

编者按
上周六,由 OpenLoong 开源社区、上海电气中央研究院与 TiDB 社区联合主办的 “数据驱动,机器人赋能:跨域智能应用与创新发展” 技术分享会顺利落幕。会上,TiDB 社区售前架构师刘源带来《TiDB:打造智能制造、能源领域新一代数据底座》主题演讲,聚焦智能制造与能源行业数字化转型中的数据痛点,深入解读 TiDB 如何依托分布式数据库技术,构建高性能、高可用的新一代数据底座。本文将基于此次分享,为大家梳理其中的核心思路与解决方案。
作者:刘源|TiDB 售前架构师
智能制造与能源领域:呼唤新一代数据底座
随着工业数字化转型的不断深入,智能制造与能源领域的数据正呈爆炸式增长,这对底层数据基础设施带来了前所未有的挑战。在今年的世界人形机器人运动会上,智能机器人的出色表现不仅向全球展示了人形机器人发展的阶段性成果,也预示着智能制造业正迎来一个蓬勃发展的时代。数据库作为其核心基础软件,如同芯片操作系统,是支撑智能制造、能源等关键行业发展的关键要素。面对智能制造与能源领域发展的新阶段,市场亟需一种能够适应数据爆发式增长,并深度融合人工智能技术的数据库解决方案。
以某知名电器制造商为例,在该企业的系统架构中,前端部署了大量制造业应用系统,如 MES (Manufacturing Execution System,制造执行系统)等,后端则依赖国外的 SQL Server 数据库支撑。由于生产流水线多、数据量大,该用户需要以多个数据库分别支撑前端的应用,且每个数据库通过 SQL Server 的同步软件连接备库,用于数据监测与计算分析。
然而,这种架构存在明显弊端:
1. 数据分散在多个数据库中,缺乏统一化数据平台,难以实现数据的实时关联分析;
2. 在传统集中式架构下,单台机器故障即可能导致数据库宕机,主备同步链路失效,严重影响后端业务;
3. 数据量激增时,传统单体数据库的分析时效性也不足。因为传统单体数据库只能通过纵向扩展,如增加 CPU、硬件的方式来提升计算性能,但单台机器的计算能力始终是有限的,性能瓶颈始终存在,导致该制造商系统后端报表生成不及时。
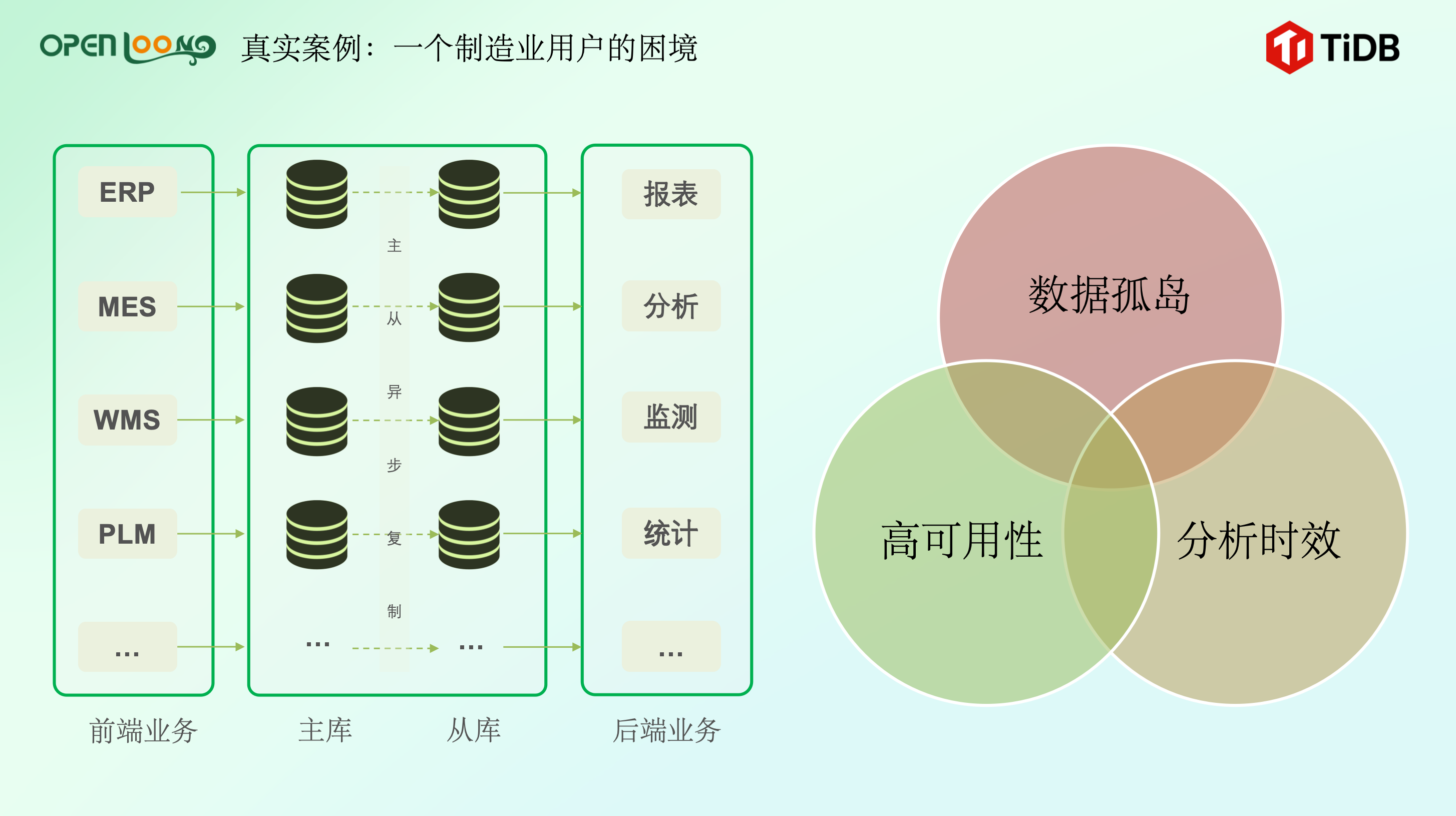
总结而言,以下痛点问题在制造业和能源行业普遍存在:
- 数据量爆发式增长,传统单体数据库难以支撑。以 TiDB 某制造领域用户为例,该企业从第一代 MES 系统到第二代 PES 系统,数据量增长达十倍;某采集系统,每秒百万写入。这些场景下,传统单机 MySQL 难以支撑。
- 随着数据量增长,数据分析的时效性要求越来越高,传统方案难以满足实时处理需求。在先进制造业、能源电力等领域,出于对生产精度、效率及安全性的高要求,生产控制需达到亚秒级响应,例如设备故障预测延迟<100ms;在电力行业,电网状态分析希望在分钟级甚至更短时间得出结果,以满足能源高效调度。
- 业务场景越来越复杂多元,传统架构难以实现数据跨系统跨大表的实时关联分析。以某半导体行业客户为例,其业务诉求希望通过一套数据平台来支撑 ERP、CRM 等系统,实现秒级分析不良率、时序数据高并发写入等。然而传统单体数据库架构下,数据分散在多套孤立系统中,跨表关联需频繁跨库查询,且面对上亿的乃至上十亿量级的数据量,单库计算能力有限,远无法满足秒级分析的业务要求。
- 系统扩展难题日益凸显。OT/IT 系统竖井式架构成为了瓶颈,历史遗留 MES/ERP 系统升级改造困难;传统架构难以进行分布式资源大规模介入。

TiDB:新一代分布式数据库的突破
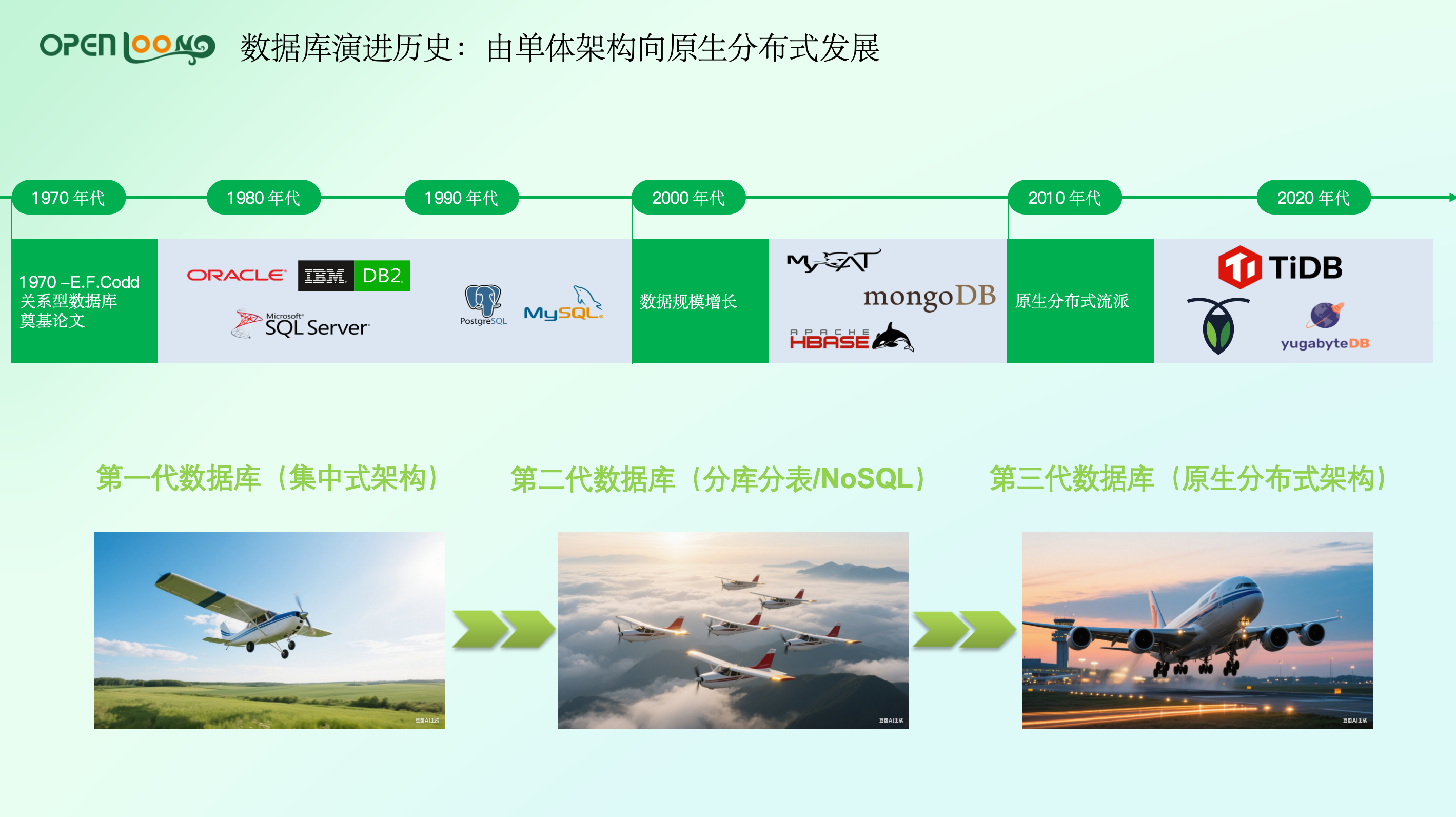
数据库的发展历经多个阶段。1970 年代起,以 Oracle、IBM DB2、微软 SQL Server 为代表的商业数据库,以及 1990 年代出现的 MySQL、PostgreSQL 等开源数据库,均为集中式架构,部署在单台机器上。2000 年后,互联网发展带来数据量爆发式增长,单台服务器难以支撑,分库分表架构和 NoSQL 数据库应运而生,但分库分表需中间件协调数据分布,NoSQL 不支持标准 SQL,二者均存在缺陷。
2010 年后,基于谷歌发表相关论文理论,TiDB 作为新一代 New SQL 数据库应运而生,采用原生分布式架构。其架构具有存算分离特点,即存储与计算可分离部署,扩展性强;多个组件协同工作,保障高可用性,单个机器故障不影响整体业务与数据;存储引擎包含行存和列存两套,可满足混合业务场景需求。
TiDB 产品架构:大中小全业务场景支持

分布式多活架构
TiDB 天生就是一套分布式架构,存算分离的设计使得它具备出色的扩展性和高可用性。在标准分布式下,系统的所有核心组件采用多副本部署,即使出现物理故障,业务运行也几乎不会受到影响。在容灾方面,TiDB 最多能保证即使三分之一的节点故障也不影响业务运行,同时确保即使三分之二的节点故障不会导致数据丢失。此外,TiDB 提供了两套存储引擎,能够灵活适配不同的工作负载,从而提供卓越的性能表现。
两节点双活架构
TiDB 不仅可以向大规模扩展,还能够通过平凯数据库(TiDB 企业版)敏捷模式向小型场景延伸,以支持业务量较小的场景。对于数据容量小于 1TB 的场景,TiDB 敏捷模式支持 1-3 节点部署、主备及强同步,显著降低了部署成本和复杂性。例如,在某能源企业的测试中,TiDB 正是利用了这种轻量化架构,在超过 400 个风电场中,每个电场都部署了一套无人值守的主备数据库,并以容器化的方式运行。这种部署模式自动化程度高,几乎无需人工干预,极大地提升了运维效率,有效支撑了分布式边缘节点的业务需求。
TiDB 的多项关键能力
- 极致扩展:凭借存算分离架构,TiDB 的计算节点与存储节点可无感扩缩容,性能随节点增长线性提升,满足制造业领域海量数据写入场景;分布式扩展带来的 QPS/TPS 增长,以及两套存储引擎自动实时同步,可支撑半导体企业等混合业务场景。
- 性能卓越:双格式存储引擎,一套集群同时满足高并发数据更新 & 实时分析需求。且不同组件物理部署隔离,互不影响。
- 简单易用:TiDB 在开发透明性上无需应用层处理分库分表逻辑,用户可以像使用单机数据库一样编写 SQL,避免了分库分表架构的运维复杂性,降低了管理难度。
- 稳定可靠:在高可用性上,TiDB 在金融行业已得到广泛验证,支持同城多中心、两地三中心部署,如杭州银行在杭州两区及合肥部署数据库,保障灾难情况下业务连续性,某制造企业也借此实现多数据中心数据准实时同步。
- 全面诊断:除了上述关键能力外,TiDB 还拥有多样化的监控诊断工具,如 Dashboard 面板、集群运维管控平台 TEM 等,便于快速定位与修复问题。SQL 统计、慢查询展示、备份恢复等均支持可视化。
TiDB 在智能制造与能源行业的多场景实践
在智能制造与能源领域,TiDB 已在多场景成功落地:

- 某制造企业分两阶段部署 TiDB,第一阶段用一套分布式集群构建统一数据中台,汇集所有前端数据,实现全局业务视角与高可用;第二阶段计划替换前端 SQL Server,通过 TiCDC 工具实现主备集群,用两套分布式数据库支撑所有业务。

- 某光电通信领域领先企业自研的 MES 系统最初采用 MariaDB,但随着数据量激增,其在历史数据存储、报表分析及高可用性方面日益显现瓶颈,特别是在多工厂共用同一实例时,一处故障便可能影响全局生产。为解决这一难题,该企业分阶段引入 TiDB:第一阶段,将 TiDB 作为 MariaDB 的实时归档库,承接历史数据分析与复杂报表任务,从而减轻 MariaDB 的生产压力;第二阶段,完全用 TiDB 替换 MariaDB,并利用其同城三机房部署能力,成功打造了一个多中心、多活的 MES 平台。这一升级不仅解决了数据存储和性能瓶颈,更大幅提升了系统的高可用性,实现了RPO=0、RTO<30秒的业务连续性保障,确保了任何一个厂区发生故障时,其他厂区生产不受影响。
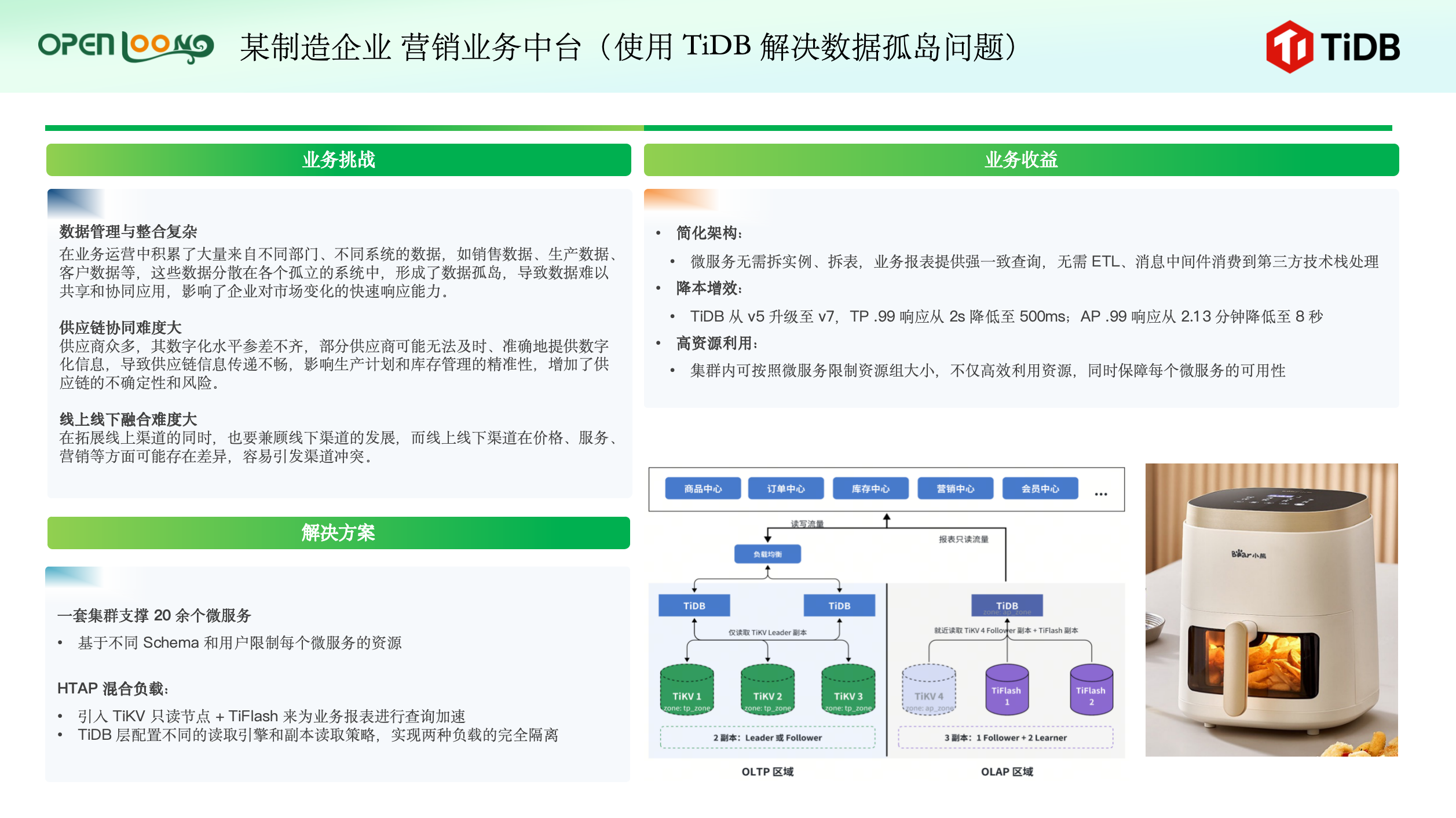
- 某制造企业曾面临各部门系统数据孤岛问题。不同业务系统(如销售、生产)的数据分散,导致协同困难;同时,供应链信息传递不畅和线上线下渠道融合也增加了业务运营风险。为解决这些问题,企业采用了基于 TiDB 的混合负载解决方案:通过一套 TiDB 集群支持超过 20 个微服务,利用不同 Schema 和用户权限实现资源隔离;并引入 TiKV 只读节点和 TiFlash 加速业务报表查询,通过配置不同的读取引擎,实现了两种负载的完全隔离。此举显著简化了数据架构,消除了跨系统 ETL 和消息中间件的复杂性,大幅提升了性能(TP 响应时间从 2 秒降至500 毫秒,AP 响应时间从 2.13 分钟降至 8 秒),并借助资源组限制实现了高效的资源利用和成本控制,最终保障了每个微服务的稳定运行。
- 某新能源汽车制造企业 OTA 系统原采用大量分库分表的单机数据库支撑 GPS 信号、车机数据等业务,虽初期通过 MySQL 分库分表解决了单库瓶颈,但面对每日近亿数据写入与新车激增,分库分表架构的动态扩展能力已难满足业务增长。该企业选择 TiDB 作为元数据底座,依托其对 MySQL 协议的高度兼容实现平滑迁移,凭借弹性扩展能力按需调整节点,并以混合负载能力同时支撑车主高并发访问与后台汇总需求。系统得以轻松应对数十万到百万辆车机管理,实现架构无忧扩展;毫秒级响应保障了车主 APP 体验,且原生分布式架构大幅降低了分库分表的开发与运维成本。

- 某省新型电力负荷管理系统面临严峻的海量数据处理挑战:需要每 15 分钟完成全终端数据采集与快速入库,年新增数据约 10TB,同时要求数据库兼具联机交易与实时分析能力,并保障业务连续性。该系统选用 TiDB 作为解决方案,凭借其 HTAP(混合事务/分析处理)能力简化了技术栈,以单一数据库同时满足 TP 和 AP 需求;原生高可用架构实现秒级灾备 RPO;弹性扩展能力支持应用无感知在线扩容,当前已轻松支撑超 50TB 数据量,并具备管理 100TB 以上容量的能力。最终方案成效显著:系统实现单表日增量 4 亿条、QPS 达 6000 的高性能表现,大幅降低开发与建设成本,确保业务连续稳定,为电网精细化负荷管理提供了有力支撑。
TiDB:面向 AI 的新一代工业数据底座

除了在传统业务场景中的应用,TiDB 还积极探索与 AI 技术的融合。TiDB 在最新版本中增加了向量存储和检索能力,使其成为一款面向 AI 的数据库,一个数据库可以同时解决关系型、向量、全文检索和图数据库等多种需求。
基于这一能力,TiDB 开源了 AutoFlow 框架,这是一个基于 Graph RAG(检索增强生成)的框架,能够快速构建企业内部的本地知识图谱。用户只需将文档和图片向量化并导入 TiDB,就能利用 TiDB 的 HTAP 和向量搜索能力,结合大模型构建自己的企业知识库,进行高效的知识检索与问答。
目前,已有 AI 企业利用 TiDB 的可扩展能力来解决其业务痛点。例如,某 AI 企业 ToC 应用的原有架构采用 PostgreSQL 分库分表,单表超过百亿行,扩展性不足。通过使用 TiDB,实现了存储和计算资源的自动扩缩容,并取得了卓越的性能,P99 延迟小于 50 毫秒,查询次数达到每秒 110 万次,存储容量达 PB 级别的同时,高效压缩率还可节省磁盘空间。
结语
作为一款原生分布式数据库,TiDB 存算分离的先进架构为未来基础架构提供了极高的上限,并具备 PB 级的弹性扩展能力。其强大的 HTAP 能力能够在一个系统内同时支持高并发的联机事务和复杂的分析查询,满足实时数据处理和洞察需求。TiDB 还支持 Data+AI,提供多模态搜索能力,覆盖各种业务场景。同时还提供了类单机数据库的极致易用性,配合完善的数据迁移和监控诊断工具,极大地降低了开发和运维门槛。这些核心优势是 TiDB 成为新一代工业数据底座的底气。
目前,全球数十家制造业和能源企业已在 TB-PB 级规模的生产环境中成功部署并验证了 TiDB 的稳定性和可靠性,充分证明了 TiDB 正以其前沿技术为智能制造和能源行业的数字化转型奠定坚实的数据基础。
对于在工作中遇到传统数据库性能瓶颈和扩展性问题的从业者,TiDB 是值得尝试的选择。TiDB 的开源文档极为全面,基于官方文档即可轻松搭建环境,快速开启体验。期待更多从业者在实践中探索 TiDB 的潜力,共同见证它在更多场景中创造价值的可能。