

作者介绍:李文杰,网易互娱高级数据库工程师,TUG 2019 年度和 2020 年度 MVA。主要负责大数据研发和数据分析工作,为产品提供精细化运营指导;同时在部门内推广使用 TiDB,为业务上云及数据库分布式化积累经验和探索最优方案,目前是 TiDB 管理小组负责人。
本文整理自 TUG 网易线上企业行活动,由网易游戏高级数据库工程师李文杰老师分享,主要介绍分布式数据库 TiDB 在网易游戏的应用实践经验。
视频回顾:[TUG 网易线上企业行] 分布式数据库 TiDB 的应用实践
网易游戏最开始引入 TiDB 是从 AP 的角度来进行使用的。在第一次使用 TiDB 时,我们把跑批业务这种计算量比较大的任务迁移到 TiDB 上面。在迁移过程中,如果跑的任务量比较大,相信很多人会遇到 “transaction too large” 报错这个问题。
TiDB 事务限制

经过一番排查发现,由于分布式事务要做两阶段提交,并且底层还需要做 Raft 复制,如果一个事务非常大,会使得提交过程非常慢,并且会卡住下面的 Raft 复制流程。为了避免系统出现被卡住的情况,TiDB 对事务的大小做了限制,具体限制的内容有单事务的 SQL 语句数、KV 键值对数目和大小、单 KV 键值对大小等。
知道这个限制后,我们就可以找到了解决办法,即 把大的事务按业务的需求切分为多个小事务分批执行 ,这样之前跑失败的 SQL 就能成功运行了,而且在 MySQL/Oracle 中的跑批程序,也都成功迁移到了 TiDB。
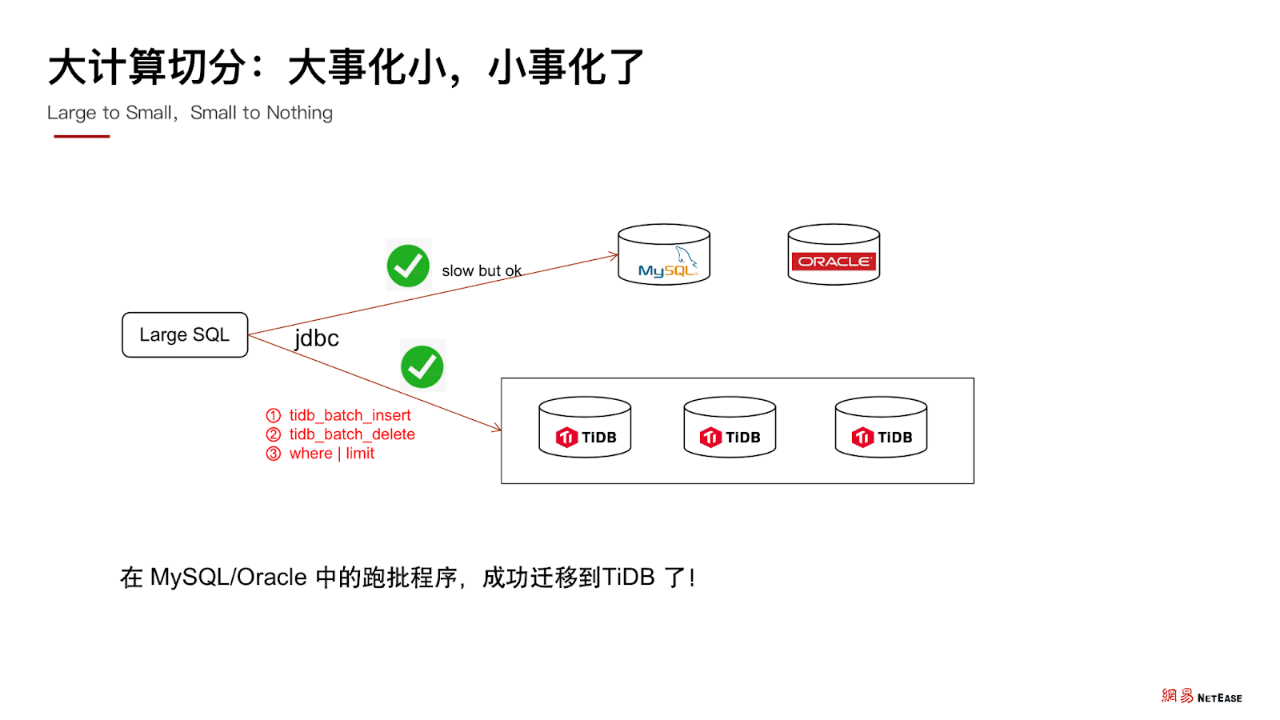
同时,我们不得不思考,在没有问题的时候,程序可以跑得非常顺畅,但是当机房中出现网络问题,或是出现其他的故障时,就会出现一部分数据写入到了 TiDB 中,而另外一部分数据是没有写入的。在场景中的表现是一个事务的执行没有能够保证其原子性,只执行了其中一部分,有一部分成功,有一部分失败了。
经排查发现,这是因为我们手动开启了事务切分,这种情况下大事务的原子性就无法保证,只能保证每个批次的小事务原子性,从整个任务的全局角度来看, 数据出现了不一致 。
那么该如何解决这个问题呢?
TiDB 大事务优化

通过向官方反馈问题之后,TiDB 4.0 对大事务进行了深度优化,不仅取消了一些限制,而且将单事务大小从 100MB 直接放宽限制到 10GB,直接优化了100 倍。但与此同时也带来了另一个问题,在进行 t+1 的跑批业务时,前一天可能会有几百甚至上千万的数据量,如果用程序 JDBC+TiDB 方式处理,效率其实不高,处理时长往往需要持续数小时,甚至几十小时以上。
那么该如何提高计算任务的整体吞吐量?答案是 TiSpark。
TiSpark:
高效处理复杂 OLAP 计算
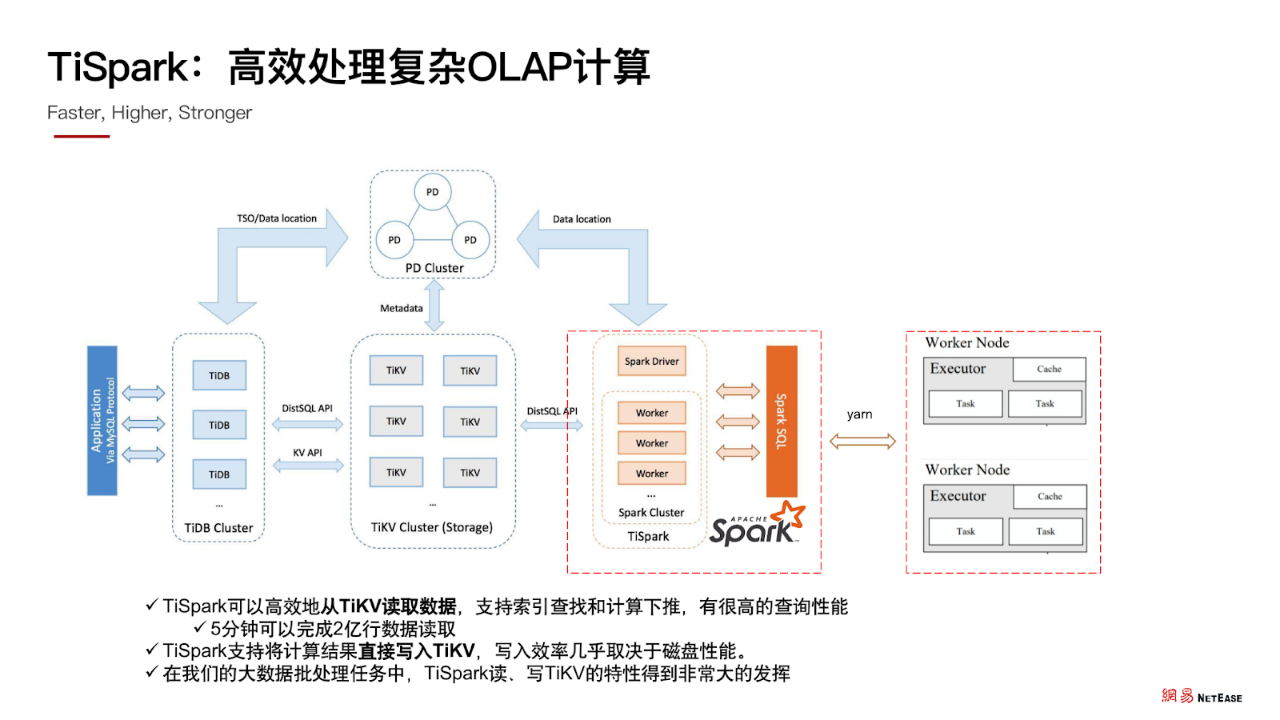
TiSpark 是在 Spark 基础上开发的一个插件,它可以高效地从 TiKV 读取数据。同时支持索引查找和计算下推策略,有很高的查询性能。我们在实践过程发现,使用 TiSpark 读取 TiKV 的方式,5 分钟可以完成 2 亿行数据读取。同时它也有很高的写入性能。有了 TiSpark,我们可以直接通过 Spark 工具访问 TiKV 数据。
经过时间证明, TiSpark 读、写 TiKV 都有着非常好的性能表现 ,通过 TiSpark 我们可以处理比较复杂、数据量比较大的运算。
TiSpark 实践
在实践中,使用 TiSpark 主要有两种方式:
- 方式一:TiSpark + JDBC 写入
TiSpark + JDBC 写入方式能够自动切分大事务,但不一定能保证事务的原子性和隔离性,且故障恢复时需要人工介入。这种方式写入速度可以达到 180 万行/min,通过 TiDB 处理 SQL 再写入 TiKV,速度一般。
- 方式二:TiSpark 批量写入 TiKV
TiSpark 批量写入 TiKV 不会自动切分大事务。通过 TiSpark 直接读写 TiKV,相当于直接通过大事务读写 TiKV 的数据,可以保证事务的原子性和隔离性,同时拥有良好的写入性能,写入速度可以达到 300 万行/min。
经过 TiSpark 的应用,解决了我们大数据量批处理任务的问题,但是也存在一定的隐患。TiSpark 在进行读、写 TiKV 的时候,由于 TiKV 是作为整个 TiDB 架构的存储引擎,如果存储引擎层的数据读写压力大,对于线上的其他业务将会产生明显的影响。此外,在 TiSpark 读写 TiKV 时,如果没有对 IO 进行限制,很容引发性能抖动,导致访问延迟上升,也会对其他线上业务产生影响。
怎么样才可以做到有效隔离?或许 TiFlash 列式存储引擎能提供答案。
TiFlash:列式存储引擎
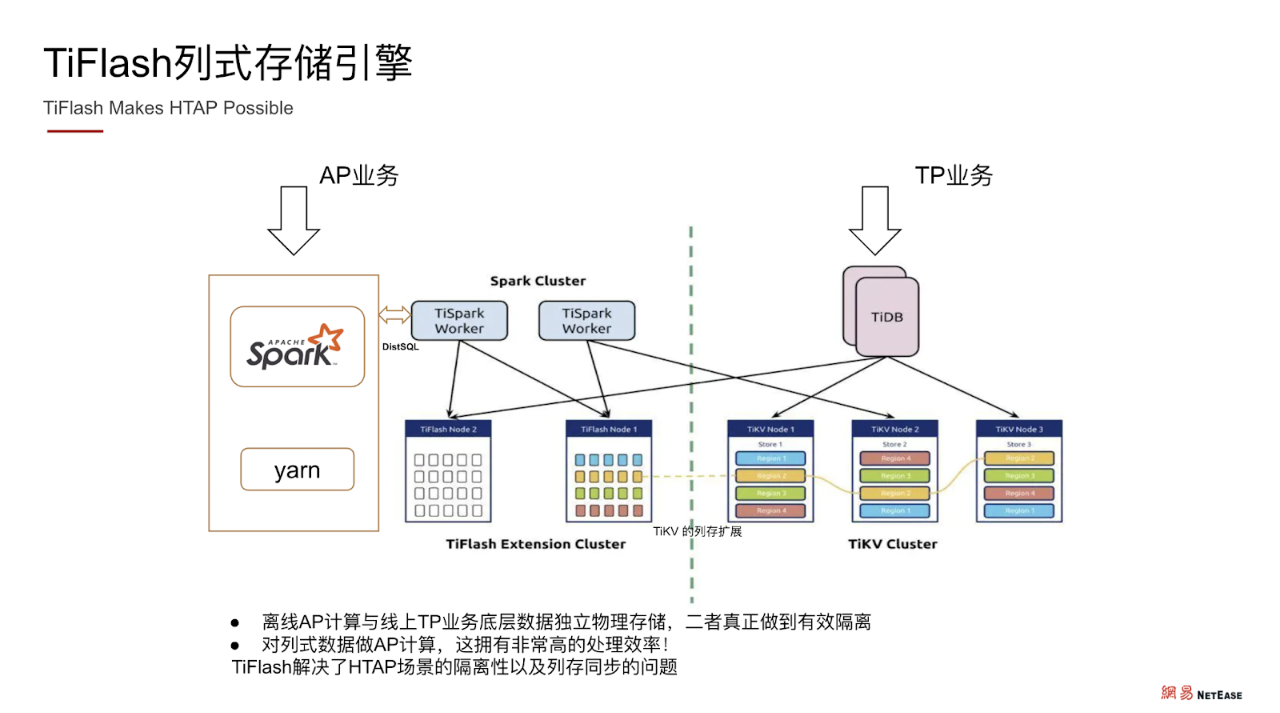
TiFlash 作为 TiKV 行式存储引擎的补充,它是 TiKV 数据的 raft 副本,TiFlash 作为在 TiKV 基础上的列式副本,经过 raft 协议保证数据同步的一致性和完整性。这样同样的一份数据就可以存储在两个存储引擎里面。TiKV 保存的是行存数据,TiFlash 保存的是列式数据。
在做 Spark 的计算分析时,我们可以直接从 TiFlash 集群进行读取,计算效率会非常高。用列式数据做 AP 分析,对于行式数据来说,简直就是降维打击。
TiFlash:TPC-H 性能分析
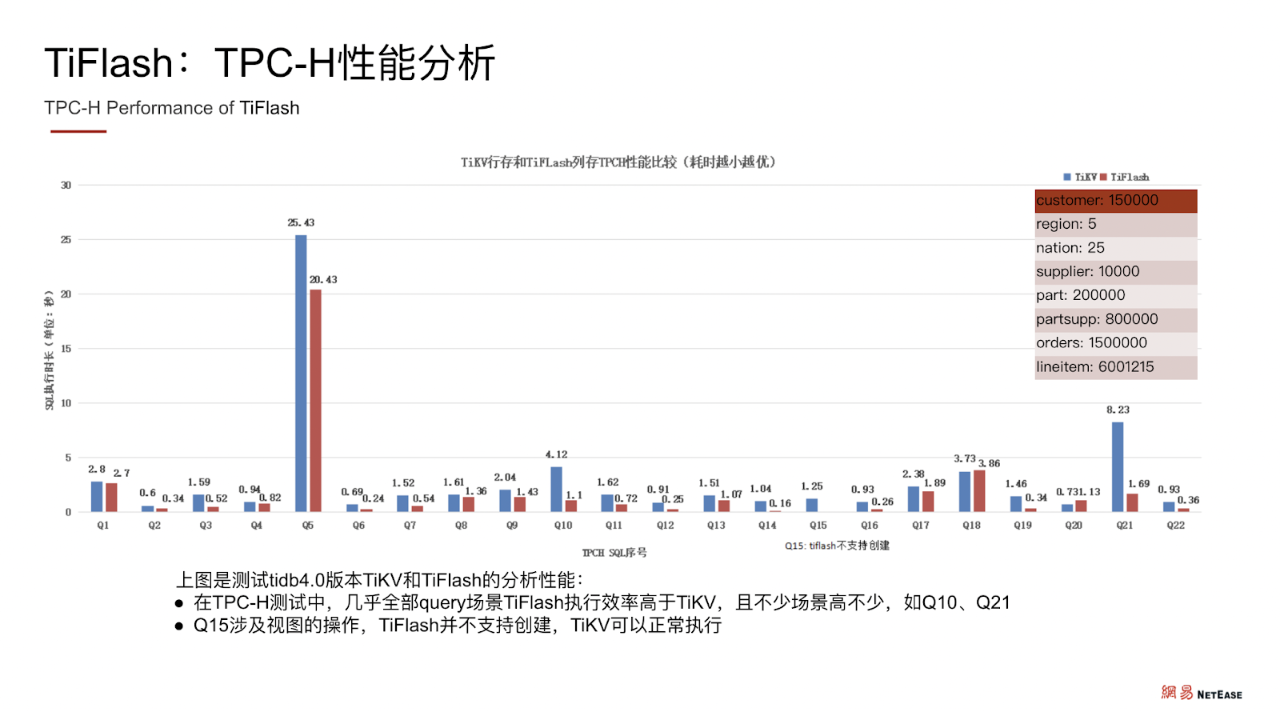
TiSpark + TiFlash 的结合应用使计算效率取得了量与质的提升。TPC-H 性能分析显示,在与 TiKV 的横向对比中,几乎全部 query 场景下 TiFlash 执行效率都高于 TiKV,且部分场景的效率远高于 TiKV 。用了 TiFlash 以后, 既不影响 TiKV 的集群性能,也不影响线下的集群业务,而且在做离线大数据分析时,依然能够保持很好的性能与吞吐量 。
经过实践证明,TiFlash 可以解决我们的诸多问题,是非常棒的一个工具。
TiFlash应用:计算更高效
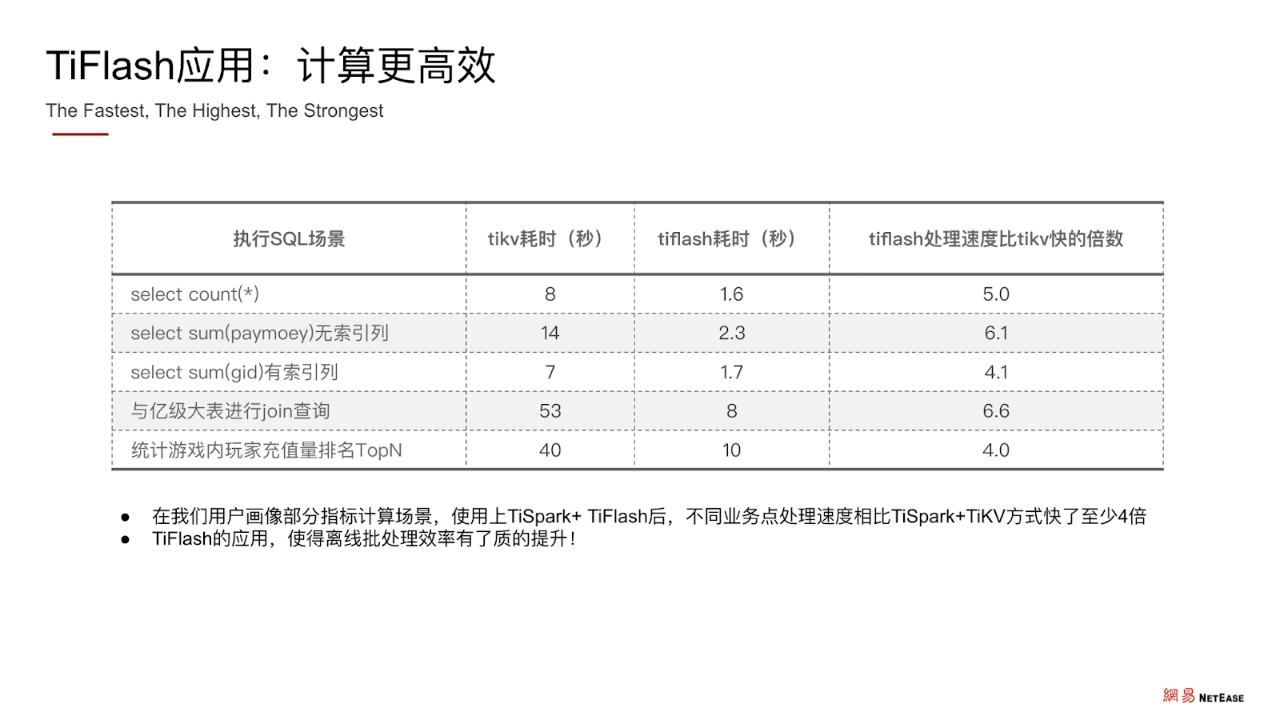
在网易游戏用户画像的部分指标计算场景中,使用上 TiSpark + TiFlash 后,不同业务内容的 SQL 处理速度相比 TiSpark + TiKV 快了至少 4 倍。所以使用 TiFlash 之后,离线批处理效率有了质的提升。
JSpark:跨源离线计算
随着业务规模和应用场景的增加,不同数据分布存储在不同的存储引擎。比如日志数据存储在 Hive,数据库数据存储在 TiDB,跨数据源访问需要大量数据迁移,耗时且费力。
能否直接打通不同数据源,实现跨源互访?针对这个问题网易游戏采用了 JSpark 工具。 JSaprk 是为了打通底层不同存储,实现跨源访问目标而实现的一个离线计算工具 。这个工具核心是 TiSpark + Spark 组件,Spark 作为桥梁,可以实现不同数据源的访问。
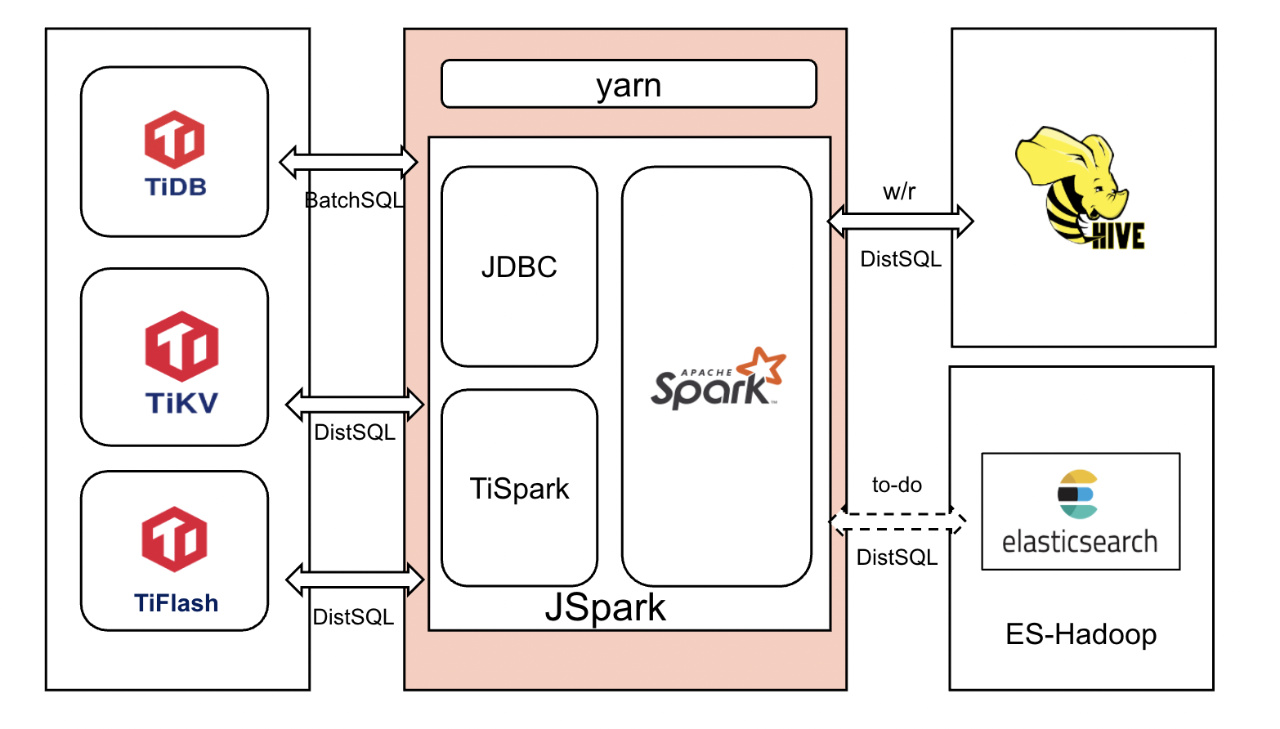
JSpark 基于 TiSpark 和 JDBC 进行封装,在 TiKV 可以进行数据读写,在 TiFlash 可以进行列式 AP 计算,在 TiDB 可以做常规的 SQL 计算,目前我们已经封装实现了 TiDB 和 Hive 的相互读写功能,后续 JSpark 工具将会支持 TiDB 与 ES 的读写互访,实现 TiDB、Hive、ES 多源数据访问。
目前 JSpark 工具,主要是实现了以下功能:
-
支持 TiSpark+JDBC 方式读写 TiDB 和读写 Hive,这种方式效率一般。
- 应用场景: 在 TiDB 宽表中只操作业务需要的部分列。
-
支持读 TiDB 表数据,Spark 计算结果写入 Hive 目标表。读推荐使用 TiSpark 读取 TiKV或 TiFlash 的方式,写推荐使用 TiSpark 写入 TiKV的方式,效率会更高。
- 应用场景: 定期轮转 TiDB 分区表过期分区 ,备份永久保留副本到 Hive,避免TiDB 表过大。
-
支持读 Hive 表数据,Spark 计算结果写入 TiDB 目标表。推荐使用 TiSpark 写入 TiKV 的方式,效率高。
- 应用场景: 分析 Hive 数据产出用户画像指标并写入线上 TiDB ,提供线上业务 TP 查询。另一个实践场景是恢复 Hive 备份到 TiDB。
-
支持前端 web 或业务发起 http 请求,远程启动 Spark 作业,完成底层 TiDB 和 Hive 的联合查询。
- 应用场景:前端管理平台点击查询按钮, 获取某玩家 Hive 链路日志和 TiDB 数据的联合聚合结果 ,提炼出相关行为数据。
我们在开发和使用 JSpark 相关功能期间,也发现了 TiSpark 的一个可优化点。
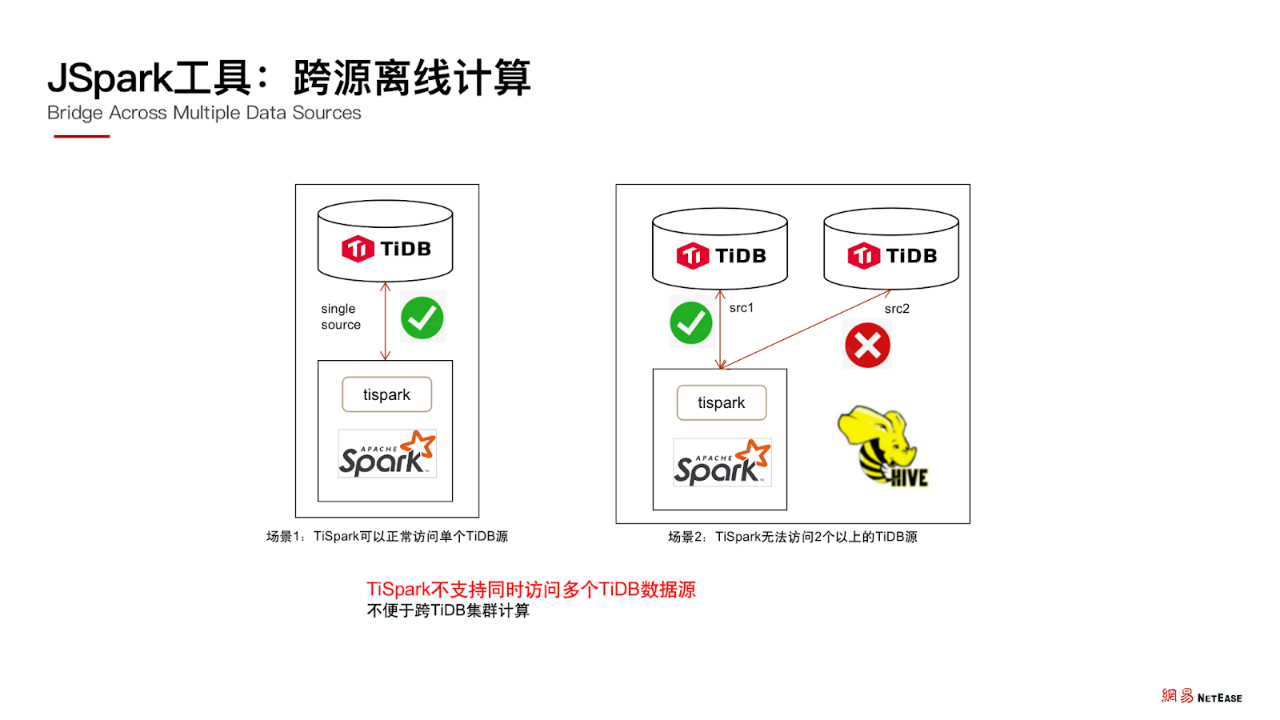
目前 TiSpark 不支持同时访问多个 TiDB 数据源,运行时只能注册一个 TiDB 集群,不能注册多个,这不便于跨 TiDB 集群计算。在未来我们希望 TiSpark 可以支持同时访问多个 TiDB 集群。
TiDB 应用:HTAP 数据体系
JSpark 目前是离线计算的核心框架,除此之外还与 JFlink 实时计算框架相结合,共同组成了大数据处理能力。JSpark 负责离线大数据计算框架,JFlink 负责实时计算框架,两者共同组成了 HTAP 的数据体系。
HTAP 计算能力:JSpark+JFlink
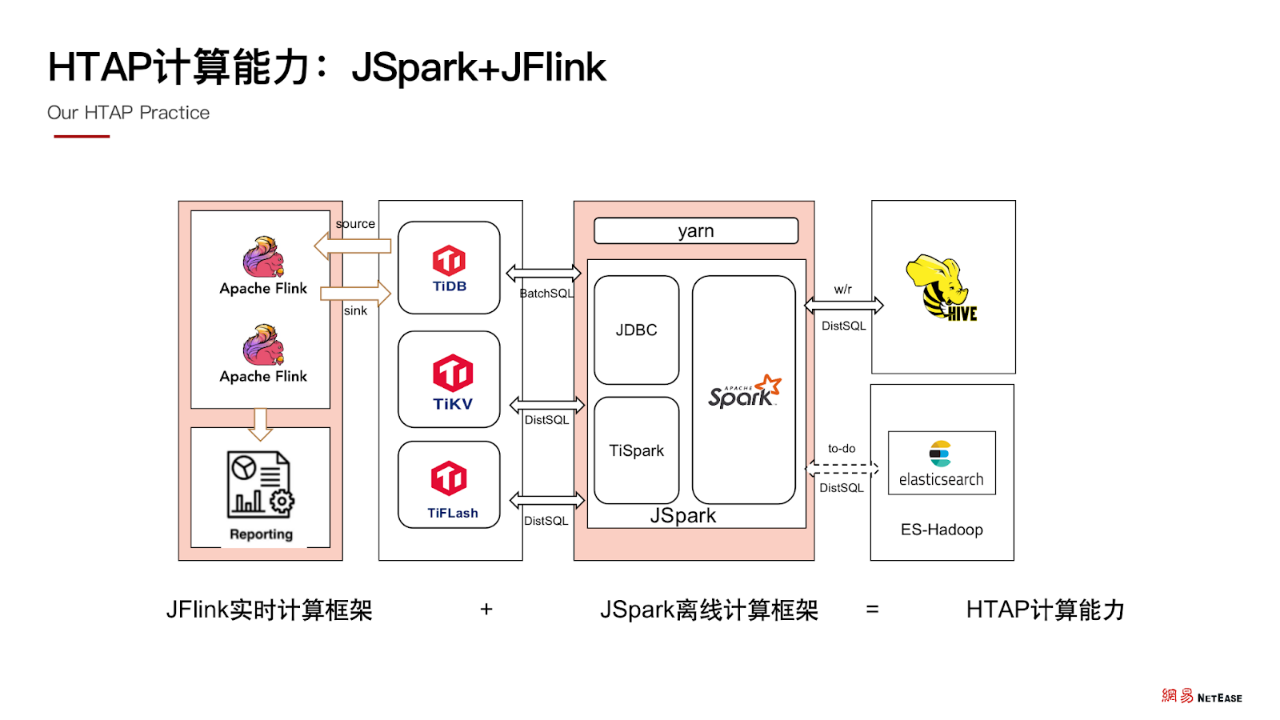
首先, 将线上数据实时同步汇总到 TiDB 集群 ,再依靠 JSpark + JFlink 在 TiDB 和其他数据源进行离线和实时计算,产出用户画像等指标分析数据,反馈线上业务查询。
TiDB 应用:HTAP 数据体系
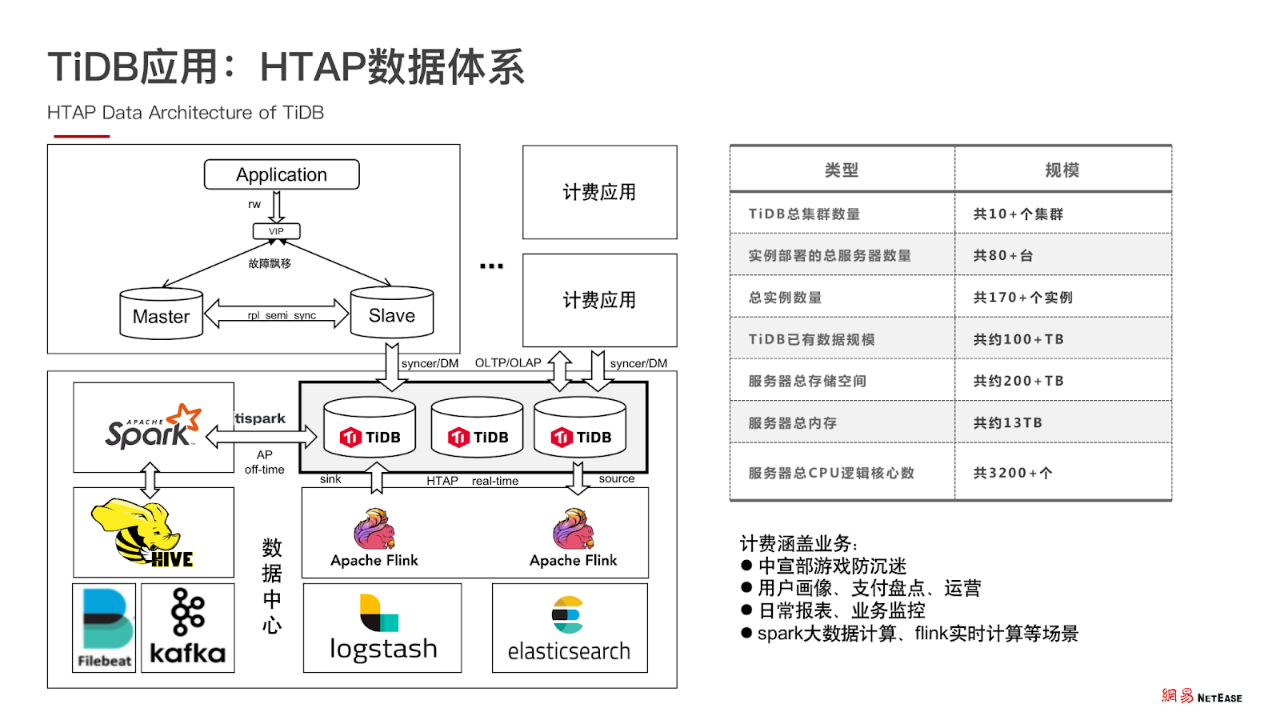
目前,经过 3 年的发展,网易游戏的集群总实例数量 170 个,数据规模达到 100 + TB 级别。我们的业务涵盖用户画像、防沉迷、运营、报表、业务监控等多个方面,并且业务规模和集群规模也在不断发展和扩大中。
以上就是网易游戏在使用 TiDB 的过程中,对于 AP 计算演进的过程,希望今天的分享可以对大家有所启发。
关于 TUG
TUG(TiDB User Group) 是由 TiDB 用户自发组织、管理的独立社区,PingCAP 官方提供赞助与支持。目前共有华北、华东、华南(广州、深圳)、西南(成都、重庆)、TUG APEC(新加坡)小组。TUG 成立的初衷是“连接用户,共建社区”,汇聚了全球数据库、大数据技术从业者,是一个独立、自发、不以盈利为目的的组织。
如果你对数据库、大数据感兴趣,如果你也想跟业界大咖们一起交流最前沿的数据库与大数据知识,欢迎加入 TUG,和 TUG 一起成长!
扫码报名或者点击链接跳转报名

🙌 小伙伴们注意啦~
为了可以给 TiDB 社区 的小伙伴提供更加好的体验,我们开通认证入口啦~完成认证,即可获得**“加急**”处理问题权限,加快问题响应速度:https://tidb.io/account/organization/new
完成团队认证,还可以获得 +200 经验值,+200 积分 ,并授予 “认证会员” 徽章!
详情了解:【已结束】完成认证抽“周边三件套”,解锁“加急”处理问题权限