

本文系北京 TUG 线下活动 “全面了解转转的 TiDB 实践” 实录,分享人:转转基础架构部负责人 陈东
大家好我叫陈东,是转转基础架构部负责人,今天为大家分享的是“业务开发对 TiDB 的使用心得”。

首先为大家介绍 TiDB 是怎么引入转转的,包括背景和具体引入过程。

TiDB 是 18 年引入转转的。原因是转转业务使用 MySQL 时遇到了一些问题,于是转转数据库负责人冀浩东就主张引入 NewSQL 数据库。
我想简单和大家分享一下 TiDB 引用、试用、内部推广的过程。
转转引入 TiDB 想解决 MySQL 的这些问题:数据量大,如何快速水平扩展存储;大数据量下,如何快速 DDL;分库分表造成业务逻辑非常复杂;常规 MySQL 主从故障转移会导致业务访问短暂不可用。
配合 DBA 启动调研后,最终选择 TiDB。

选型过程:
首先是调研测试,分为功能测试和性能测试;
然后找一个业务验证,选择一个场景去测试,看是否符合需求;
最后是业务上线。首先是涉及到数据迁移,用的比较多的是双写,之后切流量。

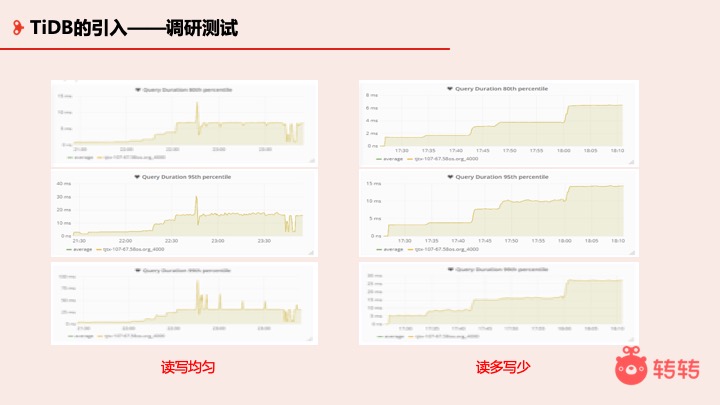
我们对 TiDB 做了一些测试,左边的这组数据是读写情况比较均匀的时候 TiDB 的性能表现,每上一个台阶并发数会高一些。右边是读多写少,比较符合互联网的应用场景,这块明显比读写均匀要好很多了,这是对 TiDB 的一个摸底。
接下来是业务场景。我们选择了电商场景下非常重要的 IM 业务来做试接入。选择 IM 的原因第一是非常相信 TiDB 这个产品,第二是相信我们自己的判断。IM 实际上是一个比较复杂的系统,比如说群消息、用户、联系人,我们就又疯狂了一把,选择了最复杂的业务——联系人。选择它的原因是根据测试数据发现 TiDB 在读写均匀的情况下性能会下降。联系人的收发都伴随着许多读写,属于读写比较均匀的业务,如果这个业务都没问题,大部分场景应该都可以适应。我们验证的步骤是:第一步是构造数据从线上扒一份数据拉到线下,再自己写数据去模拟线上流量。
看右边的三个图,最上面只有 MySQL 时的情况,很多毛刺。接入 TiDB 后延时变高,但是平滑,对业务体验更好。如果从性能角度来说, TiDB 在单个场景下很难比得过 MySQL,但在吞吐量大的情况下,不管写入怎么样,TiDB 都很平滑,这就是我们选择 TiDB 很重要的一个原因。

测试合格之后就是上线,数据迁移先主从同步,再双写迁移。
我们的方法是:先拉一份从库到 TiDB,再保持主从同步,当数据追齐之后开双写(我们一般用 MQ),之后可以观察一下,没问题切读流量,一点点分比例切,最后再把写切过去,这样业务就基本上线。

接下来和大家说一下我们使用 TiDB 时遇到的一些问题和应对办法。

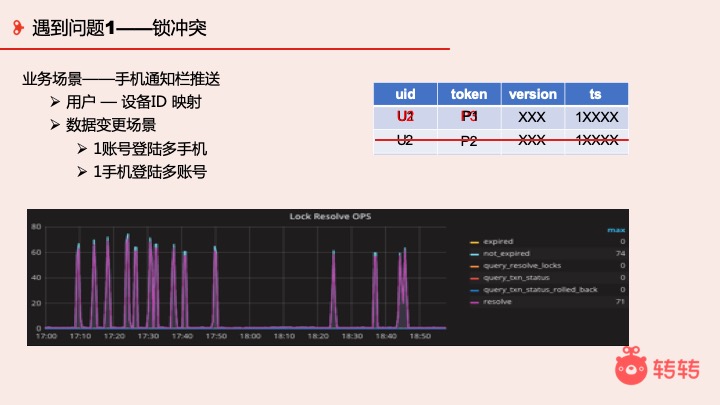
首先向大家介绍一个场景,手机推送。需要我们维护一个用户 — 设备 ID 的映射关系,因为推送是基于设备 ID 的,业务场景是 UID — 设备 ID — 第三方服务。
数据变更场景有 1 个账号登录多个手机也有 1 个手机登录多账号的情况。之前用 MySQL 的时候的时候,有的手机取不到设备号,我们会写个默认值。迁到 TiDB 后发现了一个奇怪的场景,默认值这条记录会被频繁并发更新。我们的解决方式是业务进行优化,过滤默认值数据,但根本原因在锁这块。

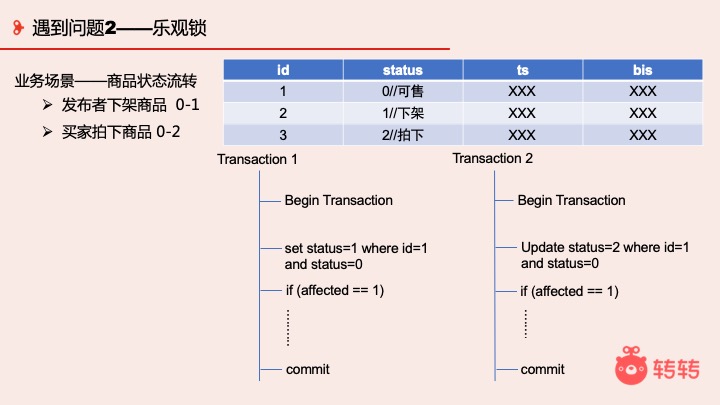
还有一个是乐观锁的问题。比如商品状态的流转场景,发布者发布商品后状态是 0,发布者可以把商品下架,状态从 0 变成 1。但是买家想买商品的话,拍下后状态从 0 变成 2。我们来看一下这两张表的事务:
第一个事务 Begin,我想把它下架既状态设成 1,同时用 where id=1 and status=0 做条件,才能下架成功,同时判断我影响的行数是不是 1 条,是的话就 Commit
第二个线程是买家,他想把状态更新成 2,他也判断是不是影响了 1 条行数,是的话就 Commit。
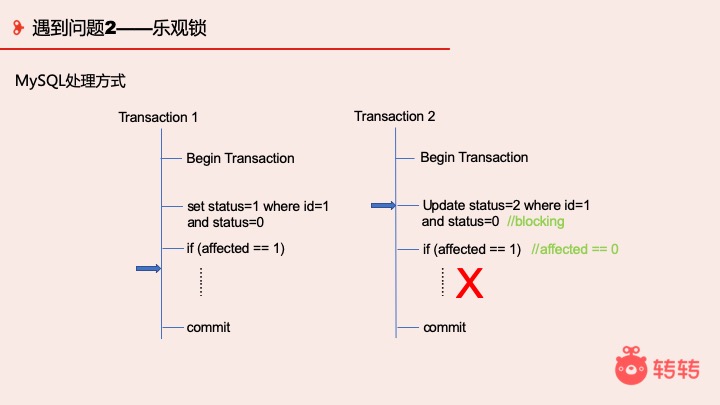
MySQL 的处理方式是:
假设这一时刻,线程 1 执行到左图蓝箭头处,线程 2 执行到右图蓝箭头处,线程 2 想提交 update 时就会被锁住。等线程 1 Commit 之后线程 2 发现影响记录不是 1 条, 线程 2 更新失败,商品下架不能购买。
TiDB 的处理方式是:
因为TiDB 不是行级锁,是乐观锁,先 Commit 看能不能成功。左边 Commit 成功,右边就会因为有冲突 Commit 失败。
我们遇到的问题场景是:万一我需要发 MQ 或做RPC 记录怎么办?买家买下商品后生成订单要 RPC,但是事务 Commit 失败了,RPC 回滚不了。

TiDB 在开启一个事务的时候,我的一段读写操作都是有缓存的,所以在提交的时候才去判断是否成功。
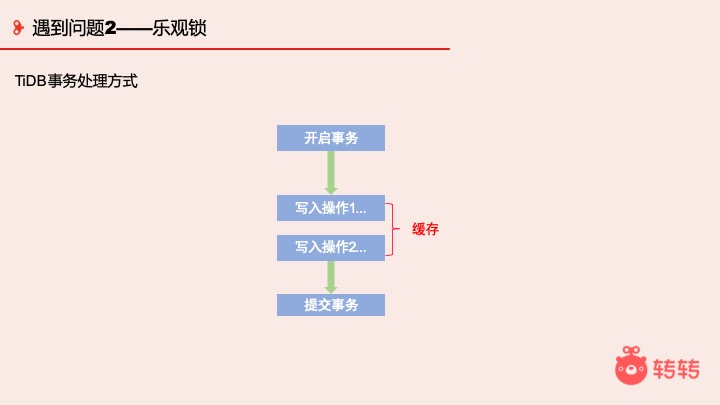
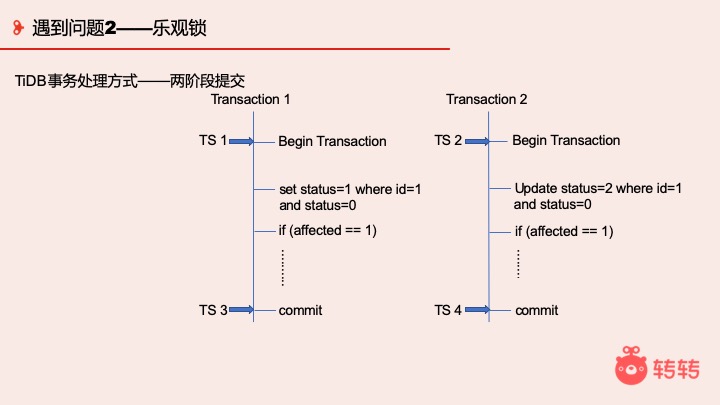
这里想和大家聊的是事务的实现方式 — 两阶段提交。

假设 TiDB 的处理方式是:TS1 线程 1 开始,TS2 线程 2 开始,TS3 线程 1 提交,TS2 线程 2 提交。谁先开始不重要,关键是谁先提交。
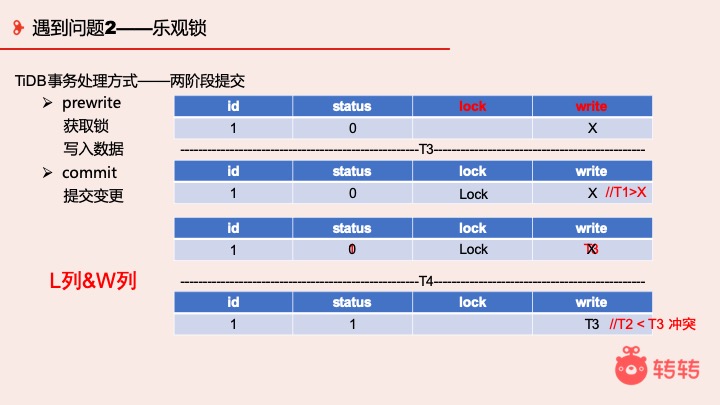
它的实现方式其实就是 L 列和 W 列,我也尝试去研究了一下,但是发现真的很复杂,我尽量简化模型。
假设我有一个表,它有一个 status。我为了实现这个事务会给它额外两列,一个 lock 一个 write。lock 列可以锁一些行,write 列可以写一些更新的信息。 线程 1 尝试提交的那一刻先尝试加锁, 如果发现数据没被加锁,则判断 W 列的时间戳是不是大于 X,如果大于就有冲突,都没问题就加锁。加完锁以后,就要写数据,写完之后更新时间戳 T3,提交事务,然后释放锁。
第一步先 Prewrite,加锁写数据,然后再 Commit 提交变更。
TS4 是 2 事务提交时间,2 事务开始时间小于 TS3,提交时发现 TS2 < TS3,有冲突,这个事务就不能提交。
知道这个原理之后我们怎么做呢?在数据库层并发可能会出问题时,业务就把它串行化处理

最后一个部分是对未来的展望。

业务方面想把 TiDB 与 MySQL 互补, 根据数据量和应用场景选择和使用 TiDB。

陈东老师分享就此结束,如果你有任何问题,欢迎到评论区留言提问。
9 月 22 日,北京 TUG 将带大家走进爱奇艺,聊聊数据库技术选型那些事儿,欢迎大家点此报名。
相关阅读: