

(20点55分)告警ing
周五下班后,准备好(欢)好(度)休(周)息(末),没曾想在晚上 8 点 55 收到 TiKV 节点物理机宕机的告警:face_vomiting:
(20点56分)自行排查:
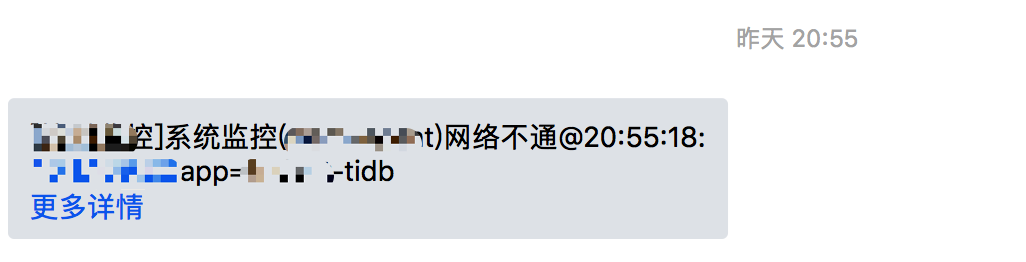
一脸错愕之后,立刻打开 TiDB Dashboard查看,发现 tidb-server 的QPS、Query Duration都没有出现明显波动。
-
QPS
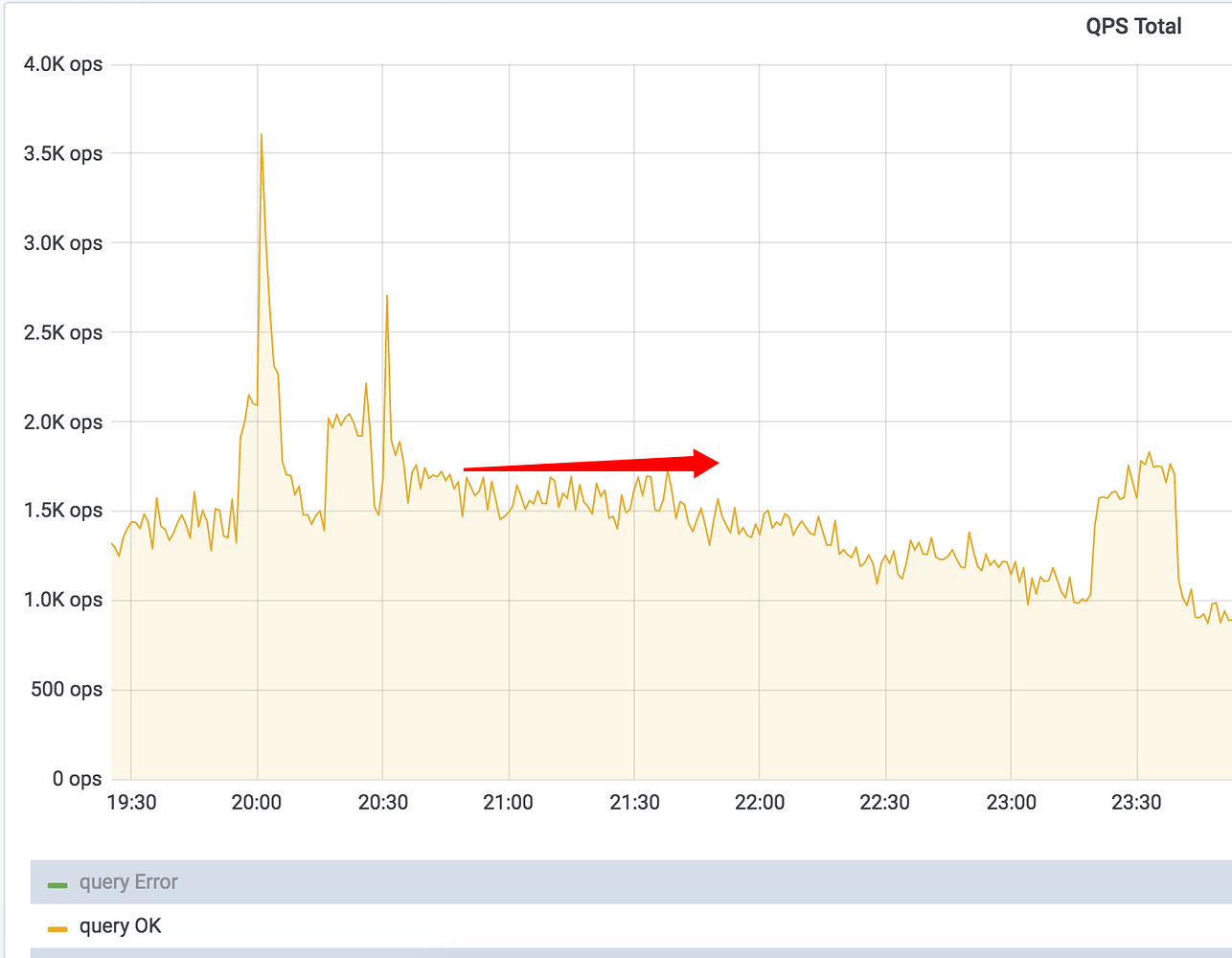
-
Query Duration 99th
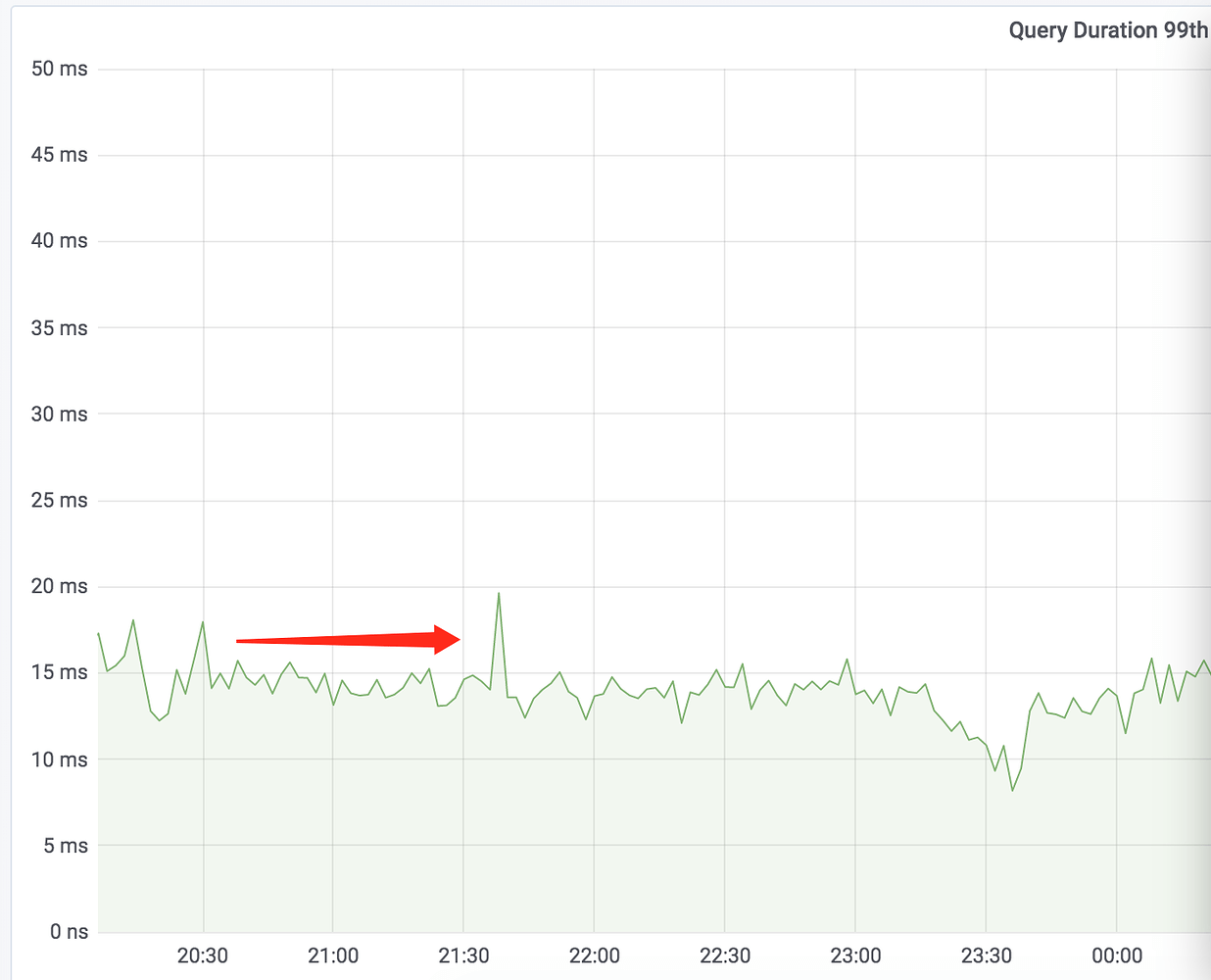
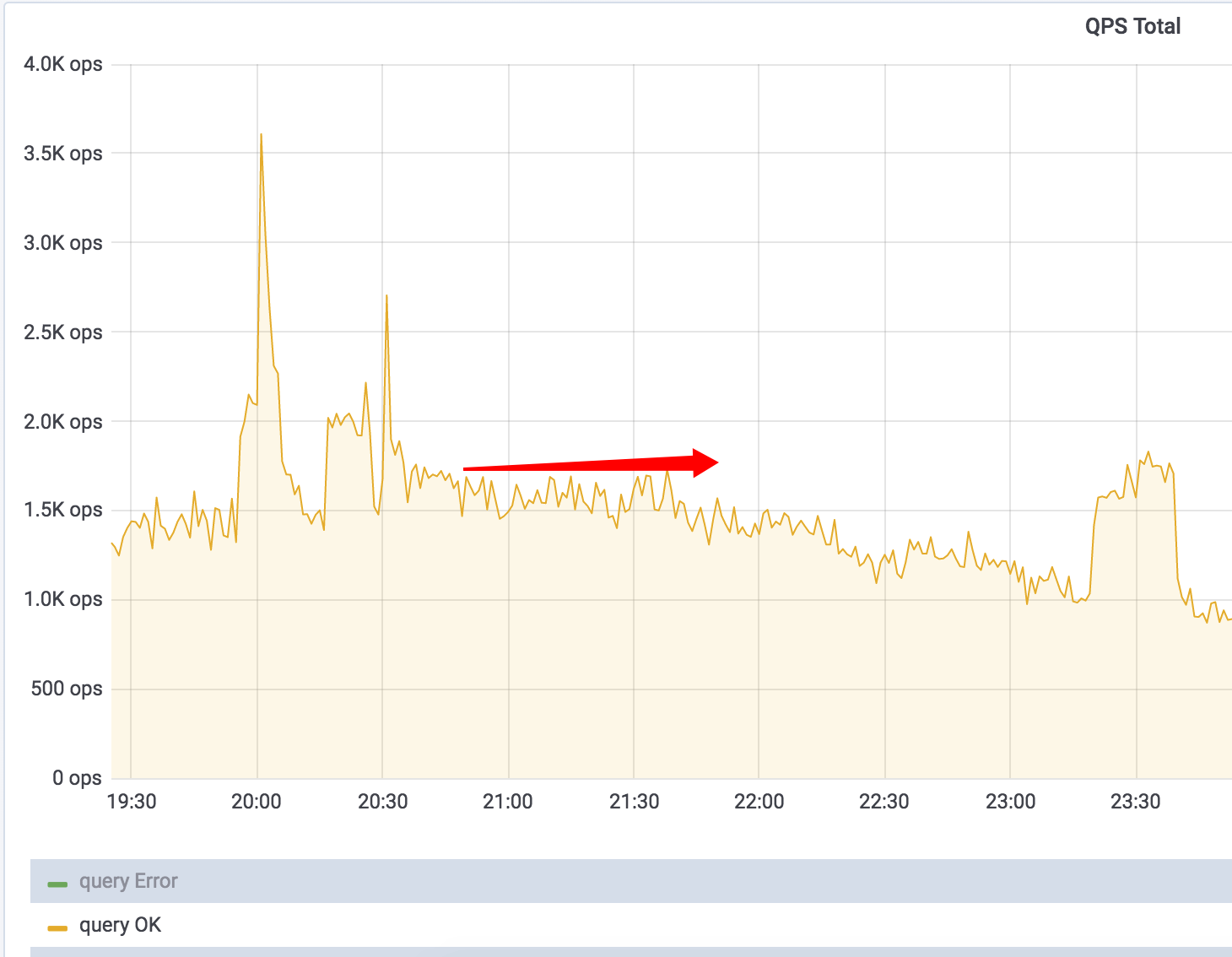
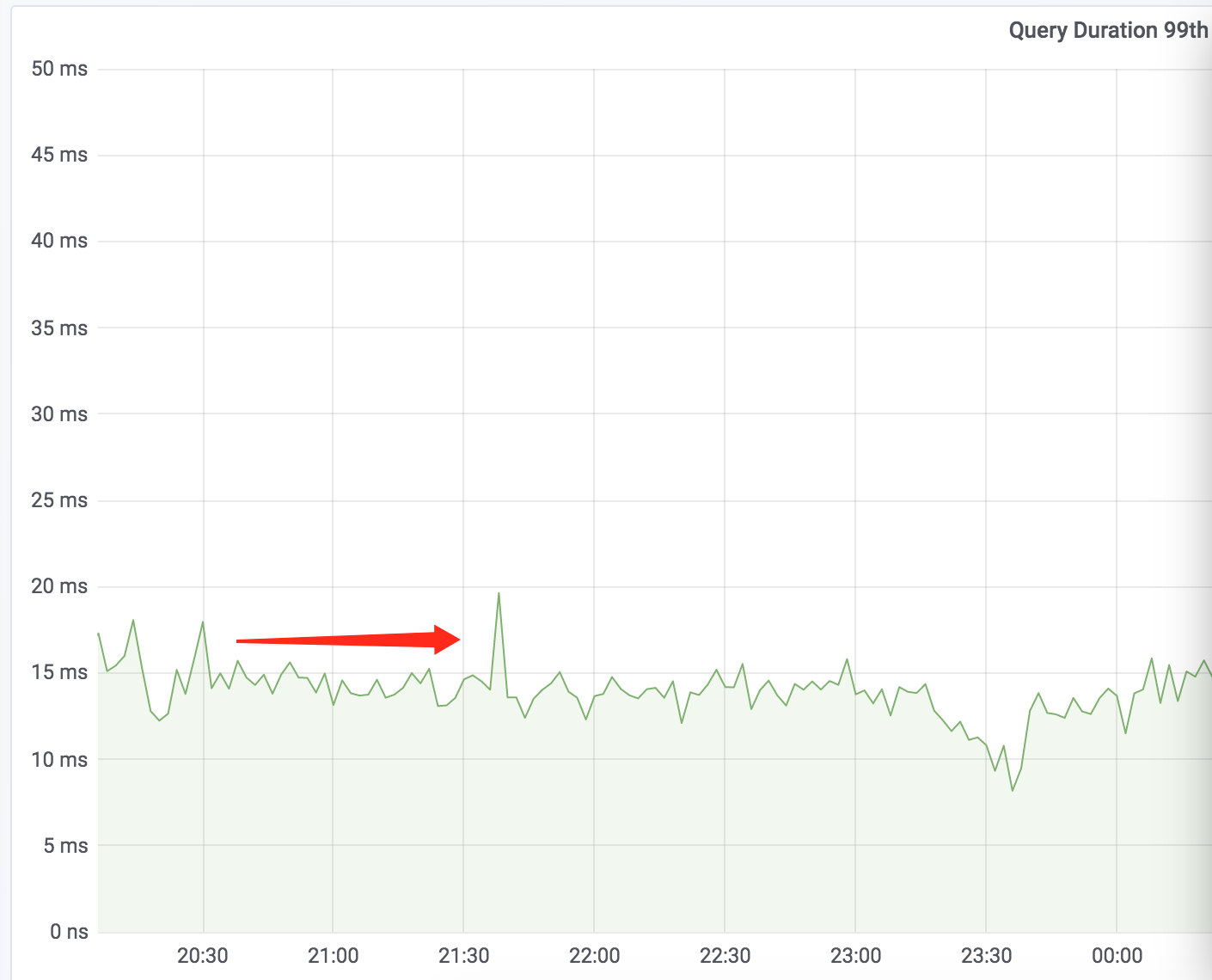
看来,TiKV 单个节点宕机,对整个 TiDB 集群几乎无影响,感觉可以慢慢排查,不慌(内心OS:tidb高可用做的真香!)。
从公司运维同事那里得知宕机的机器黑屏无响应,大约半小时后通过重启,机器恢复正常。于是,登录到机器上通过 start_tikv.sh 尝试启动该 TiKV 节点,启动之后,发现 TiKV 并没有对外提供服务,通过pd-ctl 查询该 TiKV 的状态,一直显示“Down”,进一步查看节点的 tikv.log,发现有大量的 Error 信息:
2019/08/16 21:18:12.445 panic_hook.rs:97: [ERROR] thread 'raftstore-1300116' panicked '[region 1376839] 1376842 to_commit 15084386 is out of range [last_index 15084384]' at
...
2019/08/16 21:18:42.386 panic_hook.rs:97: [ERROR] thread 'raftstore-1300116' panicked '[region 1360081] 1360084 to_commit 340143 is out of range [last_index 340141]' at
...
职业敏感性让我感到可能 TiKV 节点损坏了,对关键字做 Google 搜索,发现 TiDB 官方 Repository 里有一个issue#4731在讨论这个问题,按照 Issue 中@BusyJay 的说法,尝试在 pd-ctl 中删除该节点:
store delete 1300116
继续观察发现节点的状态立刻从“Down”变成了“Offline”,但等了一段时间,节点的状态也没有从“Offline”状态变成“Tombstone”,看来1300116号节点无法下线。通过执行命令:
operator show
也没有看到有任何将1300116号 TiKV上的 Region 搬迁到其他 TiKV 节点的调度操作,因此:一个“Down”掉的 TiKV 节点可能无法强制下线。
(21点45分)向 PingCAP 工程师求助
排查到这一步,感觉需要向 PingCAP 官方求助,将错误日志信息发给 PingCAP 工程师@张曾钧,很快收到了反馈,原因确实是宕机掉电导致了文件损坏,错误信息的意思是:
Peer 想要 commit 一条不存在的日志, Raft Log 因为掉电丢失了
在 PingCAP 工程师@张曾钧的建议下,先用如下命令将1300116号 TiKV 状态重置为“Down”:
curl -X POST http://${pd_ip}:2379/pd/api/v1/store/${store_id}/state?state=Up
然后,使用 tikv-ctl 工具做 bad-regions 的检测:
$ ./tikv-ctl --db /data6/tistack/tikv/data/db bad-regions
all regions are healthy
多次检测之后,都得到了all regions are healthy的结果,与预期不符。这里算是个小疑问。
进一步沟通之后,决定先从 tikv.log 中统计出所有 bad region 的信息,再做进一步的操作。可以通过如下命令统计出日志中出现的 bad region 的 ID 以及频次:
grep panic tikv.log | grep region|grep -oP 'region [0-9]*'|sort|uniq -c
将统计出来的region逐一从1300116号 TiKV 删除,例如:
operator add remove-peer 1376839 1300116
operator add remove-peer 1360081 1300116
删除所有的 bad region 之后,尝试 start_tikv.sh 启动 1300116 号 TiKV 节点,发现节点顺利启动了,状态也从“Down”转变成“Up” (内心OS:牛X!感谢!),1300116号 TiKV 节点顺利恢复服务。
疑问和总结:
几点疑问:
- 1、tikv-ctl 工具检查不出 bad regions,但实际上日志里面是有打印相关 region 信息的,和 PingCAP工程师@张曾钧 沟通,可能是 tikv-ctl 版本问题。
- 2、1300116号 TiKV 节点顺利从宕机中恢复服务之后,通过在 pd-ctl 中检查缺失副本数的 region 情况:
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length != 3)}"
发现有大量的 region 处于 2 副本状态:
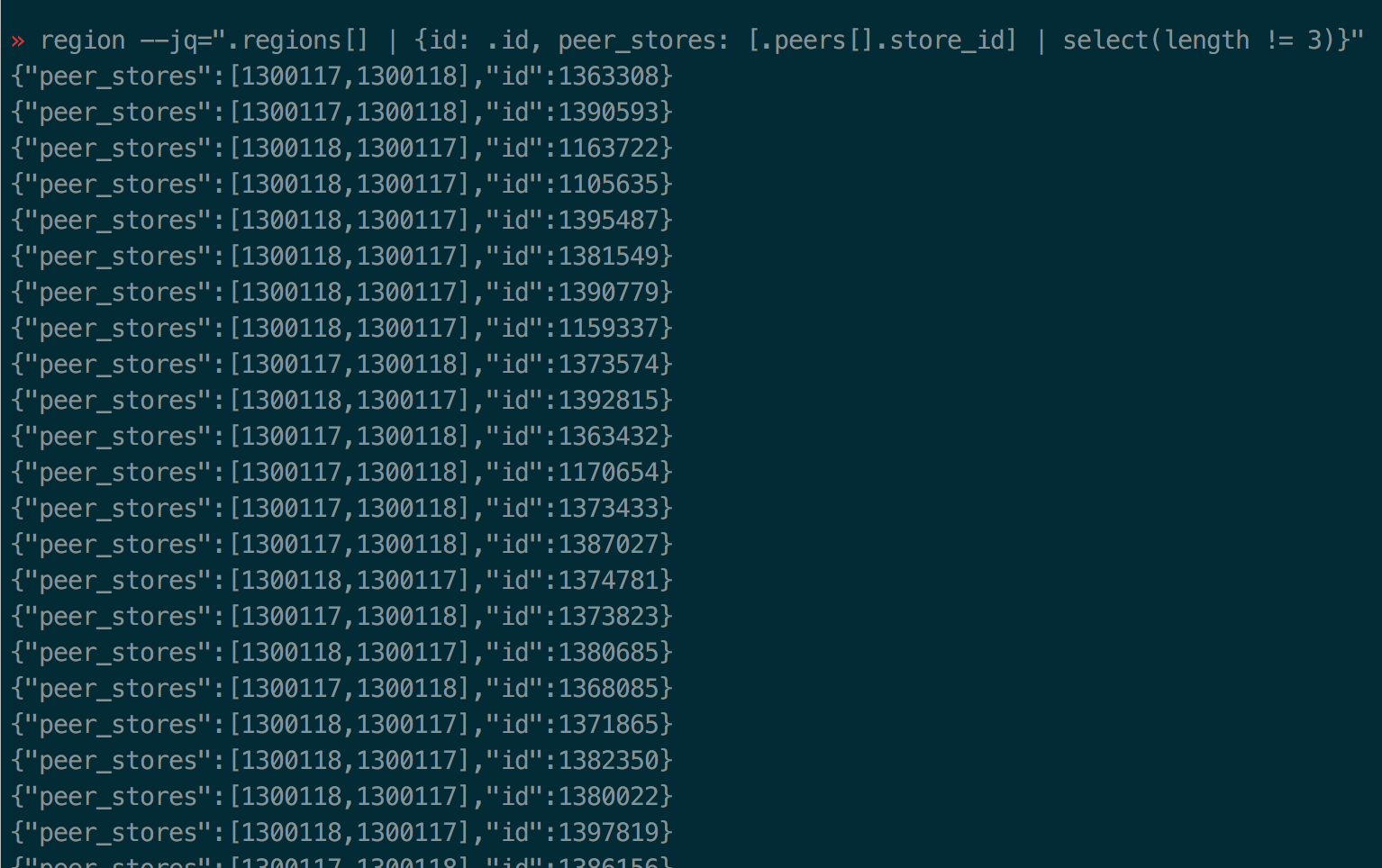
通过 operator show 并没有查看到有补副本的操作。这里对 PD 补副本的调度有疑问。 通过如下命令手动触发了补副本的操作:
operator add add-peer 1376839 1300116
operator add add-peer 1360081 1300116
几点总结:
- 1、建议将 TiKV 的日志级别设置为 “error”,“info”或者“warn”级别,都会产生过多的日志,特别是在比较繁忙的集群上,会干扰问题排查。
- 2、强烈建议将 sync-log 设置为 true,减少宕机后出现 Raft Log 丢失导致数据受损的风险。