

导读
过去一年,AI 的进化速度让整个技术行业习惯了“被震惊”。从大模型(LLM)推理能力的指数级跃迁,到 AI Agent(智能体)的密集涌现,再到越来越多企业尝试将 AI 引入核心业务流程,一个行业共识正在逐渐形成:
AI 的落地不再仅仅是一个算法模型问题,更是一个复杂的系统工程问题。
而在这一系统工程中,数据库——这个看似“传统”的基础软件,正在被重新推向舞台中央。为什么?因为我们发现, 决定企业 AI 应用上限的可能是模型,但决定其能否落地、是否可信的,往往是数据底座。
以下分享内容来自平凯数据库解决方案架构师刘源在 2025 GDPS 全球开发者先锋大会上演讲实录。
AI 真正的瓶颈,不在模型,而在数据系统
回顾近几年的 AI 发展轨迹,我们看到了模型参数规模的膨胀和推理能力的持续增强。但在 ToB(企业级)场景 中 ,AI 的落地却远没有 ToC 领域那么顺畅。这背后的核心矛盾在于:
推理能力在飞跃,但“记忆”严重不足
今年广受关注的新一代模型,本质上体现的是 “通用推理能力的增强” 。 然而,无论模型如何演进,智能体(Agent)的核心能力始终包含三个维度:
推理(Reasoning):处理信息、逻辑推导(由模型主导)。
记忆(Memory):存储事实、业务状态、历史交互(由数据底座主导)。
学习(Learning):从新数据中更新认知。
幻觉的工程解法:用数据底座约束“概率的创造”
大模型本质上是一种基于概率的“有损压缩” 技术。这意味着:模型“看起来很确定”,并不代表它真的“知道”——它在回答问题时,是在预测“下一个最可能的词”,而不是在检索“真理”。
“戏精”本质:模型的表达能力往往远大于其真实的知识边界,这导致了“幻觉”的不可避免性。
企业级风险:在金融风控、医疗辅助决策或供应链优化中,一次“看似合理但事实错误”的回答,可能意味着合规风险甚至直接的业务损失。
维度 |
模型的能力边界 |
数据底座的能力边界 |
核心能力 |
推理(Reasoning):理解语义、逻辑推导、代码生成、文本摘要。 |
记忆(Memory):存储事实、业务状态、历史记录、实体关系。 |
知识属性 |
通用知识:语法规则、常识、公开的世界知识。 |
领域/私有知识:企业财务报表、客户实时状态、库存数据。 |
时效性 |
静态:截止于训练结束那一刻。 |
动态(Real-time):实时更新,反映当前世界真实状态。 |
幻觉控制 |
逻辑校验:检查推理过程是否自洽。 |
事实锚定:提供可验证的信源(Citation),确保内容真实。 |
因此,企业级 AI 对幻觉的约束,不可能只依赖模型本身。解决“事实性幻觉”的最有效手段,是让 AI 的每一次推理,都建立在可信、实时、可校验的数据之上。
- 溯源:数据来自哪里?
- 时效性:是否是最新状态?
- 一致性:是否与其他业务系统一致?
这些问题的答案,不在模型里,而在底层的数据库和数据架构中。
小结:企业级 AI 落地困难,根源在“数据底座不匹配”
为什么 AI 在 C 端应用中发展迅速,而在企业级场景却进展缓慢?核心原因在于:
- 企业数据复杂、异构
- 系统架构割裂
- 数据治理长期不足
- 私有化部署与扩展成本高

角色的重塑:数据库作为智能体的“海马体”
每一次技术变革都会重塑数据库的角色:
信息化时代:数据库是电子账本,解决“记账与事务(ACID)”的问题
互联网时代:数据库是业务引擎,解决“高并发与海量吞吐”的问题
AI 时代:数据库开始成为“推理能力的记忆体”
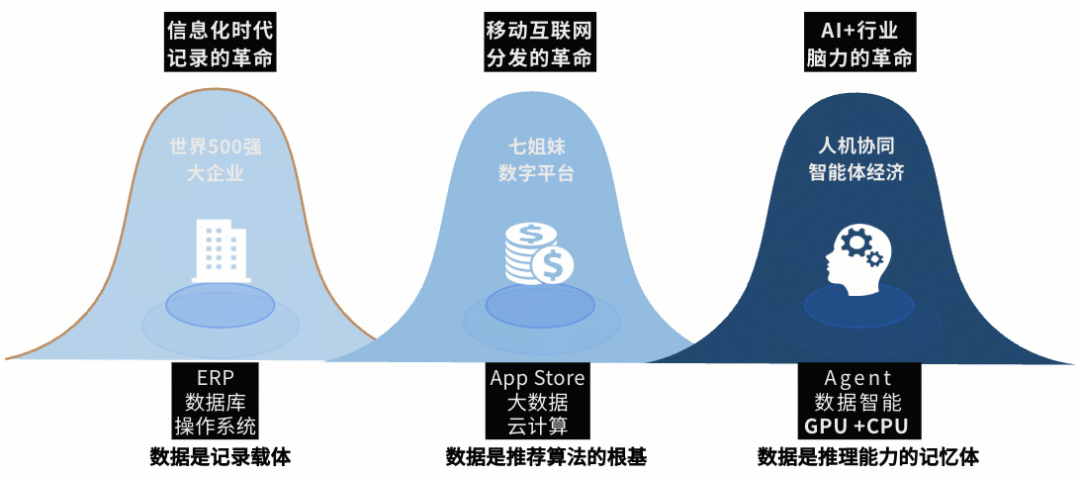
在 AI 时代,数据库不再只是一个被动“存数据的地方”,它将成为 Agent 的长期记忆 (Long-Term Memory),负责为模型提供精准的上下文(Context)。
这也对数据库提出了全新的要求。
AI 时代,对数据库提出了三项根本性要求
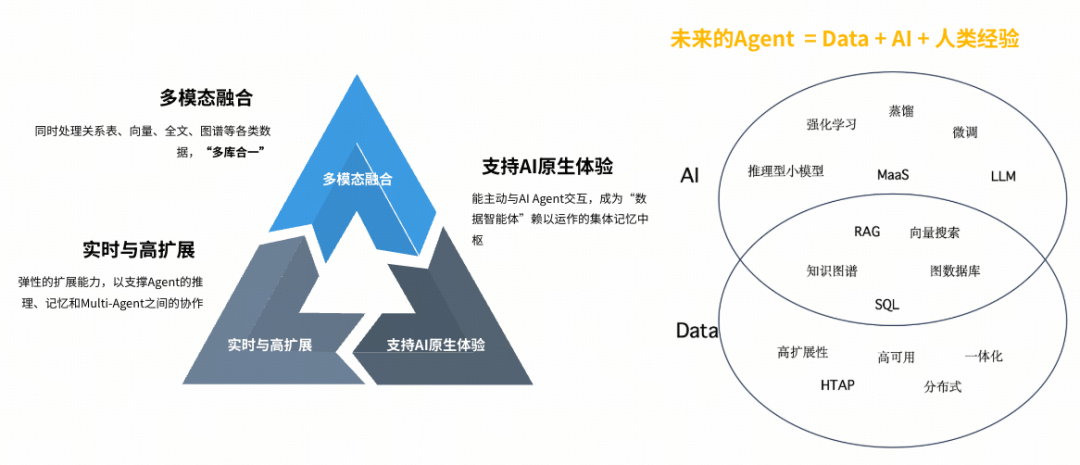
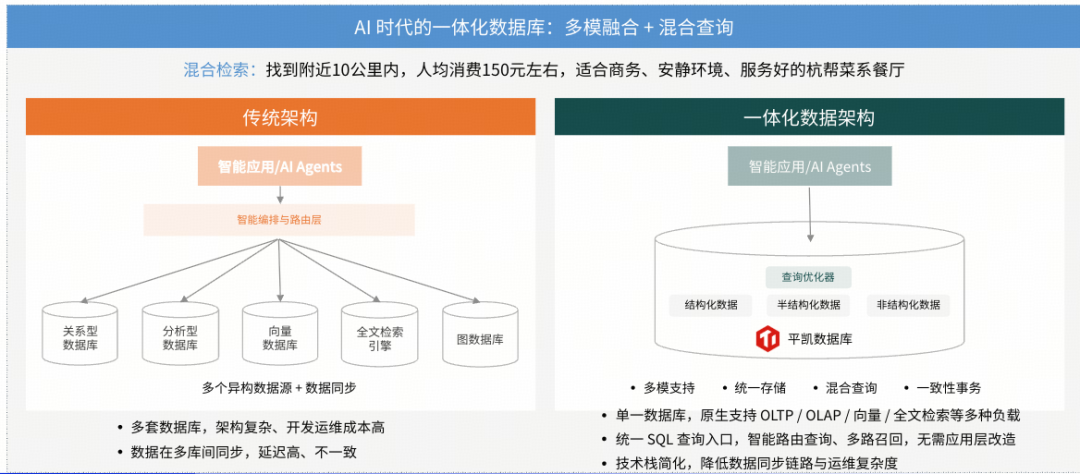
多模态融合:从“多库拼装”走向“一体化数据平台”
AI 天生是多模态的。一个完整的 AI 应用,往往需要同时处理:结构化业务数据、文档、日志等非结构化数据、向量数据(Embedding)、图关系数据,而传统架构通常需要关系数据库、分析型数据库、向量数据库、全文检索引擎、图数据库来分开协作处理。这种“多库拼装”不仅架构复杂,更带来了巨大的数据同步成本和延迟,解决一致性问题的代价极高。
AI 时代需要的是:一个数据库,原生支持多种数据模型与混合查询。
实时性与弹性扩展:应对不可预测的请求
AI 业务的负载特征具有高度的不确定性:请求模式随模型变化、读写负载高度动态。数据库必须具备:
- 在线水平扩展
- 实时分析能力
- 高并发写入能力
- 在不影响业务的情况下完成扩缩容
这已经超出了传统集中式数据库和分库分表方案的能力边界。
原生适配 AI 交互:不仅仅是加个插件
AI Agent 的行为模式,与传统程序化应用完全不同:
- Schema 经常变化
- 查询逻辑高度动态
- 一个系统内同时存在多种负载
如果数据库只是通过外挂插件来支持 AI,虽然能解决从无到有的问题,最终一定会在规模 、 稳定性 、资源隔离性面临挑战。
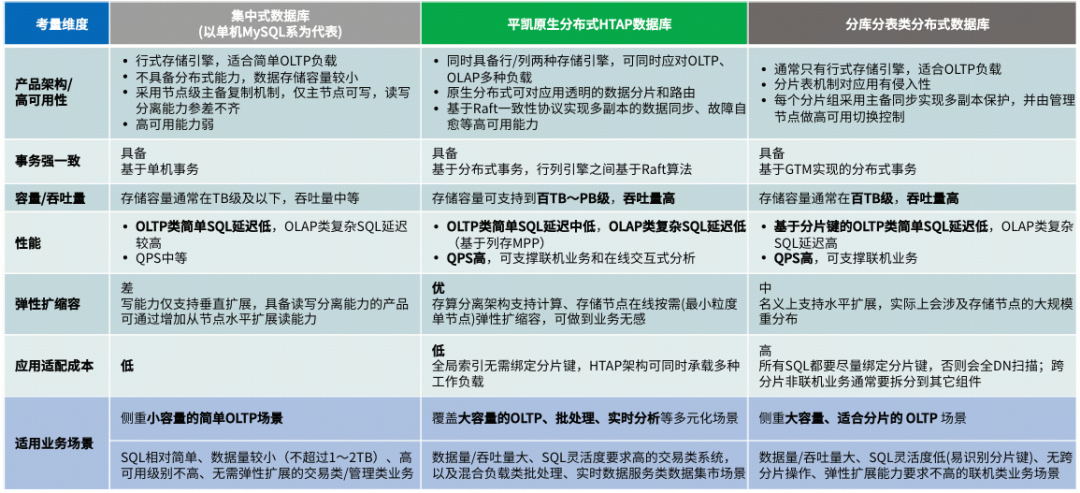
为什么 TiDB 是天然适合 AI 时代的“混合负载”底座
从设计之初,就走在正确的演进方向上
TiDB 自 2015 年诞生起,就选择了一条与传统数据库不同的路径:
- 原生分布式
- 存储与计算分离
- HTAP 架构
- 云原生设计
这些能力,并非为 AI 专门设计,但却完整契合 AI 时代对数据库的所有核心诉求。
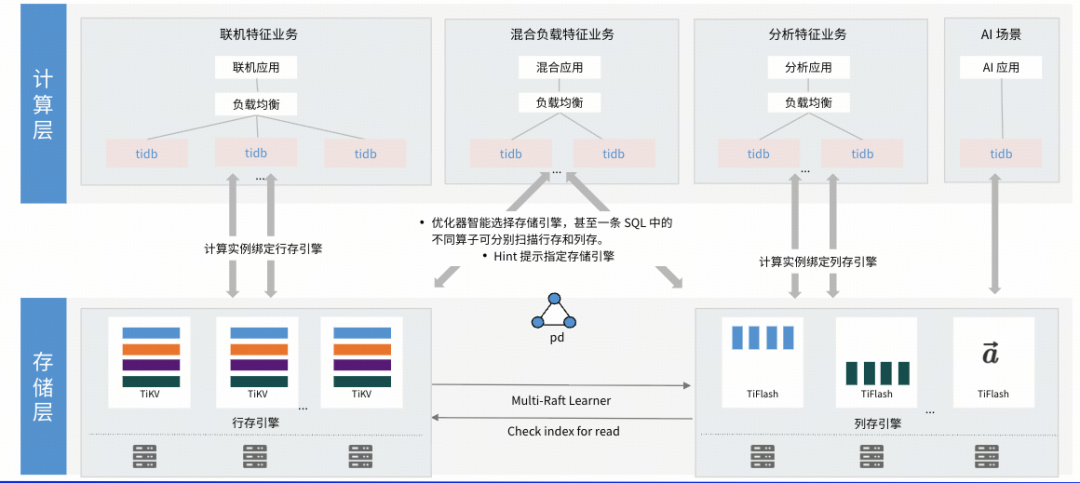
一套系统,支撑 AI 所需的绝大多数负载
TiDB 并没有将向量检索作为一个独立的孤岛,而是将其融入了 SQL 生态。 开发者可以使用熟悉的 SQL 语法,同时进行:
- OLTP(事务处理)
- OLAP(实时分析)
- 向量搜索
- 全文检索
- 图关系探索
原生向量能力,是“架构级”的优势
TiDB 在数据库内原生支持向量数据类型与索引,而不是外挂组件。这意味着:
- 向量能力天然具备分布式扩展性
- 与事务、分析能力共享一致性模型
- 能支撑海量数据规模下的向量检索

这对于 RAG、Agent 等 AI 场景至关重要。
已在真实生产级 AI 工作负载中验证
TiDB 已经在多个头部 AI 场景中承担核心数据底座角色:
- 支撑大规模 Agent 实例
- 应对用户与请求的指数级增长
- 在复杂读写混合负载下保持稳定
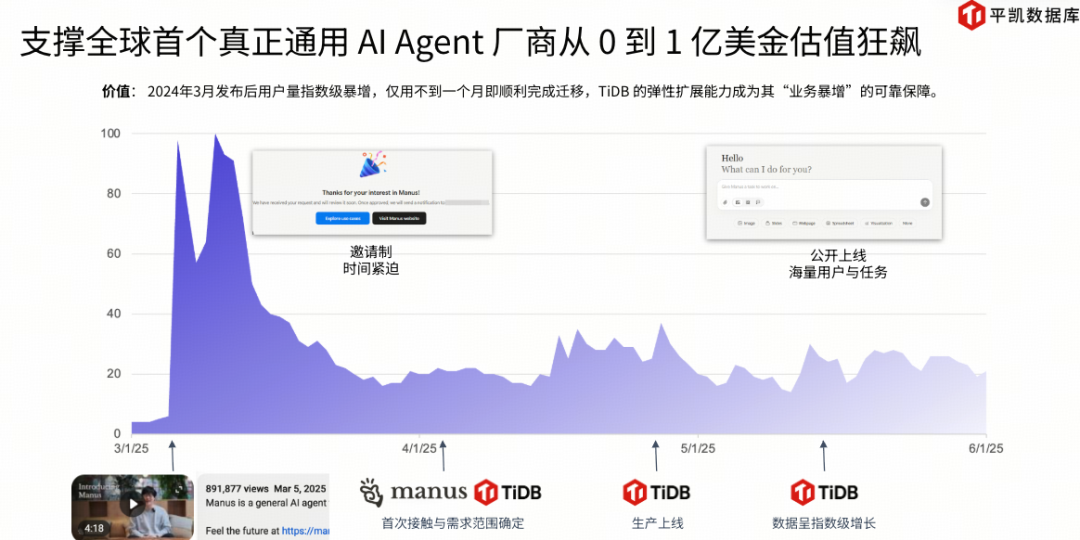
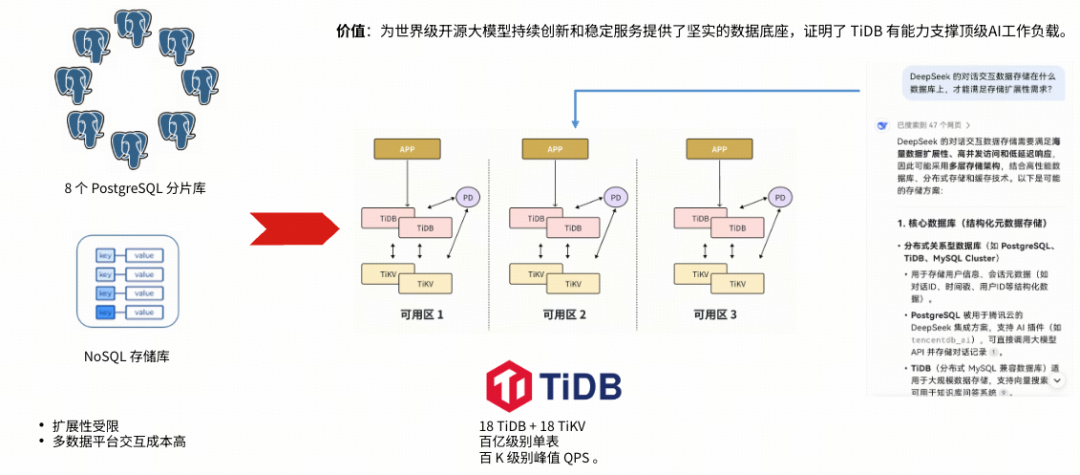
这证明 TiDB 并不是“概念上的 AI 数据库”,而是经得起真实生产环境考验的系统级基础设施。
数据库,正在从“存储”走向“智能赋能”
围绕 TiDB,平凯星辰也在持续探索更上层的 AI 能力:
- 原生支持 RAG 的数据形态
- Autoflow 等 AI 框架,降低应用构建门槛
- 打造企业级 AI 平台与行业 Agent 方案
数据库正在从“被调用的组件”,进化为 智能系统能力释放的核心枢纽。
结语:构建可演进的数据底座
AI 时代,并不是给数据库“加点 AI 功能”就够了。真正的挑战在于:
数据系统能否跟得上智能的演进速度。
TiDB 以及基于其打造的平凯数据库,让数据库从“记录系统”进化为智能体的“可靠、实时记忆体”,成为 AI 时代可信、可扩展、可演进的智能数据底座。
选择 TiDB,不只是选择一款数据库,
而是选择一个能够与 AI 时代共同进化的技术未来 :
以数据之“实”,约束模型之“虚”;以架构之“稳”,支撑应用之“变”。