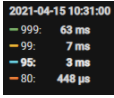
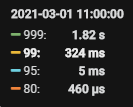
监控信息:可以从监控看出,SQL执行时间已经在1s-2s+ 了,但是没有突增
业务损失原因:业务抛弃的时间阈值是3s,即业务逻辑+SQL的整体时间超过3s ,此订单就抛弃了,导致了损失。
【TiDB监控】:

【系统监控】:
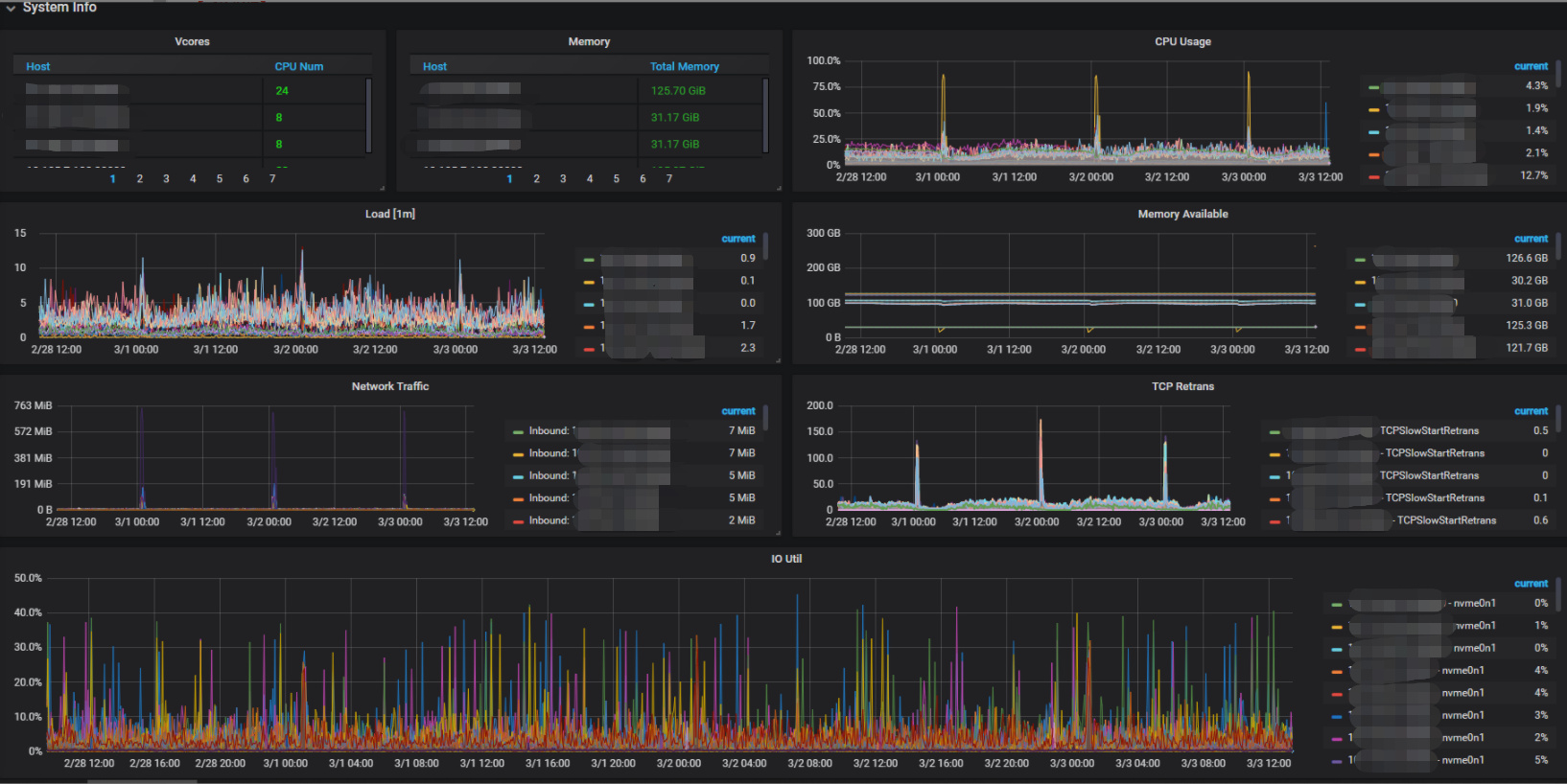
2.2、慢SQL量情况
DBA同样排查慢SQL情况,发现慢SQL量在出问题的时间,没有明显增长很多,只是增长了一点
注:中间的高峰为操作导致,忽略
【慢SQL趋势图】:

【慢SQL量详细】:
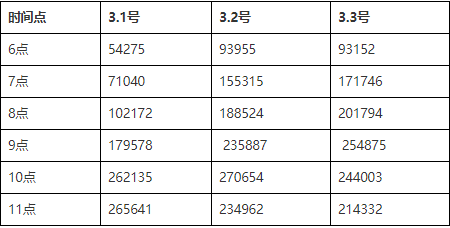
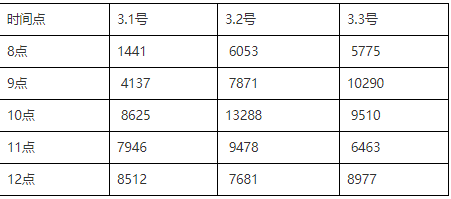
【超1.5s 慢SQL】:
超过1.5s的慢SQL信息如下,这些可能导致业务时间超3s,抛弃导致损失~

【超1.5s慢SQL量详细】:
2.3、慢SQL具体分析
发现量最大的慢SQL是节前1月份已经通知开发的慢SQL,开发没跟进解决…导致节后:业务流量增加的情况下,集群写入性能不佳。
总共2种慢SQL,分析可以添加一个联合索引解决。之前问题为:查询没有覆盖到所有字段导致性能差,进而影响了整个集群的性能。
2.3.1、慢查询SQL1
【问题SQL】:
SELECT COUNT(0) FROM xxx WHERE xx_date >= ‘xxx’ AND xx_date <= ‘xxx’ AND xxx_id = xxx AND xxx2_id = xxx AND xxx_type = 1 ;
【分析SQL量】:
select count(*),avg(Query_time),min(time),max(time),max(Query_time) from cluster_slow_query where time >=‘2021-03-04 00:00:00’ and time<=‘2021-03-04 23:59:59’ and Digest=‘xxx’;
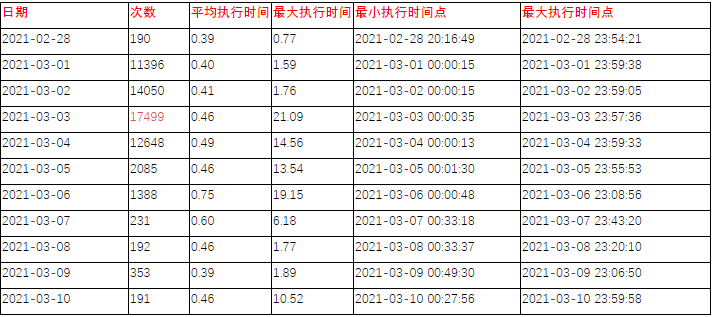
【优化前执行计划】:
执行计划:发现扫描的行数比较多,且表的健康度不高,导致执行计划不正常,DBA尝试analyze表解决。
【处理】:
analyze table xxx;
【analyze后续执行计划】:
analyze表后,执行计划算是正常了,扫描条数下降了,但是索引不是最优,还需要索引优化

【索引优化】:
添加索引: alter table xxx add index idx_xx(xx_id,xx2_id,xx_type,xx_date);
【添加索引后的执行计划】 :

2.3.2、慢查询SQL2
SELECT * FROM xxx WHERE xx_date >= ‘xx’ AND xx_date <= ‘xx’ AND xx_id = xx AND xx_id = xx AND xx_type = 0 ORDER BY xx_date DESC LIMIT 0,400;
【分析SQL量】 :
select count(*),avg(Query_time),min(time),max(time),max(Query_time) from cluster_slow_query where time >=‘2021-03-01 00:00:00’ and time<=‘2021-03-01 23:59:59’ and Digest=‘xx’;
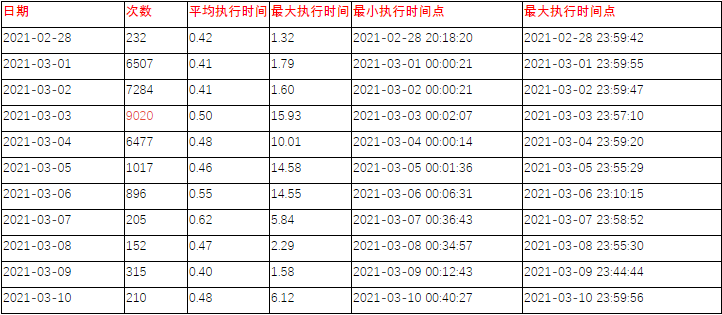
【优化前执行计划】:

【同样添加索引后的执行计划】:

2.4、执行索引优化
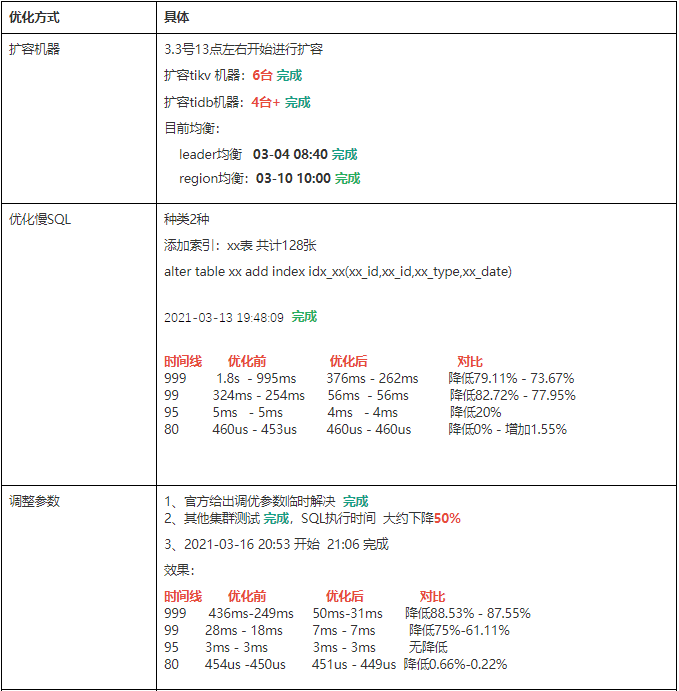
因表比较大,数量:分表128张,且白天要控制速度添加,减少对业务的影响,晚上适当加速添加
共计:
开始:2021-03-03 13:55:49
结束:2021-03-13 19:48:09
总共历经: 10天+
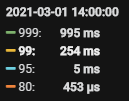
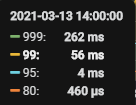
2.5、索引优化后的效果
【监控情况】:

3、扩容
同时,出问题的当天,我们就对TiDB的资源进行了扩充,扩容TiDB Server 、TiKV Server。
但扩容是无法快速解决问题的,这个是TiDB后期可以考虑优化的事情,不像MySQL,我可以快速扩容从节点,来提升读性能这样;TiDB需要均衡好数据后,才能真正有性能提升。这点确实让人头疼~
【扩容详细】:
3.3号13点左右开始进行扩容
扩容tikv 机器: 6台
扩容tidb机器: 4台+
目前均衡:
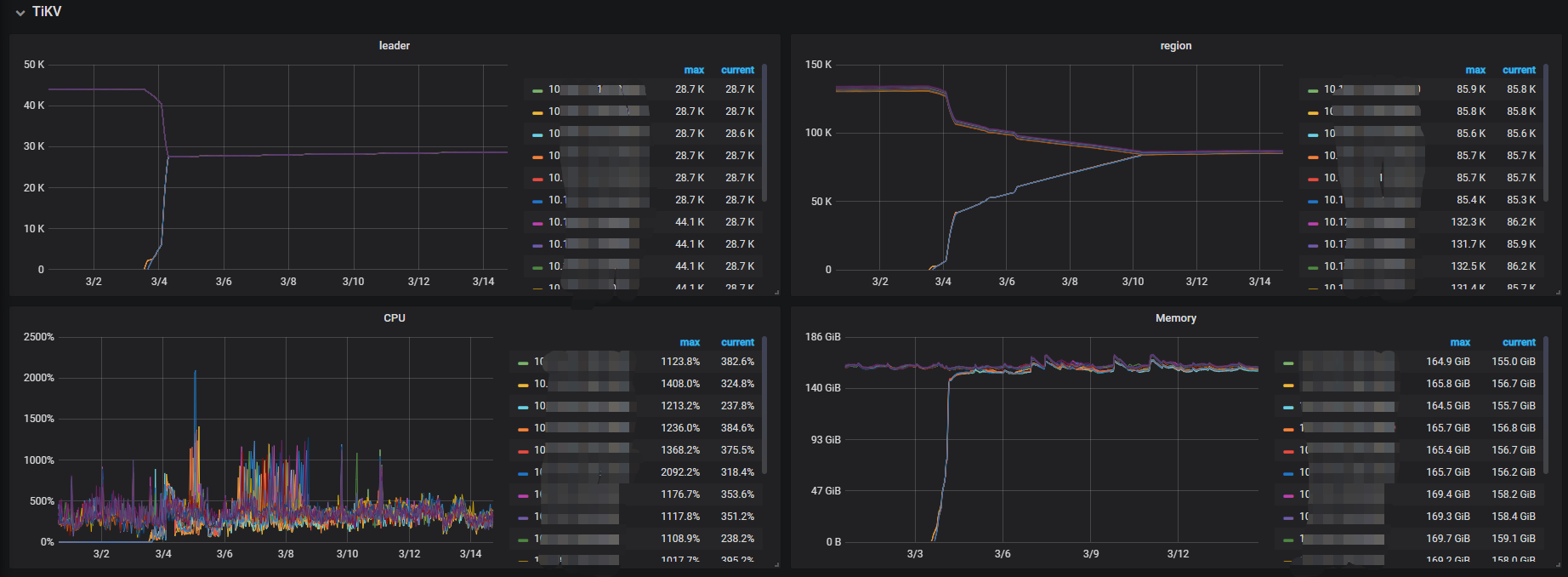
leader均衡 03-04 08:40 完成
region均衡: 03-10 10:00 完成
【监控情况】:
leader均衡很快,region均衡的时间比较长
4、参数调优
问题当天,官方就高优支持我们进行故障的处理与调优,给了一些调优的参数。这里要重点表扬~官方服务实在太好!
4.1、参数调优及说明
【调优参数】:
server_configs:
tikv:
raftdb.defaultcf.force-consistency-checks: false
raftstore.apply-max-batch-size: 256
raftstore.apply-pool-size: 10
raftstore.hibernate-regions: true
raftstore.messages-per-tick: 1024
raftstore.perf-level: 5
raftstore.raft-max-inflight-msgs: 2048
raftstore.store-max-batch-size: 256
raftstore.store-pool-size: 8
raftstore.sync-log: false
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 12
rocksdb.defaultcf.force-consistency-checks: false
rocksdb.lockcf.force-consistency-checks: false
rocksdb.raftcf.force-consistency-checks: false
rocksdb.writecf.force-consistency-checks: false
server.grpc-concurrency: 8
storage.block-cache.capacity: 148G
storage.scheduler-worker-pool-size: 8
【参数详细说明】:

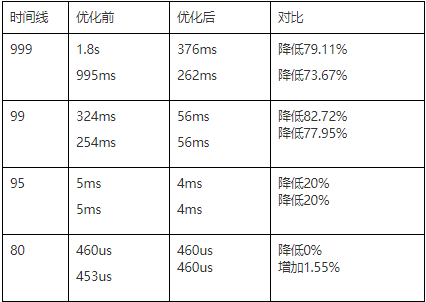
4.2、修改参数效果
因为调整参数需要reload重启tikv实例,这样影响比较大,如果出现性能不升反降,再调整回去,影响太大,所以我们先在其他集群上进行测试,发现确实提升明显,多数SQL执行时间都下降至少50%+ 。
于是我们在2021-03-16 20:53 开始调整参数,reload tikv, 21:06 完成,效果如下:
【TiDB监控】:

【SQL执行时间对比】:
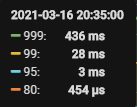
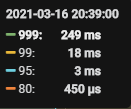
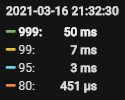
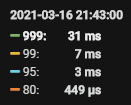
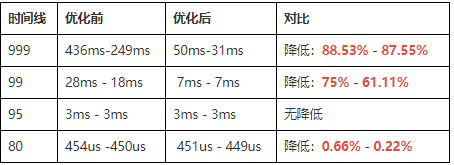
【具体数据】:
5、数据清理
后期我们与业务沟通,之前迁移至TiDB为整个集群迁移的,部分表不用,且占了很多的空间,于是我们也进行了数据清理,即不需要保留的数据及时清理掉,减轻集群的压力。
清理前: 23.7T
清理后: 14.2 T
磁盘降低: 9.5T ,占比: 40.08%
【清理数据后的SQL执行时间效果】:降低明显
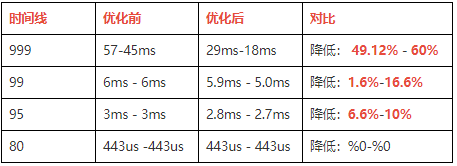
6、资源回收
优化后的集群性能很好,但是TiKV机器比较多了,出于资源的考虑,我们回收了3台tikv server,回收后的性能也能很好的满足业务。
【下线后的SQL执行时间】:
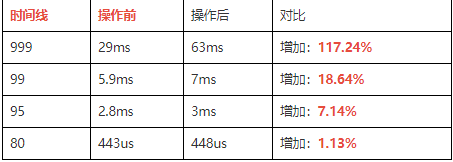
【磁盘信息】:
总共 已用 占比
49.9T 14.6T 29.25%
7、总结
7.1、优化措施进度总结
此次事故,业务损失了几十万,算是一个深刻的教训了,但是总结起来还是受益匪浅,希望给大家也看下。
反思:
-
重要的业务要定期查看集群状态、性能
-
已经反馈给开发的问题,要跟进优化落地,否则后面还是会发生问题
-
要多角度优化,不仅DBA集群方面优化,业务也要在业务侧进行优化
-
总结的参数,后续默认成为了新集群的默认参数,老集群调优也经常用到,多个集群SQL执行时间的优化效果都超级好,大家可以按需测试
-
DBA这边暂时还没做SQL执行时间的报警,后面会补充上
-
TiDB如何快速通过扩容的方式提升性能,这个希望TiDB能做出来
-
表健康度影响SQL执行计划,过低的表要定期analyze

【最后SQL执行时间】