

一. Coprocessor 简介
在 TiDB整体架构中,数据是存在 TiKV 里的,当 TiDB 在收到一个来自客户端的查询请求时,会向 TiKV 获取具体的数据信息。
那么一个读请求的流程如下:
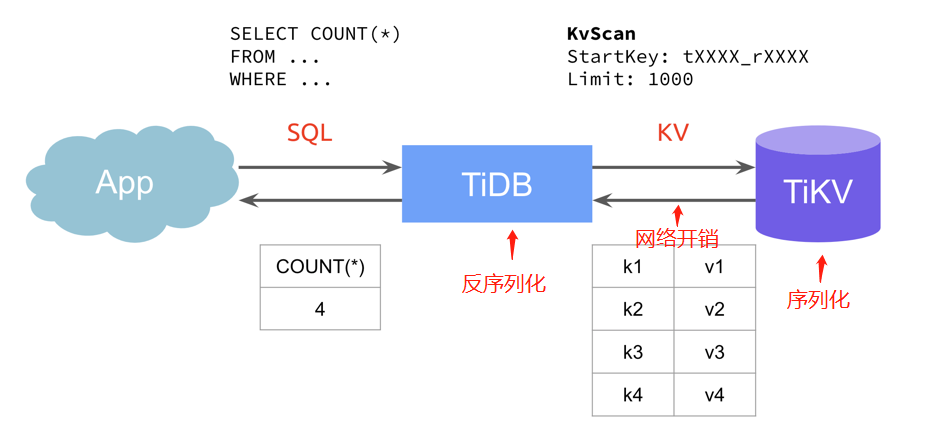
这种流程模式下主要有两个问题:
- TiDB 负责计算所有数据,导致 CPU 负载很大,而 TiKV 负载不大;
- TiKV 会返回所有数据,网络开销大;
- 数据传输会先序列化,计算前再做反序列化,数据量大的场景下资源消耗大;
为了优化以上的问题,可以让 TiKV 去承担计算任务,处理完成后再返回给 TiDB。
Coprocessor 就是 TiKV 中读取数据并计算的模块,它的实现类似于 HBase 中的 Coprocessor 的 Endpoint 部分,也可以类比 MySQL 的存储过程。
二. 语句处理
看下读请求是如何下发到 TiKV 的:
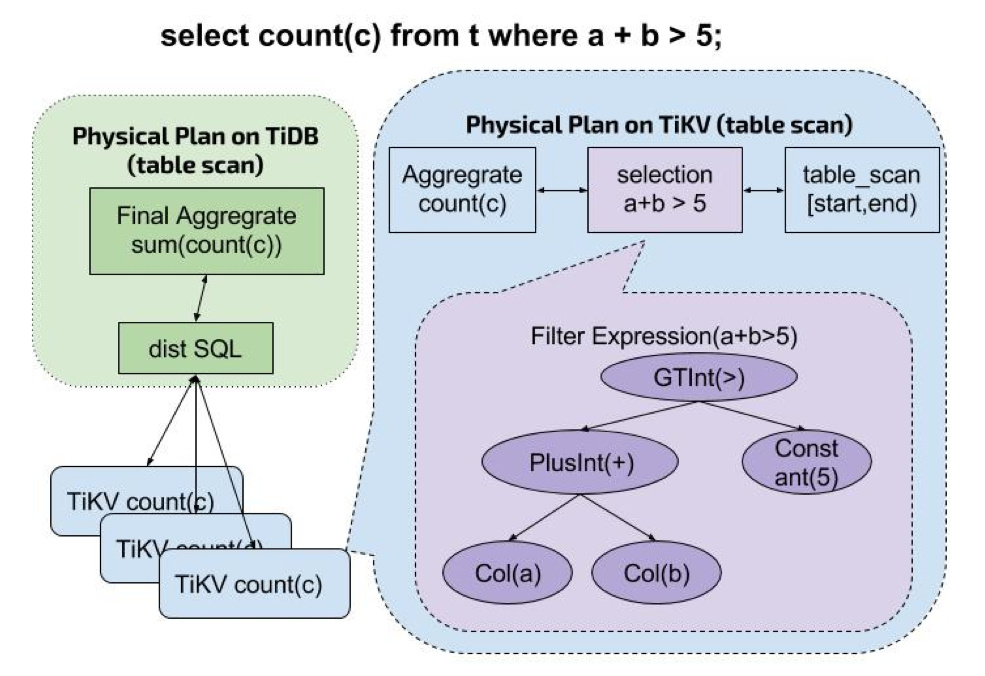
- TiDB 收到查询语句,对语句进行分析,计算出物理执行计划,组织称 TiKV 的 Coprocessor 请求。
- TiDB 将该 Coprocessor 请求根据数据的分布,分发到所有相关的 TiKV 上。
- TiKV 在收到该 Coprocessor 请求后,根据请求算子对数据进行过滤聚合,然后返回给 TiDB。
- TiDB 在收到所有数据的返回结果后,进行二次聚合,并将最终结果计算出来,返回给客户端。
1. 火山模型
一条读请求,使用 Table Scan 算子,需要扫出所有行的需求列,性能不高。3.0 之前使用的是火山模型去让请求只需要扫几行。
SELECT * FROM table WHERE age > 10 limit 1
Limit
每次都从下层算子取一行,至多取 LIMIT 行,返回给上层
Selection
不断从下层算子取一行,按照 age > 10 为过滤条件,知道有一条满足条件了返回给上层
Table Scan
扫下一行的 age 列 返回给上层
优缺点
-
优点:
- 扫的数最少,内存开销少
-
缺点:
- 每次只能处理一行数据,非扫表的算子性能比较低
2. 向量化模型(3.0之后)
- 算子之间每次都接受多行、处理多行、返回多行;
- 函数表达式按列计算
- 聚合表达式按列计算
所谓的向量化,就是在 Executor 间传递的不再是单单的一行,而是多行,比如 TableScan 在底层 MVCC Snapshot 中扫上来的不再是一行,而是说多行。在算子执行计算任务的时候,计算的单元也不再是一个标量,而是一个向量。举个例子,当遇到一个表达式:a + b 的时候, 我们不是计算一行里边 a 列和 b 列两个标量相加的结果,而是计算 a 列和 b 列两列相加的结果。
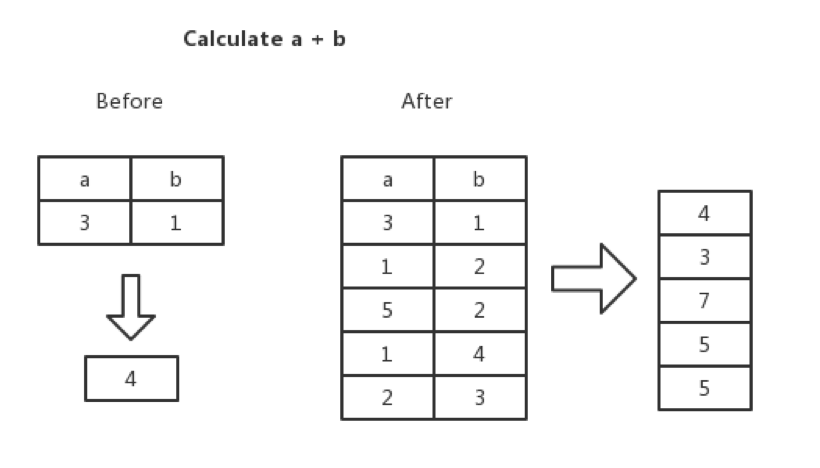
TableScan
根据指定主键范围扫表数据,并过滤出一部分列返回。它只会作为最底层算子出现,从底层 KV 获取数据。
select col from t
IndexScan
根据指定索引返回扫索引数据,并过滤出一部分索引列返回。它只会作为最底层算子出现,从底层 KV 获取数据。
select index from t
Selection
对底层算子的结果按照过滤条件进行过滤,其中这些条件由多个表达式组成。
select col from t where a+b=10

Limit
从底层算子吐出的数据中,限定返回若干行。
select col from t limit 10

TopN
按照给定表达式进行排序后,取出前若干行数据。
select col from t order by a+1 limit 10

Aggregation
按照给定表达式进行分组、聚合。
select count(1) from t group by score + 1

混用算子
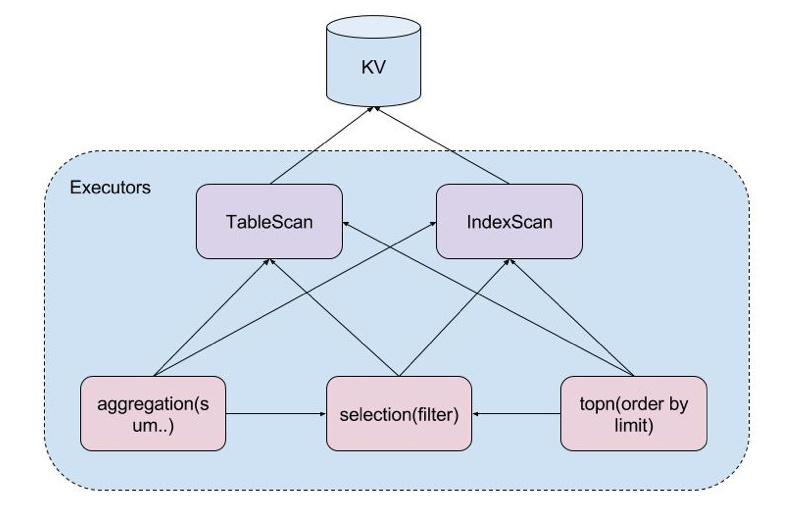
select count(1) from t where age>10

三. Coprocessor 部分知识点
- Coprocessor 只能加速查询类请求,不能用于支撑写入的需求。也就是说 TiKV 是必须要的,不能只使用 Coprocessor 接口;
- TiDB 上几乎的查询请求都是通过 Coprocessor 完成的。对于极少数的场景,比如点查,TiDB 会直接调用点查接口(Kv get),避免走到 Coprocessor 庞大的框架下执行,从而提升了性能;
- 除了 select 其他 DML 操作也可以走 Coprocessor;
- TiKV 只能算出中间结果,需要 TiDB 去做汇集并计算最终结果。比如排序取前10的需求,需要每个 TiKV 取前10,然后 TiDB 去汇总再排序,才能取到需要的值;
- TiKV 的算子执行逻辑和 TiDB 的逻辑是不一样的。比如请求是 AVG(),TiKV 返回的是 sum 或者 count,AVG() 是在 TiDB 里实现的;
四. Coprocessor cache
最新 v5.0.0 版本的 release notes 中写到,5.0 GA 默认开启 Coprocessor cache 功能。
开启该功能后,TiDB 会在 tidb-server 中缓存算子下推到 tikv-server 计算后的结果,降低读取数据的延时。
要关闭 Coprocessor cache 功能,可以修改 tikv-client.copr-cache 的 capacity-mb 配置项为 0.0。
-
capacity-mb
- 缓存的总数据量大小。当缓存空间满时,旧缓存条目将被逐出。值为 0.0 时表示关闭 Coprocessor Cache。
- 默认值:1000.0
- 单位:MB
- 类型:Float
参考资料:
 MySQL at Scale. No more manual sharding
MySQL at Scale. No more manual sharding

TiKV 源码解析系列文章(十四)Coprocessor 概览 | PingCAP
本文将简要介绍 TiKV Coprocessor 的基本原理,面向想要了解 TiKV 数据读取执行过程的同学,同时也面向想对该模块贡献代码的同学。
MySQL at Scale. No more manual sharding
TiKV 源码解析系列文章(十六)TiKV Coprocessor Executor 源码解析 | PingCAP
本文将介绍下推算子的执行流程并分析下推算子的部分实现细节,加深大家对 TiKV Coprocessor 的理解。