

前言
在 4.0 中我们对 TiDB 表数据的编码格式进行了重新设计, 使用新表数据编码格式后 TiDB 能有效减少宽表场景下表数据编解码开销。在接下来的本篇文章我们会介绍新表数据编码格式的实现和测试效果。
什么是表数据编码格式
在 《三篇文章了解 TiDB 技术内幕——说计算》中看到在 TiDB 中对于表中的每行数据会按照如下规则进行编码成 Key-Value pair:
Key: tablePrefix_rowPrefix_tableID_rowID
Value: [col1, col2, col3, col4]
本文关注的表数据编码格式即数据表中每行 Key-Value pair 的 Value 部分使用的数据编码格式。因为和索引数据以及表数据中的 Key 部分无关,表数据编码格式变更不会影响通过 RowID 或索引进行查询比较的功能,仅需要关注数据在存入前编码和读取后解码过程。
旧表数据编码格式回顾
在 3.0 及之前版本中, TiDB 的表数据编码格式的如下格式:
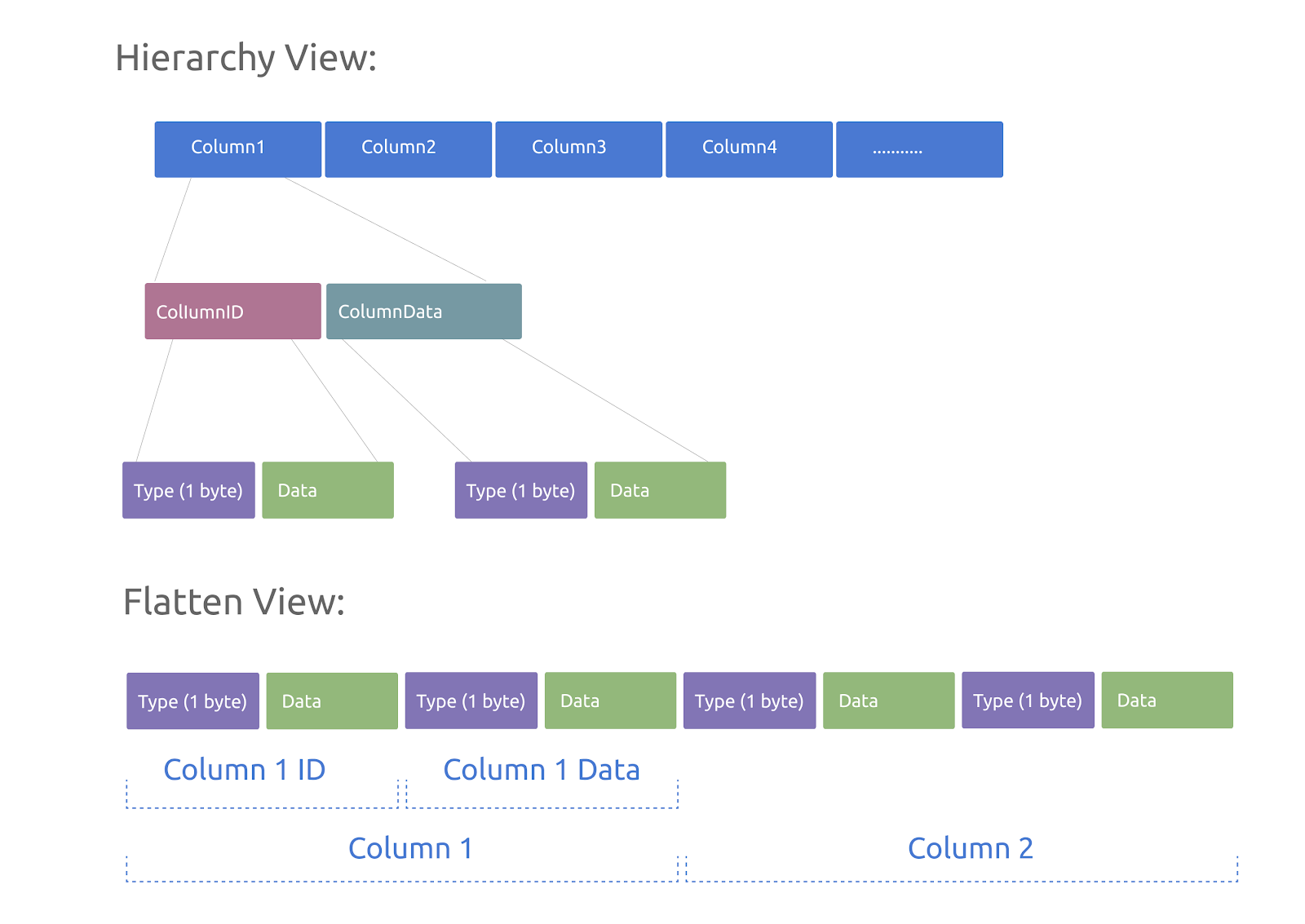
- 整个数据行由多个列的数据依次存放组成
- 其中每个列由标识列的 ColumnID 和具体的列数据组成
- 而 ColumnID 和 列数据各自分别由 1 byte 的数据类型信息和具体数据组成
- 对于 int 类型根据是否需要比较操作会选择 int 或 varint 编码
在编码时,需要对要写入的每列数据前插入 ColumnID 并对每个 ColumnID 和列数据前附加一列标识数据类型的 1 byte,并根据不同数据类型对数据进行编码。
而在解码时,调用者会提供当前数据行中所需列的 ColumnID 数组作为输入,解码逻辑会从头开始对每个 Column 解出 ColumnID 和 ColumnData,如果和输入的 ColumnID 数组匹配的列作为解码结果返回。
旧表数据编码格式存在的问题
可以看到旧表数据编码格式比较简单,但在某些情况下可能会有以下问题:
- 如果只需要其中某几列需要从头依次向后逐个列进行解码直到找到所需要的列,在列非常多时查找开销会加剧
- 对于每个列的 ColumnID 和列数据都冗余将类型信息编码,而实际在编解码时调用方通过 schema 能提供编解码所需的类型信息,并不需要每行冗余存储
- varint 在编码时相比 int 处理更复杂会消耗更多的 CPU 资源但相比节省存储收益有限
- 对于 NULL 值列也需要在 ColumnData 部分进行保存
新表数据编码格式设计
在 4.0 后, TiDB 的数据行使用的如下新格式:

- version: 首 byte 用于标识编解码版本,在上面老格式介绍中我们看到首自己是表示类型的 Type 只会使用(1-10),所以我们需要选择大于 10 的值作为版本号就能和老版 表数据编码格式区分开
- flag: 之后的 1 byte 是可扩展的标识 flag, 目前只用到 1 bit 来标识是否是 large 行,当有 ColumnID 超过 255 或 Value 部分数据总长度有超过 65535 时会标记 large 行并在后面 column id array 和 offset array 部分使用足够的字节来存储
- num of not null columns/num of null columns: 之后是 2 bytes 用于记录行中非 NULL 列的数目,再往后 2 bytes 则记录行中 Null 列的数目,这 4 bytes 主要用于确定之后 column id array 的读取长度
- not null column id array: 接下来是对应长度的非 NULL 列 ColumnID 数组,数组元素按照升序排序,便于二分查找定位用于 offset 数组的 index。如果不是 large 行,每个 ColumnID 需 1 byte ,否则需 2 bytes
- null column id array: 之后是对应长度的 NULL 列 ColumnID 数组,数组元素按照升序排序,便于二分查找确定是否有 NULL 列, NULL 值在新格式中只需要保存 ColumnID 不需保存 ColumnData
- not null column offset array: 指定当前列在 not null column data 段 byte 数组的结束 offset, 假设当前列通过 column id array 定位到的 index 是 i, 则改列的数据将是 data[offset[i-1]:offset[i]]。如果不是 large 行,一个 offset 需 2 bytes, 否则需 4 bytes
- not null column data: 非空列数据依次保存的 byte 数组,需要注意的是不再保存 Type 信息,除 使用 int 来代替 varint 外,单个列数据格式和原格式中的单列格式保持一致。
在编码时,会将行数据整理为格式定义的格式进行写入。
而在解码时,调用者会提供当前数据行中所需列的 ColumnID 数组和列的类型信息做为输入,解码处理会先根据首 byte version 判断是否按照新格式解码,如果是新格式则预先将除了最后一段 not null column data 外的其他段信息在内存中整理成 flag 或 array,然后依次对输入的 ColumnID 数组在 not null column id array 中二分查找,找到则通过 not null column offset array 定位 not null column data 中的数据并根据输入中提供的列类型信息解码,如未在 not null column id array 段找到则继续在 null column id array 进行二分查找,找到则直接使用 NULL 值作为列解码结果,还是未找到则使用 schema 定义的列默认值作为列解码结果。
兼容性 & 升级
通过识别首 byte, TiDB 4.0 可以同时解码新旧表数据编码格式数据,对于新写入的数据会按照新格式进行写入(如果 @@tidb_row_format_version=2),在之后随着老数据不断被更新写入,老数据会转换为新格式存储,最终整个集群中的数据将转换为新格式。
但 TiDB 作为一个分布式数据库,升级过程中不可避免会的出现部节点一更新其他节点还未更新的情况,因为引入新表数据编码格式, 升级 4.0 需要先完成所有 TiKV 的升级,再升级 TiDB,并且为了防止“ A TiDB 实例升级并写如新格式数据, B TiDB 还未升级就读取新格式报错”的问题,我们引入了 Global 级别的新系统变量 @@tidb_row_format_version 来支持所有节点更新完成后再开启新格式写入功能的“两阶段升级”,其默认值根据是否是新建集群不同:
- 新建集群 tidb_row_format_version = 2 默认使用新表数据编码格式进行数据写入
- 已有老集群升级后 tidb_row_format_version = 1 不会使用新表数据编码格式进行数据写入
所以对于老集群升级,需待整个 TiDB 集群升级完成后再执行:
set global tidb_row_format_version=2
来让新数据写入使用新格式,后续我们也会考虑在 4.0 后的某个版本对从 4.0 像后升级时默认开启新表数据编码格式。
性能对比
sysbench 测试表默认情况下只有 4 列, 所以本次测试先对 sysbench 的建表语句做修改,支持通过 --garbage_columns 选项在建表是添加带默认值但查询不会被用到的列来增加表的宽度, 并通过添加无用列对比测试 select-random-ranges, point-get 和 select-read-only 在不同列数下使用新旧格式的表现。

select-random-ranges 会进行随机的 range select 需对多行结果在 TiKV 进行 decode, 解码开销在该 workload 下比较明显,从测试结果看新格式随着列的增加相比老格式有 20-30% 的提升。
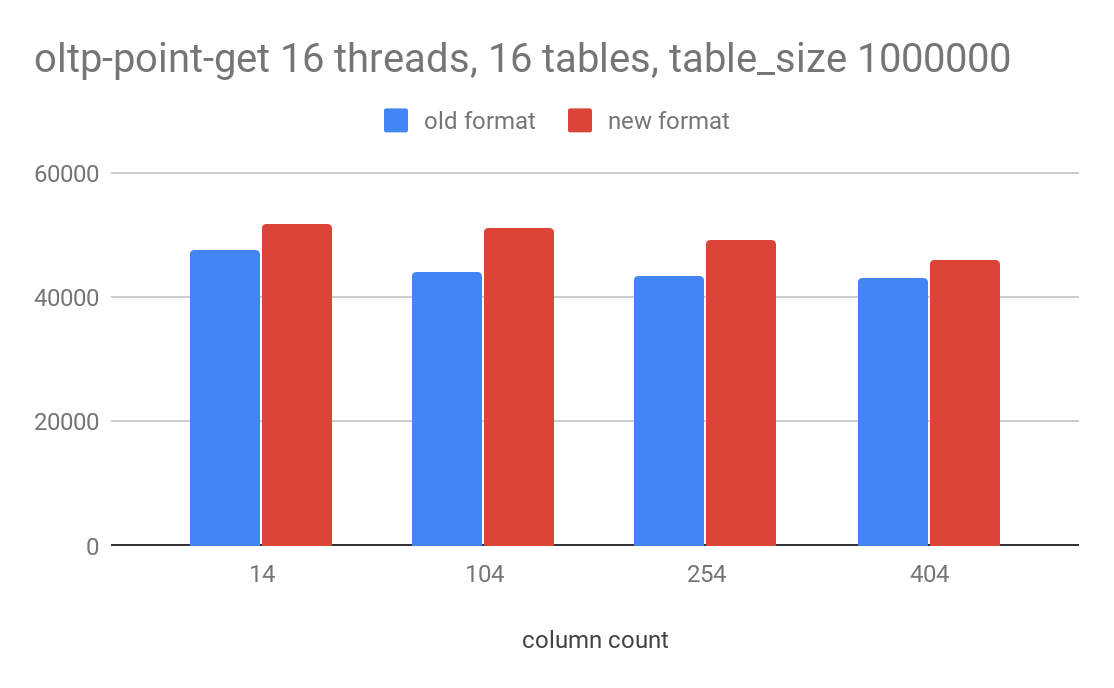
point-get 会以 rawkv get 的形式返回一行结果并在 TiDB 进行 decode,decode 开销并非瓶颈,但从测试结果看也有 6-12% 的提升。
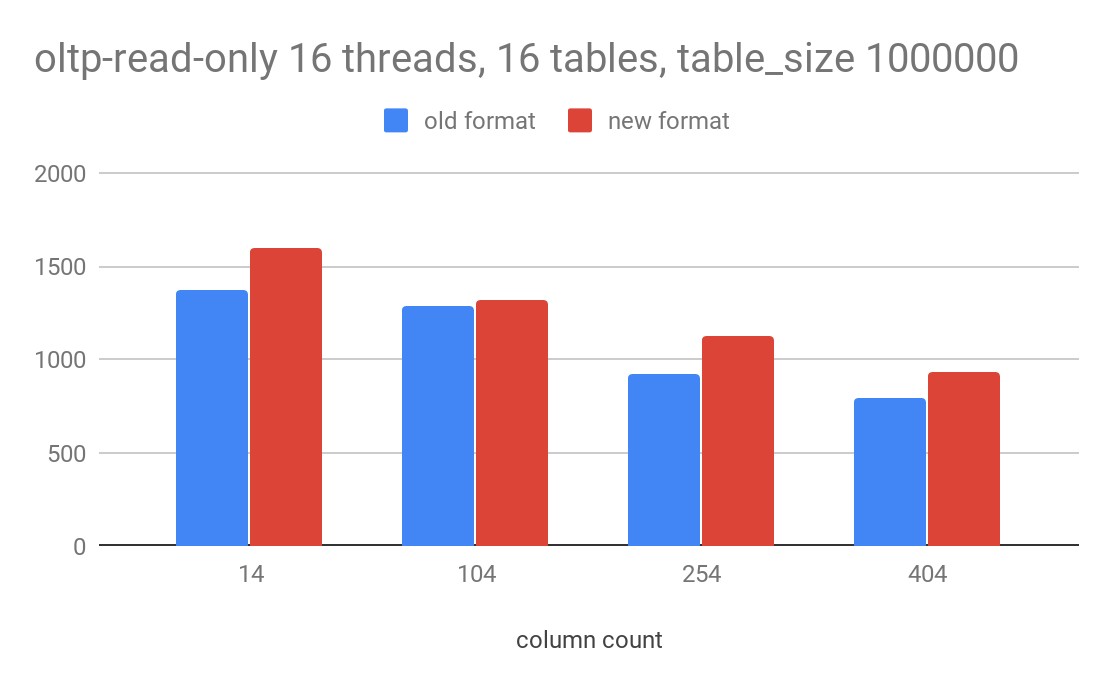
read-only 会混合点查和 range 查询,从测试结果看也有 10-15% 的提升。
总结
通过本篇文章相信已经对新表数据编码格式特性有了一定程度的了解,欢迎试用并提出宝贵意见。