

优化慢SQL是每一个DBA都不可避免的一项职责,而慢SQL很多都是系统响应时间长的罪魁祸首,而优化慢SQL的执行效率也受到统计信息过期的影响。
统计信息是指数据库描述表或者索引数据特征的信息,常见的有表记录条数、页面数等描述表规模的信息,以及描述数据分布特征的MCV(高频非NULL值)、HISTOGRAM(直方图)等信息。
TiDB 会使用统计信息来决定选择哪个索引。在 TiDB 中,我们维护的统计信息包括表的总行数,列的等深直方图,Count-Min Sketch,Null 值的个数,平均长度,不同值的数目等等。
直方图是一种对数据分布情况进行描述的工具,它会按照数据的值大小进行分桶,并用一些简单的数据来描述每个桶,比如落在桶里的值的个数。在 TiDB 中,会对每个表具体的列构建一个等深直方图,区间查询的估算便是借助该直方图来进行。
Count-Min Sketch 是一种哈希结构,当查询中出现诸如 a = 1 或者 IN 查询(如 a in (1, 2, 3))这样的等值查询时,TiDB 便会使用这个数据结构来进行估算。
我在运维过程中,发下一条慢SQL,具体SQL如下:
select *
from t_user_transaction tut
where 1 = 1
and tut.target_acc_no like ‘FF%’
and tut.trans_type = 1
and tut.status = 1
and tut.create_time between ‘2021-05-20 00:00:00’ and ‘2021-06-20 12:00:00’
and tut.acc_no not in (
select trans_in
from t_activity_result_log tarl
where tarl.status = 1
AND tarl.trans_out like 'FF%'
AND tarl.trans_in like 'YH%'
AND tarl.code != '053'
and tarl.trans_type = 0
and tarl.create_time between '2021-05-20 00:00:00' and '2021-06-20 12:00:00');
分析慢SQL第一件事就是需要看执行计划,分析执行计划发现子查询中的表t_activity_result_log并没有走索引,所以需要看这张表在create_time字段上是否建立了索引;

看到表结构信息,create_time字段是有索引的,第一时间怀疑,可能数据量都集中在这段时间,所以需要查看一些统计信息来协助分析,执行命令SHOW STATS_HISTOGRAMS where table_name=‘t_activity_result_log’;

返回结果为空,但是这个表已经存有上千万的数据了,不太可能统计信息为空,所以再次查询该表的健康度,执行命令SHOW STATS_HEALTHY where db_name=’tidb_wallet’ and table_name=‘t_activity_result_log’;

返回结果依然为空,现在这个问题走向就变得奇怪了,如果一张表没有统计信息肯定影响生成最优的执行计划。解决办法就是手动的去触发执行更新统计信息,执行命令analyze table tidb_wallet. t_activity_result_log以及验证统计信息更新命令SHOW STATS_META where db_name=’tidb_wallet’ and table_name=‘t_activity_result_log’;

这时我们再查一下该表的健康度SHOW STATS_HEALTHY where db_name=’tidb_wallet’ and table_name=‘t_activity_result_log’;
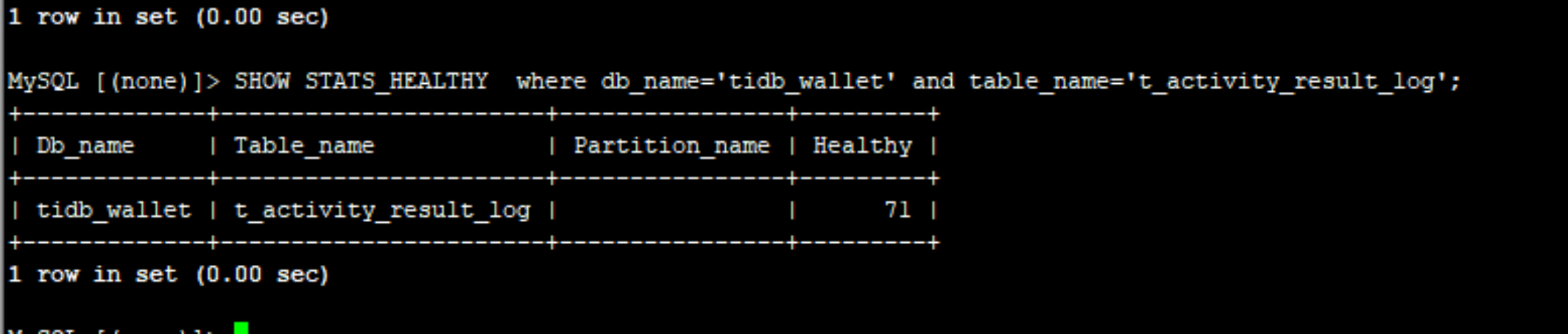
现在看起来就正常了。
出现上述问题虽然有解决办法,但是产生的原因未知,所以翻查资料以及咨询原厂的工程师后得知,加载统计信息也是内部运行 sql 的方式进行的,网络/负载等都有可能造成它失败,为了防范发生这种问题,除了自动更新统计信息外,可以追加定期更新统计信息的任务,来避免丢失统计信息带来的SQL语句执行效率低下的发生概率。
统计信息收集方式:
l 手动收集:可以通过执行 ANALYZE 语句来收集统计信息。
l 自动收集:在发生增加,删除以及修改语句时,TiDB 会自动更新表的总行数以及修改的行数。这些信息会定期持久化下来,更新的周期是 20 * stats-lease,stats-lease 的默认值是 3s,如果将其指定为 0,那么将不会自动更新
和统计信息自动更新相关的三个系统变量如下:
| 系统变量名 | 默认值 | 功能 |
|---|---|---|
| tidb_auto_analyze_ratio | 0.5 | 自动更新阈值 |
| tidb_auto_analyze_start_time | 00:00 +0000 | 一天中能够进行自动更新的开始时间 |
| tidb_auto_analyze_end_time | 23:59 +0000 | 一天中能够进行自动更新的结束时间 |
l 全量收集:可以通过以下几种语法进行全量收集。
- 收集 TableNameList 中所有表的统计信息:
ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
- 收集 TableName 中所有的 IndexNameList 中的索引列的统计信息:
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
- 收集 TableName 中所有的 PartitionNameList 中分区的统计信息:
ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
- 收集 TableName 中所有的 PartitionNameList 中分区的索引列统计信息:
ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
l 增量收集:对于类似时间列这样的单调不减列,在进行全量收集后,可以使用增量收集来单独分析新增的部分,以提高分析的速度。可以通过以下几种语法进行增量收集。
- 增量收集 TableName 中所有的 IndexNameList 中的索引列的统计信息:
ANALYZE INCREMENTAL TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];
- 增量收集 TableName 中所有的 PartitionNameList 中分区的索引列统计信息:
ANALYZE INCREMENTAL TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH|SAMPLES];