

故障影响
公司所有的TIDB集群集群不可用,涉及多个业务线:支付、视频、数据分析、用户等多个业务。
业务流量监控图:

系统负载
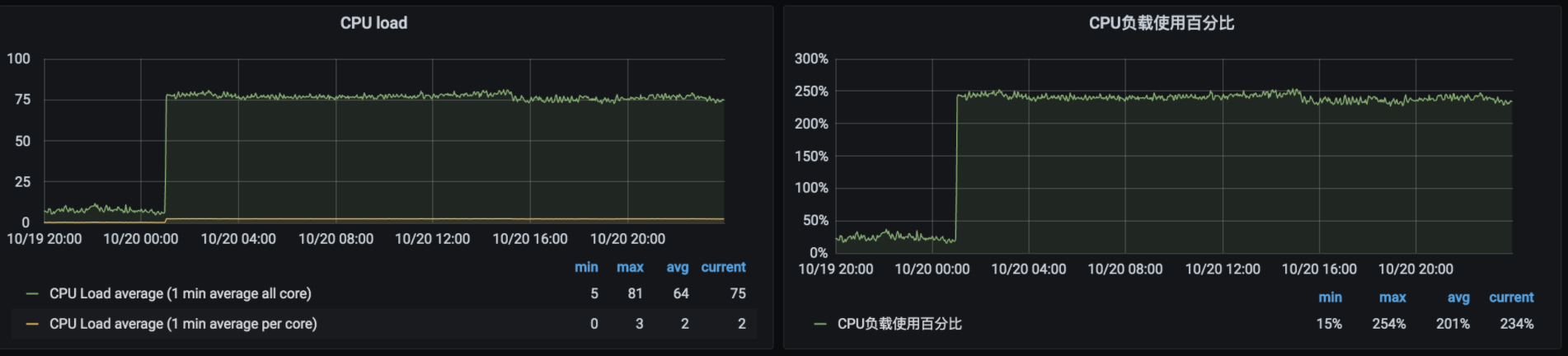
备份任开始时间

登录服务器
df -h 直接夯死
根据cpu负载以及 duration 的时间基本判断是ceph导致的问题。
BR备份原理:
TIDB是分布式的数据库,因此备份也是分布式的。TIDB每天夜晚零晨都会使用TIDB备份组件BR进行一次全量备份;使用BR备份依赖于所有TiKV节点都有一个共享文件系统详情如下图:
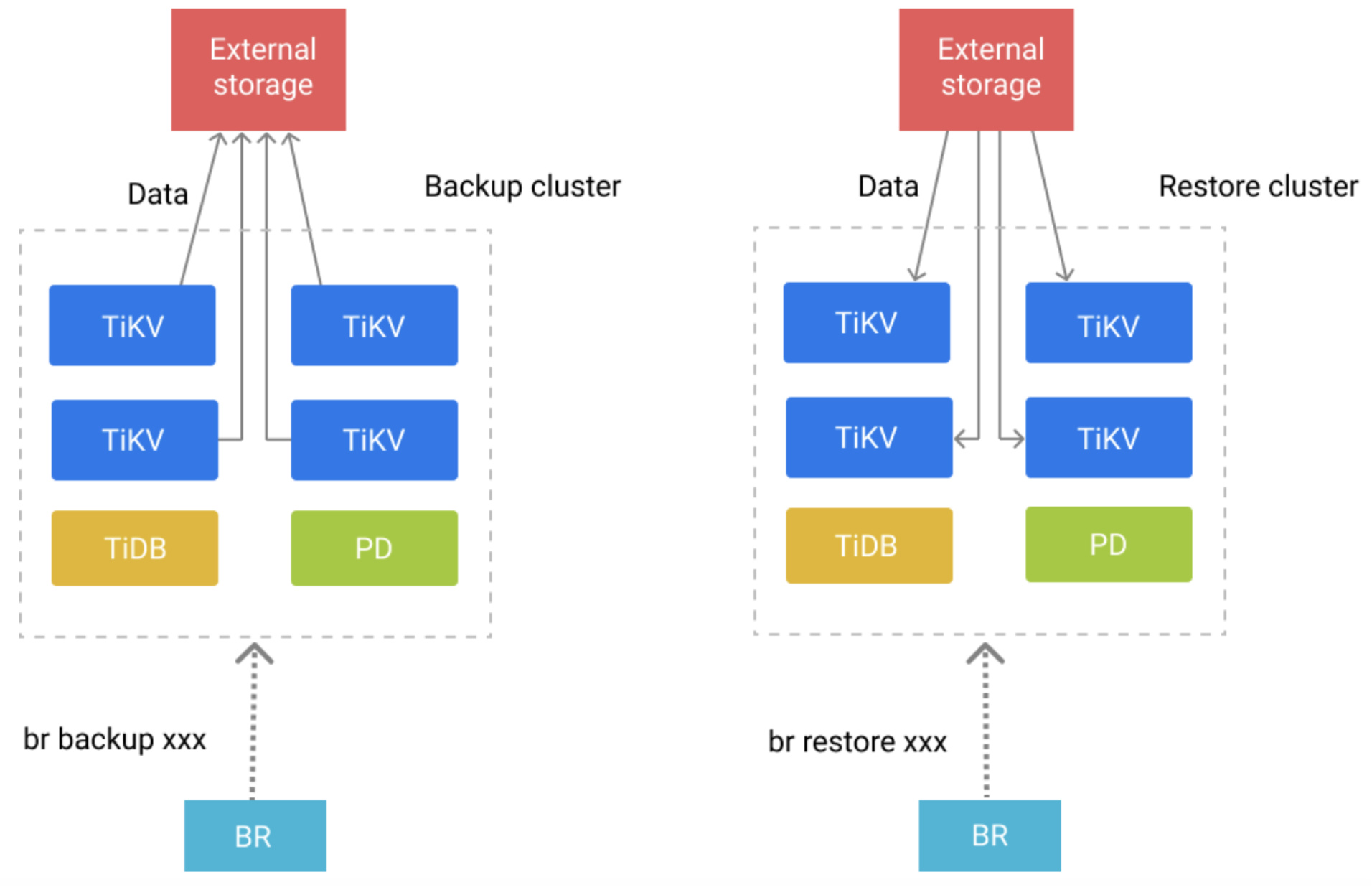
使用ceph挂载到tidb的机器做共享文件。
如下图所示:

当前TIDB部署架构
| IP | 业务部署 |
|---|---|
| 10.92.xxx.xxx | pd、tidb-server、tikv-20161、tikv-20162、tikv-20163 |
| 10.93.xxx.xxx | pd、tidb-server、tikv-20161、tikv-20162、tikv-20163 |
| 10.94.xxx.xxx | pd、tidb-server、tikv-20161、tikv-20162、tikv-20163 |
| 10.95.xxx.xxx | tikv-20161、tikv-20162、tikv-20163 |
| 10.96.xxx.xxx | tikv-20161、tikv-20162、tikv-20163 |
排查过程
问题疑问
df -h 直接夯死把机器挂载点卸载是否可以解决?
umount -l /data/local_backup
强制卸载机器上所有的挂载点,业务方还是无法访问。
排查TIDB相关日志
pd、tidb-server tikv 日志也没有发现啥有用的报错信息。
备份使用的是/data/local_backup 目录虽然目录卸载了但相关的文件句柄是不是一直还在系统里占用着,把tikv节点重启一下是否可以。
tidb 是三副本,所以理论上关闭一个节点对业务上无影响。
Tiup
tiup pingcap公司专门为tidb开发的管理工具。
因tuip需要管理多个集群,为防止某台管理机宕机不可管理;因此将tuip的相关信息存储在ceph上,当前ceph不可用tuip也无法,因此只能退回手动管理。
手动关闭tikv节点:
sudo systemctl stop tikv-20161.service
启动:
sudo systemctl start tikv-20161.service
启动报错:
[2020/10/20 11:17:46.389 +08:00] [FATAL] [server.rs:345] ["failed to create raft engine: RocksDb IO error: While lock file: /data/tidb-data/tikv-20161/raft/LOCK: Resource temporarily unavailable"]
初步怀疑tivk有一个文件锁,非正常关闭不会删除文件锁。mv LOCK LOCK_back 在次启动还是同样报错。
再次猜测
有可能是机器上的文件句柄资源使用完了,查看文件句柄配置文件
cat /etc/security/limits.conf
* soft nofile 655350
* hard nofile 655350
* soft nproc 655350
* hard nproc 655350
文件句柄非系统默认
查看本机当前文件句柄数量
lost |wc -l 直接卡死
在一台非tidb机器执行看一下,非tidb机器执行速度很快 。更加确认是文件句柄的问题
lsof > /data/lsof.out
经过漫长的等待⌛终于完成了。
wc -l lsof.out
5668031 lsof.out
看看都是那些进程占用了
awk '{print $2}' lsof.out | sort | uniq -c|sort -n
2716581 369001
2919707 369003

解决问题思路
- 先关闭一台tikv上所有tikv节点
- 查看文件句柄数据量
- 重启tikv节点
- 观察日志
开始解决问题
关闭Tikv节点
sudo systemctl stop tikv-20161.service
sudo systemctl start tikv-20161.service
启动后日志没有滚动,端口、进程,都没有
查看tikv-20161.service
cat /etc/systemd/system/tikv-20161.service
[Unit]
Description=tikv service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
#LimitCORE=infinity
LimitSTACK=10485760
User=tidb
ExecStart=/data/tidb-deploy/tikv-20161/scripts/run_tikv.sh
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
手动拉取run_tikv.sh 这个配置文件是否可行
nohup run_tikv.sh &
手动也无法拉起,端口进程,日志没有打印
sh -x 查看脚本卡在了那里

cat run_tikv.sh
#!/bin/bash
set -e
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
cd "/data/tidb-deploy/tikv-20161" || exit 1
echo -n 'sync ... '
stat=$(time sync || sync)
echo ok
echo $stat
exec bin/tikv-server \"
--addr "0.0.0.0:20161" \"
--advertise-addr "10.92.xxx.xxx:20161" \"
--status-addr "10.92.xxx.xxx:20181" \"
--pd "10.92.xxx.xxx:2379,10.93.xxx.xxx:2379,10.94.xxx.xxx:2379" \"
--data-dir "/data/tidb-xxx/tikv-20161" \"
--config conf/tikv.toml \"
--log-file "/data/tidb-xxx/tikv-20161/log/tikv.log" 2>> "/data/tidb-xxx/tikv-20161/log/tikv_stderr.log"
sync 卡住了
使用命令重启试一下:
/data/tidb-deploy/tikv-20161/bin/tikv-server \"
--addr "0.0.0.0:20161" \"
--advertise-addr "10.92.xxx.xxx:20161" \"
--status-addr "10.92.xxx.xxx:20181" \"
--pd "10.92.xxx.xxx:2379,10.92.xxx.xxx:2379,10.92.xxx.xx:2379" \"
--data-dir "/data/tidb-data/tikv-20161" \"
--config /data/tidb-xxx/tikv-20161/conf/tikv.toml \"
--log-file "/data/tidb-xxx/tikv-20161/log/tikv.log"
[2020/10/20 16:02:45.939 +08:00] [FATAL] [server.rs:295] ["lock /data/xxxx/tikv-20160 failed, maybe another instance is using this directory."]
/data/xxxx/tikv-20160 可能被某些文件正在占用


僵尸进程占用着文件
kill -s SIGCHLD pid
kill掉僵尸进程之后在次使用命令启动
僵尸进程:僵尸进程占用着文件无法重启,处理僵尸进程有两种方法一种是重启操作系统,另一种杀死kill -s SIGCHLD pid 但也有可能杀死父进程的pid变为1 此时就无法kill只能重启操作系统。
命令重启后,日志滚动看着日志是正常tikv打印,注释掉脚本里相关sync 然后在启动
#!/bin/bash
set -e
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
cd "/data/tidb-deploy/tikv-20161" || exit 1
#echo -n 'sync ... '
#stat=$(time sync || sync)
#echo ok
#echo $stat
exec bin/tikv-server \"
--addr "0.0.0.0:20161" \"
--advertise-addr "10.92.xxx.xxx:20161" \"
--status-addr "10.92.xxx.xxx:20181" \"
--pd "10.92.xxx.xxx:2379,10.92.xxx.xx:2379,10.92.xxx.xx:2379" \"
--data-dir "/data/tidb-data/tikv-20161" \"
--config conf/tikv.toml \"
--log-file "/data/tidb-deploy/tikv-20161/log/tikv.log" 2>> "/data/tidb-deploy/tikv-20161/log/tikv_stderr.log"
sudo systemctl daemon-reload 重新加载tikv-20161.service
sudo systemctl start tikv-20161.service
- 为了后面还可以使用tiup 进行管理,还是使用
systemctl进行启动
tikv 可以正常启动,但这样做非常不友好,当前正在这个store上的业务业务上会受影响。
因此我们需要在启动某个节点的时候把该节点上的region进行驱逐
调度region
./pd-ctl -u http://10.92.xxx.xxx:2379
查看当前所有的tikv节点:
>>store
把 store 1 上的所有 Region 的 leader 从 store 1 调度出去
scheduler add evict-leader-scheduler 1
把对应的 scheduler 删掉,如果不删除store 1 节点不然再被调度region
scheduler remove evict-leader-scheduler-1
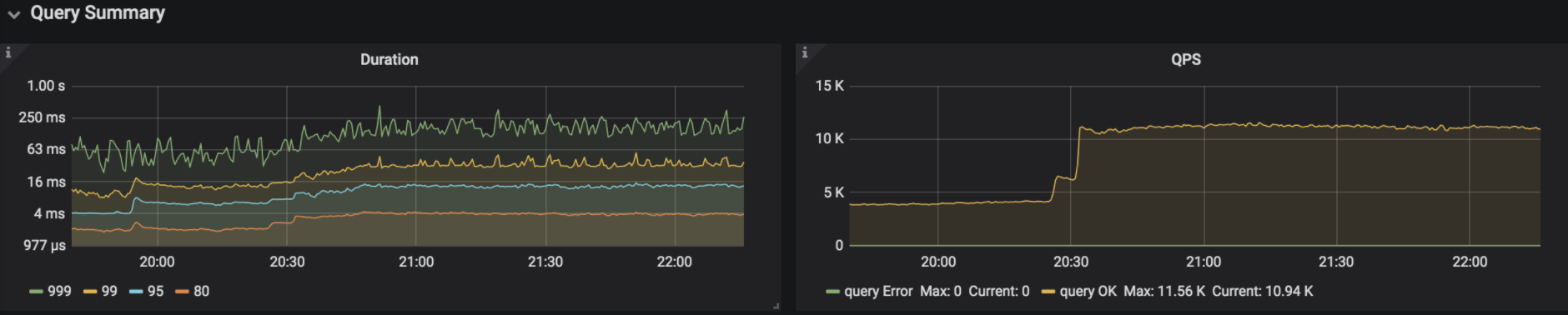
业务恢复正常
重启完所有tikv节点后业务恢复正常
其它问题
-
理论上 15个节点 关闭3个节点 不会影响正常的请求 当时的表现是关闭3个节点 直接就无法访问了
noleder官方回复:
由于 grpc 线程卡死,tikv 向 pd 上报的 heardbeat 失败,pd 此时已有一个 region 迁移的操作,但是只成功了添加 learner 的操作,后pd 检查到现在有四个 peer,一个 learner,一个挂掉的,两个正常的,就把挂掉的干掉了 。此操作属于 PD 的预期行为,正在讨论是否需要进行改进
-
Tikv发现资源可用为啥一直建立这么文件句柄
官方回复:
lsof 看起来会把 threads 所能访问到的所有 fd 都打出来,也就是说这里 grep 出来的数量 / 线程数 才是真实的 fd 数量
-
10.20 日 Ceph 卡死时 BR 备份导致集群 QPS 掉底问题
官方回复:
BR 发起备份时,tikv 向 ceph 盘创建目录,导致 tikv grpc 卡主,最终导致 TiKV 无响应 QPS 掉底。通过 PD 日志判断,也符合此推断此问题 4.0.8 版本修复
-
如果改用 ceph s3 API 是否会存在风险
官方回复:
建议继续使用 local 模式备份
ceph s3 协议未进行充分测试
目前官方在4.0.8 版本当中修复此问题: issue:https://github.com/tikv/tikv/pull/8891
期待
希望官方对ceph s3 协议纳入测试体系
感谢
最后感谢官方在解决问题的过程提供的远程支持。再次感谢!