

作者:白鳝
我算是PingCAP的老朋友了,从发布开源的TiDB到推出企业版平凯数据库,每次新版本发布,都会特意留意一下。印象最深的还是新版发布时的众筹式文档编制活动,我还曾经在一个版本的文档中贡献过一个章节。在我这些年的印象里,PingCAP是一家在数据库技术上十分有个性,对技术也十分有追求的企业。这样评价一个数据库产品,并不一定完全是赞美。作为关键的IT基础设施产品,过于追求个性,追求技术上的完美,在面向用户需求和场景方面,可能就会打些折扣。PingCAP以往给人的感受是想做一款使用起来像集中式数据库一样方便的分布式数据库产品。这一点TiDB确实做到了,不过天底下没有完美的分布式数据库架构,良好的应用亲和性的代价是TiDB的所有事务都是全局事务,无法针对单元化的应用提供优化解决方案。这些年来,TiDB一直是个偏才,在适合的应用场景中混得风生水起,但是也错过了一些对于极致低延时需求的用户场景。有些用户必须确保低延时高可靠,所以无奈之下只能做出牺牲,选择了其他的数据库产品。
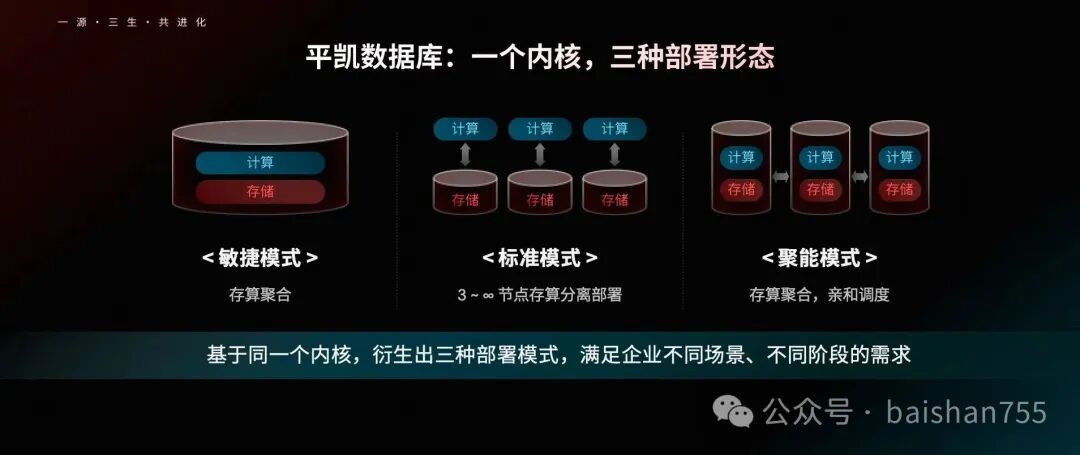
“一源三生”的亮相给我眼前一亮的,这是TiDB面向复杂多元应用场景走出的重要一步,也是走向通用型关系型数据库的关键一步。实现“通用”二字并非易事,因为用户场景是纷繁复杂的,想要用一种数据库去覆盖所有场景是极其困难的。哪怕是目前均衡性极好的Oracle数据库,面对一些互联网特性的场景依然存在不小的短板。TiDB以敏捷模式、标准模式和聚能模式三种形态来适配多变的用户场景,是一种十分聪明的做法。面对小于TB级的中小规模应用场景,TiDB以极简模式起步,用户甚至可以单机模式起步。而支撑三种模式的数据库内核是一个,可以共用一套完全一致的代码,用户的使用体验是近似的,PingCAP的“一源三生”与某些云数据库拼凑多个不同源的数据库产品的方式是完全不同的。

聚能模式则以一种令人意外的模式出现。TiDB Server与TiKV被整合在一个进程空间内,两个功能组件之间保持独立的前提下,可以通过内部调用实现计算与数据物理的“亲和”,消除了分布式架构中原本不可避免的网络开销,将关键应用的延时降低到原来的1/4。刚刚看到这个架构的时候,我是有些吃惊的,难道PingCAP要放弃自己的云原生分布式理念了吗?仔细了解后我不禁对PingCAP的这种新设计竖起大拇指。在聚能模式下,对于延时不敏感的应用,用户还可以像以前一样使用TiDB数据库,不过对于一些对于延时要求极低的应用,则可以利用聚能模式的“近距离存算”的架构进行单元化设计,在一个独立的进程空间里完成低延时的数据计算。TiDB并没有放弃其云原生分布式数据库的理念,而是针对某些特定场景做出了妥协,我们必须为这种妥协点赞,数据库产品必须服务于应用场景。

一个优秀的数据库产品,必须能够服务于当下的用户需求,但是仅仅服务当下是不够的。实际上随着基础软硬件以及云基础设施的技术发展,以及AI技术的发展,未来的数据库无论从架构还是从功能上都会产生巨大的变化。TiDB也正在经历从存算分离1.0时代向更极致的内核层弹性方面演进。
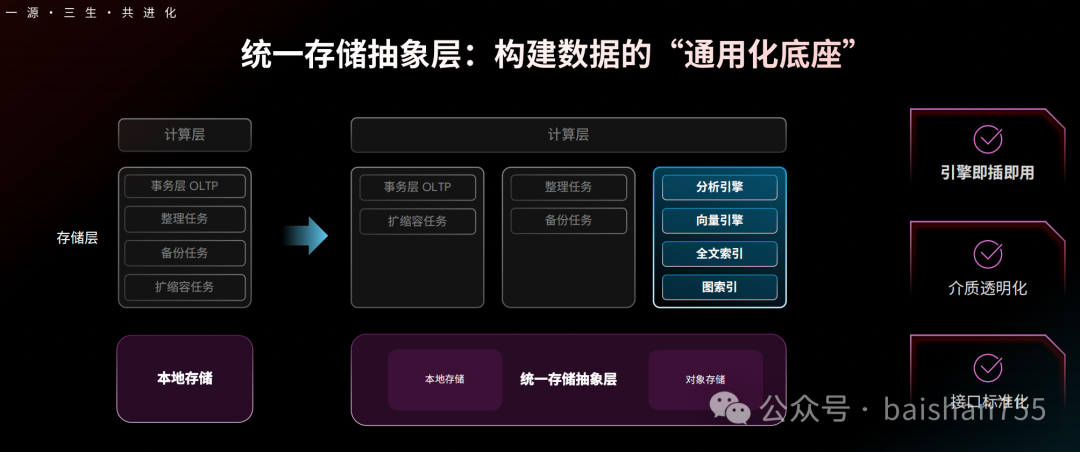
存算分离2.0架构在横向上可以更好地支持AI时代的多模态数据,在纵向上则很好地抽象了存储层,更加便于整合各种存储资源。计算隔离技术让在线任务与离线任务之间的 影响降到最低,可能是解决LSM-TREE存储架构老大难的数据合并问题的一剂良药。AI时代的业务场景与业务形态是持续演变的,应用也会完全脱离现有的菜单、模块、功能点的架构。面对AI时代的数据库产品,也必然会面对不确定性的挑战。TiDB的新一代内核给企业提供一个高稳定、高韧性、极致成本灵活性的数据底座,能够积极拥抱上层应用的不确定性。2026年初的第一场国产数据库产品发布会,让我看到了一个熟悉又陌生的PingCAP,我既看到了数据库厂商对用户场景的积极响应,也看到了对未来数据库技术的积极探索。在中国这个具有丰富场景,充满挑战的数据库应用环境中,TiDB应该是有光明前景的。