

现象
最近把TiDB Operator升级到v1.1.0后,打算把tidbcluster也升级到较高版本。按照常规操作准备了镜像,执行 kubectl edit命令后开始观察集群升级状态:
watch kubectl -n ${namespace} get pod -o wide
结果发现某个pd的pod已经处于反复重启状态,于是开始排查。
排查
因为之前在K8S上遇到过类似pd集群不正常的问题,所以沿用以前思路首先查看pd集群的API是否正常:
wget -c http://tidb-cluster-prod-pd.tidb-cluster-prod:2379/pd/api/v1/members
使用ClusterIP访问以确认底层网络是否正常:
wget -c http://${ClusterIP}:2379/pd/api/v1/members
结果是pd集群的API可以正常访问。
查看集群tidbcluster CR的yaml和pd的StatefulSet的yaml没有发现问题。
于是查看相应pod的日志:
kubect logs -f ${clustername}-pd-2
日志如下:
2020/06/16 11:03:04.329 log.go:86: [warning] etcdserver: [could not get cluster response from http://${clustername}-pd-4.${clustername}-pd-peer.${clustername}.svc:2380: Get http://${clustername}-pd-4.${clustername}-pd-peer.${clustername}.svc:2380/members: dial tcp: lookup ${clustername}-pd-4.${clustername}-pd-peer.tidbcluster->wuhanwuli.svc on ${ip}:53: no such host]
实际上集群中有pd-0到pd-3这4个pod,pd-4不在集群里:
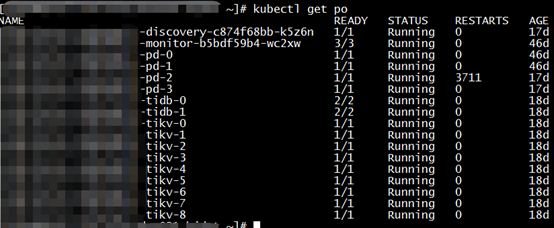
继续查看pd-2日志可见pd-2已经从集群下线:
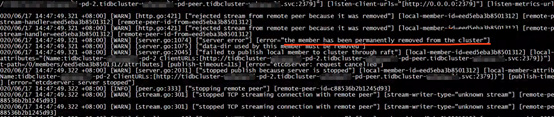
但是pd-2所在的pod仍然在运行。
查看和pd-2相关的PV:

查看为Released状态的PV存储内容:
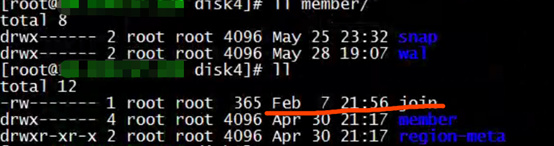
查看为Bound状态的PV存储内容:
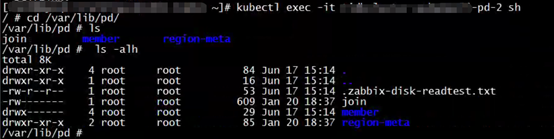
发现为Bound状态的PV文件创建时间比为Released状态的PV文件创建时间还早。老的PV里面的join文件的创建时间大概是2月7日,而新PV里面的 join文件的创建时间大概是1月20日,比老join文件还旧。
于是总结合理的时间序列如下:
- pd-2发生了failover之后,TiDB-Operator将这个member从集群中删掉了,并且删掉了pvc和pd-2的pod
- pd-2之前使用的PV被释放,成为Released状态
- pd-2新pod和pvc创建,绑定了新的PV,状态为Bound
- 由于这个新绑定的PV里面有老数据,导致pd-2这个节点无法启动
查看local-volume-provisioner目前用的版本仍然是v2.3.2,从PingCAP小伙伴那里已经收到了存在bug的提醒,从TiDB DevCon 2020也看到了相关分享,对应bug说明如下:
github.com/kubernetes-sigs/sig-storage-local-static-provisioner
Remove old cleanup status before create new pv
by yuyulei on 01:29PM - 18 Feb 20 UTC
1 commits changed 1 files with 7 additions and 0 deletions.
这个bug会导致PV对象重建了,但是里面的数据未清理。还没有来得及升级local-volume-provisioner就碰到了这个坑。
恢复方法
可以将pd-2现在使用的PV里面的数据删除,让/var/lib/pd目录为空,这样pd-2就会作为一个新的member启动,重新加入到整个pd集群。
kubectl get pv | grep pd-2
找到对应的Local PV:
kubectl get pv local-pv-xxxx -oyaml
从以上输出中找到对应目录删除所有内容,然后观察所有pod状态。
watch kubectl get po -n ${namespace}
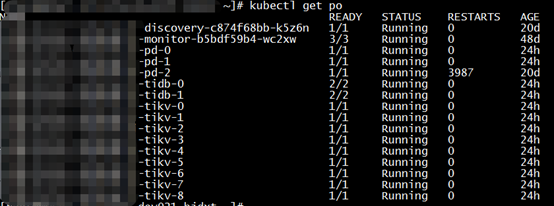
可以看到pd全部重启并恢复Running状态,然后其它组件也相继升级成功:
隐患排查和解决
- 排查所有目前状态为Available的PV,确认目录为空
kubectl get pv | grep Available | grep local-storage-pd | awk '{print $1}' | xargs kubectl get pv -oyaml | egrep 'kubernetes.io/hostname|path
找到所有目录逐一排查。
备注:本环境中pd的storageclass为local-storage-pd - local-volume-provisioner升级到2.3.4:
docker pull quay.io/external_storage/local-volume-provisioner:v2.3.4
docker tag quay.io/external_storage/local-volume-provisioner:v2.3.4 ${registry address}/tidb/local-volume-provisioner:2.3.4
docker push ${registry address}/tidb/local-volume-provisioner:2.3.4
编辑local-volume-provisioner:
kubectl edit ds local-volume-provisioner -oyaml -n kube-system
修改spec.template.spec.image保存后观察升级情况:
watch kubectl get po -l app=local-volume-provisioner -n kube-system
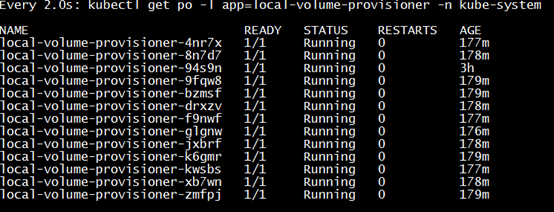
可见local-volume-provisioner已经升级成功。
后记
截止目前,K8S上的TiDB集群已正常运行两周,没有再发现问题。
同时感谢PingCAP小伙伴的大力支持!