

问题现象
SQL:SELECT count(*) FROM (SELECT DISTINCT t1.uid FROM cdp_crm_uid_detail_basic t1 WHERE (t1.message_locale IN ( ‘en-ie’, ‘en-us’,‘ms-my’,‘en-ae’,‘en-my’,‘en-au’,‘ja-jp’, ‘de-de’, ‘zh-hk’ ) AND flt_ord_num_s IS NULL AND htl_ord_num_s IS NULL) OR ( t1.message_locale = ‘ru-ru’ AND flt_ord_num_s IS NULL AND htl_ord_num_s IS NULL AND t1.edm_discounts_subscribe = 1)) a;
Set tidb_isolation_read_engines='tidb,tikv,tiflash’时,执行计划会使用streamAgg

Set tidb_isolation_read_engines='tidb,tiflash’时,SQL 执行计划还走 tiflash 引擎,但算子变成了 hashagg ,耗时明显增加,内存开销非常高,甚至会导致 tidb 发生 OOM ,变化后的执行计划如下:

虽然表的健康度只有 67,但 SQL 只走 tiflash 引擎,应该跟 tikv 本身没有关系才对,不太理解为何调整变量 tidb_isolation_read_engines 会导致优化器的评估出现差异?
原因分析
TiFlash支持的下推算子中可以确认不带 GROUP BY 条件的列可以进入下推:
可见案例中的steamAgg在默认情况下是支持下推到tiflash的,但从session变量tidb_isolation_read_engines中去除了tikv之后,下推入口是否被挡住了。查看执行计划生成源码https://github.com/pingcap/tidb/blob/v5.1.1/planner/core/exhaust_physical_plans.go#L2362 可以确认当datasource不再有 tikv access path时会变为RootTask,RootTaskType 最终会生成不下推 agg 的计划;
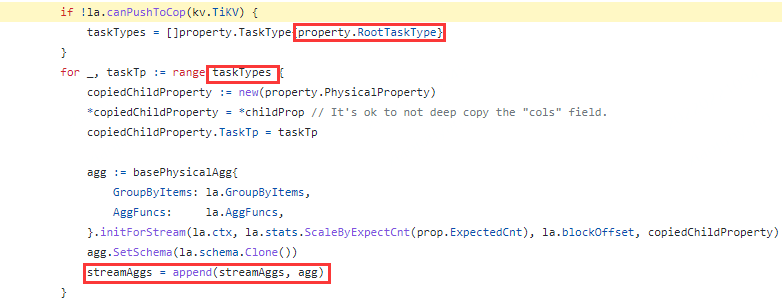
但在执行计划生成时,hashagg和streamAgg都会分别计算其下方算子子树生成何种类型的task:

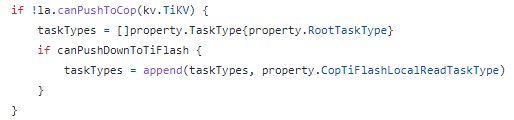
在hashAgg方法中,虽然也会受到session变量的影响,但下推tiflash的local read代价更低,因此会加入到CopTiFlashLocalReadTaskType中,https://github.com/pingcap/tidb/blob/v5.1.1/planner/core/exhaust_physical_plans.go#L2541,所以最终整个SQL在修改tidb_isolation_read_engines使用了hashAgg算子。
优化方案
影响版本:v5.0+,v5.1+,v5.2+,v5.3+,v5.4+
目前master分支已修复Bug:https://github.com/pingcap/tidb/pull/32336
临时work round:使用 hint使用tiflash 或 sql binding 固定执行计划
相关知识
- 添加TiFlash副本工作原理
https://www.modb.pro/db/152320
- TiFlash参数调优
https://docs.pingcap.com/zh/tidb/v5.1/tune-tiflash-performance