

什么是热点问题
说这个话题之前我们先回顾一下TiDB的主要结构和概念。
TiDB的核心架构分为TiDB、TiKV、PD三个部分,其中TiKV是一个分布式数据存储引擎用来存储真实的数据,在TiKV中又对存储区域进行了一系列的逻辑划分也就是Region,它是被PD调度的最小单元。熟悉TiDB的读者对这个结构应该了然于胸。
正是由于这种设计,TiDB在碰到短时间内的大流量时就会碰到数据热点问题,大量的数据被写入到同一个Region Leader导致某一部分TiKV节点资源消耗特别高,而其他节点又处于空闲状态,这种情况明显是违背了分布式系统的设计初衷。TiDB为了避免这种情况的发生,官方已经给出了成熟的解决方案,比如提前切分好Region或者是对row_id进行打散等。下图是我们对热点问题处理前后进行测试的结果:
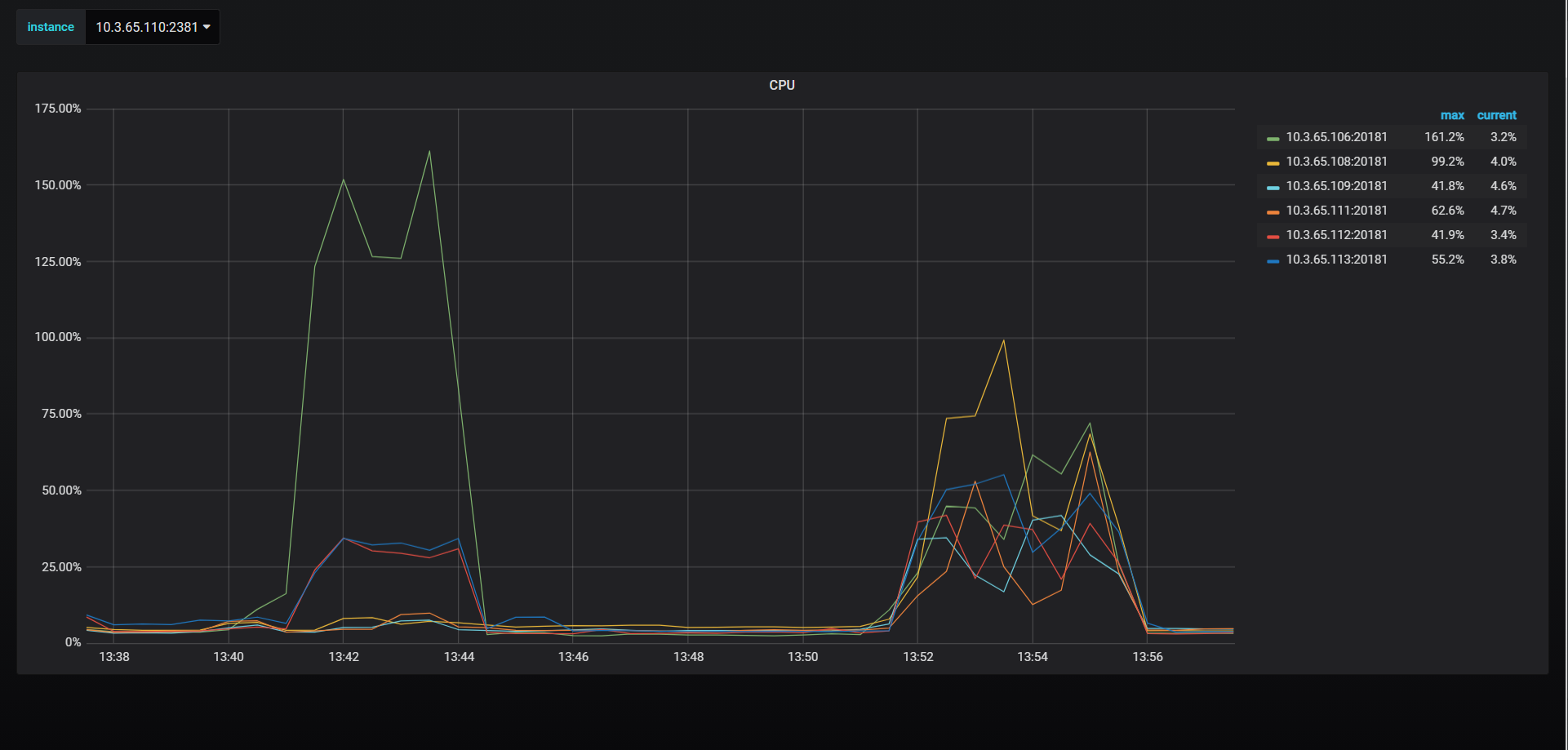

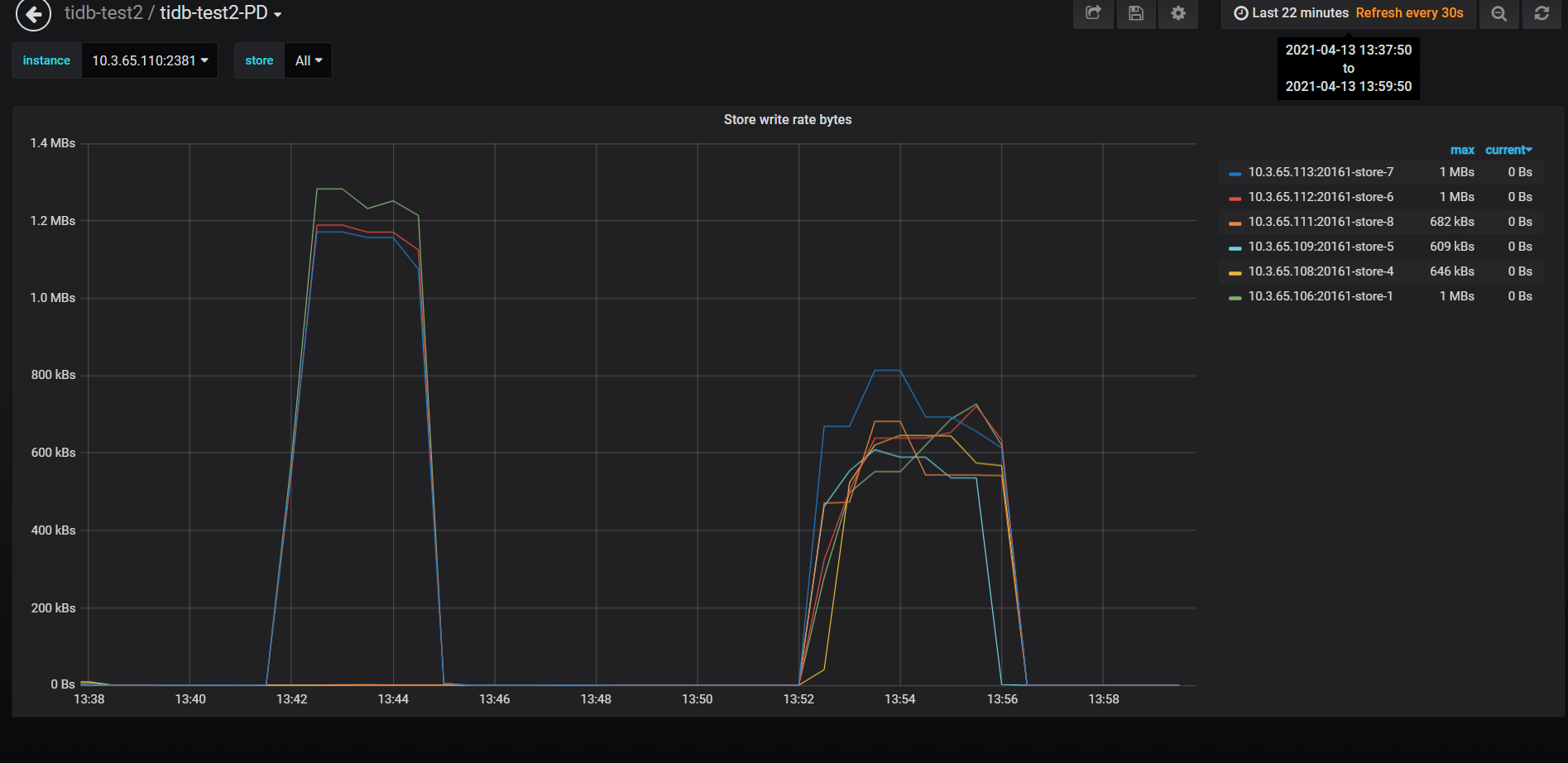
如何处理热点不是我们本文讨论的重点,TiDB本身是可以对Region进行分割和调度的,使其尽可能均匀地分布在所有TiKV节点,所以一定程度上来说它有热点自愈的特性,也就是说经过一段时间的调度后能够让Region处于一个均衡的状态,这个过程一般称为预热阶段。接下来我们重点看看它是如何进行自动调度的,这涉及到Region的两个操作: 分裂和打散。
这里要注意,预热需要花费时间(具体看调度器的运行情况,可以修改配置参数优化),对于持续高并发写入的场景依然需要提前做好Region划分,避免出现性能问题。
Region的结构
打开PD的源码结构,我们大致能看到PD包含以下几大核心模块:
- API
- 核心Server
- 集群管理
- 调度器
- TSO管理器
- Mock
- 监控指标收集
- Dashboard
- 其他一些工具包等

在PD的源码中我们可以找到Region的定义,为了使大家看的更清晰一些,我拿API模块使用的Region定义来说明:
// server/api/region.go
// RegionInfo records detail region info for api usage.
type RegionInfo struct {
ID uint64 `json:"id"`
StartKey string `json:"start_key"`
EndKey string `json:"end_key"`
RegionEpoch *metapb.RegionEpoch `json:"epoch,omitempty"`
Peers []*metapb.Peer `json:"peers,omitempty"`
Leader *metapb.Peer `json:"leader,omitempty"`
DownPeers []*pdpb.PeerStats `json:"down_peers,omitempty"`
PendingPeers []*metapb.Peer `json:"pending_peers,omitempty"`
WrittenBytes uint64 `json:"written_bytes"`
ReadBytes uint64 `json:"read_bytes"`
WrittenKeys uint64 `json:"written_keys"`
ReadKeys uint64 `json:"read_keys"`
ApproximateSize int64 `json:"approximate_size"`
ApproximateKeys int64 `json:"approximate_keys"`
ReplicationStatus *ReplicationStatus `json:"replication_status,omitempty"`
}
重点看一下如下几个字段:
StartKey和EndKey定义了这个Region的存储范围,它是一个左闭右开的区间[StartKey, EndKey)。RegionEpoch定义了Region的变更版本,用来做安全性校验Peers是这个Region的Raft Group成员,里面包含了三种类型的Peer:Leader、Follower和Learner。Leader即表示这个Region的Leader Peer是谁。PendingPeers和DownPeers是两种不同状态的Peer,和Raft选举有关。
我们可以通过pd-ctl命令行工具查看Region信息:
» region 40
{
"id": 40,
"start_key": "7480000000000000FF2500000000000000F8",
"end_key": "7480000000000000FF2700000000000000F8",
"epoch": {
"conf_ver": 5,
"version": 19
},
"peers": [
{
"id": 41,
"store_id": 1
},
{
"id": 63,
"store_id": 4
},
{
"id": 80,
"store_id": 5
}
],
"leader": {
"id": 80,
"store_id": 5
},
"written_bytes": 0,
"read_bytes": 0,
"written_keys": 0,
"read_keys": 0,
"approximate_size": 1,
"approximate_keys": 0
}
PD只负责存储Region的元数据信息,它并不负责实际的Region操作,而且PD也不会主动地发起对Region的操作。PD所有关于Region的数据都由TiKV主动上报,TiKV会对PD维持一个心跳,Leader Peer发起心跳请求的时候就会带上自己的信息,PD收到请求会更新Region元数据信息,同时根据上报的信息进行调度,这一块后面再详细说。
TiDB启动的时候并不是提前划分好Region范围的,而是用一个默认Region覆盖所有范围的key,当这个Region的大小超过设定的阈值时就会触发Region分裂,这个过程也是在TiKV中发生的。TiKV会把需要切分的key range上报给PD,PD对这个Region元信息重新计算,再把分裂操作发回给TiKV去执行。
这个特性TiKV本身就是具有的,并不会说因为热点问题才出现,本文就不做深究。
PD中的调度器
PD里面包含多种类型的调度器,与本文主题相关的调度器主要是以下几类:
- balance-leader-scheduler ,侧重于平衡计算,用来维持所有TiKV节点中Leader Peer的平衡,可以避免Leader分布不均匀的情况
- balance-region-scheduler ,侧重于平衡存储,用来维持所有TiKV节点中Peer的平衡,可以避免数据存储不均匀的情况
- hot-region-scheduler ,侧重于平衡网络,用来维持所有TiKV节点流量均衡,避免出现热点情况
每一种调度器都是可以独立启停的,我们可以使用pd-ctl工具来控制他们,也可以根据实际情况调整参数值优化执行效率,
比如我们查看PD中所有的调度器:
» scheduler show
[
"balance-hot-region-scheduler",
"balance-leader-scheduler",
"balance-region-scheduler",
"label-scheduler"
]
查看调度器的参数:
» scheduler config balance-hot-region-scheduler
{
"min-hot-byte-rate": 100,
"min-hot-key-rate": 10,
"max-zombie-rounds": 3,
"max-peer-number": 1000,
"byte-rate-rank-step-ratio": 0.05,
"key-rate-rank-step-ratio": 0.05,
"count-rank-step-ratio": 0.01,
"great-dec-ratio": 0.95,
"minor-dec-ratio": 0.99,
"src-tolerance-ratio": 1.05,
"dst-tolerance-ratio": 1.05
}
这些调度器会在PD的后台任务中持续运行,根据PD收集到的数据生成一个执行计划,前面我们提到过,PD不会主动发起请求,那么如何把这个执行计划下发到TiKV中呢?
事实上,PD是在处理TiKV的心跳时把执行计划返回给TiKV去执行的,所以这中间其实是有个时间差。那这个时间间隔到底是多少呢,我们从源码中一探究竟:
// server/schedulers/base_scheduler.go
const (
exponentialGrowth intervalGrowthType = iota
linearGrowth
zeroGrowth
)
// intervalGrow calculates the next interval of balance.
func intervalGrow(x time.Duration, maxInterval time.Duration, typ intervalGrowthType) time.Duration {
switch typ {
case exponentialGrowth:
return typeutil.MinDuration(time.Duration(float64(x)*ScheduleIntervalFactor), maxInterval)
case linearGrowth:
return typeutil.MinDuration(x+MinSlowScheduleInterval, maxInterval)
case zeroGrowth:
return x
default:
log.Fatal("type error", errs.ZapError(errs.ErrInternalGrowth))
}
return 0
}
从以上代码可以看出,PD提供了3中类型的调度频率,分别是指数增长、线性增长和不增长。对于指数增长,默认的指数因子由ScheduleIntervalFactor定义默认是1.3,对于线性增长,增长步长由MinSlowScheduleInterval定义默认是3秒。除此之外,每一种调度器都定义了最小和最大的ScheduleInterval,不管使用哪一种调度频率都不能超过最大值,以balance-hot-region-scheduler为例:
// server/schedulers/hot_region.go
const (
// HotRegionName is balance hot region scheduler name.
HotRegionName = "balance-hot-region-scheduler"
// HotRegionType is balance hot region scheduler type.
HotRegionType = "hot-region"
// HotReadRegionType is hot read region scheduler type.
HotReadRegionType = "hot-read-region"
// HotWriteRegionType is hot write region scheduler type.
HotWriteRegionType = "hot-write-region"
minHotScheduleInterval = time.Second
maxHotScheduleInterval = 20 * time.Second
)
调度器的执行流程
先用一张图看看调度器的组成结构:
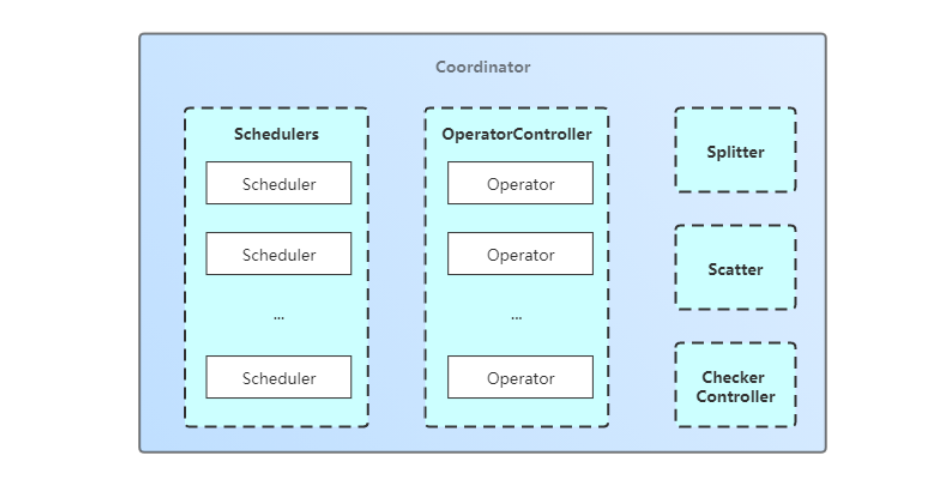
这里面的各个角色我不重复去介绍,大家可以参考PingCAP的一篇文章说的非常详细:
 MySQL at Scale. No more manual sharding
MySQL at Scale. No more manual sharding

TiKV 功能介绍 - PD Scheduler | PingCAP
在前面的文章里面,我们介绍了 PD 一些常用功能,以及它是如何跟 TiKV 进行交互的,这里,我们重点来介绍一下 PD 是如何调度 TiKV 的。
有了这个结构之后,对多种调度器进行操作甚至扩展就变得非常容易了。
我大致把调度器的执行流程分为3个阶段:
-
注册阶段
-
创建阶段
-
运行阶段
整个过程我总结为下面一个流程图:
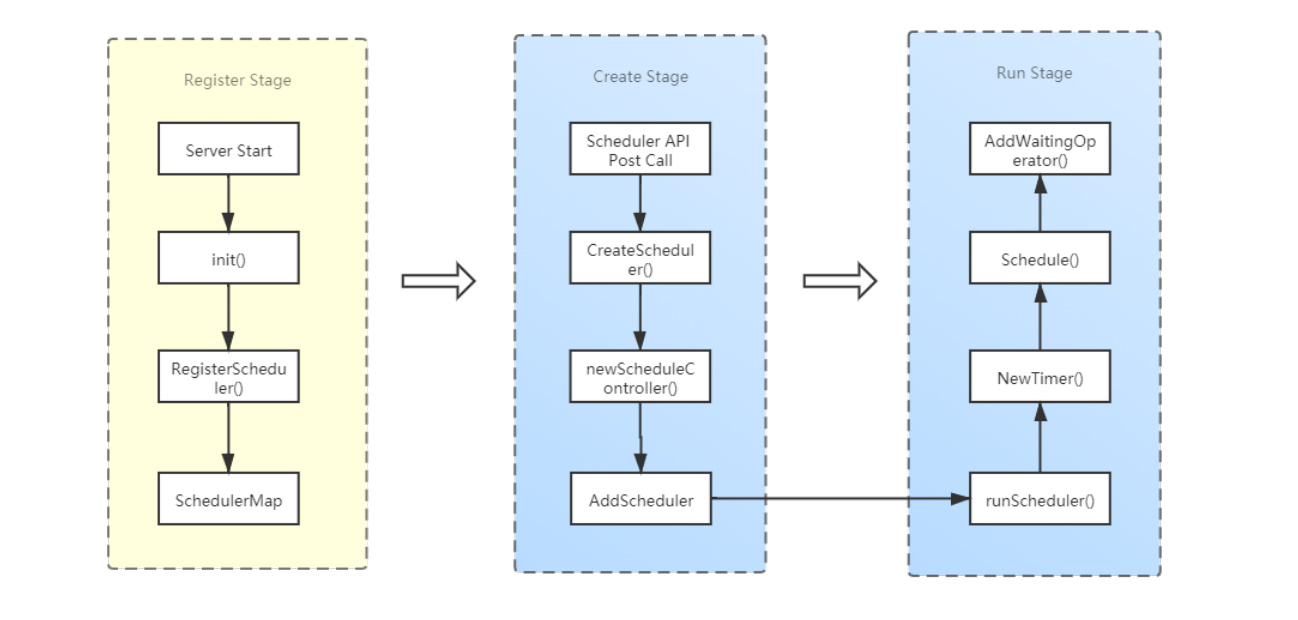
第一阶段相对比较独立,主要发生在生个PD服务启动过程中,PD启动的时候不仅会注册相关的调度器,还会启动一个Cluster对象,里面是对整个PD集群的封装,上一张图中的Coordinator和它里面的对象也是在这时候被创建和启动。
调度器注册实质是保存了一个创建调度器对象的function,当收到创建请求的时候就来执行这个function得到调度器对象。接着,调度器会被封装成一个ScheduleController对象,它被用来控制调度器的执行,这个对象里保存了调度器下一次被执行的间隔时间以及一些上下文参数。ScheduleController对象会被加入到Coordinator的调度器列表中,然后开启一个后台任务和定时器来执行最终的调度,也就是调度器的Schedule()方法,这个方法返回的是一组Operator,表示需要对Region执行一系列操作,这其中就可能包含对Region的打散操作。这些操作会被AddWaitingOperator()方法加入到OperatorController的等待队列中,等待下一次心跳到来后被下发到TiKV节点去执行。
这里要注意的是,调度器执行失败会进行重试,这个重试次数是由Coordinator设定的,默认是10次:
// server/cluster/coordinator.go
const (
maxScheduleRetries = 10
)
func (s *scheduleController) Schedule() []*operator.Operator {
for i := 0; i < maxScheduleRetries; i++ {
// If we have schedule, reset interval to the minimal interval.
if op := s.Scheduler.Schedule(s.cluster); op != nil {
s.nextInterval = s.Scheduler.GetMinInterval()
return op
}
}
s.nextInterval = s.Scheduler.GetNextInterval(s.nextInterval)
return nil
}
总结
介绍到这里,大家应该对PD的调度器运行机制有一个大致的印象了,不过本文介绍的只是抽象层面的调度器,并没有涉及到某一种具体的调度器执行逻辑,因为TiDB的工程量代码量实在太大,这个过程的任何一个细节点单独拿出来都可以写一篇专题文章。
我们会在后续持续输出TiDB底层原理技术的系列文章,欢迎大家关注,一起学习交流。如果本文有存在错误的地方,欢迎指出。