

作者:李坤
相信会有不少 TiDB 的用户对以下场景感同身受:
- 「我到底要给 storage 线程池分配多少个线程呢?少了怕之后不够用,多了又怕影响整个系统的性能。还有这高中低优先级…」
- 「线上有一条大查询,把线程池全打满了,影响线上业务了!」
为了解决这些问题,在 TiDB 4.0 中,我们对底层的执行机制做了一些改进,引入了一个全新的线程池来替代以前 storage 和 coprocessor 的线程池,希望能够解决大家曾经遇到的这些问题。
下面我来详细介绍一下这其中的原理及效果,以及在线上使用的最佳实践。
概述
用户的场景,很多时候是混合的,并不是 100% 纯粹的在线业务或分析业务。所以一个在线的 OLTP 业务系统,也避免不了要临时执行一些扫描数量较多、执行时间较长的大查询 SQL。再有就是不少公司应用开发人员也掌握着数据库账号,由于应急或者误操作,也可能在线上发起了一个大查询的 SQL。这些大查询也就有可能会影响在线的 OLTP 业务的性能。
这个问题也一直是广大用户非常关心的问题。在 TiDB 4.0 版本,为了解决这个问题,我们采用了全新的线程池方案:Unified Thread Pool。
优化方案
TiKV 原有的线程池方案中有 Coprocessor、Storage 两套线程池来处理读请求。这些线程池原本是用来分隔不同的任务,减少它们之间的相互影响,Storage 线程池主要处理点查,coprocessor 线程池则处理其余的读请求。但这也带来一些缺点,如:
- 由于多个线程池共存,每个线程池都被限制至无法使用系统的全部资源。
- 每套任务又对应多个优先级,需要对每个线程池单独配置,使用和学习成本较高。
在 TiDB 4.0 中,我们将读相关的线程进行了统一,用户可以选择用一个统一的线程池来处理所有这些读请求。不需要考虑各个优先级需要多少线程,也不需要区分 storage 和 coprocessor 各需要多少线程,只要给整个读线程池分配一个合适的线程数量就可以了。如下图所示:

实现原理
新的线程池自带智能调度策略,能够有效地平衡不同请求对计算资源的消耗状况。
在文章的一开头就提到了这么一个情况,线上业务跑的是短小的查询,而这时用户可能手工执行了一条会占用大量计算资源的分析型查询,严重挤占了线上业务所需的计算资源,导致线上业务的性能降级。
虽然旧的线程池模型中会区分用途和优先级,但这里的优先级只起了线程池间的隔离作用,并没有做到真正起到效果。而且通常为了避免计算资源闲置,其中的每一个线程池都会分配有足够多的线程数量。当多个线程池都有足够多的任务运行时,它们势必会互相争抢计算资源。
在新的线程池中,每个任务依然有优先级的区分,而且这里的优先级是真正的优先级。新线程池中有 3 个全局队列,任务被执行的机会由它所在的队列决定。如下图所示,Level 0 队列中任务被执行的概率最高,而 Level 2 队列中的任务被执行的概率最低。
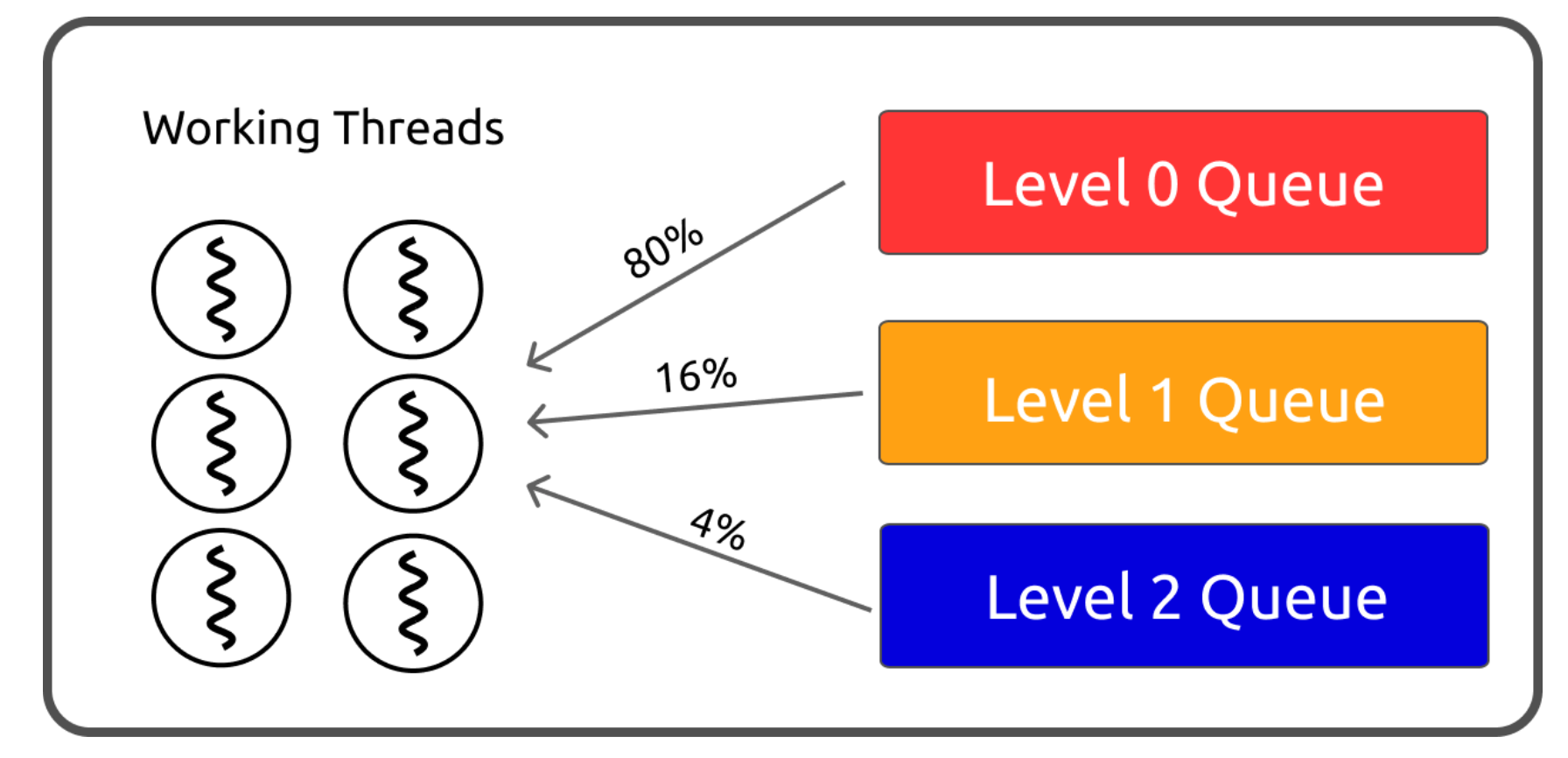
那么如何决定任务应在哪个队列中呢?通常有一个原则,执行时间长的任务的优先级应该比较低。于是,对于一般的任务,我们会先将它放入 Level 0 队列中,并监控这个任务执行所花的时间。如下图所示,一个原本需要约一秒钟,现在将会变为许多个时间约为一毫秒的小任务。
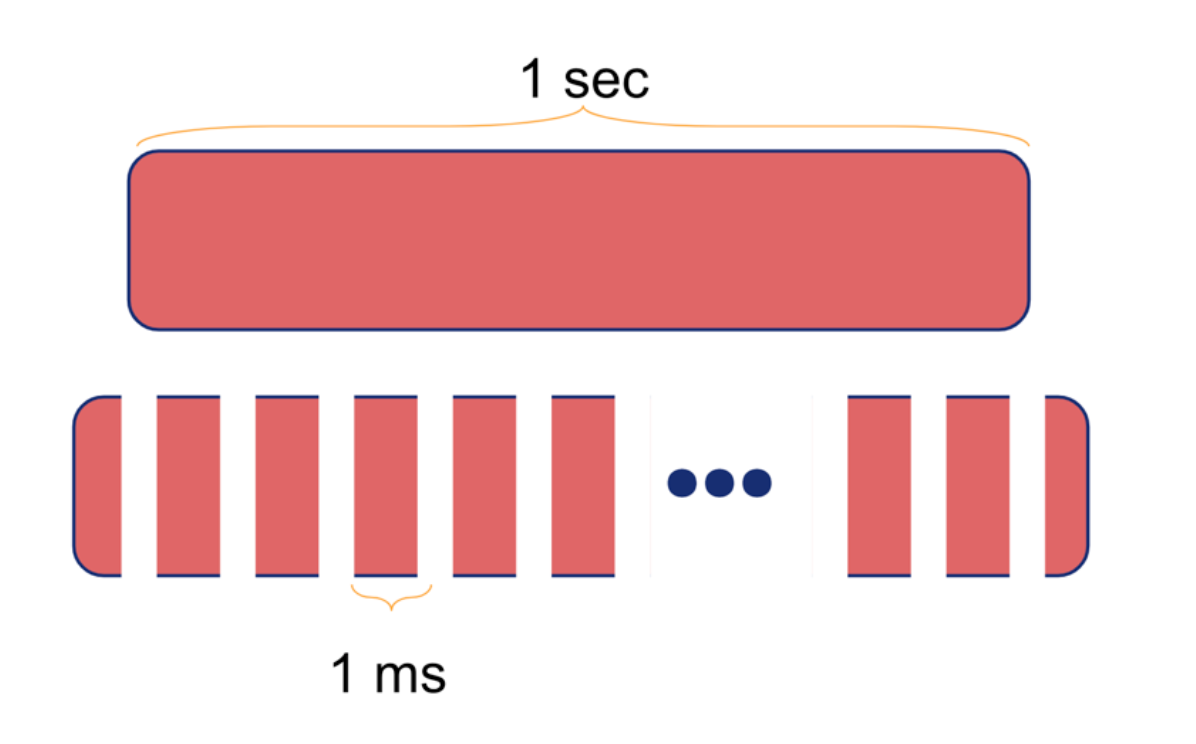
随着任务执行时间增长,任务就会被放入优先级更低的队列中。通过这样的策略,我们就能做到让短作业始终能得到较多的计算资源迅速完成。这很类似操作系统的多级反馈队列调度算法。
启用效果
目前该 Feature 已经在 4.0 的最新版本中正式 GA,默认会开启。
- 只需要设置 unified read pool 的线程数。也就是说,不用根据业务需要来调整用于点查的 storage read pool 的线程数。线程总数默认为 CPU 逻辑处理器数量的 80%,也可以在 readpool.unified 中调整 max-thread-count 来设置。
- 扫表类大查询对小查询的影响会得到较好的控制(对小查询 QPS 的影响通常在 20% 以内)。
测试效果:
-
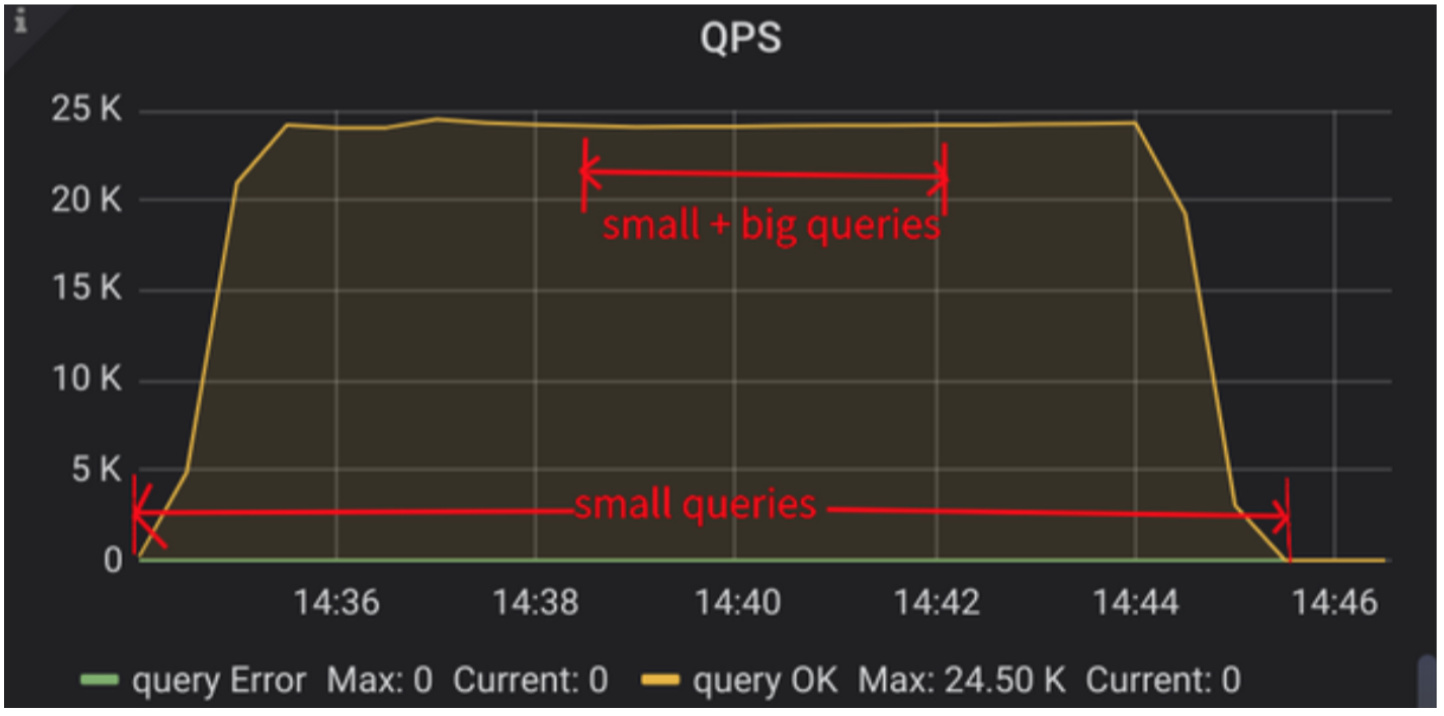
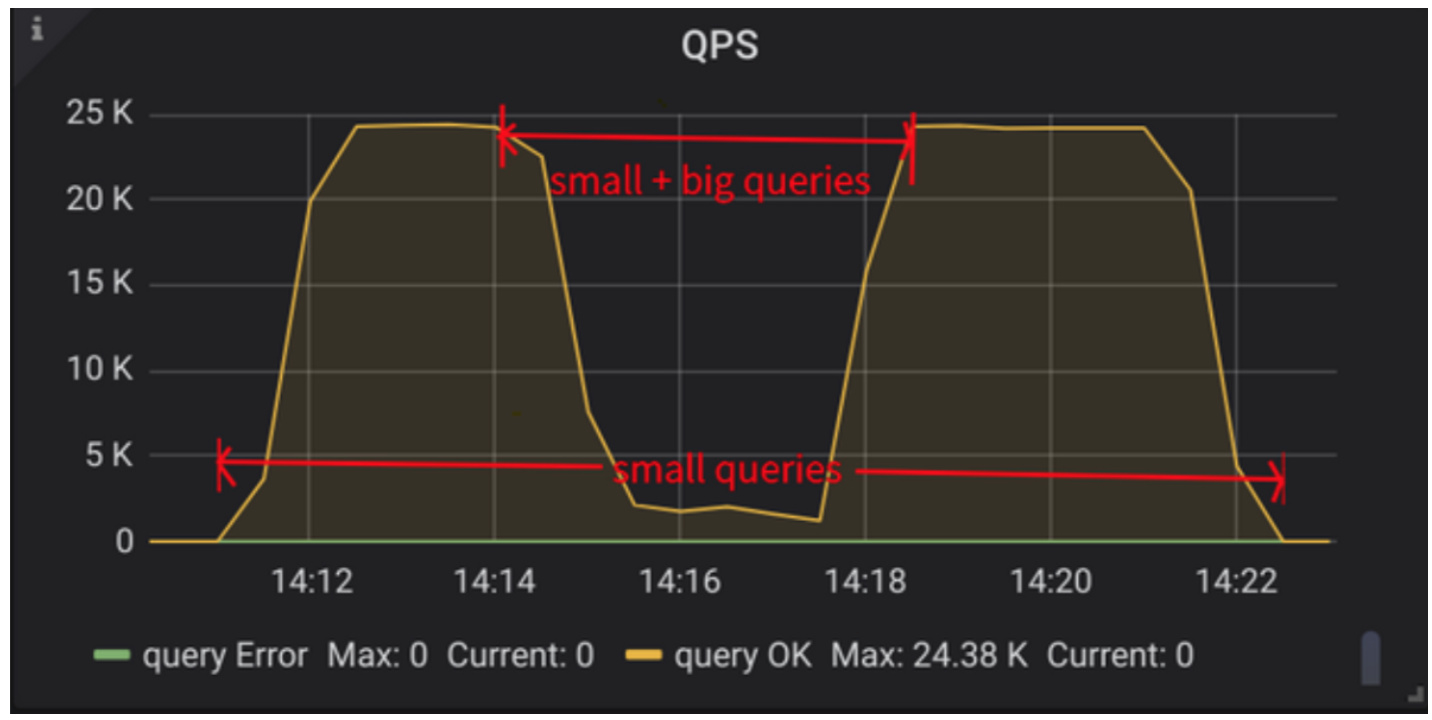
首先使用 sysbench read_only 模拟持续的小查询,然后中途执行扫表类大查询:
- 使用 Unified Read Pool 整体 QPS 波动较小:
- 旧线程池方案下,QPS 波动大:
最佳实践
以 16 vcore 为例,通常建议根据业务负载特性调整其 CPU 使用率在线程池大小的 60%~90% 之间。默认会使用 16*80% = 12 线程数。可以观察Grafana 监控上 TiKV-Details. Thread CPU. Unified read pool CPU 的峰值不超过 800%, 那么建议用户将 readpool.unified.max-thread-count 设置为尽量少的线程数,比如 10,过多的线程数会造成更频繁的线程切换,并且抢占其他任务资源。