


TiDB 5.4 作为 2022 年开山之作,于 2 月 15 日正式发版,5.4 版本包含了许多有用有益的新功能和持续性的性能/稳定性提升。 本文着重介绍重要新增功能和特性所带给用户的新体验和价值 ,按照以下章节来组织。
- 基础性能优化和提升
- 面向云环境的功能拓展
- 产品易用性和运维支持
- 新增实用性功能涉及到的系统配置开关选项
- 主要的 bug 修复和稳定性提升
更多详细内容还可以参照 Release Notes 和用户手册。
基础性能优化和提升
TiDB 5.4 在性能提升方面实现了以下的重要改进:查询计划可利用多个列上的索引进行高效条件过滤相关的优化工作,即通过正式支持索引合并查询优化功能,使此类查询的性能获得数量级的提升,并且具有响应时间稳定不占系统资源的突出特点;对于数据量大、读写更新频繁的分析场景, TiFlash 存储引擎的性能优化将使 CPU 占用率在现有基础上显著降低并间接帮助提升并发查询下的总体性能;最后,TiDB 5.4 在大规模数据同步场景下显著提升了同步工具 Lightning 的性能,使得大规模的数据同步任务更轻松快捷。
TiFlash 存储层大幅优化行存到列存转码效率
用户场景与挑战
HTAP 平台和应用中,数据更新和大量扫表行为交织在一起,存储系统的效能是影响性能和稳定性的关键因素,重度用户总是期待系统能有更好的性能并承载更多的业务。特别是 TiDB HTAP 采用了事务处理与分析查询物理分离的架构,同一份数据根据业务的需要,在后台进行自动的行式存储到列式存储的转换以分别响应 OLTP 和 OLAP 两种类型的负载。存储层大幅优化了从 TiKV “行”存储到 TiFlash “列”存储格式的转换效率,在“行 - 列”转换环节的 CPU 效率大幅提升,进而使得高负载情况下可以节约出更多的 CPU 资源用于其他环节的计算任务。
解决方案与效果
TiDB 5.4 重新梳理了 TiFlash 中行存到列存转码模块的代码架构,大量简化了冗余的数据结构和判断逻辑,采用 CPU 缓存和向量化友好的数据结构和算法,从而大幅提高运行效率。另外,新版本还相应地优化了 TiFlash 的存储引擎 DeltaTree 的默认配置,综合效果的确认参见下文。
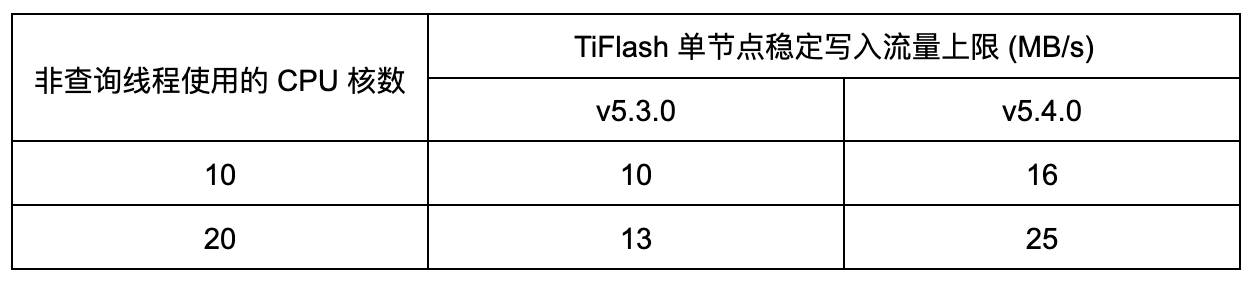
列式存储引擎写入性能验证: 在不同并发情况下吞吐性能提高 60%~90%
验证环境:
6 TiKV( 1 副本)、1 TiFlash( 1 副本),每个节点 40 个 CPU 逻辑 core,CH-benCHmark (1500 warehouse)。
CH-benCHmark 测试结果:10 并发下部分查询(Q1、Q6)性能提高约 20%
测试环境:
3 TiKV( 3 副本)、2 TiFlash( 2 副本),每个节点 40 个 CPU 逻辑 core,CH-benCHmark (1500 warehouse)。

小结
TiDB 行存与列存之间的数据转换同步通常被外界认为是一种较大的 overhead, 但是经过努力,今后 TiDB 的行列转换在架构保持大体不变的情况下,实际运行时已经不构成明显的性能瓶颈。
TiDB 正式支持索引合并查询优化
用户场景与挑战
以往有些查询在逻辑上需要同时扫描多个列,而之前版本的 TiDB 处理区域扫描的查询中只能选择单独某一列(或多列)上的索引(或一个复合列索引),即便各列上都已经有索引但整体的性能受此影响不能达到理想状态。在 TiDB 5.4 版本中,正式提供了索引合并功能,得以允许优化器在查询处理中同时选择使用多列的索引以减少回表,达到超过一两个数量级的过滤效果。对于此类以往容易形成性能瓶颈的问题在查询时间和性能稳定性上都有较大帮助,例如(参见下文)查询的响应时间可以由 600 毫秒缩短 30 倍至 20 毫秒,并提升一个数量级的查询并发度。
解决方案
TiDB 在原有三种读数据算子基础上增加了第四种类型的算子 IndexMergeReader:
- TableReader
- IndexReader
- IndexLookUpReader
- IndexMergeReader
前两种比较好理解,直接读取主表数据或者索引表数据。IndexLookUpReader(回表算子)会先读取索引表,得到 row_id,再根据 row_id 从主表中读取数据。
IndexMergeReader 执行流程类似于 IndexLookUpReader,区别在于可以利用多个索引进行回表,在如下例的场景可以极大提升查询的性能:
SELECT * FROM t1 WHERE c1 < 10 OR c2 < 100;
上述查询中如果 c1/c2 上都有索引,但是由于过滤条件是 OR,无法单独使用 c1 或 c2 索引,导致只能进行全表扫。使用索引合并可以解决无法使用索引的问题:索引合并会单独利用 c1/c2 索引得到 row_idx ,然后将两个索引拿到的 row_id 进行 UNION 操作,以 UNION 操作的结果从主表中获取实际行。
索引合并优势场景
数据来源为以 TPC-H SF 1 (lineitem 表行数为 600W),使用如下的查询来获取 lineitem 表中价格为 930,或者 orderkey 为 10000 且 comment 为特定字符串的行:
SELECT l_partkey, l_orderkey
FROM lineitem
WHERE ( l_extendedprice = 930
OR l_orderkey = 10000 AND Substring(Lpad(l_comment, 'b', 100), 50, 1) = 'b' )
AND EXISTS(SELECT 1
FROM part
WHERE l_partkey = p_partkey);
不使用索引合并时,执行时间为 3.38s+
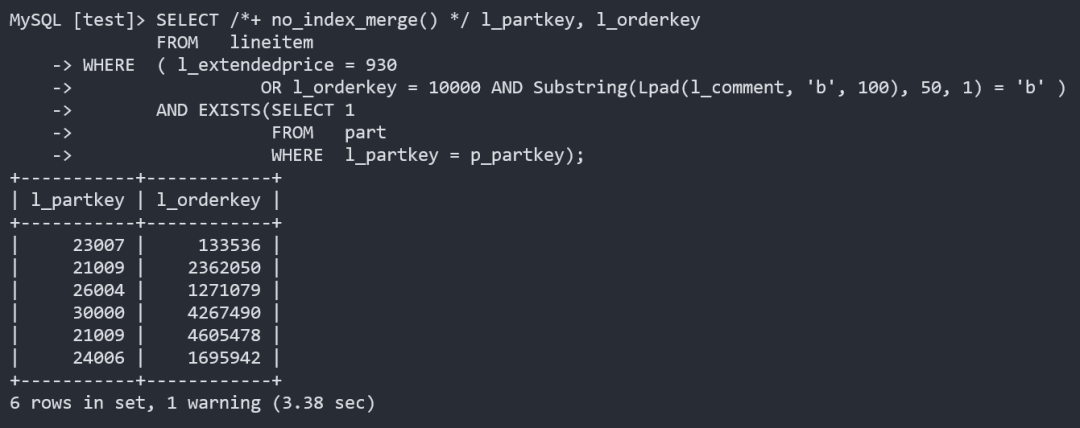
使用索引合并时,执行时间为 8.3ms:
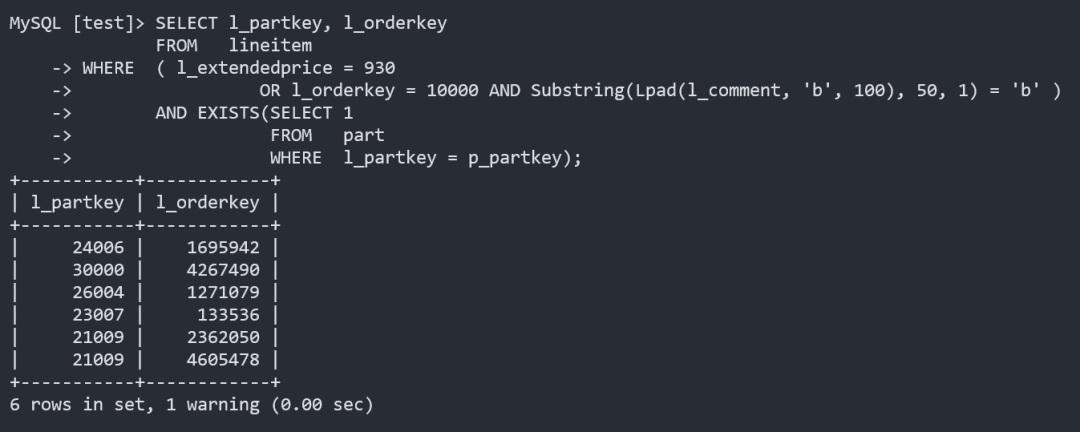
资源消耗
在索引合并优势场景的查询中,由于大部分行已经在 TiKV 过滤掉, 所以 CPU/内存资源消耗基本可以忽略。
未使用索引合并的查询,由于过滤条件无法下推,导致需要将所有行都传给 TiDB 进行 Selection 操作,内存消耗较大,在 10 个并发查询情况下,TiDB 需要 2G 内存进行 600W 行数据的过滤。
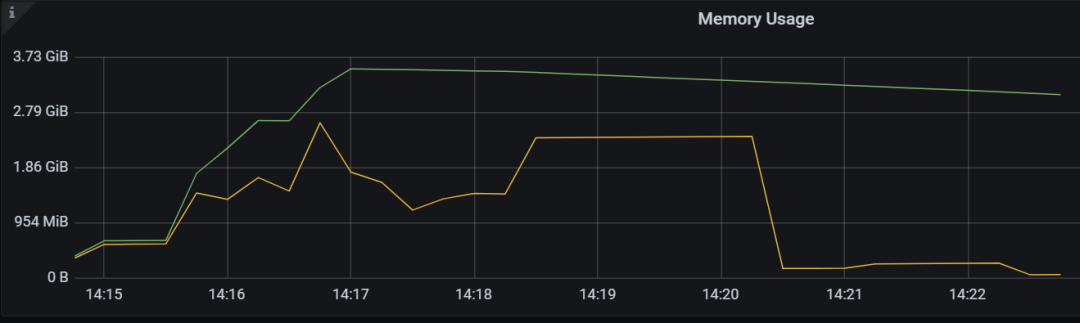
小结
- 在过滤条件选择率较高时可以考虑使用索引合并。数据流量较大过滤条件较好的场景查询响应时间可缩短 2 个数量级(本文给出的例子是 400 倍),将秒级响应的查询变为毫秒级。
- 索引合并可大幅减少并发查询时的系统资源消耗,特别是过滤条件无法下推的查询(消耗资源较大)可以达到颠覆性的效果(例如原本消耗 2GB 的查询,使用索引合并之后资源消耗甚至可以忽略不计)。
- 部分场景不适用索引合并,使用建议请查阅 Release Notes。
TiDB Lightning 新增高效的重复数据检测特性
用户场景与挑战
在生产环境中,由于历史原因,用户的各个分片 MySQL 实例的数据可能存在重复,当主键/唯一索引重复时则形成冲突数据。因此在将多个分片 MySQL 合并导入下游 TiDB 时必须进行检测和处理,且可能高达几十 TB 的单表数据量对检测效率也是一项极大的挑战。
解决方案
TiDB Lightning 是用于从 CSV/SQL 文件高速导入大规模数据到新 TiDB 集群的工具。Lightning 的 local backend 模式可将源数据编码为有序键值对,直接插入 TiKV 存储,其导入效率极高,并且支持使用多台主机并行导入一张表,是目前初始化 TiDB 集群数据的常用方式。
在 local backend 模式下,数据导入并不会经过事务写入的接口,因此无法在插入时检测冲突数据。在之前的版本, Lightning 仅能通过对比 KV 级别的校验码来实现,但局限性较大,仅能知晓发生了错误,却无法定位冲突数据的位置。
新增的重复数据检测特性使得 Lightning 精准检测冲突数据,并且内置了一种冲突数据删除算法以自动聚合。检测到冲突数据后, Lightning 可以将其保存以供使用者筛选后再次插入。
重复数据检测特性默认关闭,可以在使用时根据不同的场景需求设置 record/remove 等不同的处理方式。
详细性能验证数据可参考下表:

小结
使用 Lightning 并行导入特性,开启重复数据检测,可以精准定位数据源中的冲突数据,执行效率在多次优化后耗时占比约为总时长的 20%。
面向云环境的功能拓展
TiDB 5.4 重视与云环境的生态结合,特别推出了一项可以大幅节约存储成本的 Raft Engine 日志存储引擎, 可为用户节约 30% 以上的数据传输费用同时还在某些场合下有额外的性能收益;强化了数据备份效率,在支持 Amazon S3、Google Cloud Storage 的基础上,新增了对 Azure 环境的支持,完成了与世界主流云厂商存储服务的对接。
支持使用 Raft Engine 作为 TiKV 的日志存储引擎
用户场景与挑战
云环境上用户最为关心的问题之一是成本,数据存储量和 IO 请求所产生的开销不可小觑。通常来说,分布式数据库在处理用户写入时需要复制并持久化记录大量的日志,这无疑会增加用户部署服务的成本。另一方面看,由于云环境下的硬件资源有较为明确的限制,当用户负载发生波动,而预设的硬件配置无法满足时,服务质量也会受到显著影响。
解决方案
TiDB 5.4 推出一项实验性功能:Raft Engine,一款自研的开源日志存储引擎,相较于使用默认的 RocksDB 引擎,它最大的优势在于节省了磁盘带宽的使用量。首先,Raft Engine 将 TiDB 集群的“写入日志”压缩后直接存放在文件队列中,而不进行额外的全量转储。另外,Raft Engine 拥有更为高效的垃圾回收机制,利用过期数据的空间局部性进行批量清理,在大部分场景下不额外占用后台资源。
这些优化能够大幅降低同等负载下 TiDB 集群中存储节点的磁盘带宽使用量。这意味着,同等水平的集群将能服务更高峰值的业务输入,而同等强度的业务可以缩减部分存储节点数量来获得近似的服务水平。
另外,作为自研引擎,Raft Engine 具有更轻量的执行路径,在一些场景下显著减少了写入请求的尾延迟。
在实验环境中,TPC-C 5000 Warehouse 负载下,使用 Raft Engine 能够减少集群约 30% 的总写入带宽,并对前台吞吐有一定提升。
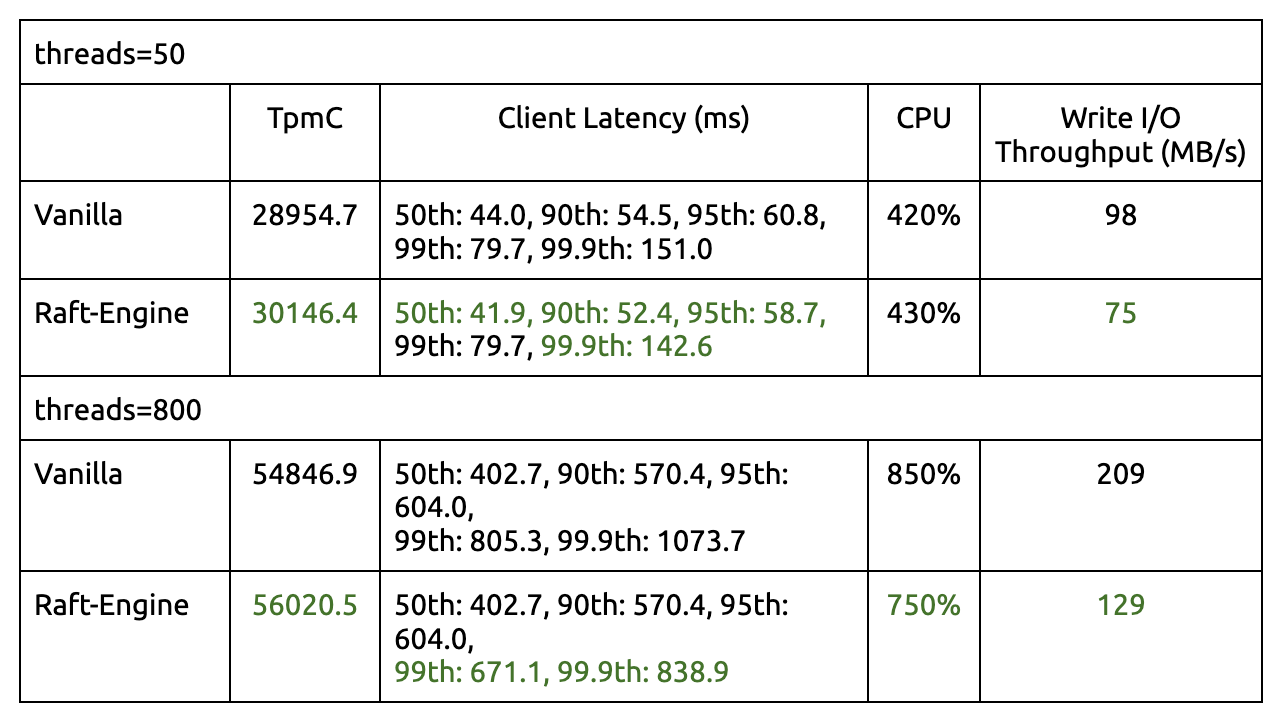
详情参见用户手册。
小结
使用 Raft Engine 存储集群日志,能够有效减少写入带宽用量,节省云上部署成本的同时提升服务稳定性。
支持 Azure Blob Storage 作为备份目标存储
Backup & Restore (BR) 支持 Azure Blob Storage 作为备份的远端目标存储。在 Azure Cloud 环境部署 TiDB 的用户,可以支持使用该功能方便地将集群数据备份到 Azure Blob Storage 服务中,支持 AD 备份 和 密钥访问 两种恢复方式。囿于篇幅,具体信息请移步用户手册中的 Azure Blob Storage 备份支持与外部存储章节。
产品易用性和运维支持
TiDB 5.4 持续提升产品易用性和运维效率,做出了以下的努力:为提升优化器生成执行计划的质量,增强了统计信息的收集和管理功能,可以针对不同的表、分区、索引设置不同的采集配置项并且默认保存设置,方便后续收集统计信息时沿用已有配置项;数据备份过程有时会影响正常业务,这是长久以来困扰一些用户的问题。5.4 BR 新增了备份线程自动调节功能,可显著减轻备份带来的负面影响;TiDB 运行过程中产生的大量日志数据处理不当会造成对性能和稳定性的影响,5.4 版本提供了新的实验特性可使用 Raft Engine 保存日志,可以显著减少写流量和 CPU 使用率,提升前台吞吐减少尾延迟;此外,TiDB 自 5.4 开始支持 GBK 字符集。
详情参见用户手册。
新增实用性功能涉及到的系统配置开关选项
TiDB 5.4 对系统配置参数的优化做出了许多努力,完整信息可参见 Release Notes 和相关用户手册,本文仅举其中一项代表性的改善点。
支持 session 变量设置有界限过期读*
TiDB 是基于 Raft 协议的多副本分布式数据库。面对高并发,高吞吐业务场景,可以通过 follower 节点实现读性能扩展,构建读写分离架构。针对不同的业务场景,follower 可以提供以下两种读模式:
- 强一致读:通过强一致读,可以确保所有节点读取的数据实时一致,适用于一致性要求严格的业务场景,但是因为 leader 和 follower 的数据同步延迟导致强一致读的吞吐较低、延迟较高,特别是在跨机房架构下延迟问题被进一步放大。
- 过期读:过期读是指可以通过快照读取过去时间的过期数据,不保证实时一致性,解决了 leader 节点和 follower 节点的延迟问题,提升吞吐。该读模式适用于数据实时一致性要求较低或者数据更新不频繁的业务场景。
TiDB 目前支持通过显示只读事务或 SQL 语句的方式开启 follower 过期读。两种方式均支持“指定时间”的精确过期读和“指定时间边界”的非精确过期读两种模式,详细用法请参考过期读官方文档。
从 TiDB 5.4.0 版本开始,TiDB 支持通过 session 变量设置有界限过期读,进一步提升易用性,具体设置示例如下:
set @@tidb_replica_read=leader_and_follower
set @@tidb_read_staleness="-5"
通过该设置,TiDB 可以通过 session 变量快速开启过期读,避免了频繁的显示开启只读事务或者在每个 SQL 内指定过期读语法,提升易用性,方便批量地实现就近选取 leader 或 follower 节点,并读取 5 秒钟内的最新过期数据,满足准实时场景下低延迟、高吞吐数据访问的业务诉求。
主要的 bug 修复和稳定性提升
自 TiDB 5.1 版本发布以来,提高稳定性不断“捉虫”,是研发和 QA 团队最优先的任务。5.4 版本总计进行了 200 余项的体验优化,其中主要部分在 Release Notes 中记录,其他细节可以参考 GitHub 上的 PR 记录。TiDB 研发和 QA 团队始终秉持对用户负责的姿态,使产品日臻完善,期待赢得广大用户的信任。
PM 寄语
2022 年是广大 TiDB 用户事业虎虎生风蒸蒸日上的一年,希望 TiDB 5.4 能给用户带来更多的舒心,更多的便利,助力各种应用和业务的健康高效发展。敬请关注 TiDB 官网,GitHub 以及各种社交媒体账号,谨代表 TiDB 产品经理(PM) 团队、研发工程与质量团队一道,期待与广大用户一起开创更美好的一年。如果您对 TiDB 的产品有任何建议,欢迎来到 internals.tidb.io 与我们交流。