

TiDB监控Prometheus磁盘内存问题
–2022-01-20 春雷
1、问题
问题: TiDB的Prometheus节点,磁盘报警,内存报警
受影响版本 :5.0.x - 5.2.x
现象 :偶发,目前我们集群碰到2个集群有此问题
2、分析
2.1、现象
【基本信息】:

【现象-内存占用高】:

【现象-磁盘占用大】:
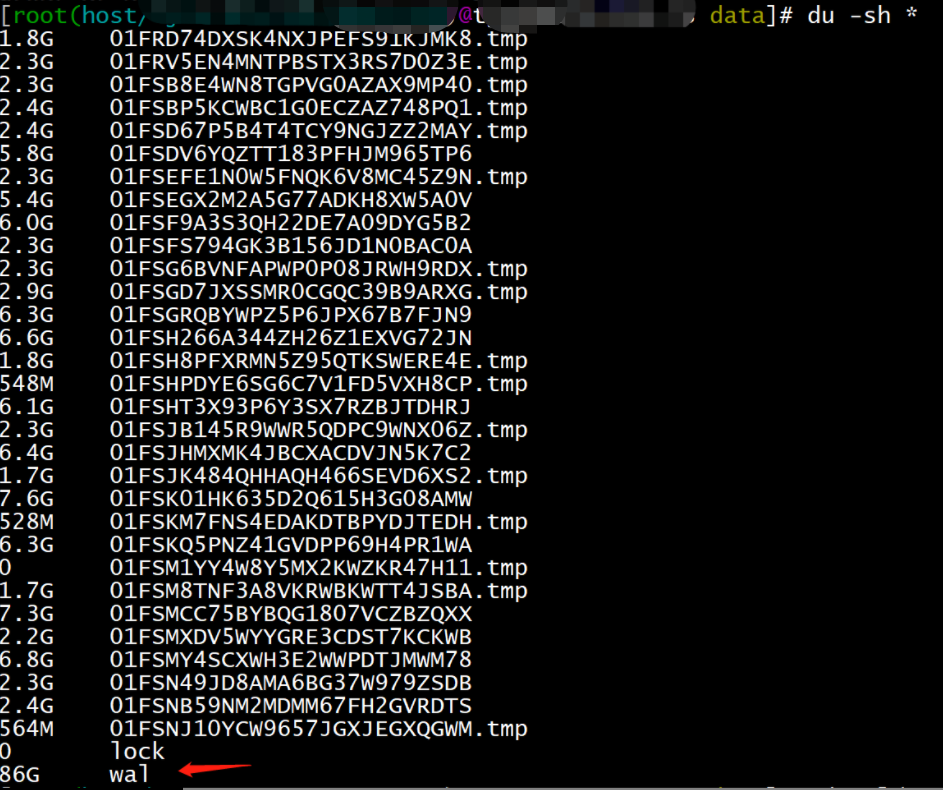
【现象-prometheus】:
prometheus会oom重启
3、处理
【修改prometheus的配置】:
cd /opt/soft/tidbxxx/prometheus-xxx/conf
vim prometheus.yml
找到job_name: "tikv"处:添加
metric_relabel_configs:
- source_labels: [name]
separator: ;
regex: tikv_thread_nonvoluntary_context_switches|tikv_thread_voluntary_context_switches|tikv_threads_io_bytes_total
action: drop - source_labels: [name,name]
separator: ;
regex: tikv_thread_cpu_seconds_total;(tokio|rocksdb).+
action: drop
如下图:
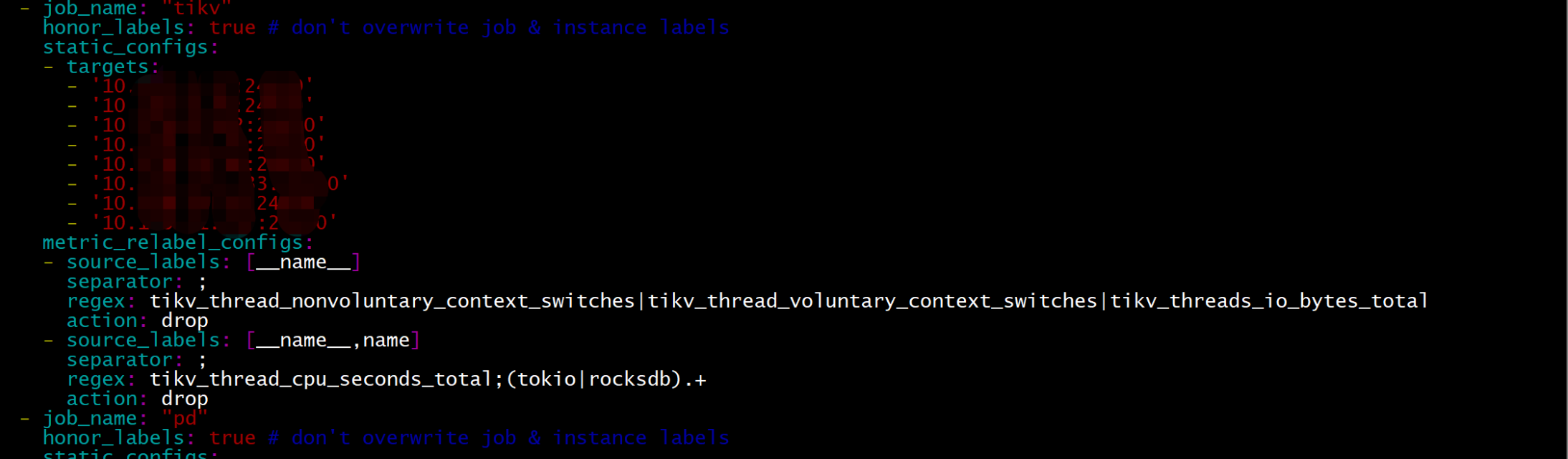
【重启prometheus】:
tiup cluster restart xxx–node xxx:xxx
【效果-内存使用降低】:

【效果-磁盘使用降低】:

【说明】:
方案 :此方案为临时解决方案
情况 :prometheus的版本也比较老了,新版本支持wal的压缩
–storage.tsdb.wal-compression:此标志启用预写日志(WAL)的压缩。根据您的数据,您可以预期WAL大小将减少一半,而额外的CPU负载却很少。此标志在2.11.0中引入,默认情况下在2.20.0中启用。请注意,一旦启用,将Prometheus降级到2.11.0以下的版本将需要删除WAL。
后续 :
- TiDB会彻底解决此问题
- prometheus 的版本后面也会升级