

【是否原创】是
【首发渠道】TiDB 社区
【首发渠道链接】其他平台首发请附上对应链接
【正文】
一、背景
一般情况下使用 TiDB 单表大小为千万级别以上在业务中性能最优,但是在实际业务中总是会存在小表。例如配置表对写请求很少,而对读请求的性能的要求更高。TiDB 作为一个分布式数据库,大表的负载很容易利用分布式的特性分散到多台机器上,但当表的数据量不大,访问又特别频繁的情况下,数据通常会集中在 TiKV 的一个 Region 上,形成读热点,更容易造成性能瓶颈。
TiDB v6.0.0(DMR) 版本推出了缓存表的功能,第一次看到这个词的时候让我想到了 MySQL 的内存表。MySQL 内存表的表结构创建在磁盘上,数据存放在内存中。内存表的缺点很明显。当 MySQL 启动着的时候,表和数据都存在,当 MySQL 重启后,表结构存在,数据消失。TiDB 的缓存表不存在这个问题。从 asktug 论坛中看到很多小伙伴都很期待缓存表的表现,个人也对它的性能很期待,因此在测试环境中实际看看缓存表的性能如何。
二、缓存表的使用场景
以下部分内容来自官方文档,详情见 缓存表
TiDB 缓存表功能适用于以下特点的表:
- 表的数据量不大
- 只读表,或者几乎很少修改
- 表的访问很频繁,期望有更好的读性能
关于第一点官方文档中提到缓存表的大小限制为包含索引在内的所有 key-value 记录的总大小不能超过 64 MB。实际测试使用 Sysbench 生成下文中表结构的表从 20w 提高到 30w 数据量时无法将普通表转换为缓存表,因此生产环境中实际使用缓存表的场景应该最多不超过几十万级别的数据量。关于缓存表对包含读写操作方面的性能,使用多种不同的读写请求比例进行了测试,相较普通表均没有达到更好的性能表现。这是因为为了读取数据的一致性,在缓存表上执行修改操作后,租约时间内写操作会被阻塞,最长可能出现 tidb_table_cache_lease 变量值时长的等待,会导致 QPS 降低。因此缓存表更适合只读表,或者几乎很少修改的场景。
缓存表把整张表的数据从 TiKV 加载到 TiDB Server 中,查询时可以不通过访问 TiKV 直接从 TiDB Server 的缓存中读取,节省了磁盘IO和网络带宽。使用普通表查询时,返回的数据量越多索引的效率可能越低,直到和全表扫描的代价接近优化器可能会直接选择全表扫描。缓存表本身数据都在 TiDB Server 的内存中,可以避免磁盘 IO,因此查询效率也会更高。以配置表为例,当业务重启的瞬间,全部业务连接一起加载配置,会造成较高的数据库读延迟。如果使用了缓存表,读请求可以直接从内存中读取数据,可以有效降低读延迟。在金融场景中,业务通常会同时涉及订单表和汇率表。汇率表通常不大,表结构很少发生变化因此几乎不会有 DDL,加上每天只更新一次,也非常适合使用缓存表。其他业务场景例如银行分行或者网点信息表,物流行业的城市、仓号库房号表,电商行业的地区、品类相关的字典表等等,对于这种很少新增记录项的表都是缓存表的典型使用场景。
三、测试环境
1.硬件配置及集群拓扑规划
使用 2 台云主机,硬件配置为 4C 16G 100G 普通 SSD 硬盘。
| Role | Host | Ports |
|---|---|---|
| alertmanager | 10.0.0.1 | 9093/9094 |
| grafana | 10.0.0.1 | 3000 |
| pd | 10.0.0.1 | 2379/2380 |
| pd | 10.0.0.2 | 2379/2380 |
| pd | 10.0.0.1 | 3379/3380 |
| prometheus | 10.0.0.1 | 9090/12020 |
| tidb | 10.0.0.1 | 4000/10080 |
| tidb | 10.0.0.2 | 4000/10080 |
| tikv | 10.0.0.1 | 20162/20182 |
| tikv | 10.0.0.1 | 20160/20180 |
| tikv | 10.0.0.2 | 20161/20181 |
2. 软件配置
| 软件名称 | 软件用途 | 版本 |
|---|---|---|
| CentOS | 操作系统 | 7.6 |
| TiDB 集群 | 开源分布式 NewSQL 数据库 | v6.0.0 DMR |
| Sysbench | 压力测试工具 | 1.0.20 |
3.参数配置
server_configs:
tidb:
log.slow-threshold: 300
new_collations_enabled_on_first_bootstrap: true
tikv:
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: false
pd:
replication.enable-placement-rules: true
replication.location-labels:
- host
由于硬件条件受限,只有 2 台普通性能的云主机混合部署的集群(实际上和单机部署也差不多了)。单机 CPU 核数较少且 TiDB Server 没有做负载均衡所以并发无法调整太高。以下测试均使用一个 TiDB Server 节点进行压测,因此不用特别关注本次测试的测试数据,可能会跟其他测试结果有所出入,不代表最佳性能实践和部署,测试结果仅限参考。
四、性能测试
Sysbench 生成的表结构
CREATE TABLE sbtest1 (
id int(11) NOT NULL AUTO_INCREMENT,
k int(11) NOT NULL DEFAULT '0',
c char(120) NOT NULL DEFAULT '',
pad char(60) NOT NULL DEFAULT '',
PRIMARY KEY (id),
KEY k_1 (k)
) ENGINE = InnoDB CHARSET = utf8mb4 COLLATE = utf8mb4_bin AUTO_INCREMENT = 1
读性能测试
测试主要参数
oltp_point_select 主键查询测试(点查,条件为唯一索引列)
主要 SQL 语句:
SELECT c FROM sbtest1 WHERE id=?
select_random_points 随机多个查询(主键列的 selete in 操作)
主要 SQL 语句:
SELECT id, k, c, pad FROM sbtest1 WHERE k IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
select_random_ranges 随机范围查询(主键列的 selete between and 操作)
主要 SQL 语句:
SELECT count(k) FROM sbtest1 WHERE k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ? OR k BETWEEN ? AND ?
oltp_read_only 只读操作(包含聚合、去重等)
主要 SQL 语句:
SELECT c FROM sbtest1 WHERE id=?
SELECT SUM(k) FROM sbtest1 WHERE id BETWEEN ? AND ?
SELECT c FROM sbtest1 WHERE id BETWEEN ? AND ? ORDER BY c
SELECT DISTINCT c FROM sbtest1 WHERE id BETWEEN ? AND ? ORDER BY c
Sysbench 测试命令示例
sysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \
--threads=8 --report-interval=10 --db-driver=mysql oltp_point_select --tables=1 --table-size=5000 run
sysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \
--threads=8 --report-interval=10 --db-driver=mysql oltp_read_only --tables=1 --table-size=5000 run
sysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \
--threads=8 --report-interval=10 --db-driver=mysql select_random_points --tables=1 --table-size=5000 run
sysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 \
--threads=8 --report-interval=10 --db-driver=mysql select_random_ranges --tables=1 --table-size=5000 run
一、使用普通表
1.单表数据量 5000,测试 QPS
| threads/request type | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | |
|---|---|---|---|---|---|
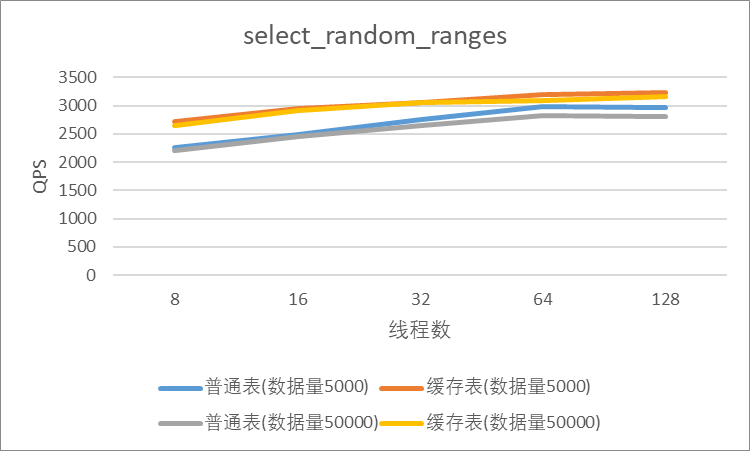
| 8 | 2214 | 1985 | 3190 | 2263 | |
| 16 | 3199 | 2414 | 3412 | 2491 | |
| 32 | 4454 | 2867 | 3898 | 2763 | |
| 64 | 5792 | 3712 | 4321 | 2981 | |
| 128 | 7639 | 4964 | 4474 | 2965 |
2.单表数据量 50000,测试 QPS
| threads/request type | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | |
|---|---|---|---|---|---|
| 8 | 4874 | 2808 | 2841 | 2207 | |
| 16 | 5042 | 3429 | 3172 | 2448 | |
| 32 | 6754 | 4290 | 3405 | 2651 | |
| 64 | 8989 | 5282 | 3831 | 2818 | |
| 128 | 12565 | 6470 | 3996 | 2811 |
二、使用缓存表
1.单表数据量 5000,测试 QPS
| threads/request type | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | |
|---|---|---|---|---|---|
| 8 | 15780 | 10811 | 5666 | 2716 | |
| 16 | 23296 | 11399 | 6417 | 2948 | |
| 32 | 28038 | 11313 | 6907 | 3050 | |
| 64 | 32924 | 11377 | 7217 | 3200 | |
| 128 | 33962 | 11413 | 7199 | 3232 |
2.单表数据量 50000,测试 QPS
| threads/request type | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | |
|---|---|---|---|---|---|
| 8 | 15910 | 16540 | 5359 | 2646 | |
| 16 | 21945 | 17022 | 5999 | 2915 | |
| 32 | 25614 | 17356 | 6355 | 3065 | |
| 64 | 31782 | 17410 | 6690 | 3088 | |
| 128 | 35009 | 17584 | 6713 | 3161 |
三、性能对比



读写混合性能测试
测试主要场景参数
oltp_read_write 表示混合读写。
point_selects(每个事务里点查的数量)
delete_inserts(每个事务里插入/删除组合的数量)
主要 SQL 语句:
INSERT INTO sbtest1 (id, k, c, pad) VALUES (?, ?, ?, ?)
DELETE FROM sbtest1 WHERE id=?
SELECT c FROM sbtest1 WHERE id=?
本次测试通过单个事务中请求类型的数量 --delete_inserts 固定为 10 且调整 --point_selects 参数的值来模拟不同读写比例下的性能差异,其余请求参数使用默认值,具体命令可参考下面 Sysbench 测试命令示例。
Sysbench 测试命令示例
sysbench --mysql-host=10.0.0.1 --mysql-port=4000 --mysql-db=sbtest --mysql-user=root --time=600 --threads=8 --report-interval=10 --db-driver=mysql oltp_read_write --tables=1 --table-size=5000 --point_selects=10 --non_index_updates=0 --delete_inserts=10 --index_updates=0 run
一.使用普通表
1.单表数据量 5000,测试 QPS
| threads/--point_selects | 10 | 40 | 160 | 640 | |
|---|---|---|---|---|---|
| 8 | 869 | 2289 | 3852 | 5090 | |
| 16 | 1014 | 2139 | 4354 | 6094 | |
| 32 | 1075 | 2205 | 5089 | 6944 | |
| 64 | 605 | 1861 | 5160 | 8395 | |
| 128 | 877 | 2127 | 4332 | 9257 |
2.单表数据量 50000,测试 QPS
| threads/--point_selects | 10 | 40 | 160 | 640 | |
|---|---|---|---|---|---|
| 8 | 1107 | 2144 | 3312 | 4439 | |
| 16 | 1108 | 2103 | 3738 | 5702 | |
| 32 | 1055 | 2228 | 4325 | 6770 | |
| 64 | 1062 | 1397 | 5367 | 8209 | |
| 128 | 981 | 1838 | 7235 | 17472 |
二、使用缓存表
1.单表数据量 5000,测试 QPS
| threads/--point_selects | 10 | 40 | 160 | 640 | |
|---|---|---|---|---|---|
| 8 | 711 | 1322 | 2123 | 2787 | |
| 16 | 361 | 665 | 1274 | 2870 | |
| 32 | 400 | 627 | 1394 | 2997 | |
| 64 | 323 | 804 | 1853 | 4100 | |
| 128 | 372 | 680 | 1847 | 4704 |
2.单表数据量 50000,测试 QPS
| threads/--point_selects | 10 | 40 | 160 | 640 | |
|---|---|---|---|---|---|
| 8 | 974 | 2726 | 3716 | 1804 | |
| 16 | 787 | 1366 | 1736 | 2176 | |
| 32 | 673 | 1231 | 2338 | 4627 | |
| 64 | 572 | 1384 | 3120 | 7755 | |
| 128 | 557 | 1104 | 2907 | 7486 |
三、性能对比




五、遇到的问题
- 尝试将 30w 数据的表改为缓存表时报错
ERROR 8242 (HY000): 'table too large' is unsupported on cache tables。
目前 TiDB 对于每张缓存表的大小限制为 64 MB,因此太大的表无法缓存在内存中。另外,缓存表无法执行普通的 DDL 语句。若要对缓存表执行 DDL 语句,需要先使用 ALTER TABLE xxx NOCACHE 语句去掉缓存属性,将缓存表设回普通表后,才能对其执行其他 DDL 语句。
- 测试过程中缓存表性能出现了不稳定的情况,有些时候缓存表反而比普通表读取性能差,使用 trace 语句(
TRACE SELECT * FROM sbtest1;)查看发现返回结果中出现了regionRequest.SendReqCtx,说明 TiDB 尚未将所有数据加载到内存中,多次尝试均未加载完成。把tidb_table_cache_lease调整为 10 后没有出现该问题。
在 asktug 中向研发大佬提出了这个问题得到了解答。根据 https://github.com/pingcap/tidb/issues/33167 中的描述,当机器负载较重时,load table 需要 3s 以上
,但是默认的 tidb_table_cache_lease 是 3s,
表示加载的数据是立即过时的,因此需要重新加载,并且该过程永远重复。导致了浪费了大量的 CPU 资源并且降低了 QPS。目前可以将 tidb_table_cache_lease 的值调大来解决,该问题在 master 分支中已经解决,后续版本应该不会出现。
- 根据测试结果,写入较为频繁的情况下缓存表的性能是比较差的。在包含写请求的测试中,缓存表相较于普通表的性能几乎都大幅下降。
在 lease 过期之前,无法对数据执行修改操作。为了保证数据一致性,修改操作必须等待 lease 过期,所以会出现写入延迟。例如 tidb_table_cache_lease 为 10 时,写入可能会出现较大的延迟。因此写入比较频繁或者对写入延迟要求很高的业务不建议使用缓存表。
六、测试总结
读性能
单表 5000,缓存表相比普通表提升的百分比
| threads/request type | oltp_point_select |
|---|---|
| 8 | 612.73% |
| 16 | 628.22% |
| 32 | 529.50% |
| 64 | 468.43% |
| 128 | 344.58% |
单表 50000,缓存表相比普通表提升的百分比
| threads/request type | oltp_point_select |
|---|---|
| 8 | 226.42% |
| 16 | 335.24% |
| 32 | 279.24% |
| 64 | 253.56% |
| 128 | 178.62% |
读写混合
单表 5000,缓存表相比普通表提升的百分比(负增长符合预期)
| threads/--point_selects | 10 |
|---|---|
| 8 | -35.77% |
| 16 | -64.39% |
| 32 | -62.79% |
| 64 | -46.61% |
| 128 | -57.58% |
单表 50000,缓存表相比普通表提升的百分比(负增长符合预期)
| threads/--point_selects | 10 |
|---|---|
| 8 | -12.01% |
| 16 | -28.97% |
| 32 | -36.20% |
| 64 | -46.13% |
| 128 | -43.21% |
结果显示,相比于普通表,缓存表在 oltp_point_select、oltp_read_only、select_random_points、select_random_ranges 几种只读的场景下性能有非常大的提升,但在包含写请求的测试中无法提供更好的性能。它的机制决定了使用场景目前仅限于表的数据量不大 的只读表,或者几乎很少修改的小表。综上,虽然缓存表目前的使用场景相对比较单一,但是在合适的场景下确实是一个解决了业务痛点的好功能,也期待在后续的版本中能有更高的稳定性和更优秀的性能表现。