
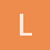
大家好。首次发文,多多指教。(没想到正要发此文的时候,发现PingCAP公众号今天的推送头条正是一篇真 HTAP 的文章,真巧)
接下来,废话不说,入正题说下此文的缘起:上周日去参加了 TUG 在北京转转的第一次线下活动。中间提问环节,晓乐问到了一个问题:各公司使用 TiDB 主要是什么场景?从在场同学们的回答来看,大多数用于的还是 TP 的场景。
而我们却正好不同,主要产品面临的是AP的场景(介绍一下,公司的主要产品是 HENGSHI SENSE 一站式数据分析平台,适配当前多种主流数据源,满足企业客户对于数据整合和分析可视化等方面的需求)。在我们的客户场景当中,自助分析敏捷探索的需求,会对数据源的 OLAP 能力有比较高的要求。
在会后,就想着基于我们的产品对接 TiDB 数据源(也是为了减少测试的工作量并且贴近实际客户场景),做一个 AP 的场景测试,以便给想将 TiDB 用于 AP 场景的小伙伴们先探一个路。因为 TiDB 的目标是 HTAP ,其中作为一个实时数仓的定位,在很多场景下是很有意义的,也是我们的产品和 TiDB 可以整合的一点。我们的产品在数据源这边已经支持了 TiDB,只需要填写连接参数就可以连接上数据源。

于是就开始设计场景,准备数据,测试硬件和环境。基本上按照官方文档部署 TiDB 之后,接上我们的产品测试,可以直接就跑通了。
此外,为了做对比测试,将衡石产品中的“加速引擎”(Hengshi Engine,以下简称HE)也作为一个对比测试对象。这是我们产品内置的数仓,目的是为了解决很多中小客户没有 OLAP 能力的问题,为它们提供一种即插即用的数据分析IT基础设施。
测试环境
测试环境如下表所示:
| DB | 模块 | 配置 |
|---|---|---|
| HE | Master | 16C32G * 1,这是HE的Meta节点,负责分发查询请求,汇总结果 |
| HE | Worker | 16C32G * [1,3],这是HE的查询节点,负责具体执行查询请求 |
| HE | 说明 | HE有两个环境:1台Worker机器的环境标注为HE1, 3台Worker机器的环境标注为HE3 |
| TiDB2.1.15 | PD | 8C8G * 2 |
| TiDB2.1.15 | TiDB | 16C48G * 3 |
| TiDB2.1.15 | TiKV | 16C32G * 3 |
| TiDB2.1.15 | 说明 |
对这个表格的说明做下解释: TiDB 采用典型的3 TiKV -3 TiDB -2 PD 配置。HE采用1个 worker (HE1)和3个 worker (HE3)两种执行引擎配置进行对比。
测试场景
场景1: 销售活动分析
数据为从客户场景中脱敏(去掉敏感的用户信息字段后)的真实业务下的 CRM 数据,具体 Schema 如下所示(字段含义比较明显,就不详细解释了):
这是一个实际用户场景,其特点如下:
- 在线查询场景,最好在秒级查询时间内返回结果。
- 1500万条,数据量适中,对于1-3台机器的小规模数据库能产生足够压力用于对比数据库性能。
- 用于分组的字段分别是10(品牌),1万(商品),100万(客户)量级,在1500万总量上已经覆盖了比较极端的分组情况。
- 查询包含了全表聚合计算,分组聚合计算和对时间字段变换的计算,在单表查询的场景下场景比较典型。
数据量合适,查询典型,同时是一个实际业务场景,比造的场景更有说服力,这也是我们最终没有造数据造场景的原因。
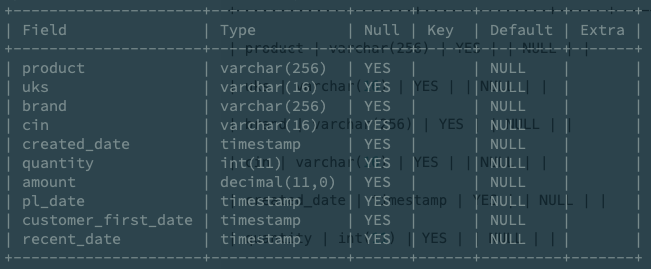
通过和公司的客户成功团队沟通,我们整理出一个针对2014-2017年范围,包含多种维度销售分析的报表(报表链接:http://106.75.77.137:8080/#/share/74BAA972/dashboard/82013CF3 )。
这里插播一下题外感受,从这份报表可以看出,对业务分析来说除了研究如何分析比较重要,好的展现形式对于让人理解数据背后的含义也是必不可少的。以下按从左至右,从上至下的顺序说明:
- 销售额: KPI 图,突出总计的结果,统计所有商品的销售总额。可以反映全表扫描并行聚合计算能力。
- 销售量:统计所有商品的销售总量。同“销售额”表,反映并行聚合计算的能力。
- 彩妆与护肤销售额:用突出横向对比结果的柱状图,对比不同品牌的销售额差异。反映出对一个维度聚合计算的能力。
- 每年7月是销售额高峰:采用热力图形式,方便找出每种品牌各自在哪个月份上是销售高峰。背后是对两个维度一个度量的聚合计算。
- 新客相对谨慎,回头客一掷千金:采用桑基图形式,视觉效果非常突出,方便从不同角度分析客户-品牌间的关联度。背后是对两个维度一个度量的聚合计算。
- 品牌活动的回召能力:采用堆叠柱状图形式,突出不同品牌对于客户回召能力的区别。背后是两个维度一个度量的聚合计算。
- 2017 H1 品牌活动带来的销量和销售额:折线图形式,对比时间区间内总的销售额-销售量的关联关系。背后是一个维度两个度量的聚合计算。
- 2017 H1 不同客源消费额:用表格形式展示分组维度和对比维度的数据度量细节。背后是三个维度和一个度量的聚合计算。(表格形式扩展性非常强,可以支持N维度M度量分析)
从业务上说,是一个真实的业务分析场景;从查询类型上说,包含了扫描全表的聚合计算,按照分析维度的聚合计算,是一般的典型分析场景。
测试方法则采用以加载HENGSHI SENSE仪表盘(参见下文测试报告)触发并行查询,记录获取到所有查询数据的总 API 相应时间的方式,以反映业务场景下的实际体验。
同时, HENGSHI SENSE 产品的数据分析与建模都会用到内部的数据查询引擎 HQL (Hengshi Query Language),今天的场景中所有的最终 SQL 就是通过 HQL 生成的。我们在产品中启用了 Debug 日志,拿到了 HQL 生成的每个 Chart 的 SQL ,具体参考 http://106.75.77.137:8080/embed.html#/app/74BAA972/dashboard/F5EBF24C/chart/FA48D779 . 再从中,我们挑出6个比较有特点的 SQL 测试单独查询时间。
场景2: 特定 SQL 测试
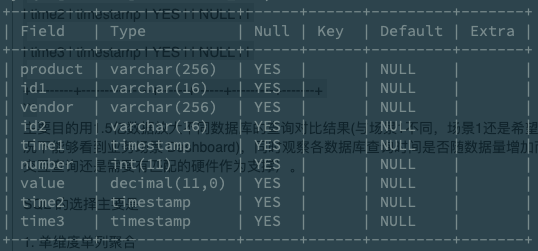
数据为场景1中的 CRM 数据简化 Schema 之后的一个版本,具体 Schema 如下所示(字段含义比较明显,就不详细解释了):
主要目的用1.5亿数据放大不同数据库的查询对比结果(与场景1不同,场景1还是希望能够在人类可以忍受的情况下能够看到业务场景 Dashboard),同时观察各数据库查询时间是否随数据量增加而线性增长(1.5亿数据的交互查询还是需要有匹配的硬件作为支撑)。
SQL 的选择主要是
- 单维度单列聚合
- 单维度多列聚合
- 多维度单列聚合
- 多维度多列聚合
具体SQL也是通过参考相应的 Dashboard(参考后文的测试报告的4-7页,慎点,会loading很长时间)触发 HQL 执行日志拿到的,参考http://106.75.77.137:8080/embed.html#/app/74BAA972/dashboard/F5EBF24C/chart/B9E015BA .
测试方法是在数据源中单独运行每条SQL查询时间的方式,同时用1500万数据循环复制到1.5亿数据,对两种量级数据分别做测试对比。
测试报告
报告截图如下(详见: http://106.75.77.137:8080/#/share/app/74BAA972/dashboard/F5EBF24C , 本报告完全用 HENGSHI SENSE 产品完成,与下面的截图不同,里面的每一个图表都可以打开查看详情哦)

结论
从测试结果看, TiDB 2.1.15 的兼容性不错,部署也相对简单,基本上接上去了就可以跑通,但是这个版本的 TiDB 在 AP 场景下的能力还是较为薄弱的。我们也和 PingCAP 的同学做了沟通,有一些初步的想法和结论:
- 和 PingCAP 的同学一起整理分析了 HQL 生成的 SQL,发现这些 SQL 语句含有较多的 CAST 运算,确认 CAST 运算会在某些场景下对 TiDB 的性能有影响,主要原因是 TIKV Coprocessor 的 CAST 函数还不完善,所以 CAST 函数并没有下推到 TiKV 上并行的计算,导致聚合函数也不能下推到 TiKV 上并行的计算,影响了聚合函数的执行效率。这个是我们后续考虑优化 HE 和 HQL 的一点,同时考虑扔掉 CAST 再做一轮测试。
- 前段时间 TiDB 也发布了 3.0 的版本,从官方宣传来看,在性能方面有了很大的提升,我们内部测试也得到了验证,但是因为时间关系,还没有全部测试完成,等下周有机会出一篇 TiDB 3.0 的测试报告:)