

最近看上了积分兑换里面的衣服,奈何积分不够,搬运整理几篇文章攒积分。
【版本】 v4.0.11
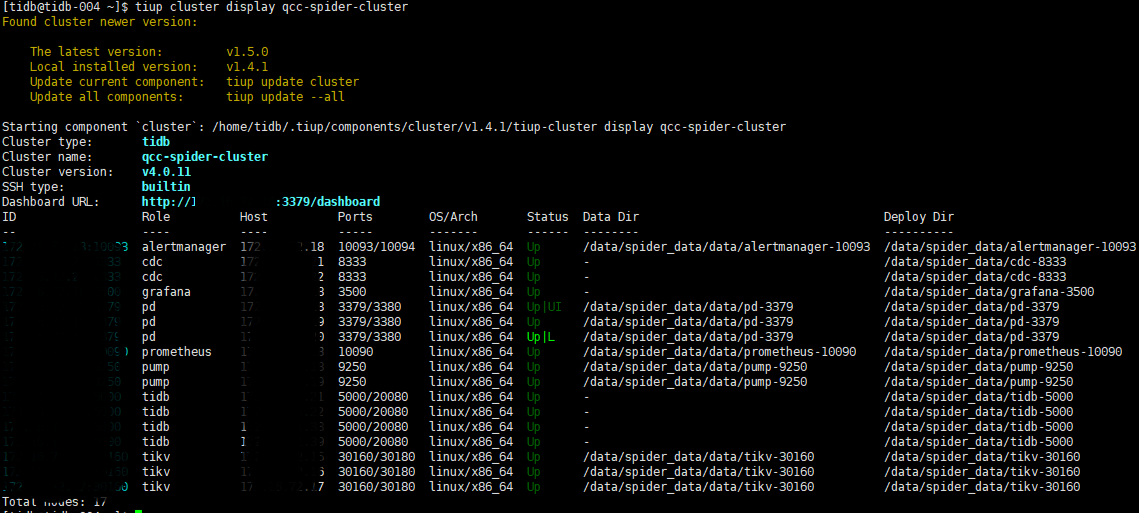
【集群信息】2 TiDB 3 PD 3 TiKV
集群组件:
一、【现象】
Scheduler 线程 CPU 使用率倾斜严重。
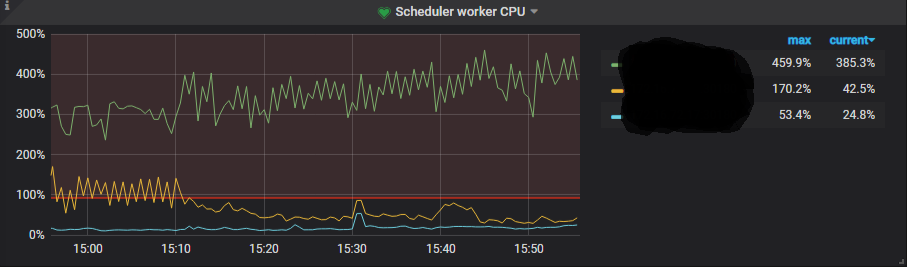
Scheduler 线程池有什么用?
scheduler 负责检测事务冲突,将复杂的事务操作转换为简单的 key-value 插入、删除,发送给 raftstore 线程。但是 scheduler 线程池本身不进行任何写操作 。
Scheduler 线程池相关配置参数?
storage.scheduler-worker-pool-size: 8
storage.scheduler-concurrency: 2048000
storage.scheduler-worker-pool-size在 TiKV 检测到机器 CPU 核数大于等于 16 时默认为 8,小于 16 时默认为 4。我这配置的是8。
二、【问题排查】
1、监控 PD-Statistics-hot read
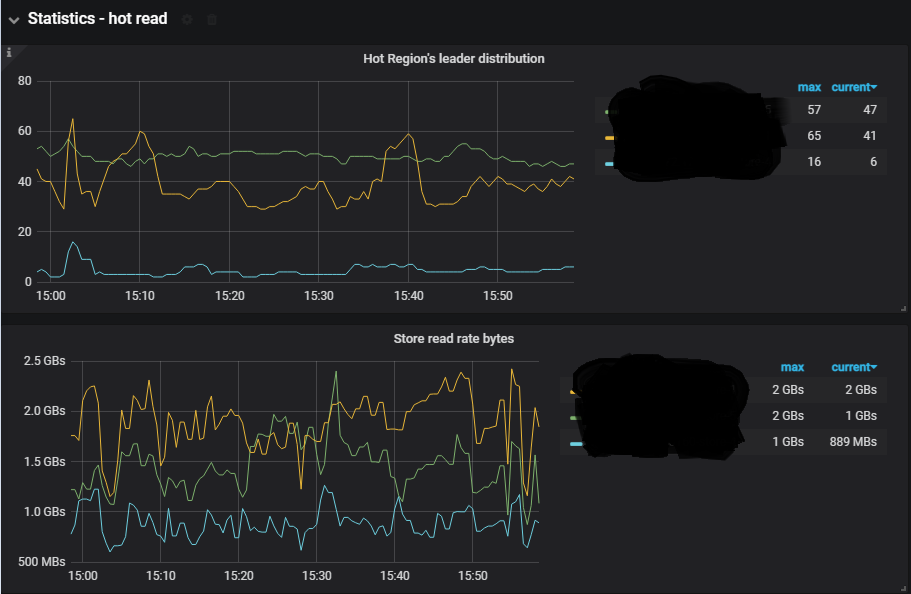
通过监控可以看到热点 region 都集中在了2个节点。
2、 查找热点 region
tiup ctl pd -u http://{pdip:port} hot read > st.txt
过滤并升序输出:
grep ““flow_bytes”” st.txt | awk -F “:” ‘{print $2}’ | sort -n
396624945.6,
489116688.4166667,
499403881.4,
比如我这里使用 499403881 过滤 st.txt 查找到对应的 region id
结果示例:
{
“as_peer”: null,
“as_leader”: {
“1”: {
“total_flow_bytes”: 1245937535.8,
“total_flow_keys”: 2007998.4,
“regions_count”: 40,
“statistics”: [
{
“store_id”: 5,
“region_id”: 62132,
“hot_degree”: 110,
“anti_count”: 2,
“kind”: 1,
“flow_bytes”: 499403881.4,
“flow_keys”: 201507.55,
“last_update_time”: “2021-06-07T16:21:38.409868198+08:00”,
“version”: 1176
}
}
可以看到 store_id 为 5 ,监控上面绿色的线为 {ip:port}-store-5。是能够对应上的。
或者通过元数据表直接查找热点表:
SELECT * FROM information_schema.TIDB_HOT_REGIONS
WHERE TYPE = ‘read’
ORDER BY flow_bytes DESC;
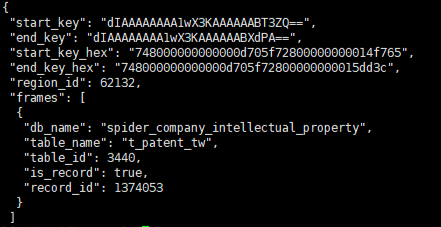
3、 通过 region id 查找热点表
curl http://{tidbip}:10080/regions/62132
4、通过慢查询日志查找对应的SQL
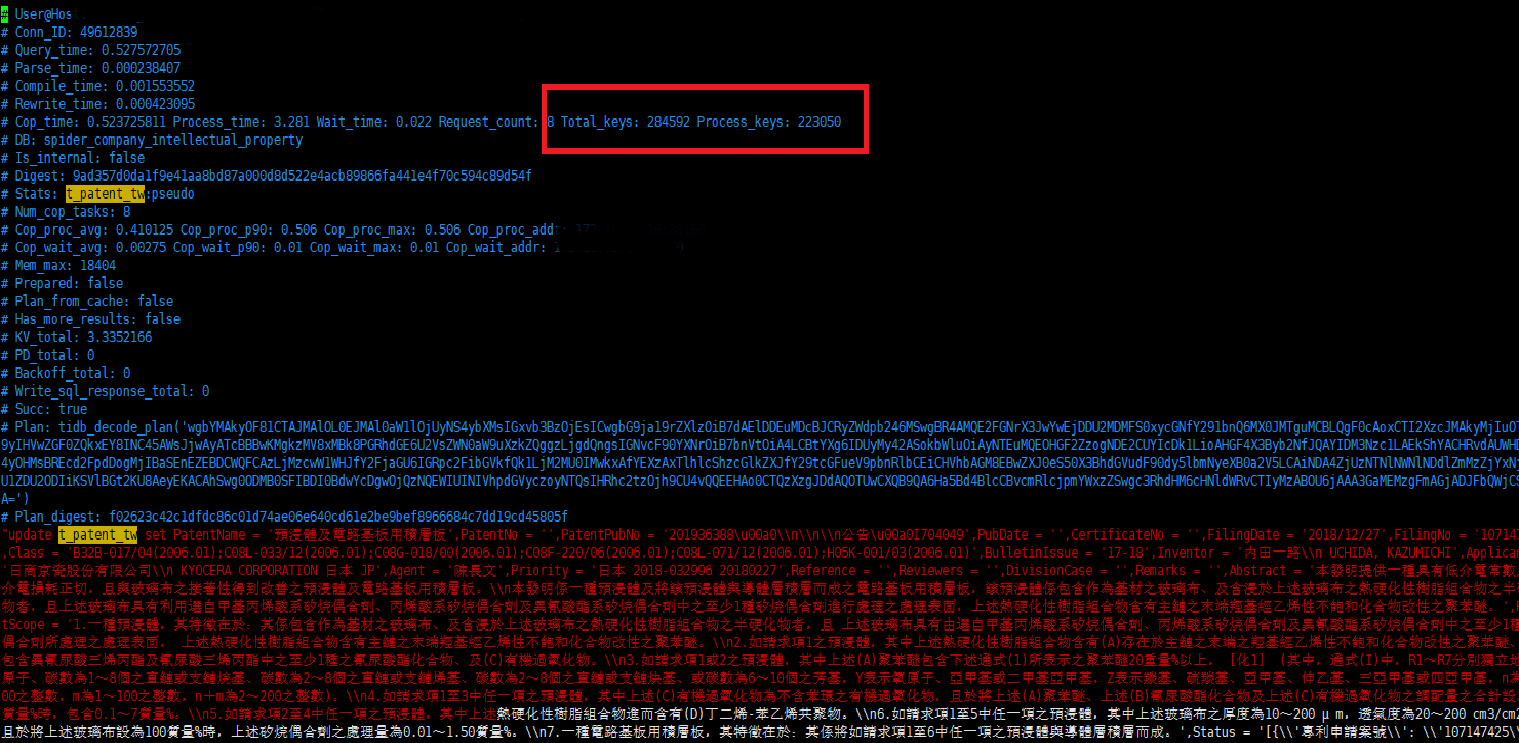
【【慢SQL优化】】
慢日志分析:
Total_keys: 286665 Process_keys: 223050
Total_keys:扫描的总keys
Process_keys:扫描当前keys(不包括旧版本)
这里有6万的旧key,因为这边的GC时长为28h,所以旧版本比较多。
通过上面的Process_keys加上更新SQL,可以分析出扫描这么多的key只有两种情况:
(1)统计信息不准 如果统计信息不准,使用analyze table 更新下。
(2)缺失索引 通过排查是第(2)种情况。
通过添加索引后观察。热点信息有所缓解。
【【热点 region 拆分】】
通过SQL继续排查其它热点表:
SELECT * FROM information_schema.TIDB_HOT_REGIONS WHERE TYPE = ‘read’ ORDER BY flow_bytes DESC;
找到热点表排查region:
SHOW TABLE t_company_gsxt_base_inc regions

t_986_r_23378649 解析:
t:表示table
986:表示table id
r:表示记录
i:表示索引
通过上面的信息可以看到有3个热点 region 。
split merge
operator add split-region 1 --policy=approximate
// 将 Region 1 对半拆分成两个 Region,基于粗略估计值,消耗更少的 I/O,可以更快地完成。
operator add split-region 1 --policy=scan
// 将 Region 1 对半拆分成两个 Region,基于精确扫描值,更加精确
这边使用第1种方式进行拆分,计划将拆分为每个region大概100000个key,所以需要设置一下参数,避免拆分后自动 merge 。
config set max-merge-region-size 10
config set max-merge-region-keys 100000
注意:拆分后需要等待一定时间让 hot leader 自动均衡。并且拆分后的 region 一定要满足以下条件之一,否则 region 会被自动 merge**
max-merge-region-size: 20 // 默认为20MB
max-merge-region-keys: 200000 // 默认为200000
Region Merge 的触发
- 如果 Region 的大小大于
max-merge-region-size(默认 20MB)或者 key 数量大于max-merge-region-keys(默认 200000)不会触发 Merge。 - 对于新 Split 的 Region 在一段时间内
split-merge-interval(默认 1h)不会触发 Merge。
另外,也可以调整 coprocessor.region-max-size 默认为96MB,调小使得 hot leader 更加分散。由于我这边生产环境目前设置的为 384MB ,导致热点 region 过于集中,后面将调整回96MB。
经过我的九九八十一次优化,热点region终于分散到了两个节点。 哈哈哈。
三、【解决方案】
根据不同的情况,选用不同的解决方案。
解决方案1:优化慢sql
解决方案2:热点 region 拆分
解决方案3:未完待续
参考:

作者:李坤,PingCAP 互联网架构师,TUG Ambassador,前美团、去哪儿数据库专家。 背景 从现有的数据库使用场景来看,随着数据规模的爆发式增长,考虑采用TiDB这种分布式存储的业务,通常都是由于触发了单机数据库的瓶颈,我认为瓶颈分为3点:存储瓶颈、写入瓶颈、读取瓶颈。我们希望TiDB能够解决这3个瓶颈,而存储瓶颈是可以首先被解决的,随着机器的扩容,存储瓶颈自然就可以几乎线性的…
 TiDB MVCC 多版本保存机制及其对性能的影响 原理解读
TiDB MVCC 多版本保存机制及其对性能的影响 原理解读
从接触TiDB以来,就看到过TiDB官方文档上的提示,gc_life_time设置过大,会因为历史版本过多,影响查询效率,但是为什么SQL非要去扫描历史版本呢?下面列举一些知识点一步一步来解析这个问题 1. TiDB key的编码方式 TiDB 会对每个表分配一个全局唯一的table_id,每一个索引都会分配一个表内唯一的 index_id,每一行分配一个 row_id(如果表有整数型的 Pri…
https://book.tidb.io/session4/chapter7/hotspot-resolved.html#721-确认热点问题