

这篇长文是 InfoQ 的邀约,PingCAP 和 InfoQ 一起搞的一个年终总结,我当时一不小心写了一篇长文,后来被编辑拆成了四篇文章,其实完整的原文的阅读体验其实更佳。所以放在这里和大家分享一下。
专题前言:
经常思考一个问题,为什么我们需要分布式?很大程度或许是不得已而为之。如果摩尔定律不会失效,如果通过低成本的硬件就能解决互联网日益增长的计算存储需求,是不是我们也就不需要分布式了。
·
过去的二三十年,是一场软件工程师们自我拯救的,浩浩荡荡的革命。分布式技术的发展,深刻地改变了我们编程的模式,改变了我们思考软件的模式。通过随处可见的 X86 或者 Arm 机器,构建出一个无限扩展的计算以及存储能力,这是软件工程师最浪漫的自我救赎。
值 2019 年末,PingCAP 联合 InfoQ 共同策划出品“分布式系统前沿技术”专题, 邀请转转、UCloud、Pulsar、微众银行、贝壳金服等技术团队共同参与,从数据库、硬件、测试、运维等角度,共同探索这个古老领域的新生机。
分布式系统 in 2010s (初稿完成)
Author: 黄东旭
近几年,分布式系统领域有很多新东西,特别是云和 AI 的崛起,让这个过去其实不太 sexy 的领域一下到了风口浪尖,在这期间也诞生了很多新技术、新思想,让这个古老的领域重新焕发生机。
本篇文章会集中讲讲最近几年在分布式系统相关的一些新动态,重点在硬件、软件、测试运维三个大方面。希望这篇文章能成为最近几年在系统领域工业界发生的一些新东西的索引和概览,由于篇幅原因,很多话题只能点到为止,不过还是希望大家能够喜欢。
硬件的进化
存储设备
如果说云的出现是一种商业模式的变化的话,驱动这个商业革命的推手就是最近十年硬件的快速更新。比起 CPU,存储和网络设备的进化速度更加迅速。最近五年,SSD 的价格 (包括 PCIe 接口) 的成本持续下降,批量采购的话已经几乎达到和 HDD 接近的价格。

Prices of 512 GB SSDs will drop below $ 0.1 per GB by the end of the year
Good news if you are planning to purchase some SSD storage later this year, the ongoing drop in prices for NAND is just that, ongoing and will reach a price of less than 10 Cents per GB by the end of ...
SSD 的普及,对于存储软件厂商带来的影响是深远的。一是极大地缓解了 IO 瓶颈,对于数据库厂商来说,可以将更多的精力花在其他事情,而不是优化存储引擎上。而且最近两年发生了一些更大的变化, NVMe 正在成为主流,我们很早就在 Intel Optane 进行实验和投资,类似这样的非易失内存的技术,正在模糊内存和存储的界限,但是同时对开发者带来挑战也是存在的。举一个简单的例子,对于 Optane 这类的非易失内存,如果你希望能够完全利用它的性能优势,最好使用类似 PMDK 这类基于 Page cache Bypass 的 SDK 针对你的程序进行开发,这类 SDK 的核心思想是将 NVM 设备真正地当做内存使用。如果仅仅将 Optane 挂载成本地磁盘使用,其实很大程度上的瓶颈不一定出现在硬件本身的 IO 上。
下面这张图很有意思,来自 Intel 对于 Optane 的测试,我们可以看见在中间那一列,Storage with Optane SSD,随机读取的硬件延迟已经接近操作系统和文件系统带来的延迟,甚至 Linux VFS 本身会变成 CPU 瓶颈。其实背后的原因也很简单,过去由于 VFS 本身在 CPU 上的开销(比如锁)相比过去的 IO 来说太小了,但是现在这些新硬件本身的 IO 延迟已经低到让文件系统本身开销的比例不容忽视了。

当然,另外一个方向是从操作系统和文件系统本身入手,例如针对 Persistent Memory 设计新的文件系统,其中来自 UCSD 的 NVSL 实验室 (名字很厉害, Non-Volatile Systems Laboratory) 的 NovaFS 就是一个很好的例子。简单来说是大量使用了无锁数据结构,减低 CPU 开销,NovaFS 的代码量很小很好读,有兴趣可以看看,本文就不展开了。
另外下面是来自 Intel 对 Persistent Memory 编程模型很好的一篇入门文章,感兴趣的话可以从这里开始。
网络设备
说完了存储设备,我们聊聊网络设备。我还记得我第一份工作的数据中心里甚至还有百兆的网卡,但现在,1GbE 已经都快淘汰光了,主流的数据中心基本上开始提供 10GbE 甚至 25GbE 的网络。为什么会变成这样? 我们做一个简单的算术题就知道了。根据 Cisco 的文档介绍, 一块千兆网卡的吞吐大概是: [1,000,000,000 b/s / (84 B * 8 b/B)] == 1,488,096 f/s (maximum rate)。
那么万兆网卡的吞吐大概是它的十倍,也就是差不多每秒 1488 万帧,处理一个包的时间在百纳秒的级别,基本相当于一个 L2 Cache Miss 的时间。所以如何减小内核协议栈处理带来的内核-用户态频繁内存拷贝的开销,成为一个很重要的课题,这就是为什么现在很多高性能网络程序开始基于 DPDK 进行开发。
对于不了解 DPDK 的朋友,在这里简单科普一下:

从上图可以看到,数据包直接从网卡到了 DPDK,绕过了操作系统的内核驱动、协议栈和 Socket Library。DPDK 内部维护了一个叫做 UIO Framework 的用户态驱动 (PMD),通过 ring queue 等技术实现内核到用户态的 zero-copy 数据交换,避免了 Syscall 和内核切换带来的 cache miss,而且在多核架构上通过多线程和绑核,极大提升了报文处理效率。如果你确定你的网络程序瓶颈在包处理效率上,不妨关注一下 DPDK。
另外 RDMA 对未来体系结构的影响也会很大,它会让一个分布式集群向一个超级 NUMA 的架构演进(它的通信延时/带宽已经跟现在 NUMA 架构中连接不同 socket node 的 QPI 的延时/带宽在一个量级),但是目前受限于成本和开发模型的变化,可能还需要等很长一段时间才能普及。
可以看到的,其实不管是的 DPDK,SPDK,PMDK 背后的主线是 Bypass kernel,Linux 内核本身带来的开销已经很难适应现代硬件的发展(一个很新的例子),但是生态和兼容性依然是大的挑战,我对于一言不合就搞个 Bypass Kernel SDK 的做法其实是不太赞同的。大量的基础软件需要适配,甚至整个开发模型都要变化。我认为有关内核的问题,内核社区从长期来看一定会解决,一个值得关注的技术是 Linux 5.1 内核中引入的 io_uring 系列的新系统调用,io_uring 的原理简单来说就是通过两个内核/用户态共享的 ring buffer 来实现 IO 事件的提交以及收割,避免了 syscall 及内核<->用户态的内存拷贝,同时提供了 poll 的模式, 不用等待硬件中断,而是不断轮询硬件,这极大降低了 IO 延迟,提升了整体吞吐。 我认为 io_uring 的出现也代表了内核社区在各种 Bypass Kernel 技术涌现的当下,正在奋起直追。
软件构建方式和演化
我上大学的时候专业是软件工程,当时的软件工程是 CMM,瀑布模型什么的,但是十几年过去了,看看现在我们的软件开发模式,尤其是在互联网行业,敏捷已经成为主流,很多时候老板说业务下周上线,那基本就是怎么快怎么来,所以现代架构师对于可复用性和弹性会有更多的关注。我所知道业界对 SOA 的关注是从 Amazon 的大规模 SOA 化开始, 2002 年 Bezos 要求 Amazon 的工程团队将所有的业务 API 和服务化,几条原则放在今天仍然非常适用(出处):
- All teams will henceforth expose their data and functionality through service interfaces.
- Teams must communicate with each other through these interfaces.
- There will be no other form of inter-process communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
- It doesn’t matter what technology they use.
- All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
尤其最后一条,我个人认为对于后来的 AWS 的诞生有直接的影响,另外这条也间接地对工程团队对于软件质量和 API 质量提出了更高的要求,可谓是一举多得。亚马逊在 SOA 上的实践是组件化在分布式环境中的延伸,尽可能地将业务打散成最细粒度的可复用单元(Services),新的业务通过组合的方式构建。这样的原则一直发展到今天,我们提到的微服务、甚至 Serverless,都是这个思想的延伸。
很多人在思考 SOA 和微服务的区别时,经常有一些观点类似:「拆的粗就是 SOA,拆的细就是微服务 -_-|| 」,「使用 RESTful API 就是微服务,用 RPC 是 SOA」,「使用 XXX(可以是任何流行的开源框架) 的是微服务,使用 YYY 的是 SOA」… 这些观点我其实并不认可,我理解的 SOA 或者微服务只是一个方法论,核心在于有效地拆分应用,实现敏捷构建和部署,至于使用什么技术或者框架其实无所谓,甚至 SOA 本身就是反对绑定在某项技术上的。
对于架构师来说, 微服务化也并不是灵丹妙药,有一些核心问题,在微服务化的实践中经常会遇到:
- 服务的拆分粒度到底多细?
- 大的单体服务如何避免成为单点,如何支持快速的弹性水平扩展?
- 如何进行流控和降级?防止调用者 DDoS?
- 海量服务背景下的 CI/CD (测试,版本控制,依赖管理),运维(包括 tracing,分布式 metric 收集,问题排查)
…
上面几个问题都很大。熟悉多线程编程的同学可能比较熟悉 Actor 模型,我认为 Actor 的思想和微服务还是很接近的,同样的最佳实践也可以在分布式场景下适用,事实上 Erlang OTP 和 Scala 的 Akka Framework 都尝试直接将 Actor 模型在大规模分布式系统中应用。其实在软件工程上这个也不是新的东西,Actor 和 CSP 的概念几乎在软件诞生之初就存在了,现在服务化的兴起我认为是架构复杂到一定程度后很自然的选择,就像当年 CSP 和 Actor 简化并发编程一样。
云和服务化
从服务化的大方向和基础设施方面来说,我们这几年经历了:本地单体服务 + 私有 API (自建数据中心,自己运维管理) -> 云 IaaS + 本地服务 + 云提供的 Managed Service (例如 EC2 + RDS) -> Serverless 的转变。其本质在于云的出现让开发者对于硬件控制力越来越低,算力越来越变成标准化的东西。而容器的诞生,使得资源复用的粒度进一步的降低(从物理机 -> VM -> Container),这无疑是云厂商非常希望看到的,尤其对公有云厂商来说,资源分配的粒度越细越轻量,就越能精准的分配以提升整体的硬件资源利用率,实现效益最大化,这里暗含着一个我的观点:公有云和私有云价值主张和商业模式是不一样的,对公有云来说,只有不断地规模化,通过不断提升系统资源的利用率,获取收益(比如主流的公有云几乎对小型实例都会超卖)。反过来私有云的模式可以概括成降低运维成本(标准化服务 + 自动化运维),对于自己拥有数据中心的企业来说,通过云技术提升硬件资源的利用率也是好事,但是这个收益并没有公有云的规模化收益来得明显。
在服务化的大背景下,也产生了另外一个趋势,就是基础软件的垂直化和碎片化,当然这也是和现在的 workload 变得越来越大,单一的数据库软件或者开发框架很难满足多变且极端的需求有关。数据库、对象存储、RPC、缓存、监控这几个大类,几乎每位架构师都熟悉多个备选方案,根据不同需求排列组合,一个 Oracle 包打天下的时代已经过去了。这样带来的结果是数据或状态在不同系统之间的同步和传递成为一个新的普遍需求,这就是为什么以 Kafka,Pulsar 为代表的分布式的消息队列越来越流行。但是在异构数据源之间的同步,暗含了异步和不一致(如果需要一致性,那么就需要对消费者实现幂等的语义),在一些对一致性有极端需求的场景,仍然需要交给数据库处理。
刚才提到 Container 的出现将计算资源分配的粒度进一步的降低且更加标准化,硬件对于开发者来说越来越透明,而且随着 workload 的规模越来越大,就带来的一个新的挑战:海量的计算单元如何管理,以及如何进行服务编排。既然有编排这里面还隐含了另外一个问题:服务的生命周期管理。
其实在 Kubernetes 诞生之前,很多产品也做过此类尝试,例如 Mesos。Mesos 早期甚至并不支持容器,主要设计的目标也是短任务(后通过 Marathon Framework 支持长服务),更像一个分布式的工作流和任务管理(或者是分布式进程管理)系统,但是已经体现了 Workload 和硬件资源分离的思想。
在前 Kubernetes 时代,Mesos 的设计更像是传统的系统工程师对分布式任务调度的思考和实践,而 K8s 的野心更大,从设计之初就是要在硬件层之上去抽象所有类型的 workload,构建自己的生态系统。如果说 Mesos 还是个工具的话,那么 K8s 的目标其实是奔着做一个分布式操作系统去的。简单做个类比整个集群的计算资源统一管控起来就像一个单机的物理计算资源,容器就像一个个进程,Overlay network 就像进程通信,镜像就像一个个可执行文件,Controller 就像 Systemd,Kubectl 就像 Shell……同样相似的类比还有很多。
从另一方面看,Kubernetes 为各种 IaaS 层提供了一套标准的抽象,不管你底层是自己的数据中心的物理机,还是某个公有云的 VM,只要你的服务是构建在 K8s 之上,那么就获得了无缝迁移的能力。K8s 就是一个更加中立的云,在我的设想中,未来不管是公有云还是私有云都会提供标准 K8s 能力。对于业务来说,基础架构的上云,最安全的路径就是上 K8s,目前从几个主流的公有云厂商的动作上来看(GCP 的 GKE,AWS 的 EKS,Azure 的 AKS),这个假设是成立的。
不选择 K8s 的人很多时候会从性能角度来攻击 K8s,理由是:多一层抽象一定会损害性能。对于这个我是不太同意的,比如说网络,其实大家可能有个误解,认为 Overlay Network 的性能一定不好,其实这不一定是事实。下面这张图来自 ITNEXT 的工程师对几个流行的 CNI 实现的评测:
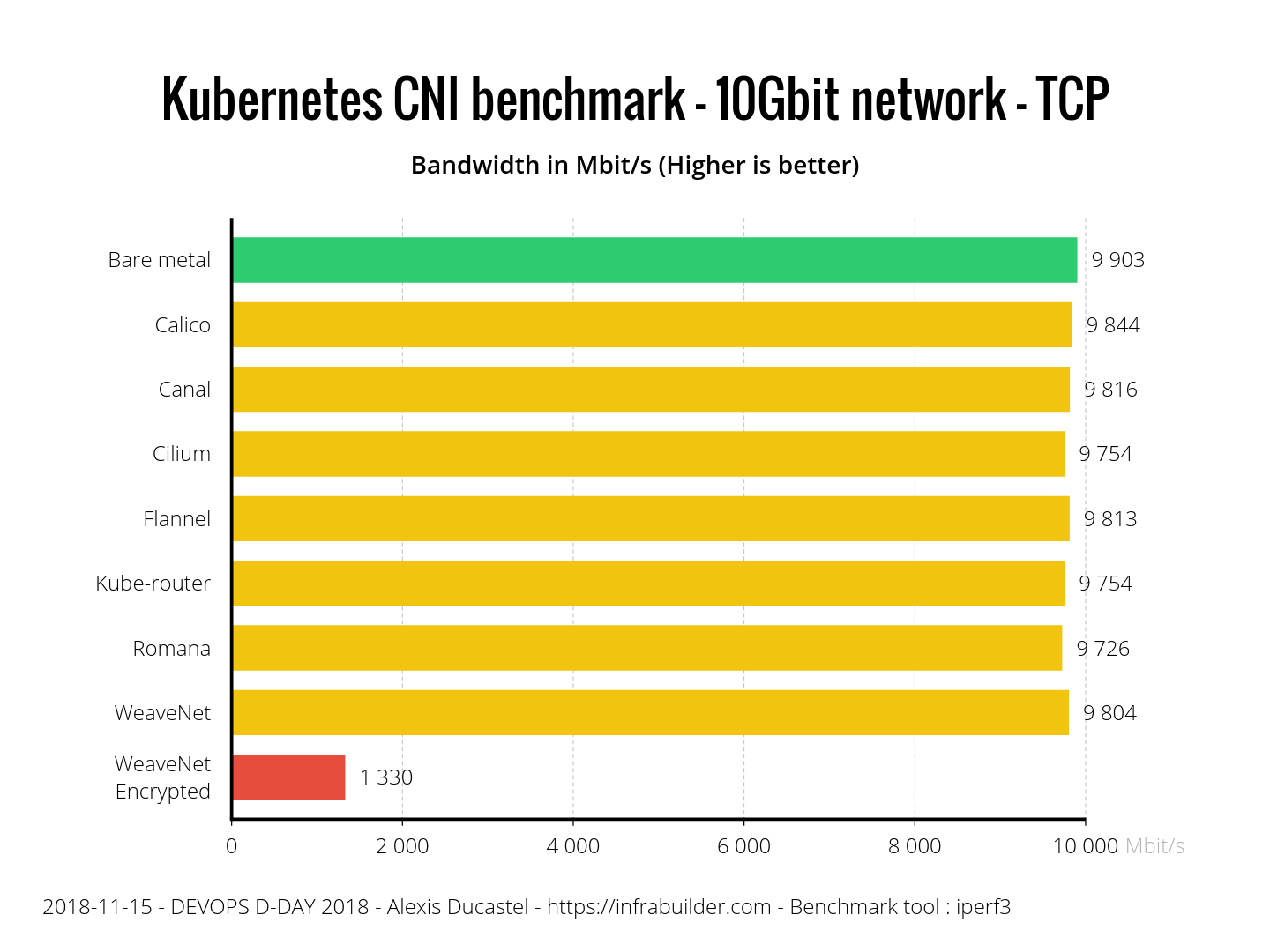
我们其实可以看到,除了 WaveNet Encrypted 因为需要额外的加密导致性能不佳以外,其它的 CNI 实现几乎已经和 Bare metal 的 host network 性能接近,出现异常的网络延迟大多问题是出现在 iptable NAT 或者 Ingress 的错误配置上面。
K8s 的新一代霸主地位已经很稳,但是我觉得 K8s 社区仍然有几个方向需要持续的投入和努力:
- 安全。目前 K8s 就像一个在快车道行驶的车,整个社区的精力过去几年都在做 Feature 和定标准,安全在这个阶段是最容易被忽视的。其实最近两年我们可以陆续地注意到 k8s 一些严重的安全漏洞开始出现(例如:CVE-2018-1002105,CVE-2019-16276,这几个严重的提权漏洞,DDoS 的漏洞就更多了,这里就不提了)。当然这也是好事,说明关注的眼睛已经足够多,但是看看类比的 Liunx、Windows ,尤其是 Windows,已经诞生了那么多年,安全仍然还是一个非常严肃的话题,仍然也有各种各样的 0-day。而且随着 K8s 自身的架构越来越复杂,其依赖的第三方库的服务安全问题未来可能也会浮出水面。但是这也没法避免,这是 K8s 想要成为真正的企业级基础设施的必经之路,但有开源社区的助力,对此我还是比较乐观的。
- 扩展性。涉及两方面,从微观上来看,元信息(Etcd)的扩展性问题是大家在运维 Hyper Scale Cluster 上都会面临的一个问题,例如 Etcd 的本地存储是 BoltDB,在大数据量(其实官方过去的推荐大小是 2G)的情况下 BoltDB 的问题还挺多的,但是最近阿里巴巴对 Etcd 的 Boltdb 做了一系列的改进,解决了部分问题。但是从长远来看,Etcd 并不支持横向的水平扩展,在 Hyper scale 的集群下,仍然会有单机存储的上限。当然这个问题也是有解决方法的,例如使用 TiKV 这样的可扩展的事务型 KV Database 替换 Etcd 底层的存储,这样元信息就能实现水平扩展。
另一方面,从宏观上看跨数据中心的 K8s 部署目前仍然是一个困难的事情,不过我也比较欣喜地看到社区已经有人开始这方面的探索,比如我们的友商 CockroachDB 最近写了一篇 Blog,介绍了他们名为 DNS Chaining 的方案如何实现多数据中心部署 K8s。从长远上来看,K8s 几乎一定会支持跨数据中心,毕竟背后有强烈的需求驱动。
- 第三方生态。如果说 K8s 的目标是奔着操作系统去的,那么一个非常重要的组成部分就是包管理和软件分发,特别是上文我也提到了基础软件的碎片化。现代的基础软件几乎都是分布式系统,相比单机系统,分布式系统的运维和部署调优都会更加复杂,K8s 也不会是所有领域的专家,所以第三方基础软件开发者有必要将自己软件的运维和部署逻辑固化成代码注入到 K8s 中,K8s 早期的 TPR(3rd party resource) 到现在主推的 CRD,其本质还是让第三方开发者将自己的运维逻辑进行封装,这就是 Operator 的概念。其实很多朋友问我什么是 Operator,是不是有什么 SDK 或者 Framework 之类的,虽然红帽、阿里巴巴都在推进自己的 Operator 基础库,但是我想说,Operator 只是一个方法论或者一个 mindset,其实并没有一个通用的套路。我认为 Operator 的核心在于能提供一键部署和运维软件的方式,另一方面能够有机会构建出类似应用商店这样的生态,像红帽的 operatorhub.io 就在做类似的事情。但是多数 Operator 还需要一定时间才能成熟。如果 K8s 官方能够提供更多构建 Operator 的基础库和最佳实践就更好了。
- 本地存储,这个我放在后边说。
所以软件的未来在哪里?我个人的意见是硬件和操作系统对开发者会更加的透明,也就是现在概念刚开始普及起来的 Serverless。Serverless 的好处我在此不再赘述,网上的文章很多。我经常用的一个不十分恰当的比喻是:如果自己维护数据中心,采购服务器的话,相当于买房;使用云 IaaS 相当于租房;而 Serverless,相当于住酒店。长远来看,这三种方案都有各自适用的范围,并不是谁取代谁的关系。目前看来 Serverless 因为出现时间最短,所以发展的潜力也是最大的,我同意最近网易杭研院院长汪源在他的 blog 中的说法:Serverless 技术上是 OK 的,但商业上需要探索出更好的模式。但是另一方面我也相信从用户角度做出好的产品,好的技术,长期商业上一定是没问题的。
从服务治理上来说,微服务的碎片化必然导致了管理成本上升,所以近年 Service mesh (服务网格)的概念才兴起。 服务网格虽然名字很酷,但是其实可以想象成就是一个高级的负载均衡器或服务路由。比较新鲜的是 Sidecar 的模式,将业务逻辑和通信解耦。我其实一直相信未来在七层之上,会有一层以 Service Mesh 和服务为基础的「八层网络」,不过目前并没有一个事实标准出现。istio 的整体架构过于臃肿,相比之下我更加喜欢单纯使用 Envoy 或者 Kong 这样更加轻量的 API Proxy。 不过我认为目前在 Service mesh 领域还没有出现有统治地位的解决方案,还需要时间。
存储之数据库
聊完云和服务化,我们来聊聊存储。无论哪个时代,存储都是一个重要的话题,而且也是我的本行,由于篇幅关系,我今天就先聊数据库。在过去的几年,数据库技术上有以下几个趋势:
- 存储和计算进一步分离。我印象中最早的存储-计算分离的尝试是 Snowflake,Snowflake 团队在 2016 年发表的论文《The Snowflake Elastic Data Warehouse》是近几年我读过的最好的大数据相关论文之一,尤其推荐阅读。Snowflake 的架构关键点是在无状态的计算节点 + 中间的缓存层 + S3 上存储数据,计算并不强耦合缓存层,非常符合云的思想。从最近 AWS 推出的 RedShift 冷热分离架构来看,AWS 也承认 Snowflake 这个搞法是先进生产力的发展方向。另外这几年关注数据库的朋友不可能不注意到 Aurora。不同于 Snowflake,Aurora 应该是第一个将存储-计算分离的思想用在 OLTP 数据库中的产品,并大放异彩。Aurora 的成功在于将数据复制的粒度从 Binlog降低到 Redo Log ,极大地减少复制链路上的 IO 放大。而且前端复用了 MySQL,基本做到了 100% 的应用层 MySQL 语法兼容,并且托管了运维,同时让传统的 MySQL 适用范围进一步拓展,这在中小型数据量的场景下是一个很省心的方案。
虽然 Aurora 获得了商业上的成功,但是从技术上,我并不觉得有很大的创新。熟悉 Oracle 的朋友第一次见 Aurora 的架构可能会觉得和 RAC 似曾相识。Oracle 大概在十几年前就用了类似的方案,甚至很完美的解决了 Cache Coherence 的问题。另外,Aurora 的 Multi-Master 还有很长的路要走,从最近在 ReInvent 上的说法来看,目前 Aurora 的 Multi-Master 的主要场景还是作为 Single Writer 的高可用方案,本质的原因应该是目前 Multi-Writer 采用乐观冲突检测,冲突检测的粒度是 Page,在冲突率高的场合会带来很大的性能下降。
我认为 Aurora 是一个很好的迎合 90% 的公有云互联网用户的方案:100% MySQL 兼容,对一致性不太关心,读远大于写,全托管。但同时,Aurora 的架构决定了它放弃了 10% 有极端需求的用户,如全局的 ACID 事务+ 强一致,Hyper Scale(单库百 T 以上,并且业务不方便拆库),需要实时的复杂 OLAP。这类方案我觉得类似 TiDB 的以 Shared-nothing 为主的设计才是唯一的出路。作为一个分布式系统工程师,我对任何不能无限水平扩展的架构都会觉得不太优雅,所以对于 SIGMOD 将去年的年度系统奖颁发给了 Aurora,我还是有点点酸的……
- 分布式 SQL 数据库开始登上舞台,ACID 全面回归。回想几年前 NoSQL 最风光的时候,大家恨不得将一切系统都使用 NoSQL 改造,虽然易用性、扩展性和性能都不错,但是多数 NoSQL 系统抛弃掉数据库最重要的一些东西,例如 ACID 约束,SQL 等等。NoSQL 的主要推手是互联网公司,对于互联网公司的简单业务加上超强的工程师团队来说当然能用这些简单工具搞定。但最近几年大家渐渐发现低垂的果实基本上没有了,剩下的都是硬骨头。最好的例子就是作为 NoSQL 的开山鼻祖,Google 第一个搞了 NewSQL (Spanner 和 F1)。在后移动时代,业务变得越来越复杂,要求越来越实时,同时对于数据的需求也越来越强。尤其对于一些金融机构来说,一方面产品面临着互联网化,一方面不管是出于监管的要求还是业务本身的需求,ACID 是很难绕开的。更现实的是,大多数传统公司并没有像顶级互联网公司的人才供给,大量历史系统基于 SQL 开发,完全迁移到 NoSQL 上肯定不现实。在这个背景下,分布式关系型数据库,我认为这是我们这一代人,在开源数据库这个市场上最后一个 missing part,终于慢慢流行起来。这背后的很多细节由于篇幅的原因我就不介绍,推荐阅读 PingCAP OLAP 组技术负责人 maxiaoyu 的一篇文章《从大数据到数据库》,对这个话题有很精彩的阐述。
- 云基础设施和数据库的进一步整合。在过去的几十年,数据库开发者都像是在单打独斗,就好像操作系统以下的就完全是黑盒了,这个假设也没错,毕竟软件开发者大多也没有硬件背景。。另外如果一个方案过于绑定硬件和底层基础设施,必然很难成为事实标准,而且硬件非常不利于调试和更新,成本过高,这也是我一直对定制一体机不是太感兴趣的原因。但是云的出现,将 IaaS 的基础能力变成了软件可复用的单元,我可以在云上按需地租用算力和服务,这会给数据库开发者在设计系统的时候带来更多的可能性,举几个例子:
- Spanner 原生的 TrueTime API 依赖原子钟和 GPS 时钟,如果纯软件实现的话,需要牺牲的东西很多(例如 CockroachDB 的 HLC 和 TiDB 的改进版 Percolator 模型,都是基于软件时钟的事务模型)。但是长期来看,不管是 AWS 还是 GCP 都会提供类似 TrueTime 的高精度时钟服务,这样一来我们就能更好的实现低延迟长距离分布式事务。
- 可以借助 Fargate + EKS 这种轻量级容器 + Managed K8s 的服务,让我们的数据库在面临突发热点小表读的场景(这个场景几乎是 Shared-Nothing 架构的老大难问题),比如在 TiDB 中我们可以通过 Raft Learner 的方式,配合云的 Auto Scaler 快速在新的容器中创建只读副本,而不是仅仅通过 3 副本提供服务;比如动态起 10 个 pod,给热点数据创建 Raft 副本(这是我们将 TiKV 的数据分片设计得那么小的一个重要原因),处理完突发的读流量后再销毁这些容器,变成 3 副本。
- 冷热数据分离,这个很好理解,将不常用的数据分片,分析型的副本,数据备份放到 S3 上,极大地降低成本。
- RDMA/CPU/超算 as a Service,任何云上的硬件层面的改进,只要暴露 API,都是可以给软件开发者带来新的好处。
例子还有很多,我就不一一列举了。总之我的观点是云服务 API 的能力会像过去的代码标准库一样,是大家可以依赖的东西,虽然现在公有云的 SLA 仍然有问题,但是长远上看,一定是会越来越完善的。
所以,数据库的未来在哪里?是更加的垂直化还是走向统一?对于这个问题,我同意这个世界不存在银弹,但是我也并不像我的偶像,AWS 的 CTO,Vogels 博士那么悲观,相信未来是一个割裂的世界(AWS 恨不得为了每个细分的场景设计一个数据库)。过度地细分会加大数据在不同系统中流动的成本。解决这个问题有两个关键:
- 数据产品应该切分到什么粒度?
- 用户可不可以不用知道背后发生了什么?
第一个问题并没有一个明确的答案,但是我觉得肯定不是越细越好的,而且这个和 Workload 有关,比如如果没有那么大量的数据,直接在 MySQL 或者 PostgreSQL 上跑分析查询其实一点问题也没有,没有必要非去用 Redshift。虽然没有直接的答案,但是我隐约觉得第一个问题和第二个问题是息息相关的,毕竟没有银弹,就像 OLAP 跑在列存储引擎上一定比行存引擎快,但是对用户来说其实可以都是 SQL 的接口。SQL 是一个非常棒的语言,它只描述了用户的意图,而且完全与实现无关,对于数据库来说,其实可以在 SQL 层的后面来进行切分,在 TiDB 中,我们引入 TiFlash 就是一个很好的例子。动机很简单:1. 用户其实并不是数据库专家,你不能指望用户能 100% 在恰当的时间使用恰当的数据库,并且用对。2. 数据之间的同步在一个系统之下才能尽量保持更多的信息,例如,TiFlash 能保持 TiDB 中事务的 MVCC 版本,TiFlash 的数据同步粒度可以小到 Raft Log 的级别。我其实坚信系统一定是朝着更智能、更易用的方向发展的,现在都 21 世纪了,你是希望每天拿着一个 Nokia 再背着一个相机,还是直接用 iPhone?😊
测试和运维
我觉得面对测试的态度是区分一个普通程序员和优秀程序员的重要标准。现如今我们的程序和服务越来越庞大,光是单元测试 TDD 之类的就已经很难保证质量,不过这些都是 baseline,所以今天聊点新的话题。
说测试之前,我们先问下自己,为什么要测试?当然是为了找 Bug。看起来这是句废话,但是仔细想想,如果我们能写出 Bug-free 的程序不就好了吗?何必那么麻烦😂。 不过100% 的 bug-free 肯定是不行的,那么我们有没有办法能够尽可能地提升我们程序的质量?举个例子,我想到一个 Raft 的优化算法,与其等实现之后再测试,能不能在写代码前就知道这个算法理论上有没有问题?办法其实是有的,那就是形式化证明技术,比较常用的是 TLA+。
TLA+ 背后的思想很简单,TLA+ 会通过一套自己的 DSL(符号很接近数学语言)描述程序的初始状态以及后续状态之间的转换关系,同时根据你的业务逻辑来定义在这些状态切换中的不变量,然后 TLA+ 的 TLC model checker 对状态机的所有可达状态进行穷举,在穷举过程中不断检验不变量约束是否被破坏。举个简单的例子,分布式事务最简单的两阶段提交算法,对于 TLA+ Spec 来说,需要你定义好初始状态(例如事务要操作的 keys、有几个并发客户端等),然后定义状态间跳转的操作( Begin / Write / Read / Commit 等),最后定义不变量(例如任何处于 Committed 状态的 write ops 一定是按照 commit timestamp 排序的,或者 Read 的操作一定不会读到脏数据之类的),写完以后放到 TLC Checker 里面运行,等待结果就好。
但是,我们活在一个不完美的世界,即使你写出了完美的证明,也很难保证你就是对的。第一, Simulator 并没有办法模拟出无限多的 paticipants 和并发度, 一般也就是三五个;第二,聪明的你可能也看出来了,一般 TLA+ 的推广文章也不会告诉你 Spec 的关键是定义不变量,如果不变量定义不完备,或者定义出错,那么证明就是无效的。因此,我认为形式化验证的意义在于让工程师在写代码之前提高信心,在写证明的过程中也能更加深对算法的理解,此外,如果在 TLC Checker 里就跑出异常,那就更好了。
目前 PingCAP 应该是国内唯一一个使用 TLA+ 证明关键算法,并且将证明的 Spec 开源出来的公司,大家可以参考 pingcap/tla-plus 这个 Repo,以及我们的首席架构师唐刘的这篇博客了解更多。
如果完美的证明不存在,那么 Deterministic 的测试存在吗?我记得大概 2015 年在 PingCAP 成立前,我看到了一个 FoundationDB 关于他们的 Deterministic 测试的演讲。简单来说他们用自己的 IO 处理和多任务处理框架 Flow 将代码逻辑和操作系统的线程以及 IO 操作解耦,并通过集群模拟器做到了百分之百重现 Bug 出现时的事件顺序,同时可以在模拟器中精确模拟各种异常,确实很完美。但是考虑到现实的情况,我们当时选择使用的编程语言主要是 Go,很难或者没有必要做类似 Flow 的事情 。所以我们选择了从另一个方向解决这个问题,提升分布式环境下 Bug 的复现率,能方便复现的 Bug 就能好解决,这个思路也是最近几年很火的 Chaos Engineering。 做 Chaos Engineering 的几个关键点:
- 定义稳态,记录正常环境下的 workload 以及关注的重要指标。
- 定义系统稳态后,我们分为实验组和对照组进行实验,确认在理想的硬件情况下,无论如何操作实验组,最后都会回归稳态。
- 开始对底层的操作系统和网络进行破坏,再重复实验,观察实验组会不会回归稳态。
道理大家都懂,但是实际做起来最大的问题在于如何将整个流程自动化。原因在于:一是靠手动的效率很低;二是正统的 Chaos Engineering 强调的是在生产环境中操作,如何控制爆炸半径,这也是个比较重要的问题。
先说第一个问题,PingCAP 在实践混沌工程的初期,都是在物理机上通过脚本启停服务,所有实验都需要手动完成,耗时且非常低效,在资源利用上也十分不合理。这个问题我们觉得正好是 K8s 非常擅长的,于是我们开发了一个基于 K8s 的,内部称为 Schrodinger 的自动化测试平台,将 TiDB 集群的启停镜像化,另外将 TiDB 本身的 CI/CD,自动化测试用例的管理、Fault Injection 都统一了起来。这个项目还催生出一个好玩的子项目 Chaos Operator:我们通过 CRD 来描述 Chaos 的类型,然后在不同的物理节点上启动一个 DaemonSets,这个 DaemonSets 就负责干扰 Pod,往对应的 Pod 里面注入一个 Sidecar,Sidecar 帮我们进行注入错误(例如使用 Fuse 来模拟 IO 异常,修改 iptable 制造网络隔离等),破坏 Pod。近期我们也有计划将 Chaos Operator 开源。
第二个问题,其实在我看来,有 Chaos Engineering 仍然还是不够的,我们在长时间的对测试和质量的研究中发现提升测试质量的关键是如何发现更多的测试 workload。在早期我们大量依赖了 MySQL 和相关社区的集成测试,数量大概千万级别,这个决定让我们在快速迭代的同时保证质量,但是即使这样还是不够的,我们也在从学术界寻求答案.例如引入并通过官方的 Jepsen Test ,再例如通过 SQLfuzz 自动生成合法 SQL 的语句加入到测试集中,这个思路在最近我们的一次 Hackathon 项目中有一个很完美的落地,可以看看这篇介绍这个项目的文章《你呼呼大睡,机器人却在找 bug?》。说了那么多,我只是想说,比起写业务逻辑,在分布式环境下写测试 + 写测试框架花费的精力可能一点都不少,甚至可能多很多(如果就从代码量来说,TiDB 的测试相关的代码行数可能比内核代码行数多一个数量级),而且这是一个非常值得研究和投资的领域。另外一个问题是如何通过测试发现性能回退。我们的测试平台中每天运行着一个名为 benchbot 的机器人,每天的回归测试都会自动跑性能测试,对比每日的结果。这样一来我们的工程师就能很快知道哪些变更导致了性能下降,以及得到一个长期性能变化趋势。
说完测试,另外一个相关的话题是 profiling 和分布式 tracing。tracing 看看 Google 的 Dapper 和开源实现 OpenTracing 就大概能理解,所以,我重点聊聊 profiling。最近这几年我关注的比较多的是 eBPF (extended BPF)技术。想象下,过去我们如果要开发一个 tcp filter,要么就自己写一个内核驱动,要么就用 libpcap 之类的基于传统 BPF 的库,而传统 BPF 只是针对包过滤这个场景设计的虚拟机,很难定制和扩展。

BPF 工作原理

eBPF 架构图
在这个背景下,eBPF 应运而生,eBPF 引入了 JIT 和寄存器,将 BPF 的功能进一步扩充,这背后的意义是,我们在内核中有一个安全的、高性能的、基于事件的、支持 JIT 的字节码的虚拟机!这其实极大地降低了拓展内核能力的门槛,我们可以不用担心在驱动中写个异常把内核搞崩,我们也可以将给 llvm 用的 clang 直接编译成 eBPF 对象,社区还有类似 bcc 这样的基于 Python 的实用工具集……过去其实大家是从系统状态监控,防火墙这个角度认识 eBPF 的,没错,性能监控以及防火墙确实是目前 eBPF 的王牌场景,但是我大胆地预测未来不止于此,就像最近 Brendan Gregg 在他的 blog 里喊出的口号:BPF is a new type of software。可能在不久的未来,eBPF 社区能诞生出更多好玩的东西,例如我们能不能用 eBPF 来做个超高性能的 web server?能不能做个 CDN 加速器?能不能用 BPF 来重定义操作系统的进程调度?我喜欢 eBPF 的另一个重要原因是,第一次内核应用开发者可以无视内核的类型和版本,只要内核能够运行 eBPF bytecode 就可以了,真正做到了一次编译,各个内核运行。所以有一种说法是 BPF is eating Linux,也不是没有道理 :slight_smile:
PingCAP 也已经默默地在 BPF 社区投入了很长时间,我们也将自己做的一些 bcc 工具开源了,详情可以参考 pingcap/kdt 这个 repo。其中值得一提的是,我们的 bcc 工具之一 drsnoop 被 Brendan Gregg 的新书收录了,也算是为社区做出了一点微小的贡献😁。
上面聊的很多东西都是具体的技术,技术的落地离不开部署和运维,分布式系统的特性决定了维护的复杂度比单机系统大得多。 在这个背景之下,我认为解法可能是:不可变基础设施。云和容器的普及让 infrastructure as code 的理念得以变成现实,通过描述式的语言来创建可重复的部署体验,这样可重用的描述其实很方便在开源社区共享,而且由于这些描述几乎是和具体的云的实现无关,对于跨云部署和混合数据中心部署的场景很适合。有些部署工具甚至诞生出自己的生态系统,例如 Terraform / Chef / Ansible。有一种说法戏称现在的运维工程师都是 yaml 语言工程师,其实很有道理的:人总是会出错,且传统的基于 shell 脚本的运维部署受环境影响太大,shell 天然也不是一个非常严谨的语言。描述意图,让机器去干事情,才是能 scale 的正道。
展望未来
过去十年,互联网时代的喷井式发展催生出多种应用需求,随之涌现出多种系统和解决方案,这个势头仍在持续。这些年的发展经验的沉淀会让大家思考如何进一步减少成本,提高易用性。所以未来的软件将朝着更加透明,智能的方向发展。具体来说,现有的系统在多个层面进行整合,向上层提供统一,透明的接口。例如 SQL 发展成操作多种数据系统的通用语言。就数据库系统而言,HTAP 是用户的切实需求,也就意味着它是未来业界发展的一个主要目标。这些需求会驱动业界对现有软件技术的融合与革新,而硬件的发展为之提供更多创新的可能。尤其是 NMVe 和RDMA 逐步成熟之后,会让分布式技术更加可靠和高效。另外部署和运维将会随着 AI 技术的发展变得更加自动化。未来有无限可能,期待我们一起创造与见证。
(洋洋洒洒写了这么多,很多话题因为篇幅的关系,基本只能点到为止,也可能有些地方描述的不准确,先抱歉了,我希望这篇文章成为最近几年在系统领域工业界发生的一些新东西的索引和概览,如果你对其中任何的内容感兴趣,欢迎来 PingCAP 做客和我聊聊。就这样吧,预祝大家新年愉快。)