

时钟对数据库系统尤为重要,目前分布式数据库已经是主流方向,但是在分布式环境中获取一致性的时钟非常困难。
由于存在时钟偏移(clock skew),分布式中各个节点的时钟无法完美同步。人们尝试了各种方法来使得分布式系统各个节点保证时钟同步。比较知名的有Lamport提出的逻辑时钟,混合逻辑时钟 和 TrueTime。
接下来介绍下TiDB中的时钟服务。首先回顾下TiDB集群整体架构:
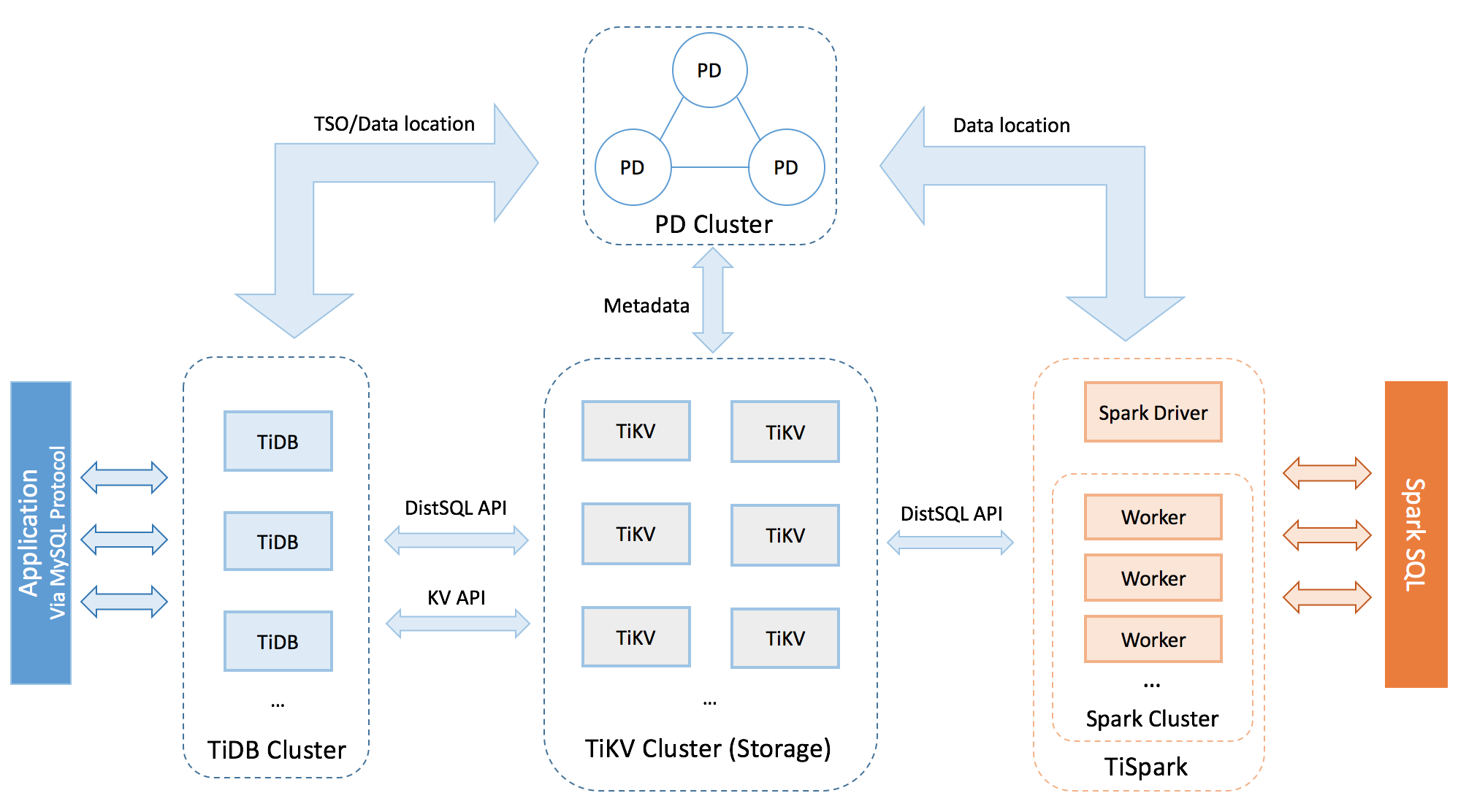
其中,Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是提供时间服务。
TiDB的时间服务是由PD提供的,使用的是中心授时服务。
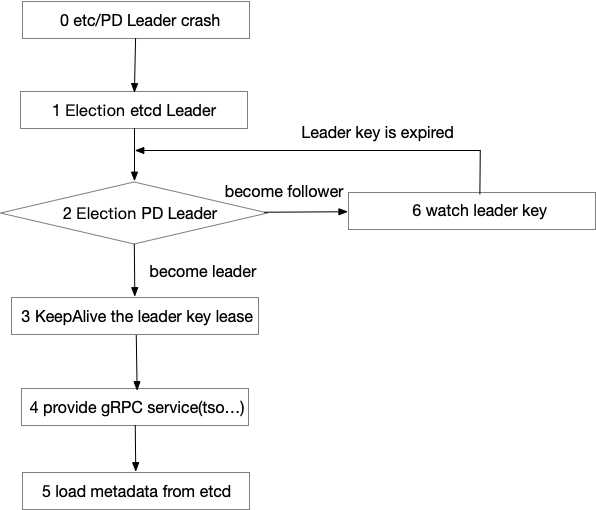
PD集群是由多个(通常3个)PD实例构成的,其中的Leader实例对外提供服务。PD内置的etcd服务,用来实现PD的高可用和元数据存储。当PD的Leader实例出现故障,通过选举产生新的Leader,从而保证了授时等服务的高可用。其中etcd的Leader节点通常与PD的Leader节点是同一个PD实例,因此选举新Leader的时候,会先选举etcd的Leader再选举PD的Leader,其流程大致如下:
PD的TSO使用的是中心式的混合逻辑时钟。其使用64位表示一个时间,其中低18位代表逻辑时钟部分,剩余部分代表物理时钟部分,其结构如下图所示。由于其逻辑部分为18位,因此理论上每秒可以分配时间戳为 218 * 1000 = 262144000个,即每秒可以产生2.6亿个时间戳。

接下来,我们将详细介绍PD中的TSO的算法实现。我们将TSO分成三部分进行讲解:校时,授时,推进。
校时
当新的Leader节点被选出时,其并不知道当前系统的时间已经推进到了哪里,因此首选需要对Leader的时间进行校对。
首先新Leader节点会读取上一个Leader保存到etcd中的时间,这个保存到etcd的时间是上一个Leader申请的物理时间的最大值tlast。通过读取该时间,便可以知道上一个Leader分配的时间戳是小于Tlast的。
获得Tlast后,会将本地物理时间Tnow与Tlast进行比较,如果Tnow - Tlast < 1ms,那么当前的物理时间 Tnext = Tlast + 1,否则 Tnext= Tnow。至此,校时完成。
授时
校时完成后,便可以对外提供TSO服务了。为了保证当前Leader 节点宕机之后,新Leader能够校时成功,需要在每次授时之后,都要对tlast进行持久化,保存到etcd中。如果每次授时之后,都会持久化,性能会大大降低。因此PD目前采取的策略是预申请一个可分配的时间窗口Tx,默认Tx = 3s。
因此在授时开始之前,PD的Leader首先将Tlast = Tnext + Tx存储到etcd中,存储成功之后,PD的Leader便可以在内存中直接分配 [Tnext , Tnext + Tx)之内的所有时间戳。预分配解决了频繁操作etcd带来的性能问题,但是如果Leader crash,就会浪费一些时间戳。
当客户端请求PD的TSO服务时,返回给客户端的是64位表示的混合逻辑时间戳。其中的物理时钟部分便是校时之后的tlast,而逻辑时钟部分便随着请求原子递增。如果逻辑时钟部分超过了最大逻辑时钟的值(1 << 18),则会睡眠50ms来等待时间被推进,物理时间被推进后,如果有时间戳可以被分配,则会继续分配时间戳。
由于TSO请求是跨网络的,所以减少网络开销,PD的TSO服务支持批量请求时间戳。客户端可以一次申请N个时间戳,减少网络开销。
推进
授时阶段,只能通过逻辑时钟部分自增来分配时间戳,当逻辑时钟部分到达上限后,则无法继续分配,则需要对物理时间进行推进。
PD会每50ms检测当前的时钟,进行时钟推进。首先计算jetLag = Tnow - Tlast,如果jetLag > 1ms,则说明混合逻辑时钟的物理时钟部分落后于物理时钟,则需要更新混合逻辑时钟的物理时钟部分:Tnext = Tnow。与此同时,为了防止授时阶段由于逻辑时钟达到阈值导致的等待,在推进阶段,当发现当前的逻辑时钟 已经大于逻辑时钟的最大值的一半时,也会增加混合逻辑时钟的物理时钟部分。一旦混合逻辑时钟的物理时钟部分增长,则逻辑时钟部分会被重置为0。
当Tlast - Tnext <= 1ms时,说明上次申请的时间窗口已经用完了,需要申请下一个时间窗口。此时,同样将Tlast = Tnext + Tx存储到etcd中,然后继续在新的时间窗口内进行时间分配。
PD采用了中心式的时钟解决方案,本质上还是混合逻辑时钟。但是由于其是单点授时,所以是全序的。中心式的解决方案实现简单,但是跨区域的性能损耗大,因此实际部署时,会将PD集群部署在同一个区域,避免跨区域的性能损耗;PD通过引入etcd解决了单点问题,一旦Leader节点故障,会立刻选举新的Leader继续提供服务;而由于TSO服务只通过PD的Leader提供,所以可能会出现性能瓶颈,但是理论上PD每秒可以产生2.6亿个时间戳,并且经过了很多优化,从目前使用情况看,TSO并没有出现性能瓶颈。