

背景
前段时间线上的tidb集群,偶尔收到告警tikv节点报CPU使用率超过80%,也有业务方反馈tidb集群上的业务SQL偶尔会变慢,正常情况表都是毫秒级别的,并且慢的时间点和tikv CPU使用报警的时间点都吻合,这个集群的业务一直在增加,并且已知的有几个SQL是表扫,所以基本可以确定是tikv节点CPU瓶颈了,tikv集群在原来的3台基础上扩容了4个节点,扩容完成后发现各个节点的region分布比较均匀,但是leader分布就很不均匀,新加的4个节点上leader要比原来3台上的leader少很多,如下图:
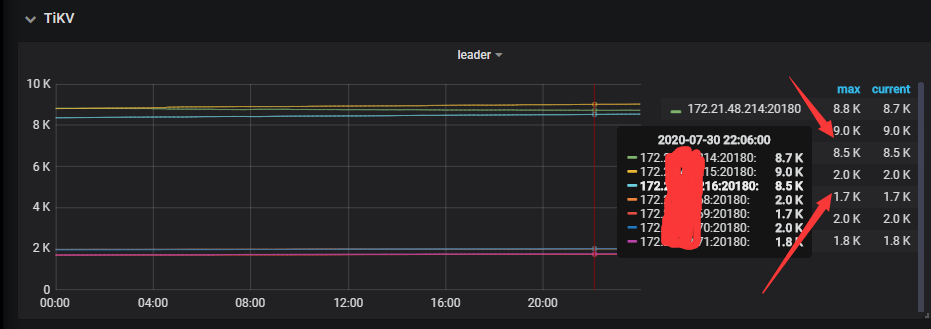
集群版本:3.0.14
问题定位
- 因为缺少相关经验,定位过程走了不少弯路,针对上面问题的定位,通过下面方法基本直接可以定位到问题
- 查看各个tikv节点的leader_weight、region_weight值是否均匀,如果每台tikv的配置都一样,正常情况下,那每台的值应该是相等或者相近的
./resources/bin/pd-ctl -u http://172.21.xx.213:2379 store --jq=".stores[].status | { leader_weight,region_weight}"
{"leader_weight":1,"region_weight":1}
{"leader_weight":1,"region_weight":1}
{"leader_weight":1,"region_weight":1}
{"leader_weight":1,"region_weight":1}
{"leader_weight":5,"region_weight":1}
{"leader_weight":5,"region_weight":1}
{"leader_weight":5,"region_weight":1}
./resources/bin/pd-ctl -u http://172.xx.48.213:2379 store --jq=".stores[].store | { id, address, state_name}"
{"id":179309,"address":"172.xx.49.69:20160","state_name":"Up"}
{"id":179310,"address":"172.xx.49.71:20160","state_name":"Up"}
{"id":179311,"address":"172.xx.49.70:20160","state_name":"Up"}
{"id":179312,"address":"172.xx.49.68:20160","state_name":"Up"}
{"id":1,"address":"172.21.xx.216:20160","state_name":"Up"}
{"id":4,"address":"172.21.xx.215:20160","state_name":"Up"}
{"id":5,"address":"172.21.xx.214:20160","state_name":"Up"}
热点问题定位知识扩展
- 通过监控定位热点问题
- 判断写热点依据:打开监控面板 TiKV-Trouble-Shooting 中 Hot Write 面板(如下图所示),观察 Raftstore CPU 监控是否存在个别 TiKV 节点的指标明显高于其他节点的现象。
- 判断读热点依据:打开监控面板 TIKV-Details 中 Thread_CPU,查看 coprocessor cpu 有没有明显的某个 TiKV 特别高。
- 通过pd-ctl获取热点region的信息
./resources/bin/pd-ctl -u http://172.xx.48.213:2379 hot read 或者write
{
"as_peer": null,
"as_leader": {
"1": {
"total_flow_bytes": 99986218, #这个store总的流量
"regions_count": 4, #这个store热点的region数量
"statistics": [
{
"region_id": 21945, #region的id
"flow_bytes": 7671153, #这个region的流量
"hot_degree": 193, #表示 region 是持续热点,每分钟上报 1次,如果是热点,degree+1
"last_update_time": "2020-08-03T07:37:37.240263801+08:00", #最近一次上报时间
"AntiCount": 1,
"Version": 3963, #记录region分裂的次数
"Stats": null
},
、。。。。
},
- 跟进上面获取到的region ID定位是哪张表,是表数据还是索引
curl http://172.xx.xx.50:10080/regions/21093
- 如何判断一张表的region leader 分布是否均已
python scripts/table-regions.py --host 172.xx.49.50 --port 10080 base task
- 通过tikv的日志找到热点表的region ID和table ID
cat tikv.log |grep "2020/07/31 16:" |grep slow-query|grep "table_id"|awk '{print $21,$30}'|grep "9719"
- 通过表的ID查找表名
select * from information_schema.tables where tidb_table_id=9719
或者
curl http://{TiDBIP}:10080/db-table/{tableID}
- 大region定位,主要关注approximate_size(单位是MB),approximate_keys(这个region key的数量),当region的大小超过200MB算是大region了,可以通过下面方法拆分
[tidb@prod01 tidb-ansible-prod]$ ./resources/bin/pd-ctl -u http://172.xx.48.213:2379 region topsize 1
{
"count": 1,
"regions": [
{
"id": 31649, #region的ID,用这个ID做region拆分
"start_key": "7480000000000015FF7700000000000000F8",
"end_key": "7480000000000015FF775F728000000000FF01B2810000000000FA",
"store_id": 5
},
"approximate_size": 143,
"approximate_keys": 1182536
}
]
}
-
4.0的流量热力图定位热点杀手锏
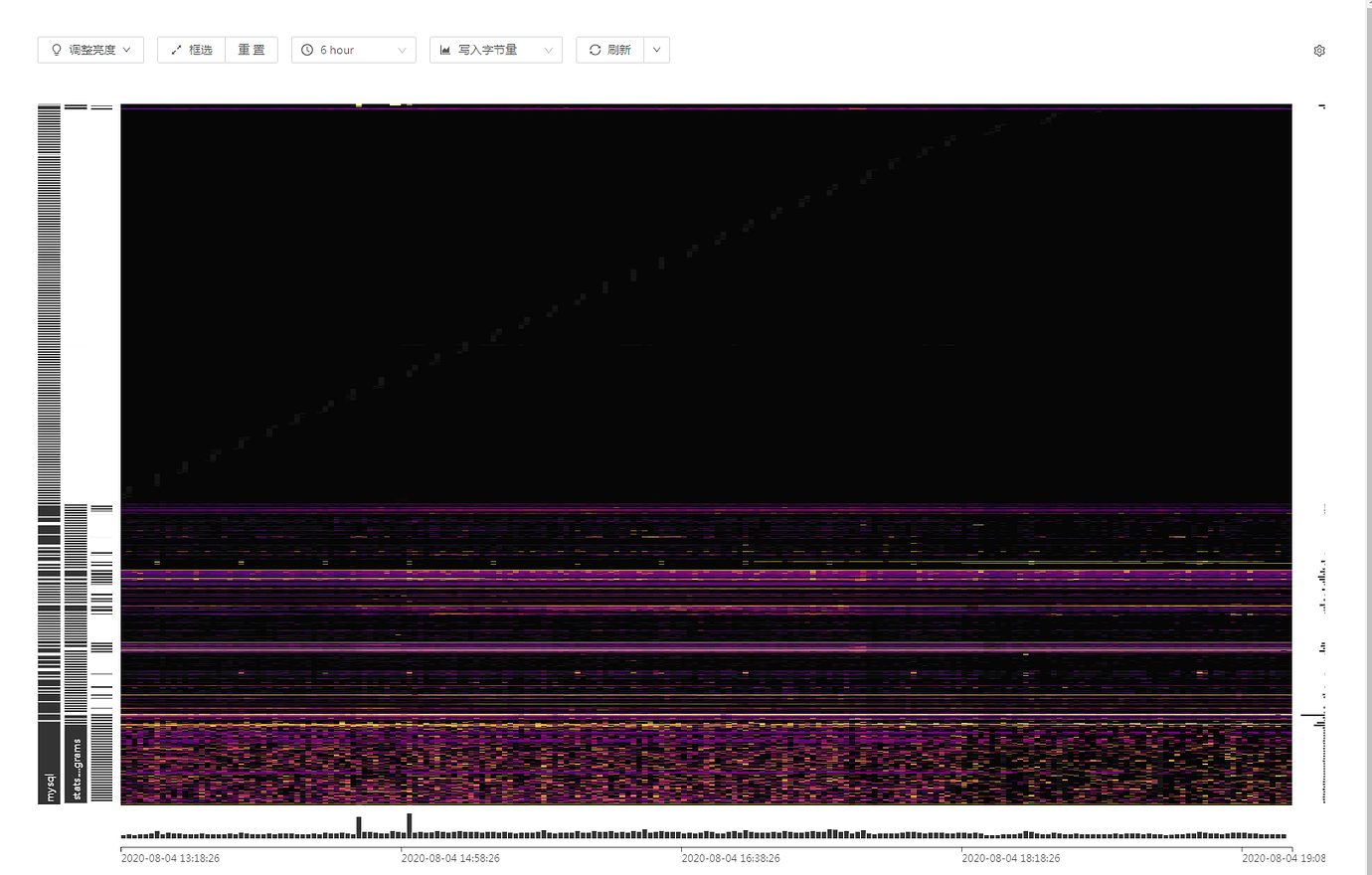
如何解决
- 通过人工干预,调整各个tikv节点的leader weight值,让其各个节点相等
- 查看tikv的ID和地址的对应关系
./resources/bin/pd-ctl -u http://172.xx.48.213:2379 store --jq=".stores[].store | { id, address, state_name}"
- 设置 store id 为 179309 的 store 的 leader weight 为 5,Region weight 为 1
./resources/bin/pd-ctl -u http://172.xx.48.213:2379 store weight 179309 5 1
- 把热地region或者大region拆分
- 把ID为252868的region对半拆分成两个region
./resources/bin/pd-ctl -u http://172.xx.48.213:2379 -i
operator add split-region 252868 --policy=approximate
- operator add split-region 1 --policy=approximate // 将 Region 1 对半拆分成两个 Region,基于粗略估计值,消耗更少的 I/O,可以更快地完成。
- operator add split-region 1 --policy=scan // 将 Region 1 对半拆分成两个 Region,基于精确扫描值,更加精确
参考文档
https://book.tidb.io/session4/chapter7/hotspot-resolved.html
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues

作者:李坤,PingCAP 互联网架构师,TUG Ambassador,前美团、去哪儿数据库专家。 背景 从现有的数据库使用场景来看,随着数据规模的爆发式增长,考虑采用TiDB这种分布式存储的业务,通常都是由于触发了单机数据库的瓶颈,我认为瓶颈分为3点:存储瓶颈、写入瓶颈、读取瓶颈。我们希望TiDB能够解决这3个瓶颈,而存储瓶颈是可以首先被解决的,随着机器的扩容,存储瓶颈自然就可以几乎线性的…
https://pingcap.com/docs-cn/v3.0/pd-control/

性能问题排查常用操作 基本原则 应用压测目标 当前机器拓扑和资源下 测试出压测程序压测 TiDB 集群,QPS 和 TPS 的 “天花板” 平均响应时间和最高响应时间满足需求 常见优化思路 热点优化,当前主键热点可以使用 shard bits 的方式进行优化 对于索引热点暂时无法优化,后期可以使用离散列做分区表,可以解决该问题 业务逻辑冲突优化,比如会有同时修改一行的场景。 按照压测场景…