

本文来自涂鸦智能的刘筠松在 PingCAP DevCon 2021 上的分享,包括 TiDB 在 IoT 领域,特别是在智能家居行业的使用。
- 视频回顾: https://www.bilibili.com/video/BV1oy4y157N8
- 讲义下载:涂鸦-刘筠松-涂鸦智能选型 TiKV 的心路历程.pdf (1.4 MB)
关于涂鸦智能
涂鸦智能是一个全球化 IoT 开发平台, 打造互联互通的开发标准,连接品牌、OEM 厂商、开发者、零售商和各行业的智能化需求。基于全球公有云,实现智慧场景和智能设备的互联互通。涵盖 硬件开发工具、全球公有云、智慧商业平台 开发三方面; 提供从技术到营销渠道的全面赋能,打造中立且开放的开发者生态。
目前涂鸦在国内外已经有超过十万家的合作伙伴,在 IoT PaaS 和 IoT 的开发者平台的生态客户数量已经达到 32 万 +,其涉及到制造业、零售业、运营商、地产、养老、酒店(PaaS)等。涂鸦赋能的有欧美品牌和中国品牌,包括飞利浦,国内的海尔以及三大运营商。

海量数据的实时响应:TiKV 选型历程
涂鸦的设备在全球每天处理 840 亿请求,平均处理高峰次数能达到 150 万 TPS,平均响应时间要求小于 10 毫秒。因为涂鸦是物联网行业,区别于传统行业,没有低峰点,写入量非常大,涂鸦用六年的时间不断选型尝试,探索最合适的数据架构。

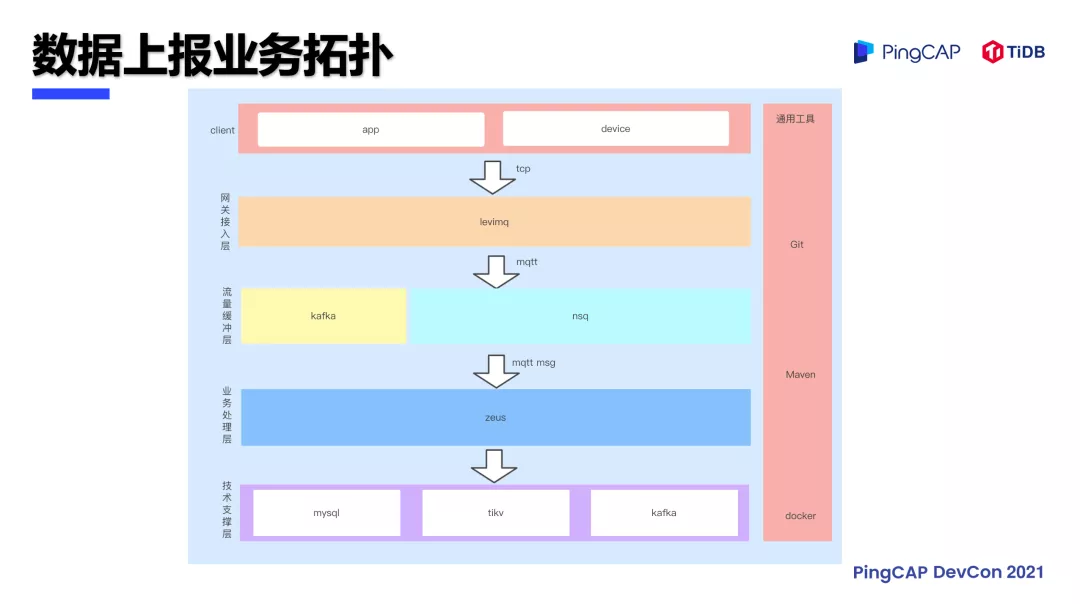
涂鸦之所以有这么大量的数据,是因为目前人们家里应该都会使用到智能设备,例如智能电灯、扫地机器人,设备联网后就与涂鸦平台有了通讯的能力,而智能设备的各种定时触发,比如家里的摄像头巡更、扫地机器人的位置信息都需要上报给涂鸦的 Zeus 平台。Zeus 系统作为涂鸦平台最重要的角色,负责处理 数据上报,业务拓扑 如下图所示,应用网关收集到智能设备上报的 MQTT 消息之后会发送到 Kafka 和 NSQ 上面,Zeus 系统会消费这些消息进行解密,处理过后要放到存储里面。本文主要描述的也正是从 Zeus 到存储之间的这段产品选型。
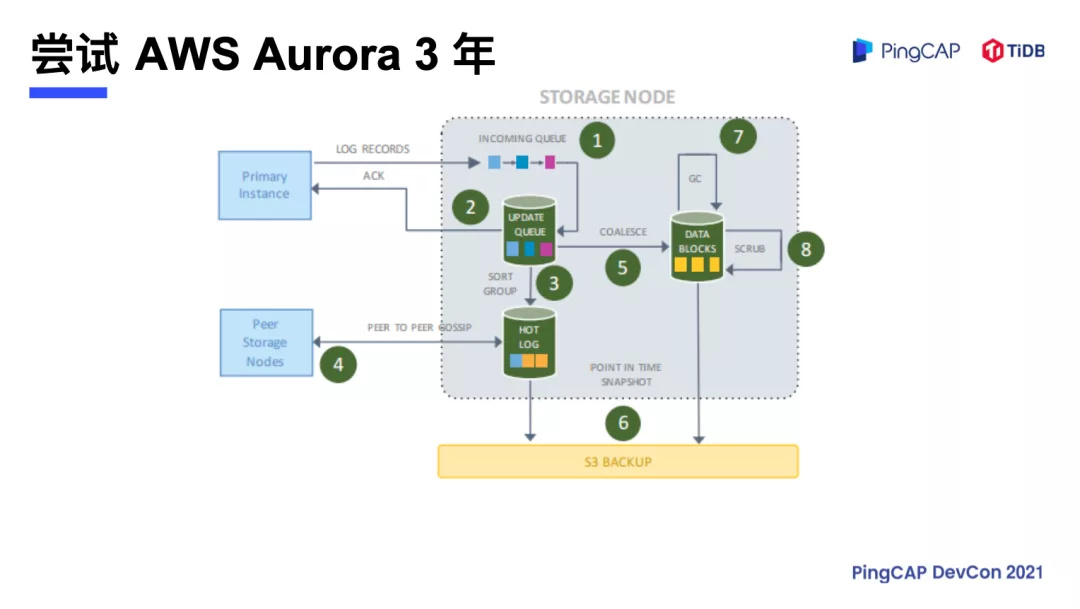
AWS Aurora
涂鸦在早期使用的是 AWS Aurora。Aurora 跟阿里云的 PolarDB 类似,是 存算分离 的架构,涂鸦在 Aurora 上稳定运行了三年,在前三年使用中 Aurora 完全满足需求。物联网在六七年前还比较冷门,智能家居设备没有这么普及,用户用的不多,但后来随着业务的扩展,近几年设备呈指数级的成长,每年都要翻三到五倍,Aurora 就无法承受暴增的数据量,特别是物联网响应时间要求是 10 毫秒以内,即使进行分库分表,拆散集群也达不到涂鸦的业务需求。
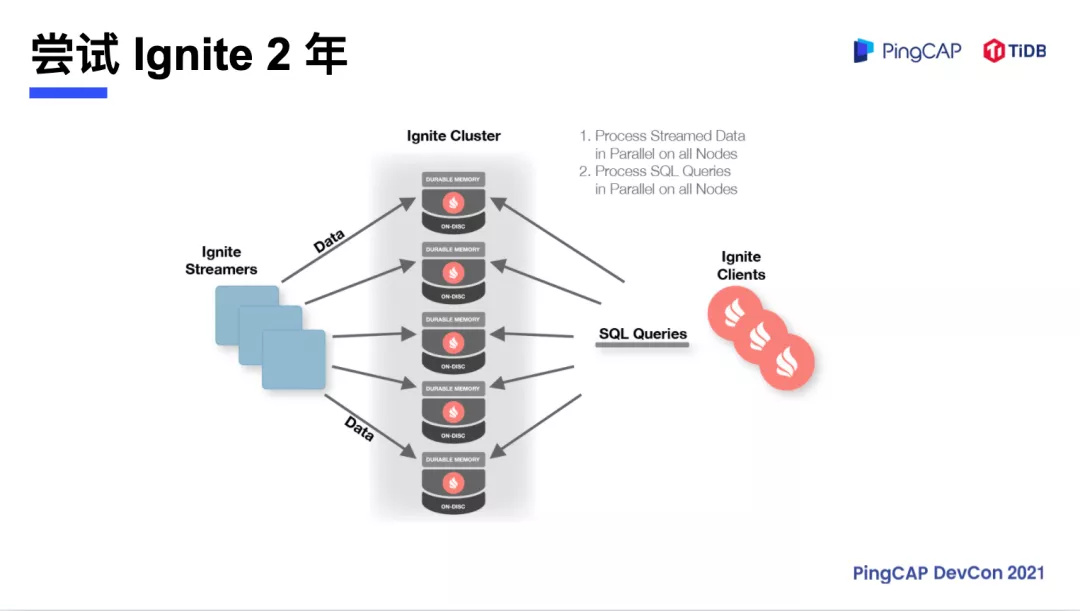
Apache Ignite
于是涂鸦开始尝试使用 Apache Ignite,也是一个分布式的 KV 系统 ,类似于 PingCAP 的 TiKV,它是基于JAVA 架构进行数据分片的,其分片比较大,1G 的数据一个 Partition,并且其扩容没有 TiKV 这么线性。如果涂鸦的业务量翻倍,在机器要扩容的时候就不得不停机,还会有数据丢失的风险。这个时期我们在一个 Ignite 后面下挂了 Aurora 作为灾备,数据会同步写到 Aurora 里面。然而随着业务量的暴增,一个 Ignite 也不能满足涂鸦的业务需求,就需要进行扩容,而 Ignite 架构下扩容的时候要求停机,这是物联网所无法容忍的。
TiDB 3.0 和 4.0
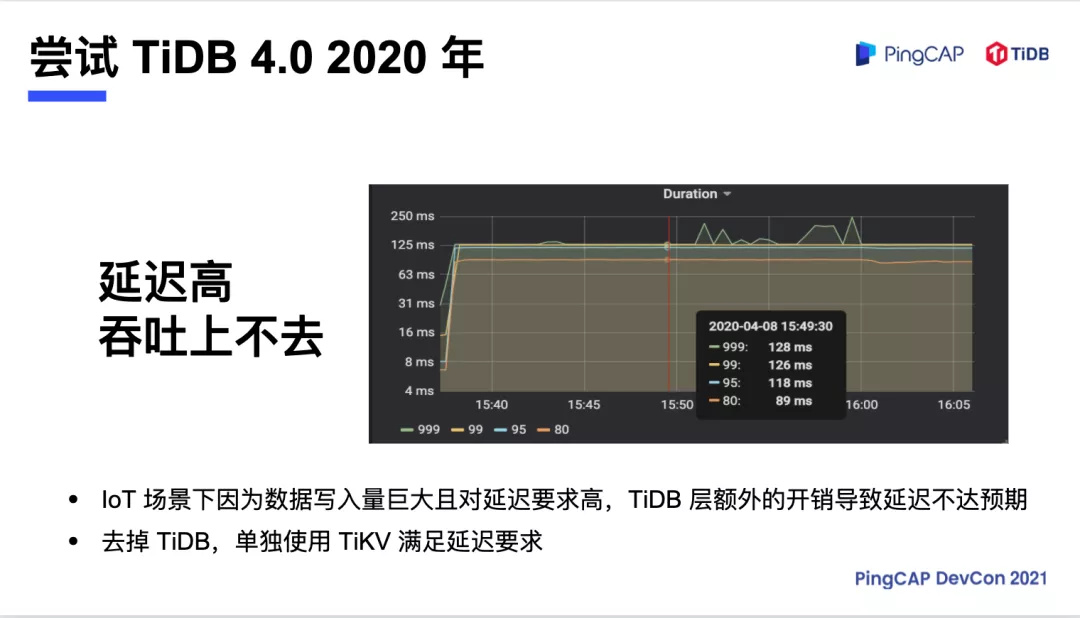
在 2019 年涂鸦在尝试替换掉 Ignite Cluster 的时候,美国区的存储设备已经达到 12 台节点。恰逢 PingCAP 在杭州举行 TUG 活动,我们对 TiDB 3.0 进行了验证测试。但是 TiDB 3.0 上线没有满足涂鸦的要求,因为延迟高,吞吐也上不去,尝试了几个月以后只好作罢。
时间来到 2020 年,TiDB 4.0 上线了。我们又对 TiDB 4.0 进行了测试,对比 3.0 有非常大的进步,但是延迟高,吞吐量不足的问题依旧存在。这时候 PingCAP 研发团队针对这个问题进行了深入分析,发现主要的耗时就在 SQL PARSER 层,而 TiKV 底层的存储是完全闲着的,因为涂鸦的写入量大,对延迟要求高,完全达不到预期。
既然出现的延时都消耗在 SQL PARSER 层,而物联网写入的数据虽然 TPS 高,但业务逻辑没有那么复杂,能不能去掉 SQL 层,直接写入 TiKV 层?我们参照了 PingCAP 提供了 TiKV 的官方 API 文档,宣称已经 支持 JAVA、GO 和 Rust ,开始了尝试和探索。
上线应用的结果很惊喜,得到了全公司的认可。之后我们在全球各个地区都上线了 TiDB 4.0,经过一年的测试,运行正常没有发现什么问题,原本需要 12 台机器,同等配置下现在只要 3 台机器就能搞定了,也就是说 硬件成本只有原本的四分之一 。
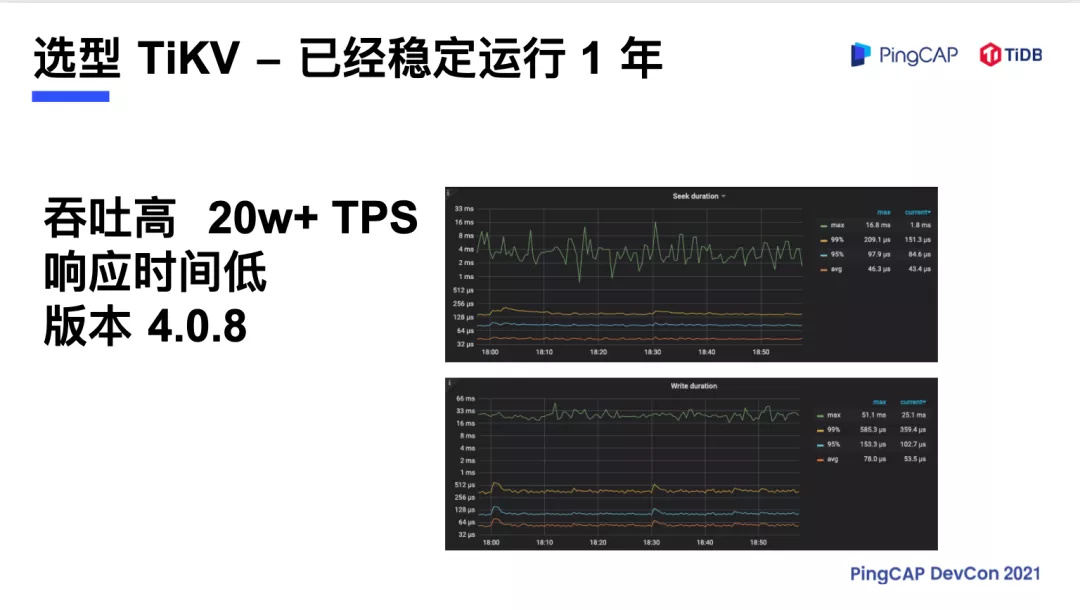
涂鸦吞吐量上线的时候已经有 20 万 TPS,以北美区的集群来看,当时的版本是 4.0.8,查询的响应时间 99% 是 150 微秒,写入是 360 微秒(不到一毫秒),有类似场景的小伙伴们可以尝试一下。
新的挑战:跨区域部署
但是我们没有高兴多久就遇到了新的挑战,因为 AWS 部署的时候是三个可用区的部署,比如法兰克福一部署就是 ABC 三个区域,三个副本之间通讯是要消耗流量,而流量是要收费的,而且涂鸦所有的应用也是部署在三个区,也需要跨区域的调用,TiKV 并没有像 Dubbo 那样同区调用的策略,所以这个费用的成本居高不下,尽管涂鸦只有以前四分之一的机器,但是成本比原本还高。目前进行的解决方案是进行了基于 RPC 的压缩,降低网络的流量,但这种流量只能解决 Region 复制的流量,应用代码跨区的复制流量还是没有降下来。
我们发现出现这种问题的原因是因为 TiKV 的服务端没有进行服务端过滤,需要把 TiKV 存储的数据取回到本地进行应用程序的过滤,然后再塞回去,这个跟 TiKV 的研发团队进行了沟通, 后续的版本可能会推出 基于服务端的过滤,降低服务器的负载,流量成本也可能会下降 。

降本增效:从 X86 到 ARM 的架构升级
IoT 行业之所以注重降低成本,因为 IoT 行业的毛利率非常低,我们需要降低每一件模组的成本。在 2020 年 6 月,AWS 推出了 C6G 的产品,性价比宣称比上一代 C5 高出 40%,于是我们对 AWS 的 C6G 进行了尝试,但用 TiUP 编译直接部署的时候发现响应时间比 X86 架构慢 6 到 7 倍,即 TiUP 部署的是通用编译版本,跟硬件不是那么贴切。经过测试验证,发现现有的 TiKV 版本不支持 SSE 指令集,也就是说目前 TiKV 4.0 使用的 RocksDB 版本是不支持 SSE 指令集的。
SSE 指令集主要是进行 CRC 校验、HASH 和浮点运算的。当时进行了折中方案就是混合部署,TiKV 这边使用的是 X86 架构,其他节点使用的是 ARM 的架构,但这样也带来不方便,如果升级版本的话,指向的镜像一会是 X86 的,一会是 ARM 的,这样会是很麻烦,于是则整体切回了 X86 的架构。
到了今年,TiKV 推出了 5.0 版本,TiKV 5.0 是支持了 aarch 64 优化过的 CRC32C 指令集,也就是 SSE 4.2 指令集,但前提条件是 RocksDB 版本要大于 6.1.2,而 TiKV 5.0 版本的 RocksDB 的版本是 6.4.6,并且在 TiKV 上面可以找到 TiKV 针对 SSE 指令集的优化,也就是说 TiKV 5.0 现在已经完全支持 SSE 指令集了 ,下半年将会纳入重点进行测试,这样的话成本有可能会更大幅的下降。
业务展望
未来借助 TiDB 5.0 和 5.1,涂鸦有信心能够承接数倍的业务增长,预计年底 TiKV 的流量又会翻到现在的三到四倍。大数据平台也用了 TiDB 作为大屏展示,并且物联网的设备流水也正在考虑使用 TiKV 5.1 作为存储,更大程度上 提高易用性 ,TiDB ARM 版本的部署也在下半年的规划之中。