

【是否原创】是
【首发渠道】TiDB 社区
前言
分布式关系型数据库TiDB是一种计算和存储分离的架构,每一层都可以独立地进行水平扩展,这样就可以做到有的放矢,对症下药。

从TiDB整体架构图可以看到,计算层(图中的TiDB Cluster)负责与外部应用使用MySQL协议通信,每一个TiDB Server是一个无状态节点彼此独立,应用端连接任何一个TiDB节点都可以正常访问数据库。这样做的好处有以下两点:
- 简单增加TiDB节点就可以提升集群处理能力。
- 把TP请求和AP请求在计算层分开,各玩各的互不影响。
但这样带来的一个问题是,如果集群有多个TiDB节点,应用端应该访问哪一个呢?我们不可能在应用端写多个数据库连接,A业务访问TiDB-1,B业务访问访问TiDB-2。又或者是习惯了分库分表读写分离的同学会考虑用MyCat这类的数据库中间件来实现请求转发。
TiDB的诞生初衷就是彻底告别各种复杂的数据库拆分模式,做到不和数据库中间件强耦合,我们需要的是一个单纯的代理来自动实现TiDB节点路由。
这时候,运行在TCP层的负载均衡组件显然更适合。
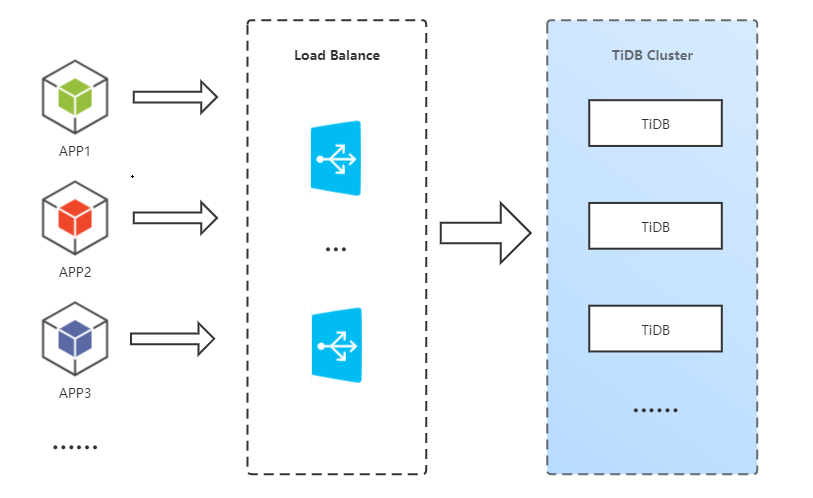
TiDB可以用哪些负载均衡组件
经过多方调研和使用,这里推荐以下三种TiDB负载均衡方案。
首先是HAProxy,它作为一款工作在TCP(四层)和HTTP(七层)的开源代理组件,支持丰富的负载均衡策略以及出色的性能从而使用非常广泛,它是TiDB官方推荐的负载均衡方式。
其次是LVS,这也是一款鼎鼎大名的负载均衡开源软件,它工作在网络第四层,流量直接通过Linux内核来处理性能非常高,同时也支持多种负载均衡算法,但是配置和使用相对比较复杂。
最后要介绍一下TiDB孵化器下的Weir,这个项目最初由伴鱼发起并开源,而后PingCAP也加入其中,也是官方推荐的负载均衡之一。除此之外,它还支持SQL审计、监控、多租户、自适应熔断限流等高级特性,对这方面有需求的可以优先考虑。和前面两种不一样的是,它是工作在第七层应用层的。
另外,像DNS解析或F5这类非软件层面的负载均衡也可以用在TiDB上,但不在本文的讨论范围。
HAProxy
HAProxy在TiDB中的最佳实践官网有一篇文章详细介绍过,手把手教你如何安装和配置,地址是https://docs.pingcap.com/zh/tidb/dev/haproxy-best-practices
这里借用里面的一张图:
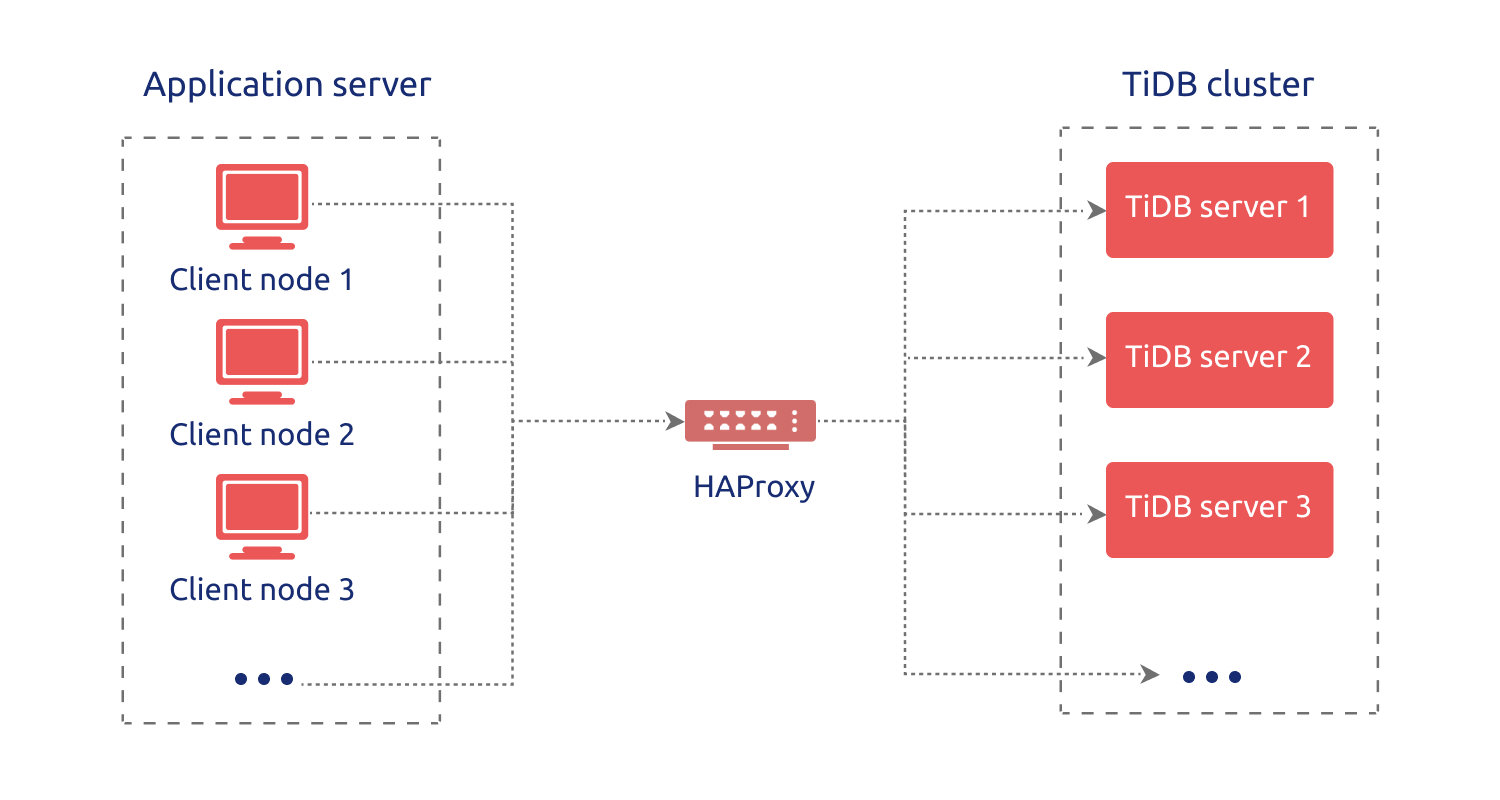
从这张图里面可以发现,引入HAProxy后它自身成为了一个单点,一旦出现故障那整个数据库都无法访问,那么搭建高可用负载均衡是不可避免的,这里我推荐的方式是使用Keepalived+VIP的方式,架构如下图所示:
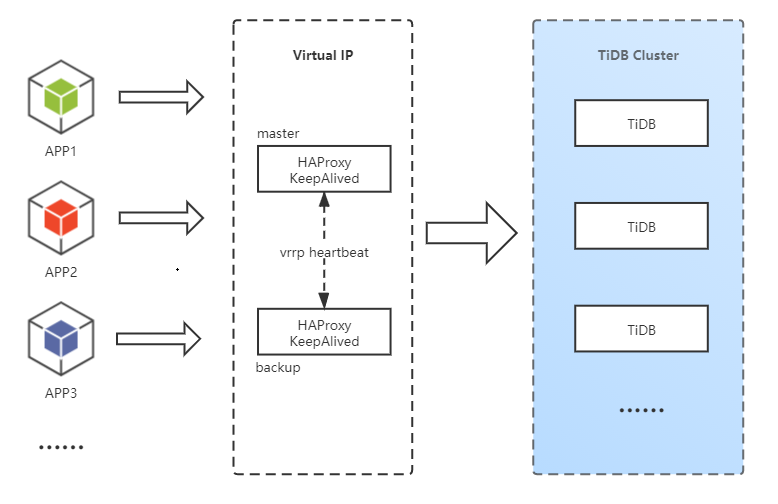
Keepalived的工作原理是基于虚拟路由冗余协议(VRRP)让两台主机绑定同一个虚拟IP,当其中的master节点故障时自动路由到backup节点,无需人工介入。
值得一提的是,bakcup节点在成为master前都是闲置状态,有一定的资源浪费。
接下来看一下如何操作。
直接通过yum就可以安装keepalived:
[root@localhost ~]# yum install -y keepalived
[root@localhost ~]# which keepalived
/usr/sbin/keepalived
它的配置文件在/etc/keepalived/keepalived.conf。
分别在两台负载均衡节点上安装keepalived。
在第一台节点(设置为master)上修改keepalived的配置如下:
! Configuration File for keepalived
global_defs {
router_id kad_01 #节点标识,要全局唯一
}
vrrp_instance tidb_ha {
state MASTER #节点角色
interface ens192 #这里设置成自己的网卡名字,标识绑定到哪个网卡
virtual_router_id 51 #虚拟路由id,同一组主备节点要相同
priority 100 #优先级,要确保master的优先级比backup的高
advert_int 1 #主备之间检查频率为1秒
authentication {
auth_type PASS
auth_pass tidb666 #主备之间的认证密码
}
virtual_ipaddress {
10.3.65.200 #设置绑定的虚拟IP
}
}
这里只演示了最基础的几个配置,它还可以用更多的配置实现复杂功能,可以参考其他资料实现。
然后启动服务:
[root@localhost haproxy]# systemctl start keepalived
[root@localhost haproxy]# systemctl status keepalived
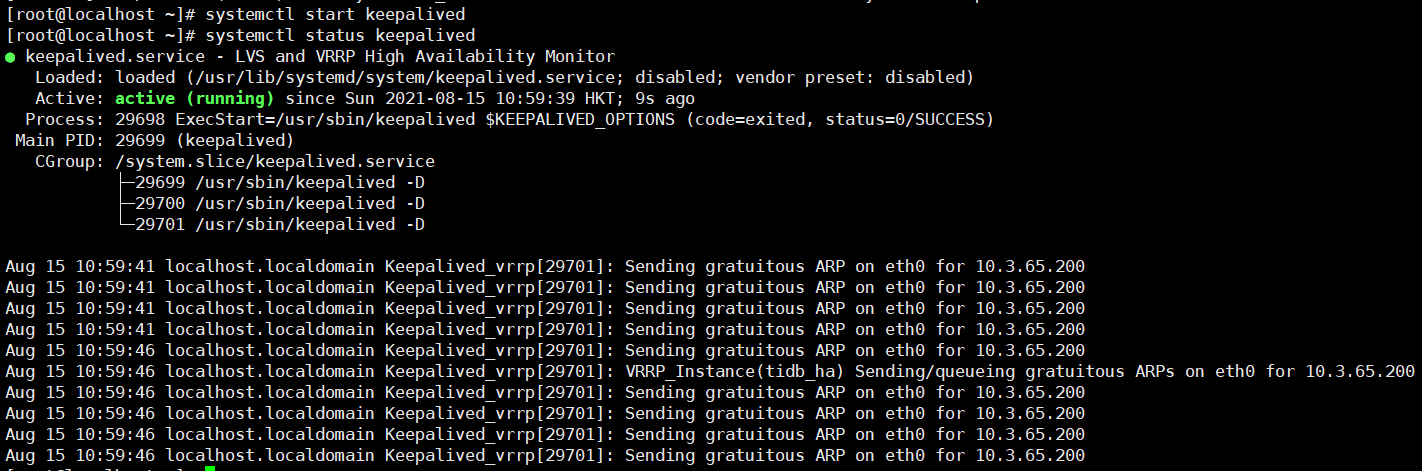
可以看到当前keepalived已经是active (running)状态,虚拟IP已经绑定到了网卡上:
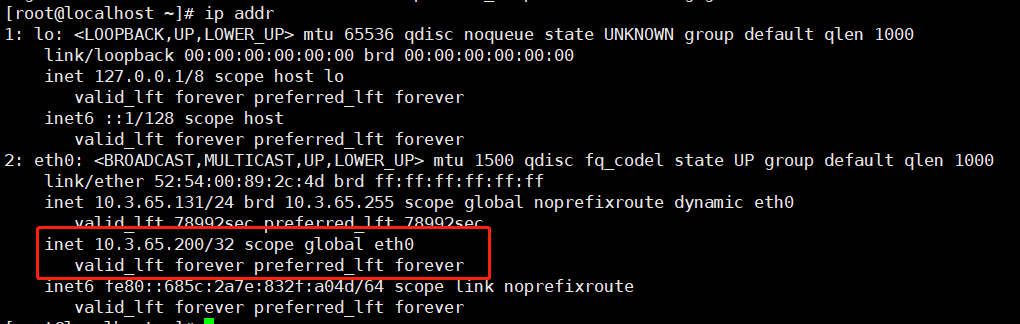
我们用虚拟IP为入口验证一下是否能够登录到TiDB中:
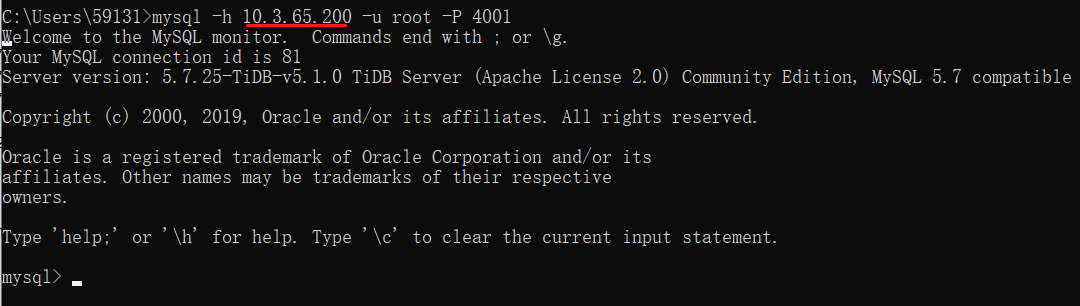
发现登录成功。
用相同的方式,用如下配置文件在第二个节点启动keepalived服务:
! Configuration File for keepalived
global_defs {
router_id kad_02 #节点标识,要全局唯一
}
vrrp_instance tidb_ha {
state BACKUP #节点角色
interface eth0 #这里设置成自己的网卡名字,标识绑定到哪个网卡
virtual_router_id 51 #虚拟路由id,同一组主备节点要相同
priority 50 #优先级,要确保master的优先级比backup的高
advert_int 1 #主备之间检查频率为1秒
authentication {
auth_type PASS
auth_pass tidb666 #主备之间的认证密码
}
virtual_ipaddress {
10.3.65.200 #设置绑定的虚拟IP
}
}
这里要注意router_id、state、priority要与第一个节点不同。
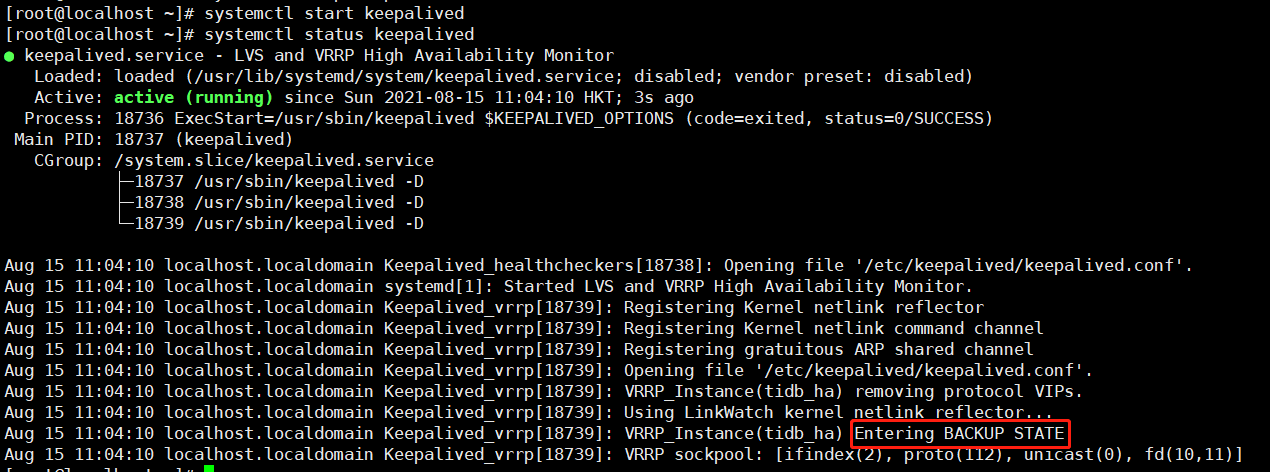
接着我模拟master节点故障,直接把它关机:
[root@localhost haproxy]# poweroff
Connection closing...Socket close.
Connection closed by foreign host.
Disconnected from remote host(centos-9) at 20:38:16.
Type `help' to learn how to use Xshell prompt.
[C:\"~]$
退出连接后再次登录,发现依然正常:
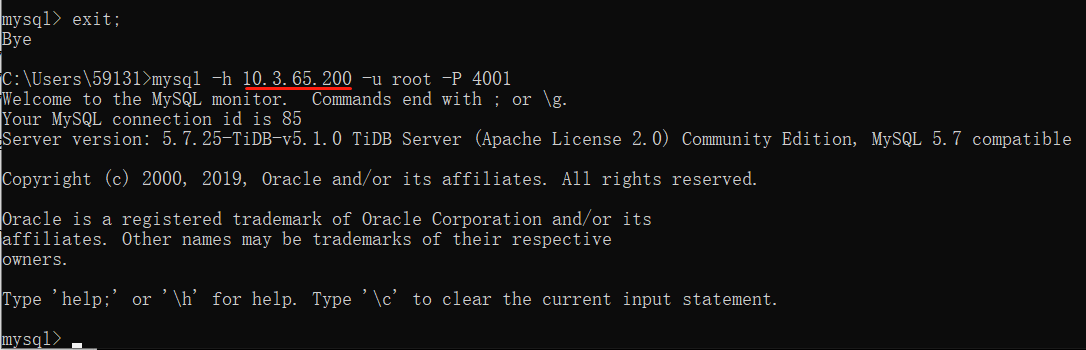
另外一点使用HAProxy的彩蛋是,Prometheus官方已经出了HAProxy的exporter,而且从HAProxy 2.0开始已经自己提供了prometheus-exporter,这意味着我们可以很方便的把对HAProxy的监控集成到TiDB的监控体系中。

限于篇幅,以后再介绍详细。
LVS
LVS支持三种工作模式,每种模式的工作原理这里不做介绍,大家去参考其他资料,每一种模式的配置方式都不同,我只列出它们之间的对比结果:
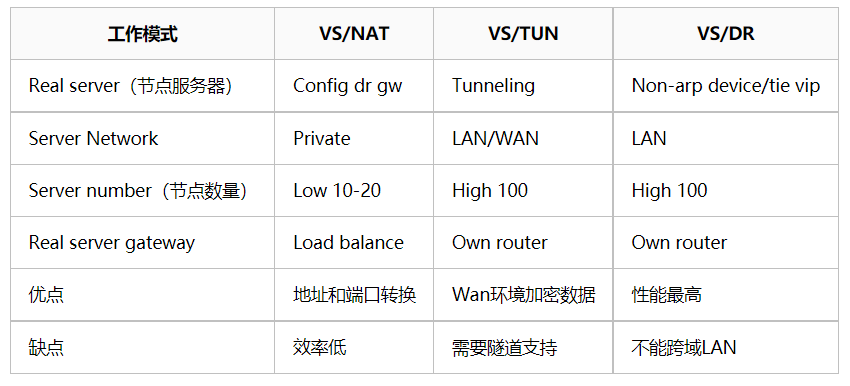
我以使用最广泛的DR模式来介绍配置过程,相比HAProxy它在网络上的配置要复杂一些。
从DR的工作原理可以得知,LVS所在的主机和它后面的真实服务主机都需要绑定同一个虚拟IP。
先配置LVS的主机,复制一份默认网卡的配置进行修改:
[root@localhost ~]# cd /etc/sysconfig/network-scripts
[root@localhost network-scripts]# cp ifcfg-eth0 ifcfg-eth0:1
[root@localhost network-scripts]# vi ifcfg-eth0:1
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
IPADDR=10.3.65.201 # 这里配置虚拟IP
NETMASK=255.255.255.0
NAME="eth0:1"
DEVICE="eth0:1"
ONBOOT="yes"
~
[root@localhost network-scripts]# systemctl restart network
接着对TiDB节点进行网卡配置:
[root@localhost ~]# cd /etc/sysconfig/network-scripts
[root@localhost network-scripts]# cp ifcfg-lo ifcfg-lo:1
[root@localhost network-scripts]# vi ifcfg-lo:1
DEVICE=lo:1
IPADDR=10.3.65.201
NETMASK=255.255.255.255
NETWORK=127.0.0.0
# If you're having problems with gated making 127.0.0.0/8 a martian,
# you can change this to something else (255.255.255.255, for example)
BROADCAST=127.255.255.255
ONBOOT=yes
NAME=loopback
~
[root@localhost network-scripts]# systemctl restart network
[root@localhost network-scripts]# vi /etc/sysctl.conf # 这里新增下面显示的几条配置
[root@localhost network-scripts]# sysctl -p
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.default.arp_ignore = 1
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
[root@localhost network-scripts]# route add -host 10.3.65.201 dev lo:1
Linux内核从2.4版本开始就已经集成了LVS,所以我们不用单独安装了,这里只需要安装它的管理工ipvsadmin。
[root@localhost ~]# yum install ipvsadm
[root@localhost ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
通过ipvsadm添加LVS节点信息:
[root@localhost ~]# ipvsadm -A -t 10.3.65.201:4000 -s wrr -p 5 #这里添加虚拟IP,使用加权轮询策略
然后把TiDB节点也添加进去:
[root@localhost network-scripts]# ipvsadm -a -t 10.3.65.201:4000 -r 10.3.65.126:4000 -g
这里的-t参数指定LVS节点虚拟IP,-r参数指定后面的真实服务节点也就是TiDB的访问端口,如果有多个TiDB节点就每个都加入。
准备就绪以后,我们把当前的信息保存到LVS配置文件中,然后启动服务即可:
[root@localhost network-scripts]# ipvsadm --save > /etc/sysconfig/ipvsadm
[root@localhost network-scripts]# cat /etc/sysconfig/ipvsadm
-A -t 10.3.65.201:4000 -s wrr
-a -t 10.3.65.201:4000 -r 10.3.65.126:4000 -g -w 1
[root@localhost network-scripts]# systemctl start ipvsadm
启动以后通过虚拟IP来登录到TiDB中,发现登录成功:
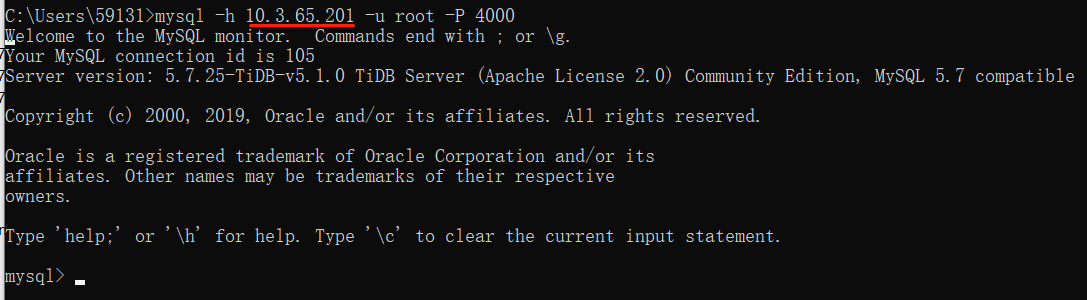
LVS的高可用方案与前面提到的HAProxy类似,都是使用keepalived来实现,为了避免大量重复内容,这里只给出Master的关键配置:
! Configuration File for keepalived
global_defs {
router_id kad_01 #节点标识,要全局唯一
}
vrrp_instance tidb_ha {
state MASTER #节点角色
interface eth0 #这里设置成自己的网卡名字,标识绑定到哪个网卡
virtual_router_id 51 #虚拟路由id,同一组主备节点要相同
priority 100 #优先级,要确保master的优先级比backup的高
advert_int 1 #主备之间检查频率为1秒
authentication {
auth_type PASS
auth_pass tidb666 #主备之间的认证密码
}
virtual_ipaddress {
10.3.65.201 #设置绑定的虚拟IP
}
virtual_server 10.3.65.201 4000 {
delay_loop 6 #服务轮询的时间间隔
lb_algo wrr #加权轮询调度,调度算法有 rr|wrr|lc|wlc|lblc|sh|sh
lb_kind DR #LVS工作模式 NAT|DR|TUN
persistence_timeout 50 #会话保持时间
protocol TCP #健康检查协议
# 真实的后台服务,这里配TiDB访问信息,每个TiDB节点配置一个real_server
real_server 10.3.65.126 4000 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
connect_port 4000
}
}
}
}
Backup节点配置参考前面的修改即可,更多详细配置可以去网上搜索。
Weir
网上关于Weir的信息并不多,有用的资料都来自Github主页的文档,Weir的架构和原理可以参考这篇文章:https://asktug.com/t/topic/93717,这里只总结一下如何去快速使用。
首先从Github拉取源码编译安装:
[root@localhost ~]# git clone https://github.com/tidb-incubator/weir
[root@localhost ~]# cd weir
[root@localhost ~]# make weirproxy
它涉及到两个配置文件,一个和proxy相关(weir默认端口是6000),一个和namespace相关,都在conf目录下。简单起见,proxy的配置我不做任何修改都用默认值,只改一下namespace配置里和TiDB有关的参数:
[root@localhost weir]# vi conf/namespace/test_namespace.yaml
version: "v1"
namespace: "test_namespace"
frontend:
allowed_dbs:
- "test"
slow_sql_time: 50
sql_blacklist:
denied_ips:
idle_timeout: 3600
users:
- username: "weir"
password: "111111"
backend:
instances:
- "10.3.65.126:4000"
username: "root"
password: ""
selector_type: "random"
pool_size: 10
idle_timeout: 60
~
详细的配置参数可以参考官方文档。
修改好配置后运行启动文件:
[root@localhost weir]# ./bin/weirproxy &
通过Weir暴露的入口登录到TiDB,发现登录成功:
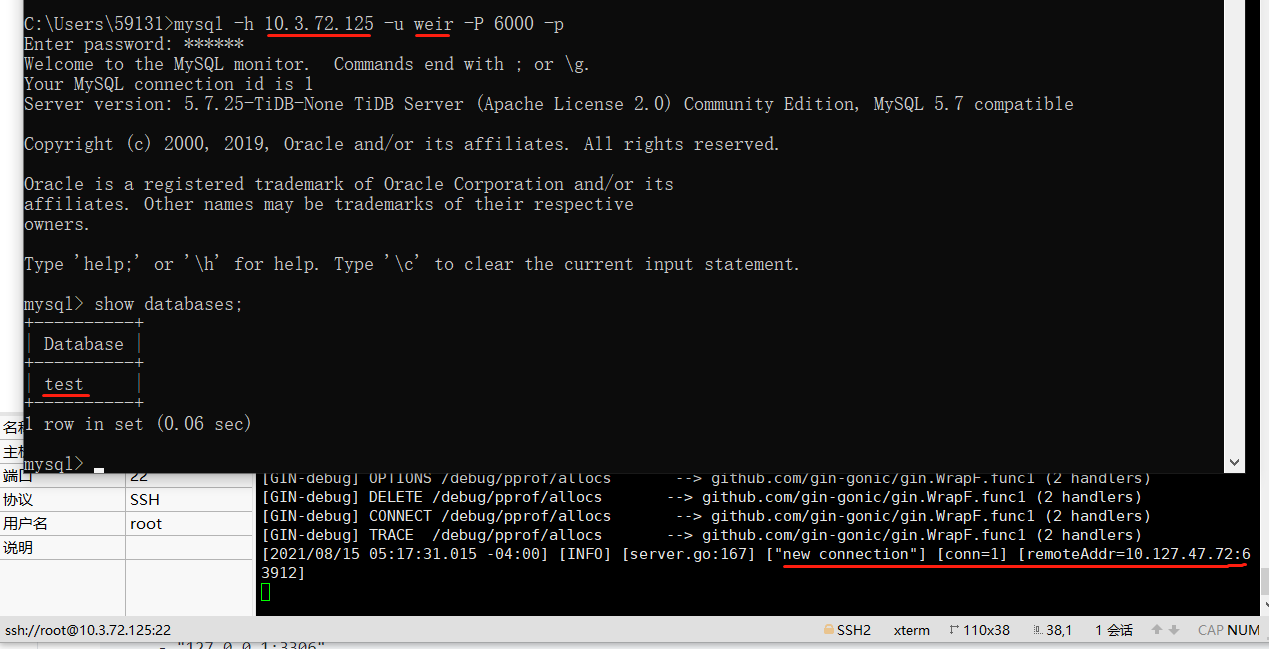
这里要注意的是,MySQL客户端登录时使用的账号密码是namespace中设置的信息,不再是TiDB原本的账号密码。
Weir的高可用方案官方介绍的不多,没有提供原生的高可用支持。从某个角度来看,Weir更像是TiDB SQL层的一个HTTP扩展,所以也是无状态服务,如果部署多个Weir来做集群的话,那么它的上层就需要引入像Nginx或HAProxy这样的负载均衡组件,问题好像一下子回到最开始了。
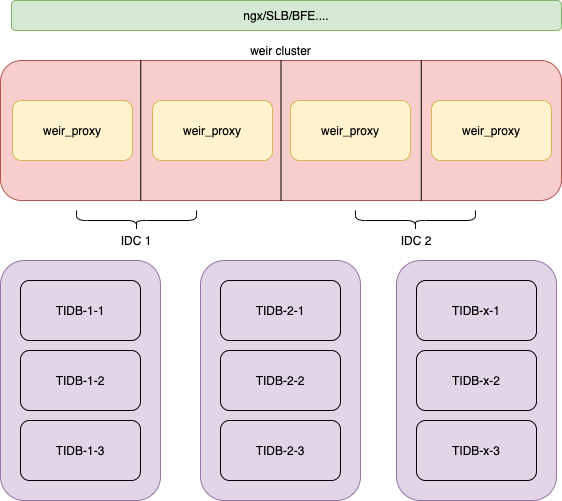
与前面两种方案相比,Weir实施起来稍微有点重,不过它胜在支持前面两种没有的功能,这就需要大家根据实际情况取舍,还是希望Weir会越做越好。
总结
总体来说,本文介绍的内容都偏TiDB外侧的东西,看似关系不大但是又很重要,一旦用了TiDB就不得不考虑负载均衡的问题,希望本文能给大家带来一些帮助。