

1 月 22 日的新品分享会上,平凯数据库正式推出了基于一套内核的三种部署模式:敏捷模式、标准模式、聚能模式。
为了帮助大家进一步了解平凯数据库“三种部署模式”的区别、能力、适配场景与产品价值,特推出平凯数据库(TiDB 企业版)新品分享会核心问答。
Q1:为什么要在现在推出“三种模式”?
为了平衡数据库选型的“不可能三角”。
过去,企业在水平扩展、业务透明和极致性能之间只能做三选二。现在,通过一套内核三种模式,彻底打破了这一制约。无论您是初创起步还是超大规模核心场景,都能在同一个技术体系内找到最优解,无需再做艰难取舍。

Q2:这三种模式是三个独立的产品吗?
不是。它们是一套内核的三个形态。
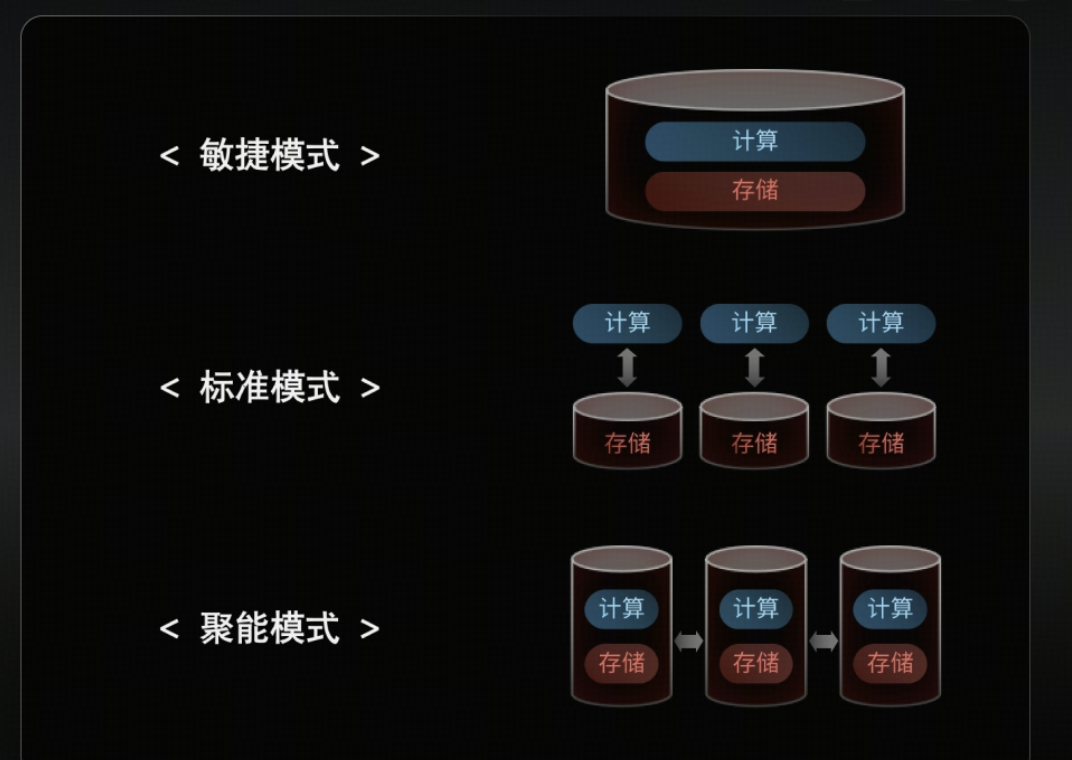
Q3:为什么一套内核能变出三种模式?原理是什么?
核心机制是“数据分布的自适应”。
聚:在资源受限或追求极致低延迟时,通过亲和性调度让计算与存储“聚合”(如敏捷模式、聚能模式),获得单机般的性能体验。
散:在规模扩张时,数据自然“分散”(如标准模式),发挥原生分布式的无限扩展能力。 这种随业务变化而动态调整的能力,是平凯数据库的核心护城河。

Q4:三种模式具体有什么区别?我该如何选择?
可以根据您的数据规模与业务需求,对照三种模式的定位、适用场景、适用数据量、部署规模与性能指标 进行选择:
| 敏捷模式 | 标准模式 | 聚能模式 | |
|---|---|---|---|
| 定位 | 极简部署,金融级RPO=0的强一致高可用 | 海量吞吐,应用透明 | 极致性能,巅峰响应 |
| 适用场景 | 小数据量业务、创新业务、初创项目 | 快速增长的成长型与核心业务 | 核心交易、高频互动等延迟敏感业务 |
| 适用数据量 | GB ~ TB + | TB ~PB | TB ~PB |
| 部署规模 | 1-3节点 | 3-∞节点 | 3-∞节点 |
| 性能表现 | 读写优于 MySQL,压缩率提升 3 倍以上 | 业界标杆的水平扩展能力 | 延迟降低至 1/4,吞吐提升 2-3 倍 |
Q5:敏捷模式最适合谁?
如果您符合以下画像,敏捷模式是首选。
- 初创期/验证期: 业务刚起步,数据量不大(TB 以下),希望快速上线,降低试错成本。
- 关注成本: 只有 1-3 台机器,希望获得比 MySQL 更好的性能和 3 倍以上的存储压缩率(省硬件)。
- MySQL 升级: 正在寻找比传统主从架构维护更简单、高可用更强(RPO=0)的替代方案。
Q6:聚能模式追求极致性能,是否牺牲了业务透明性?
完全没有,业务零感知。
聚能模式虽然通过“内存直连”将延迟压到了极致,但其底层的调度逻辑完全由内核自动完成。对上层应用来说,它依然是一个逻辑统一的分布式数据库。我们把复杂的调度留给自己,把简单的使用体验留给客户。
Q7:如果业务发展了,三种模式之间可以切换吗?
完全可以,无需重构即可平滑演进。
这是“一核三态”的最大价值——打通了业务发展的全生命周期。企业无需在早期为未来“押注”,可以先用敏捷模式低成本起步,随着业务增长平滑演进到标准模式或聚能模式。全程无需重构应用,真正做到“随需而变”。
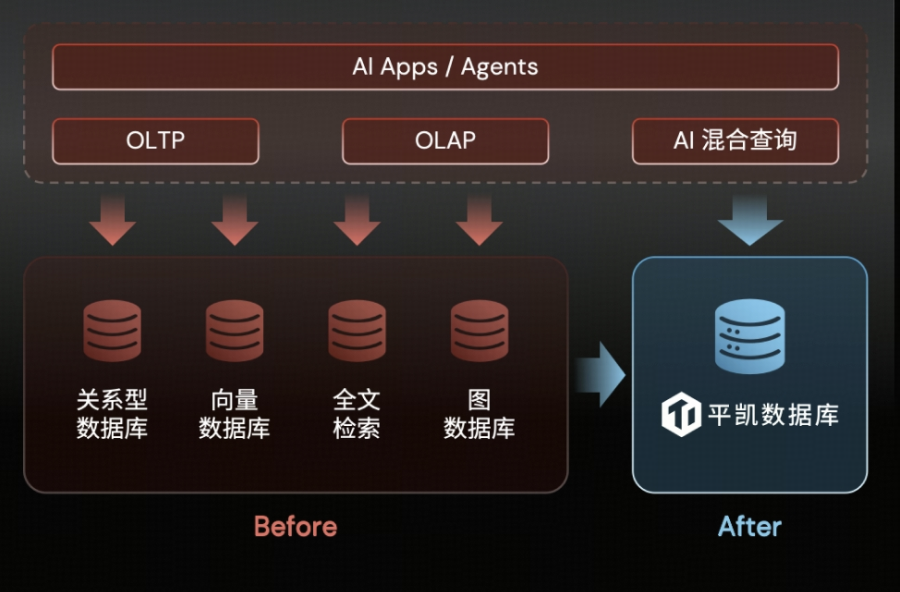
Q8:现在的技术栈越来越复杂(SQL、向量、搜索等),平凯数据库能帮我“减负”吗?
能,我们主张“统一数据底座”。
AI 时代不需要割裂的组件拼凑,而需要统一的数据底座。平凯数据库新一代内核集成了交易、分析、向量和全文检索能力。你无需在不同数据库间来回倒腾数据,一套系统即可支撑复杂的 AI 应用与核心业务,让架构回归极致简洁。
Q9:三种模式现在都可以试用了吗?
敏捷模式:https://pingkai.cn/products/pingkai-db/light-mode
标准模式:https://pingkai.cn/products/pingkai-db/standard-mode