

【是否原创】是
【首发渠道】TiDB 社区,转载请注明出处
背景介绍
传统行业在本文中是指在国内有一定体量,较为基础的一些行业企业,此类企业有几个特征:
- 企业体量较大
- 业务变化不大
- 客户群体大
- 客户数量变化不大
此类行业近几年随着数据中台、人工智能、数字孪生等等概念的不断洗刷,也因为本身业务发展的实际需要,数据体量连年增长。
随着国内开源软件生态逐步成熟,面向传统行业的软件企业交付的数据架构,也以开源软件为主构建,逐步的发展变化。本文主要介绍在开源的背景下,传统行业数据架构近几年的发展变化,以及每一步的掣肘和突破,作者总结下来感觉有一定的代表性,希望分享出来能够提供一些思路。
数据架构的发展变化
作者所经历的数据架构分三个阶段:单一数据库集群、TP和AP分离、大数据的引入,现在正在经历HTAP+云原生这一阶段。
单一数据库集群
作者所经历的单一数据库集群阶段,大约是在18年开始的,现在也会在项目开始阶段较多的采用。架构图如下:
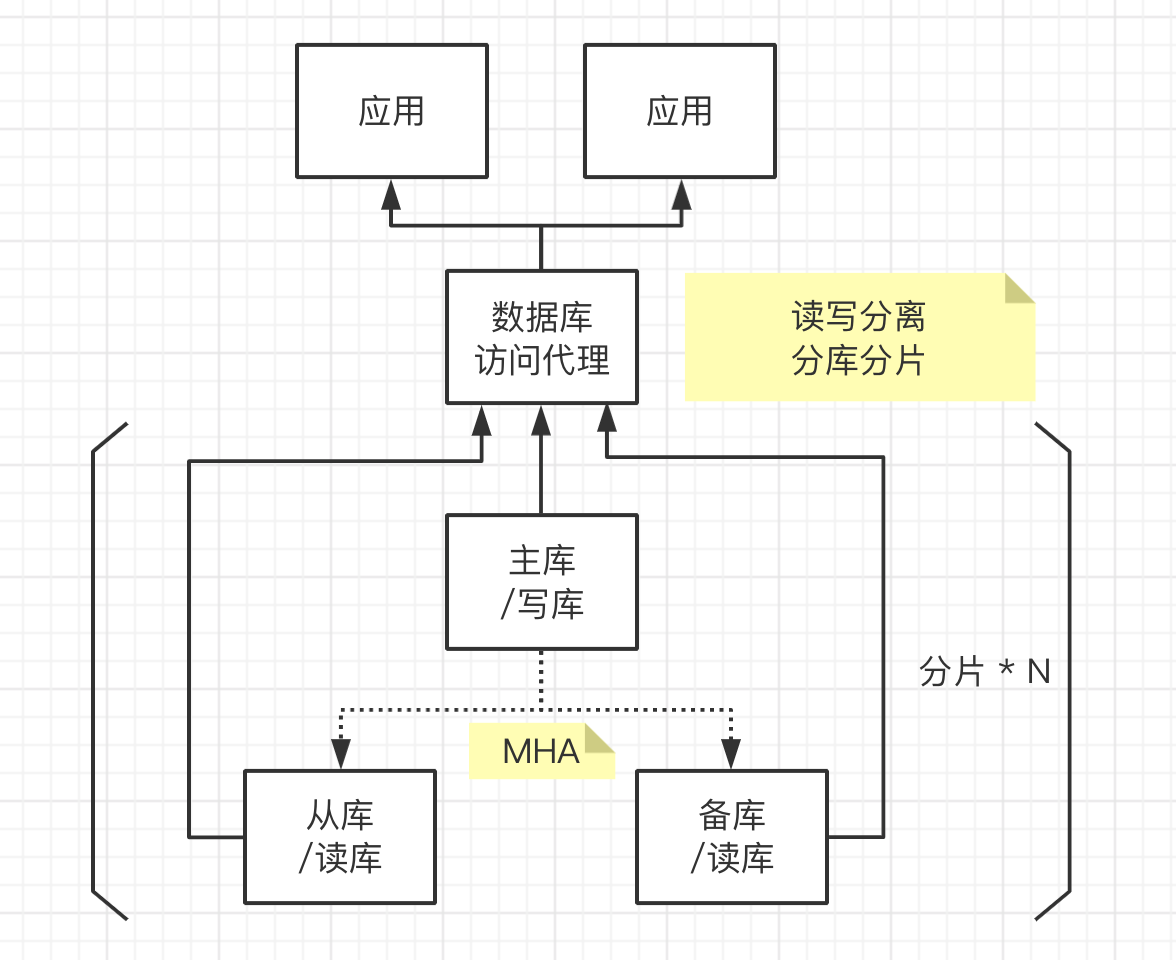
单一数据库并不是指就一个数据库实例,而且整个架构的主体采用了一个数据库产品,例如架构图中是以Mysql官方分发版本为主体,通过MHA方案,搭建的高可用Mysql集群,为了应对数据的增长,中间加了一个数据库访问代理,我们采用的是mycat,分库分表、读写分离都通过mycat做出来。
此架构模式下,数据量增长的一定规模之后,出现了一些问题:
- 跨分片访问性能不佳
- 汇总性能不佳、宽表支持较差
- 分析类需求支持不好,与实时业务争抢CPU和IO
这些原因搞过数据架构的都会很容易总结出来,归根结底,是过多的把AP的需求让Mysql来解决了。
TP和AP分离
基于项目越来越多的离线汇总需求和在线分析需求,整个项目引入了AP类型的数据库。由于开源的GreenPlum在国内的火热,企业内部多采用了GreenPlum数据库,有较多的技术积累。
集成了GP的数据架构如下:
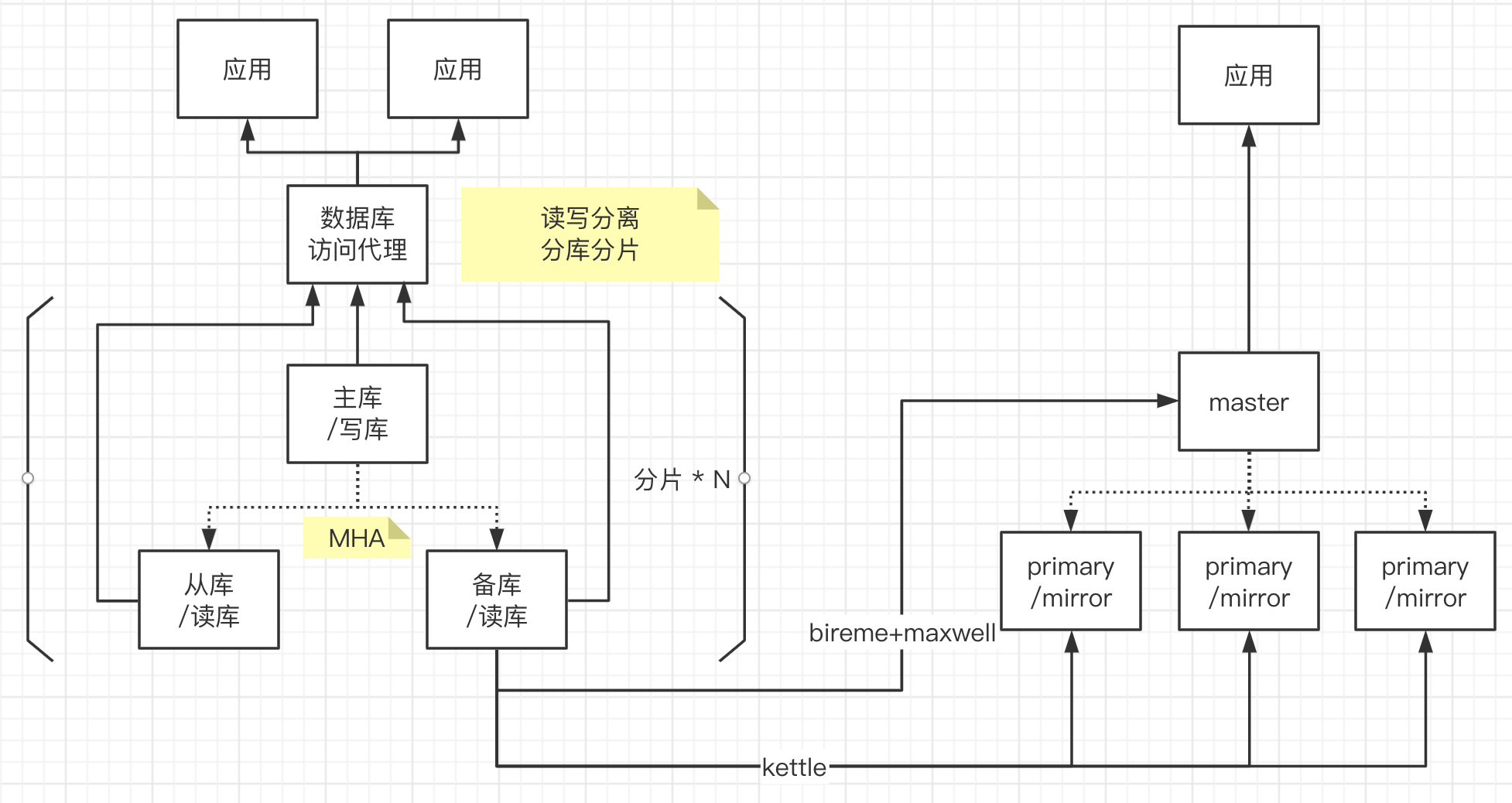
参考:bireme
我们从Mysql到Greenplum构建了两个通道,一个通道是通过kettle构建ETL任务批量抽取数据到Greenplum,一个通道是通过bireme+maxwell实时同步数据到Greenplum。从架构图上可以看到,kettle写入数据,实际上是与Greenplum的Segment(primary)节点打交道,效率比较高;bireme+maxwell是通过master写入Greenplum集群的,效率不高,特别是一些更新较频繁的表,大量占用IO。
kettle支撑了我们很久,bireme+maxwell由于IO问题没有彻底解决也就放弃了这条路线。20年Greenplum官方出了streaming-server组件,这个环节的问题得到了很好的解决,但那个时候我们换了方案,也就没在实际生产中使用。
随着数据量的增长,我们面对几个棘手的问题,始终解决的不好,引起了客户大量的投诉:
- 随着业务发展和数据量增长,ETL过程越来越长,ETL的窗口越来越短,抽数与正常业务逐渐的交叠在一起
- 因为Greenplum当时的几个BUG,ETL之后的汇总任务不太稳定,汇总失败之后的重算,又占用白天的查询IO,AP业务基本不可用
基于以上原因,考虑从两个方面解决问题:
- 放弃ETL,改用binlog同步
- 引入专业离线计算工具
综合考虑当时的情况,决定引入Hadoop,采用HDP分发版本,结合HDF的一些思路,构建一个准实时的数据平台。
大数据的引入
引入Hadoop后,架构如下:
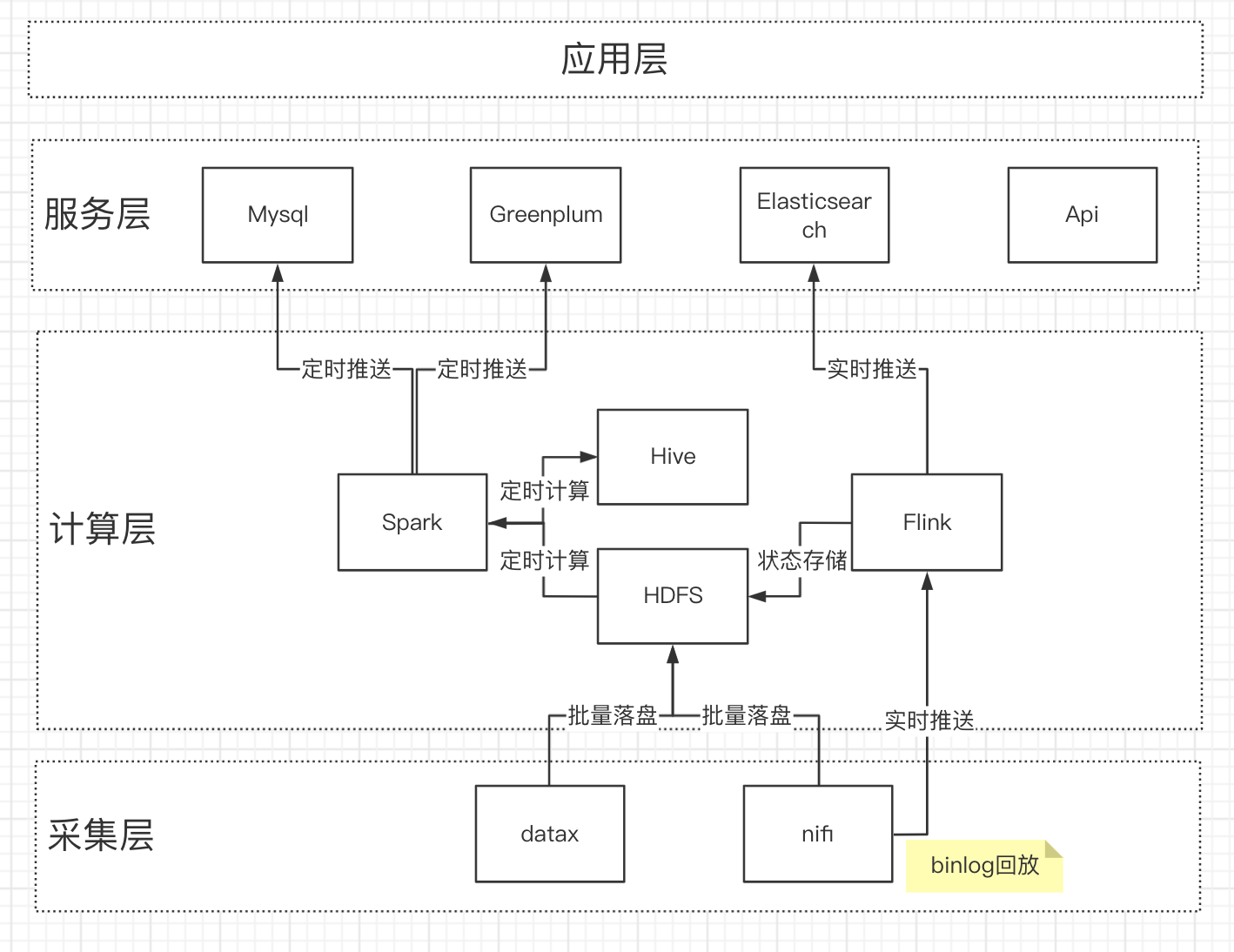
HDP、HDF已成为过去,不再提供连接供参考。
数据经过NIFI,采用binlog回放的方式,实时写入Hbase,定时启动Spark任务,进行汇总计算,计算结果输出到GreenPlum中。
整体数据架构的职责划分如下:
| 技术组件 | 服务能力 | 存储期限 |
|---|---|---|
| Mysql(集群) | 交易(核心) | 1个月 |
| Hadoop | 离线计算、明细查询 | 全部 |
| Greenplum | 在线分析 | 半年 |
此架构的优势是:
- 采用binlog回放,不存在ETL过程,对业务库影响最小
- 采用Spark进行汇总计算,计算性能、稳定性都有大幅度的提升
- 汇总计算和在线分析物理隔离,重算、验算、模型计算等任务使用Hadoop集群,不影响在线分析业务的稳定性
- 对于需要实时的业务,采用Flink+Elasticsearch的方式满足。
但同时这一套架构也有其局限性:
- Mysql的ddl变更,扩缩容非常繁琐,需要寻找停机时间,也牵扯到大量人工操作
- 数据链路过长,实时业务需求存在开发门槛,不能提供实时AP业务支撑
- 部分业务计算完成后,需要回写Mysql,效率很差,调优空间很小
- 资源需求起点高,部署组件多,运维难度大,运维人员要求高
本身团队人员少,仅仅维护一个集群尚能保证可用性,产品复制推广后,运维和本地开发存在极大的困难。
HTAP+云原生
在Hadoop引入过程中也在不断尝试简化整个架构。先后研究过cockroachlabs、yugabyte、citusdb等多款分布式数据库。也阅读过很多TiDB的技术文章,参考:HTAP 会成为数据库的未来吗?。
经过对比,我们认为TiDB比较适合我们:
- 使用Mysql协议,兼容Mysql 5.7,迁移成本很小
- 所有的HTAP数据库中,对接Spark是最好的
- 中文资料详实、国内支持较好
OceanBase因开源时间较晚,开源时生态并不丰富,对多租户的模式需求不高等多种原因没有深入进行相关测试。
引入TiDB之后的架构:
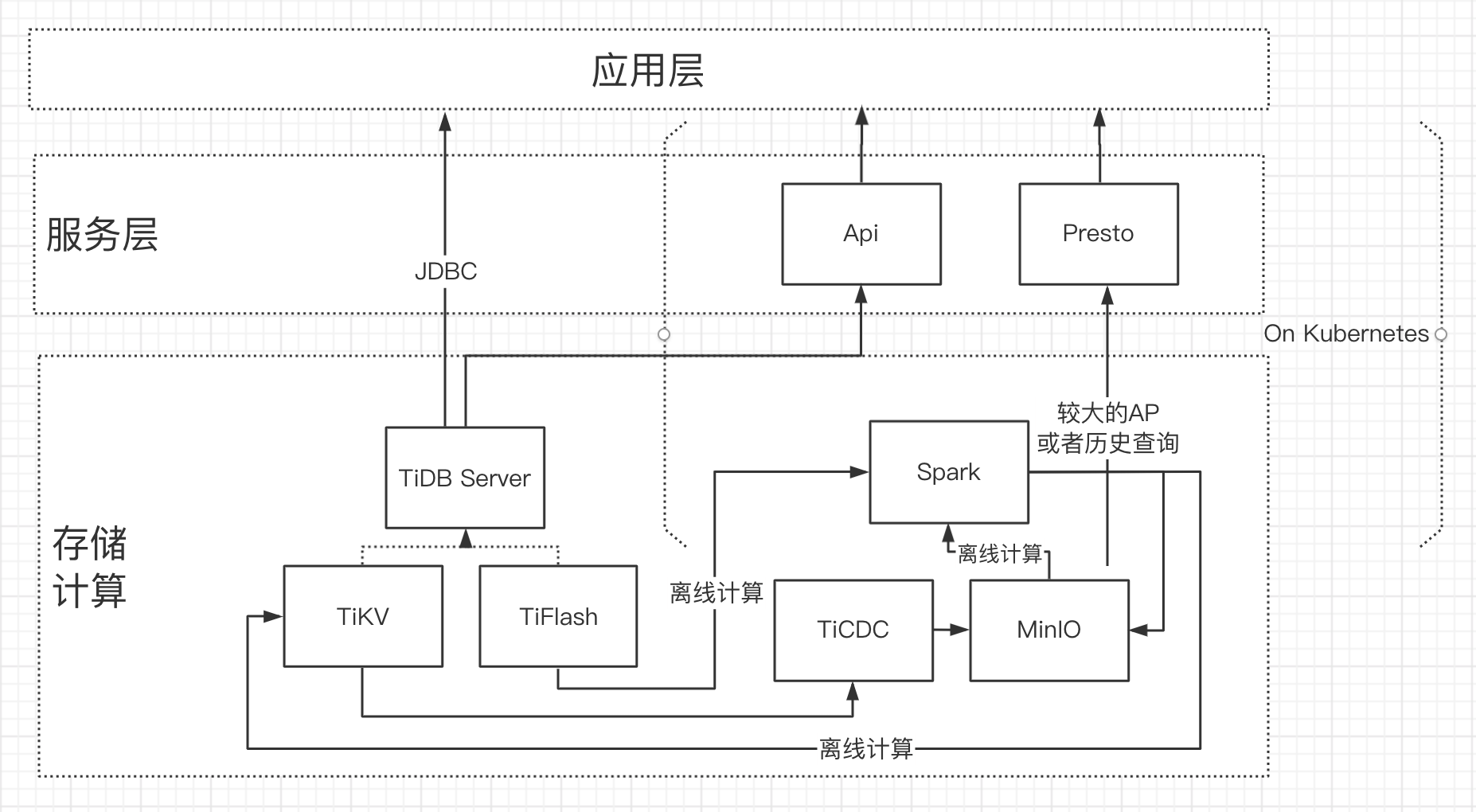
其中:
- 整个架构以TiDB为核心,不再关注分片、无法执行ddl变更、离线扩缩容等等一系列问题
- 轻度的AP工作,不需要额外的ETL动作,扩展TiFlash副本就可以
- Spark上我们做了大量的离线计算的封装,TiSpark的回写效率不错,我们做了一些适配工作,降低了离线计算这一块的改造难度
- Spark、Api、Presto等我们都跑在了k8s上,极大的降低了计算资源的管理与运维难度
- 从架构上去掉了Flink,是因为Flink原来进行的计算在TiDB能够通过实时的查询解决
其中最关键的我认为是TiSpark,Spark在离线计算领域的效率、稳定性不可替代。
我们仍然在路上
HTAP+云原生我们仍然在改造过程中,或许有一些认知错误,但HTAP+云原生这条路给我们的开发、运维都极大地减轻了工作量,我们会不断走下去。