

简单梳理下 OLTP 数据库(MySQL)和分布式数据库(TiDB)不同的 DDL 发展历程。
一. MySQL - DDL
MySQL 的 DDL 也是经历过了多次变更升级,知道 5.6 版本才引进了 Online DDL。
1. Mysql 5.6
这个版本,MySQL 允许大多数 DDL 语句与 DML 语句并行执行,初步实现了 Online 的特性。
整个 DDL 可以分为三个阶段,Initialization, Execution, Commit Table Definition 。其中元数据是通过 MDL(Metadata Lock)来进行保护的。
Initialization
初始阶段,主要是分析 DDL 语句,确定执行计划,这个阶段会持有表的 shared MDL。
Execution
进入 Execution 阶段,需要获取排他的 exclusive MDL,等完成准备工作后,降级为 shared MDL,期间允许读写操作。
降级前的准备工作包括:
- 等待该表上的事务全部结束;
- 创建Rowlog;
- 写元信息;
- 分配 Leaf 和 NonLeaf 段;
- 创建 Root;
在允许读写并行的时候,所有新事务所涉及的变更都会写入 RowLog,RowLog 切分为多个小块,增量数据始终写入最后一块。同时开始索引构建流程,将全量数据排序后填充到索引中。
填充完成后就要开始顺序应用 RowLog,在应用 RowLog 的最后一步,禁止表上的写入操作。
Commit Table Definition
这个阶段还需要获取一次 exclusive MDL 锁,完成元数据更新后释放 MDL 锁,整个流程结束。
2. 5.6 Online DDL 的特点
会在几个时间段上排它锁:
- Execution 初期 和 Commit 阶段短暂获取 exclusive MDL,禁止表上的读写操作
- Execution 阶段应用最后一块 RowLog 时,禁止目标表上的写操作
从这个功能实现来看,Online DDL 会出现以下问题:
- 如果DDL执行之前有长事务,那会阻塞后续这个表上的所有请求,从而导致后续的请求全部堆积起来,打满连接;
- 数据回填期间虽然降级成 shared MDL,允许读写,但是业务高峰期执行还是有风险,并不能实现真正的 Online。
3. Mysql 8.0
8.O 又优化了一部分 DDL 操作,比如新增了快速加列 INSTANT 功能。
INSTANT 只会修改数据字典中的元数据,在准备和执行阶段,不会对表加 metadata lock ,因此操作可以很快完成,而且期间允许并发 DML。
但这个功能只能应对加列这种场景,如果遇到 add a secondary index 的场景是用不了 INSTANT 的。
加索引 8.0 官方操作指南:

再贴一个 5.7 版本的:

4. MySQL 总结
随着 MySQL 版本的迭代,DDL 的便捷度确实在一步步提升,到了8.0的快速加列功能帮很多 DBA 简化了日常的工作。有些时候不放心官方的 ONLINE DDL,我们还可以使用 gh-ost 和 pt-osc 来进行 DDL 变更。
相信 MySQL 之后的版本会继续优化 DDL 操作。
二. 分布式数据库 DDL
分布式数据库一般由3台以上的服务器组成集群,每个节点都会缓存 schema 的信息,如果设计方案使用的是单节点的 DDL 方案,需要通过外部的分布式锁来保证一致性,确保加载新版本 schema 新的时候没有读写的并发操作。另外如果集群内机器通信出现问题,DDL 将无法完成。
1. 分布式下可能出现的情况
1.1 索引有多余数据
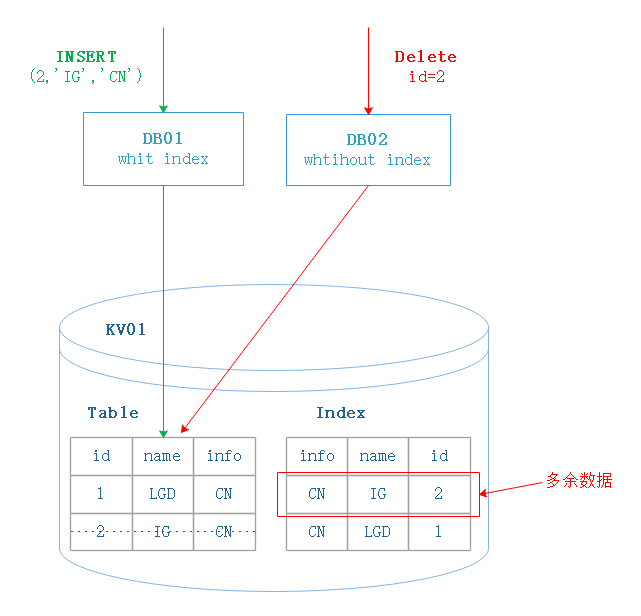
DB02 的 schema 信息处于无索引状态
DB01 的 scheam 信息处于有索引状态
- DB01 有一条 insert,插入了数据和索引;
- DB02 执行 delete,删除了该条数据,因为 DB02 认为 table 没有索引,所以不会去删除对应的索引记录;
- 最终结果,表数据已删除,但是索引未删除;
1.2. 索引缺少数据

DB02 的 schema 信息处于无索引状态
DB01 的 scheam 信息处于有索引状态
DB02 上有 insert 请求,数据可以正常插入,但是它的 schema 版本是在无索引状态,所以不会去插入索引数据,导致索引缺少数据的情况发生。
2. 分布式下的解决方案
目前市面上分布式数据库 DDL 的实现都是基于 Google F1 提出的方案。该方案引入了两个重要的中间状态 delete_only 和 write_only
该论文定义了以下几个 states:
-
absent: an element is not present in the schema
-
public: an element is present in the schema, and it can be affected by or applied to all operations
-
delete-only:
- 适用于 table, column, or index
- 无法被事务读取
- 对于 table or column 只允许 delete 操作
- 对于 index 只允许 delete 或 update,且 update 操作仅从索引上删除记录,不增加新的记录
-
write-only:
- 适用于 column, index
- 无法被事务读取
- 允许 insert, delete, and update
再来看下基于中间状态是如何解决索引有多余数据和索引缺少数据这两个问题的:
2.1. 索引有多余数
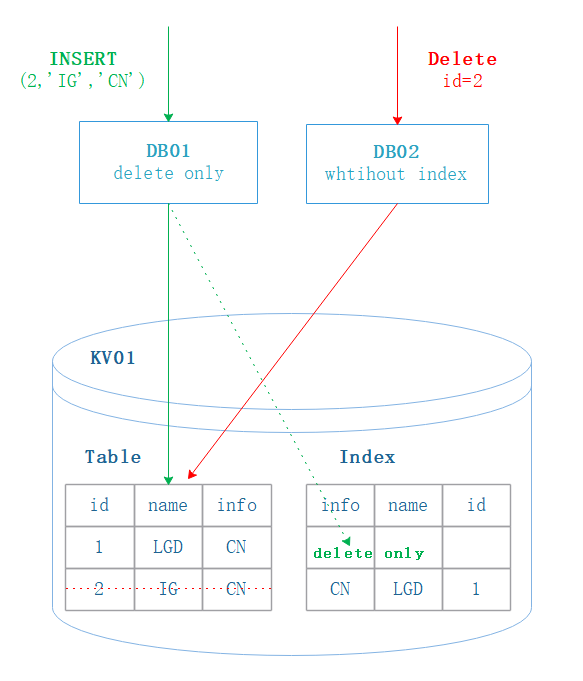
DB02 的 schema 信息处于无索引状态
DB01 的 scheam 信息处于 delete only 状态
当 DB01 处于 delete only 状态时,只会在表上插入数据,不会创建索引数据。DB02 认为该表没有索引,也只会删除表中数据。因此 DB01 和 DB02 最终处于无数据无索引的状态。
2.2. 索引缺少数据
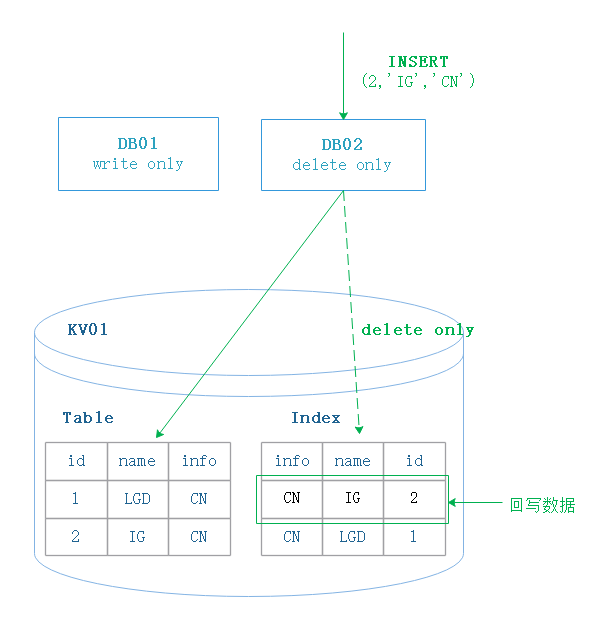
DB02 的 schema 信息处于 delete only 状态
DB01 的 scheam 信息处于 write only 状态
DB02 认为索引处于 delete only 状态,只会插入数据,没有写相关的增量日志。当所有节点都更新为 write only 状态后,数据回填操作会在索引中填入这一条数据。
3. 小结
总结一下,Google F1 方案增加两个中间状态(delete_only,write_only),然后允许集群中的事务同时使用至多两个最近的元数据版本。
保证最多两个版本是通过租约 lease 实现的,会保证在一个租约周期内,没有拿到最新版本 Schema 的节点,无法提交事务。
三. TiDB - DDL
之前测试了下 TiDB,觉得 DDL 这块做的还是非常不错的,现在简单梳理下 TiDB DDL 操作。
https://github.com/pingcap/tidb/blob/master/docs/design/2018-10-08-online-DDL.md
先贴下官方文档,想详细了解的,可以看下官方文档,介绍的非常详细。
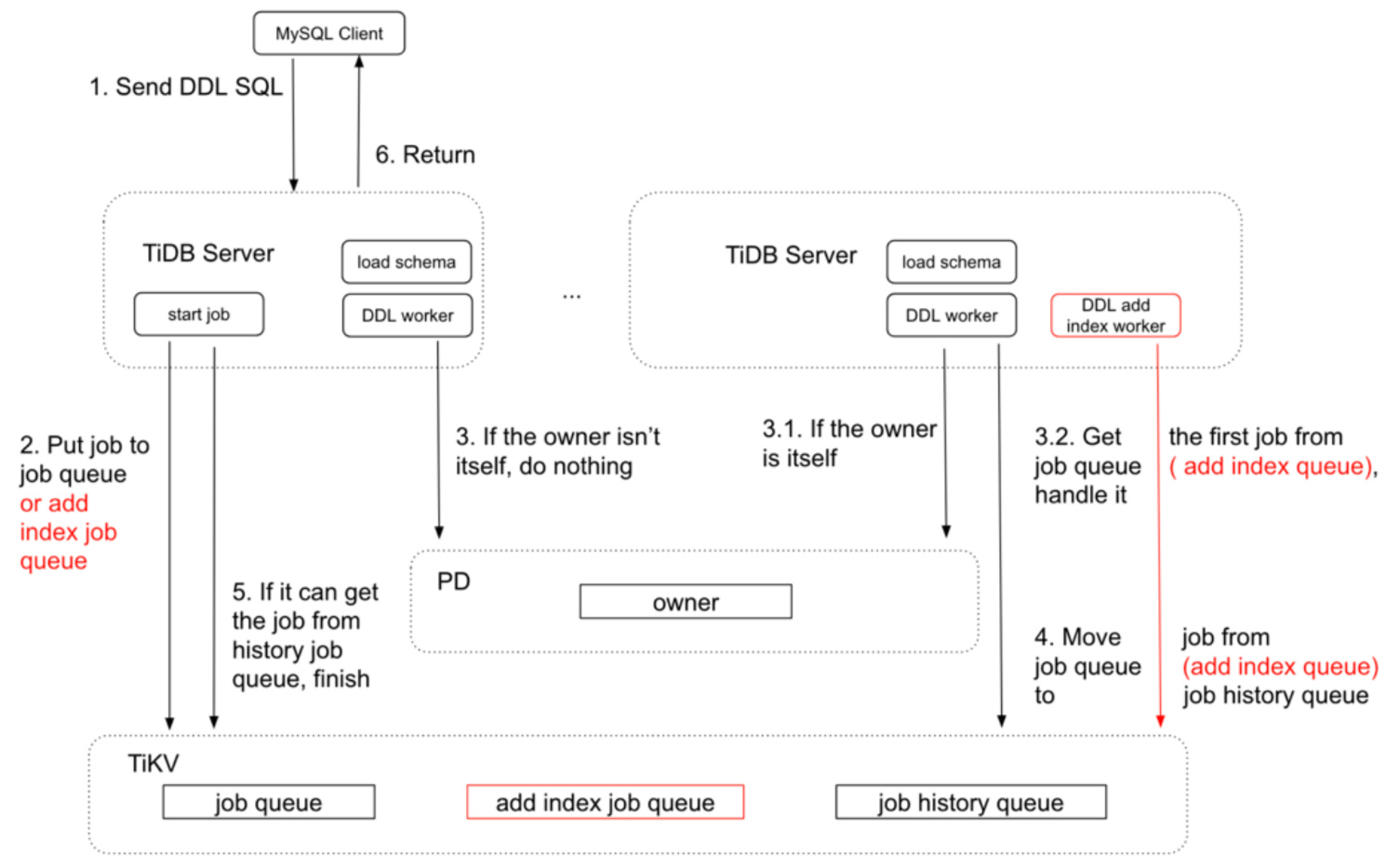
1. TiDB-DDL 架构及流程
TiDB 的 DDL 主要有以下几个重要部分:
-
组件
- TiDB,更新和加载 schema 信息
- TiKV 存储 schema 信息和 DDL job
- PD 通知 schema 版本信息
-
角色
- Owner
- 非 Owner
-
模块
- 处理 DDL 任务:worker
- 加载 schemma
-
状态
- none
- delete only
- write only
- write reorganization
- public
DDL 流程
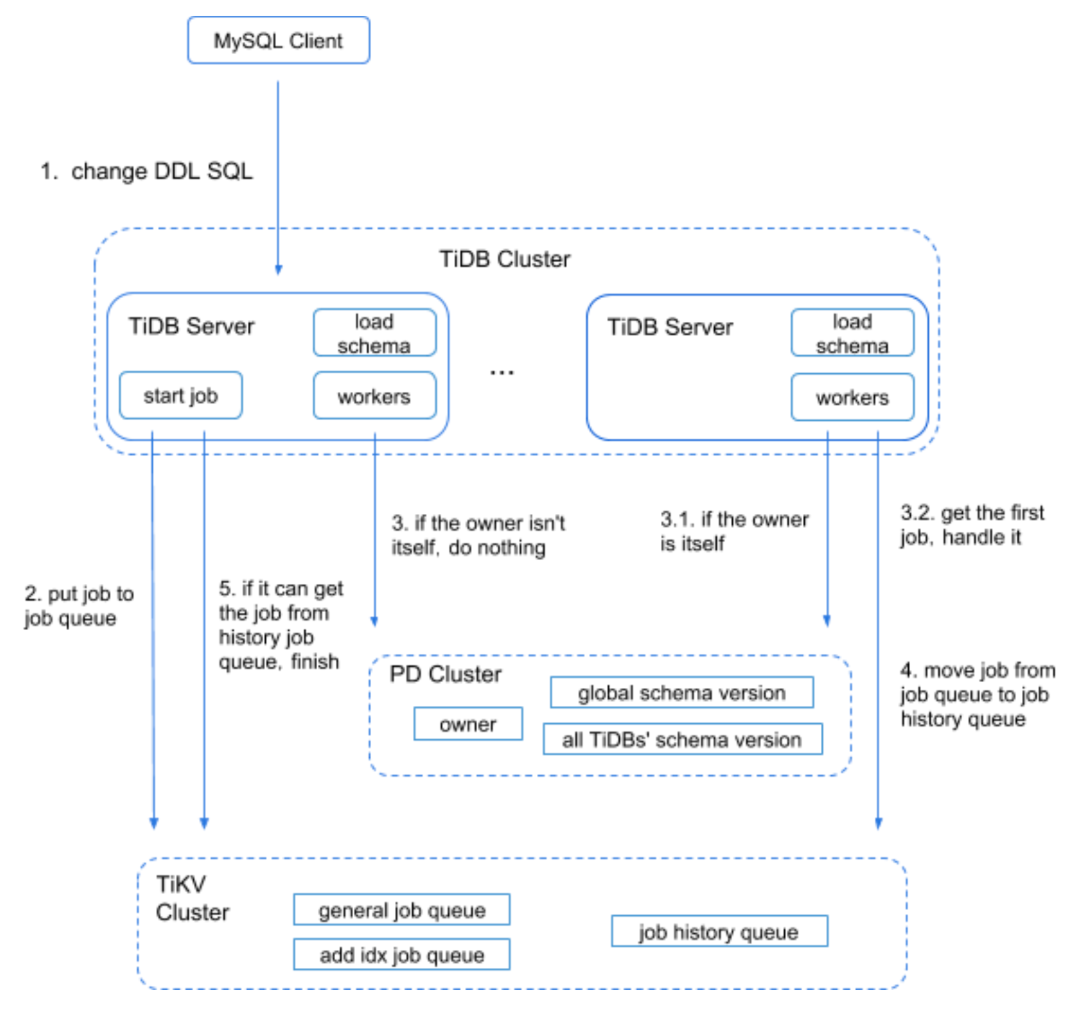
-
DDL 请求发到 TiDB 集群;
-
把请求转化为一个 job ,发到 TiKV 集群上;
-
每台 TiDB 判断当前是不是 Owner 的角色,如果不是不做任何操作
3.1 如果是 Owner,进行下一步操作
3.2 获取 job 信息,更新 schema 版本信息
-
如果没有其他 job 了,会把当前 job 从队列中删除,然后移至历史队列;
-
可以从历史队列获取到 job 了,返回给客户端完成信息;
并行流程
TiDB 只有创建索引操作耗时比较久,因为要去 TiKV 写数据。因此创建索引操作可能会阻塞其他 DDL 操作。
在不同表之间,可以并行执行创建索引操作和其他操作,比如 a 表增加索引,b 表新建列,这两个操作是可以并行的。
并行队列只分为两个,如上面的流程图 general job queue 和 add idx job queue
并行 DDL 处理流程:
2. 各类 DDL 操作
2.1. add column
优化:
- 将新添加的列的默认值保存到名为原始默认值的字段中;
- 在之后的读操作中,读取此列中的数据,如果 TiKV 读取此列的值为 null 并且此默认值字段中的值不为空,则次默认值将填充到相应列中并返回。
2.2. modify column
限制:
- 仅支持整形类型之间的修改,字符串类型之间的修改以及 blob 类型之间的修改,并且只能延长原始类型长度
- 不支持更改 unsigned 属性
简单来说,不支持有损变更
2.3. drop index / column / table / database
这些操作不关心表中数据行数,只需要更改整个过程中对应的几个状态。
在正常的处理完此类 DDL job 后:
- 将有关已删除数据的信息存储到 gc_delete_range 表中;
- 然后在 GC 阶段进行处理;
所以 drop 操作后,磁盘空间不会立马释放。默认的 GC 处理时间建个为 10 分钟。
2.4. add index
add index 这块涉及比较多,需要详细了解的,可以去官方文档看一下。
3. TiDB-DDL 运维
3.1. DDL 耗时
add index 操作耗时:
- 取决于表中的数据,因为需要读取数据行数,然后建索引写入 TiKV;
- 也取决于系统负载;
- 空表时耗时在 3s 左右(worker 和 owner 是否在同一个 TiDB 上,不在的话需要去历史队列里面找 DDL job);
其他 DDL 操作:
- 耗时大多数少于 1s
3.2. DDL 执行慢
一般来说 TiDB 中执行 DDL 速度是比较快,如果遇到执行慢的问题,可能是以下原因造成的:
- 多个 DDL 语句一起执行;
- 正常启动集群后,第一个 DDL 操作的执行时间可能会比较久(owner 的选举)
- TiDB 不能与 PD 正常通信,比如 kill -9 停 TiDB 导致 TiDB 没有及时清理注册数据
- 某个 TiDB 与 PD 或者 TiKV 出现通信问题,导致 TiDB 不能即使获取最新的版本的信息
3.3. TiDB DDL 限制
与 MySQL 相比,TiDB 的 DDL 还是有些不一样的地方的。
- 不能在单条 ALTER TABLE 语句中完成多个操作。MySQL 下往往会把多个同一张表的 DDL 进行合并,然后使用 gh-ost 或者 pt-osc 工具一次性跑掉。TiDB 里只能一个个单独去执行;
- 不支持不同类型的索引 (HASH|BTREE|RTREE|FULLTEXT);
- 不支持添加/删除主键,除非开启了
alter-primary-key配置项; - 不支持将字段类型修改为其超集,例如不支持从
INTEGER修改为VARCHAR,或者从TIMESTAMP修改为DATETIME,否则可能输出的错误信息Unsupported modify column: type %d not match origin %d; - 更改/修改数据类型时,尚未支持“有损更改”,例如不支持从 BIGINT 更改为 INT;
- 更改/修改 DECIMAL 类型时,不支持更改精度;
- 更改/修改整数列时,不允许更改 UNSIGNED 属性;
大部分操作可以通过前期建表规则来规避掉。
另外 ANALYZE TABLE 和 MySQL 也有些区别:
TiDB 中的信息统计 与 MySQL 中的有所不同:TiDB 中的信息统计会完全重构表的统计数据,语句执行过程较长,但在 MySQL/InnoDB 中,它是一个轻量级语句,执行过程较短。
四. 总结
之前还简单看了下 OceanBase DDL 这块的实现,它的 ObServer 都同时具备存储和计算的功能,保存有一份元数据拷贝,可以在任务转发过程中判断两端的元数据版本是否一致。总结下就是:
- 元数据分为多个版本
- 一个事务内的所有 SQL 都发到相同 ObServer,避免语句级别的元数据版本回退导致数据不一致的问题
- 事务中的语句需要访问的 ObServer 的元数据版本与 RootService 不同时对语句进行重试
再贴一张产品对比图,更加直观:
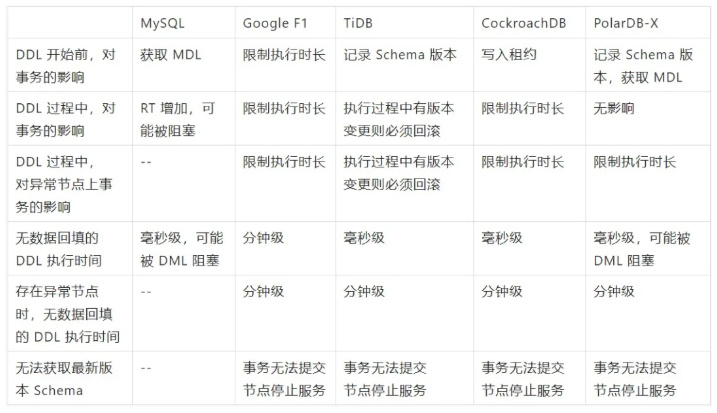
单机数据库 schema 只有一个版本,只能通过加锁来避免 DDL 和 DML 并发导致的数据问题,然后通过缩小加锁范围来实现 online change 的特性。
而分布式数据库引入了中间状态,允许系统中至多同时存在两个 Schema 版本,再结合租约特性,实现分布式的 DDL。