

笔记有点乱,整理一下,以备查阅,如有错误请指出。
一、事务概览
TiDB 支持分布式事务,提供乐观事务与悲观事务。TiDB 3.0.8 及以后版本,TiDB 默认采用悲观事务模式。支持的隔离级别是 SI (Snapshot Isolation),参数 transaction_isolation 只是为了兼容 MySQL,在 TiDB 无实际意义。
即使设置了悲观事务模式,autocommit 事务仍然会优先尝试使用乐观事务模式进行提交,并在发生冲突后、自动重试时切换为悲观事务模式。
经过测试,当 tidb_txn_mode='pessimistic',且使用自动提交事务。首次commit时,仍然使用的是悲观事务?这里测下来和官方不一致,还是以官方为准吧。
另外显示事务、自动提交事务遇到写冲突都会自动重试,直到重试次数达到限制 pessimistic-txn.max-retry-count
1.1 MVCC
TiKV 支持多版本并发控制 (Multi-Version Concurrency Control, MVCC)。假设有这样一种场景:某客户端 A 在写一个 Key,另一个客户端 B 同时在对这个 Key 进行读操作。如果没有数据的多版本控制机制,那么这里的读写操作必然互斥。在分布式场景下,这种情况可能会导致性能问题和死锁问题。有了 MVCC,只要客户端 B 执行的读操作的逻辑时间早于客户端 A,那么客户端 B 就可以在客户端 A 写入的同时正确地读原有的值。即使该 Key 被多个写操作修改过多次,客户端 B 也可以按照其逻辑时间读到旧的值。
TiKV 的 MVCC 是通过在 Key 后面添加版本号来实现的。没有 MVCC 时,可以把 TiKV 看作如下的 Key-Value 对:
Key1 -> Value Key2 -> Value …… KeyN -> Value 有了 MVCC 之后,TiKV 的 Key-Value 排列如下: Key1_Version2 -> Value Key1_Version1 -> Value …… Key2_Version3 -> Value Key2_Version2 -> Value Key2_Version1 -> Value …… KeyN_Version2 -> Value KeyN_Version1 -> Value …… 注意,对于同一个 Key 的多个版本,版本号较大的会被放在前面,版本号小的会被放在后面(见 Key-Value 一节,Key 是有序的排列),这样当用户通过一个 Key + Version 来获取 Value 的时候,可以通过 Key 和 Version 构造出 MVCC 的 Key,也就是 Key_Version。然后可以直接通过 RocksDB 的 SeekPrefix(Key_Version) API,定位到第一个大于等于这个 Key_Version 的位置。
二、相关参数与限制
2.2 悲观事务参数
performance.max-txn-ttl
默认值:1小时,当悲观锁的事务执行时间超过 TTL 时,会出现下述报错:
TTL manager has timed out, pessimistic locks may expire, please commit or rollback this transaction
pessimistic-txn.max-retry-count
默认值:256,悲观事务中单个语句最大重试次数。超过则会报错:pessimistic lock retry limit reached;
可以通过 grep -i Exec_retry_count tidb_slow_query.log 查看 SQL 的重试次数
innodb_lock_wait_timeout
默认值:50秒,在悲观锁模式下,事务最大等锁时间。超过则会报错:Lock wait timeout exceeded;try restarting transaction;
2.3 乐观事务参数
tidb_disable_txn_auto_retry
默认值:on,控制乐观事务在提交时遇到写冲突是否自动重试
tidb_retry_limit
默认值:10,乐观事务的自动重试次数
performance.stmt-count-limit
默认值:5000,单个事务包含的 sql 语句不超过 5000 条,该限制只在可重试的乐观事务中生效,如果使用悲观事务或者关闭了事务重试,事务中的语句数将不受此限制)
2.4 其他重要参数
storage.scheduler-concurrency
默认值:524288,scheduler 内置一个内存锁机制,防止同时对一个 key 进行操作。每个 key hash 到不同的槽;
performance.committer-concurrency
默认值:16,在单个事务的提交阶段,用于执行提交操作相关请求的 goroutine 数量;
enable-batch-dml
默认值:false,官方建议禁用此参数;
2.5 事务的限制
- 每个键值对不超过 6 MB (4.0.10起支持参数调整:raft-entry-max-size、txn-entry-size-limit)
- 键值对的总数不超过 300000 (计算方式为 300000 / (1+二级索引数量) 代码写死无法修改)
- 键值对的总大小默认为 100 MB (performance.txn-total-size-limit 参数不超过10GB。DELETE语句不受此限制)
注意:
- 开启大事务建议最大不超过2G,事务大小受参数 txn-total-size-limit 控制,开启后30W键值对的总数失效。
- 事务对内存的占用可能会有 3-4 倍的放大,10GB 大的事务可能会占用 30-40GB 的内存。如果需要执行特别大的事务,需要提前做好内存的规划,避免对业务产生影响。
三、乐观事务
TiDB 中事务使用两阶段提交协议,参考图片:

乐观事务简图:

3.1 事务执行完整流程
- 客户端开始一个事务
- TiDB 从 PD 获取 start_ts
- TiDB 校验写入数据是否符合约束(如数据类型是否正确、是否符合非空约束等)。校验通过的数据将存放在 TiDB 中该事务的私有内存里
- 客户端发起 commit
- TiDB 开始两阶段提交,见 3.2 节
- TiDB 向客户端返回事务提交成功
- TiDB 异步清理本次事务遗留的锁信息
3.2 两阶段提交2PC
RocksDB Column Family 简称:
- D 列:rocksdb.defaultcf
- L 列:rocksdb.lockcf
- W 列:rocksdb.writecf
在 prewrite 之前会在 TiDB 缓存所有数据。生产有遇到过同时并发写入上百MB数据,导致 TiDB OOM。
1、TiDB 选择一个 Key 作为当前事务的 Primary Key,剩下的为 Secondary Key
2、从 PD 获取所有数据的写入路由信息,并将所有的 Key 按照路由进行分类(即数据具体存在哪个 TiKV 节点上)
3、TiDB 发起 prewrite 请求(修改数据写入D列+锁信息写入L列),将 Primary Key 与数据写入到 TiKV,并进行加锁【加锁前会检查写入冲突,参考本节最后】, 加锁成功后执行下面操作:
(1) 锁信息写入L列,示例:<1,(W,pk,key,start_ts ... )>
(2) 行数据写入D列,示例:put<key,start_ts,'业务数据'>
未提交的数据未写入W列,因此客户端查询不到此数据。因为需要通过W列来查找Key的版本信息
4、然后 Secondary Key 并发地向所有涉及的 TiKV 发起 prewrite 请求,流程同 Primary Key 类似区别是锁信息指向了 Primary Key :
(1) 锁信息写入L列,示例:<2,(W,@1,key,start_ts ... )>
@1 表明指向 Primary key,也就是(1) 的锁信息
5、TiDB 收到所有 prewrite 都成功
6、TiDB 向 PD 获取 commit_ts
7、TiDB 向 Primary Key 所在 TiKV 发起 2PC 的 commit
(1) 写入 W 列,示例:put<key,commit_ts,start_ts>
此时数据可见,通过start_ts + key找到D列中的数据
(2) 写入 L 列,表示删除锁信息,示例:<1,(D,pk,key,start_ts ... )>
(3) 最后清理锁信息
8、Primary Commit 提交成功后,Secondary 可以进行异步提交
9、TiDB 收到两阶段提交成功
【加锁前检查写入冲突】
- 检查 L 列,是否已经有别的客户端已经上锁
<1,(D,pk,key,start_ts ... )>
<1,(W,pk,key,start_ts ... )>
D 表明锁已经删除,如果仅有 W 表明 key 已被加锁
- 检查 W 列,在本次事务开始时间之后,是否有更新 [startTs, +Inf) 的写操作已经提交 (Conflict)
start_ts > commit_ts 继续
start_ts < commit_ts 回滚
Prewrite 出现冲突,当前事务回滚。
Primary Commit 出现冲突,全事务回滚。
Scheduler 中有一个模块叫做 Latches,它包含很多个槽。每个需要写入操作的任务在开始前,会去取它们涉及到的 key 的 hash,每个 key 落在 Latch 的一个槽中;接下来会尝试对这些槽上锁,成功上锁才会继续执行取 snapshot、进行读写操作的流程。这样一来,如果两个任务需要写入同一个 key,那么它们必然需要在 Latches 的同一个槽中上锁,因而必然互斥。
3.2 ResolveLocks
当在事务中读数据或者 prewrite keys 时,如果 key 上已经有 Lock 了,这时就需要进行 ResolveLock 。为什么会出现这种情况?有以下几种情况:
- 事务 txn_1 在完成
prewritekey_1,key_2 后就异常退出了,那么此时事务 txn_2 再去读 key_1, key_2 时,就会发现有 txn_1 在prewrite时写的 Lock。 - 事务 txn_1 在
prewritekey_1完成,但在 key_2 因为冲突而失败时,txn_1 会终止并异步清理 key_1 上的锁,如果异步清理锁还没完成,此时 txn_2 去读 key_1 ,也会遇到 Lock - 事务 txn_1 在
commitprimary key 成功后,是用异步commitsecond keys,在异步commit还没完成时,txn_2 去读 second keys 时也会遇到 Lock。
那么如何 ResolveLocks 呢?prewrite keys 时会同时带上一个 LockTTL, ResolveLock的流程首先是检查所有 Lock 的 TTL,记下最久的 expire Time ,并发现如果有 keys 上的 locks 的 ttl 已经过期后,就会发起对这些过期 keys 的 Locks 进行 resolveLock,如果还有 keys 的 locks 没有 resolve,就根据最久的 expire time 进行 back off 后重试。
3.3 乐观事务优缺点
优点:事务在二阶段提交的 Prewrite 时才会检测冲突。在事务提交的过程中锁检测的代价是比较大的,所以乐观事务在一些场景有较好的写入提升。比如基于id自增主键的写入情景,或者有唯一索引但是很少或者不会出现多个并发同时对同一个行的DML操作的情景。
缺点:事务冲突不可避免,乐观模式采用了内部重试功能。
重试的好处:写冲突的情况避免直接报错给client。
重试的缺点:每次重试时间间隔会逐渐变长,写冲突高的情况下,一条SQL可能需要较长时间才能写入成功,另外TiDB 默认不进行事务重试,因为重试事务可能会导致更新丢失,从而破坏可重复读的隔离级别。
3.4 读写冲突
在 TiDB 中,读取数据时,会获取一个包含当前物理时间且全局唯一递增的时间戳作为当前事务的 start_ts。事务在读取时,需要读到目标 key 的 commit_ts 小于这个事务的 start_ts 的最新的数据版本。当读取时发现目标 key 上存在 lock 时,因为无法知道上锁的那个事务是在 Commit 阶段还是 Prewrite 阶段,所以就会出现读写冲突的情况,如下图:
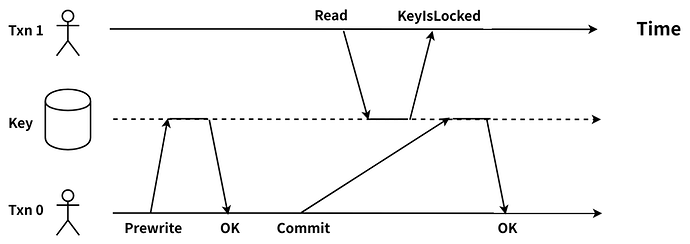
分析:
Txn0 完成了 Prewrite,在 Commit 的过程中 Txn1 对该 key 发起了读请求,Txn1 需要读取 start_ts > commit_ts 最近的 key 的版本。此时,Txn1 的 start_ts > Txn0 的 lock_ts,需要读取的 key 上的锁信息仍未清理,故无法判断 Txn0 是否提交成功,因此 Txn1 与 Txn0 出现读写冲突。
监控:
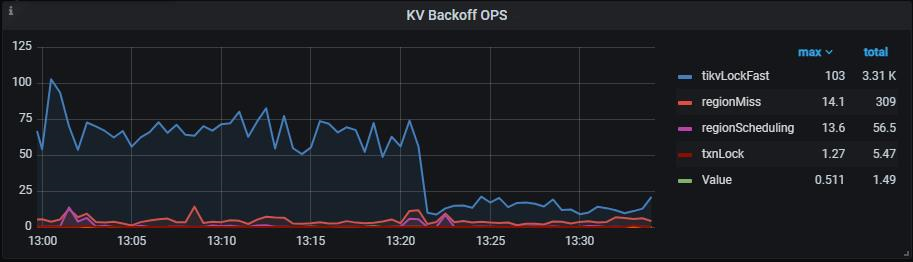
观察 KV Errors 下 Lock Resolve OPS 面板中的 not_expired/resolve 监控项以及 KV Backoff OPS 面板中的 tikvLockFast 监控项,如果有较为明显的上升趋势,那么可能是当前的环境中出现了大量的读写冲突。其中,not_expired 是指对应的锁还没有超时,resolve 是指尝试清锁的操作,tikvLockFast 代表出现了读写冲突。txnLock表示写写冲突。

通过tidb日志分析:
[2025/04/30 15:10:29.745 +08:00] [INFO] [coprocessor.go:1288] ["[TIME_COP_PROCESS]
resp_time:475.782087ms
txnStartTS:457702645097825569
region_id:11148636727
store_addr:xx.xx.xx.xx:xxxx
backoff_ms:516
backoff_types:[txnLockFast,txnLockFast,txnLockFast,txnLockFast,txnLockFast,txnLockFast]
kv_process_ms:318
kv_wait_ms:15
kv_read_ms:458
processed_versions:8277
total_versions:319382
rocksdb_delete_skipped_count:66
rocksdb_key_skipped_count:284751
rocksdb_cache_hit_count:868
rocksdb_read_count:0
rocksdb_read_byte:0"]
[conn=9167336529683369533]
- txnStartTS:发起读请求的事务的 start_ts
- region_id:读请求访问的目标 region 的 id
- backoff_types:读写发生了冲突,并且读请求进行了 backoff 重试,重试的类型为 txnLockFast
- backoff_ms:读请求 backoff 重试的耗时,单位为 ms
3.5 写写冲突
写写冲突发生在(当客户端发起 COMMIT 请求的时候,TiDB 开始两阶段提交) prewrite 阶段,当发现有其他的事务在写当前 Key (data.commit_ts > txn.start_ts),则会发生写写冲突。
TiDB 会根据 tidb_disable_txn_auto_retry 和 tidb_retry_limit 参数设置的情况决定是否进行重试,如果设置了不重试,或者重试次数达到上限后还是没有 prewrite 成功,则向 TiDB 返回 Write Conflict 错误。
通过 TiDB 日志查看是否有 [kv:9007]Write conflict 关键字,如果搜索到对应关键字,则可以表明集群中存在写写冲突。
[2025/05/06 14:45:14.529 +08:00] [WARN] [session.go:959] [sql] [conn=3145507056292557201] [label=general]
[error="[kv:9007]Write conflict, txnStartTS=457838143577785185, conflictStartTS=457838143577785183, conflictCommitTS=457838143577785343,
key={tableID=9387, tableName=test_db.test_table, indexID=3, indexValues={1852812006013272064, c41116affcf5713e88ecbf613924ff83, }},
originalKey=7480000000000024ab5f6980000000000000030419b682b3ee000000016334313131366166ff6663663537313365ff3838656362663631ff3339323466663833ff0000000000000000f7,
primary={tableID=9387, tableName=test_db.test_table, indexID=3, indexValues={1852812006013272064, c41116affcf5713e88ecbf613924ff83, }}, originalPrimaryKey=7480000000000024ab5f6980000000000000030419b682b3ee000000016334313131366166ff6663663537313365ff3838656362663631ff3339323466663833ff0000000000000000f7,
reason=Optimistic [try again later]"]
[txn="Txn{state=invalid}"]
关于日志的解释如下:
[kv:9007]Write conflict:表示出现了写写冲突 txnStartTS=457838143577785185:表示当前事务的 start_ts 时间戳 conflictStartTS=457838143577785183:表示冲突事务的 start_ts 时间戳 conflictCommitTS=conflictCommitTS:表示冲突事务的 commit_ts 时间戳 key={tableID=6132, indexID=1, indexValues={string, }}:表示当前事务中冲突的数据,tableID 表示发生冲突的表的 ID,indexID 表示是索引数据发生了冲突。如果是数据发生了冲突,会打印 handle=x 表示对应哪行数据发生了冲突,indexValues 表示发生冲突的索引数据 primary={tableID=6132, indexID=1, indexValues={string, }}:表示当前事务中的 Primary Key 信息
四、悲观事务

TiDB 在乐观事务模型的基础上支持了悲观事务模型,将上锁的时机提前到进行DML时。TiDB 的悲观锁实现的原理确实如此,在一个事务执行 DML (UPDATE/DELETE) 的过程中,TiDB 不仅会将需要修改的行在本地缓存,同时还会对这些行直接加锁,这里的悲观锁的格式和乐观事务中的锁几乎一致,但是锁的内容是空的,只是一个占位符,待到客户端 commit 时,直接将这些悲观锁改写成标准的 Percolator 模型的锁,后续流程跟乐观模型一样。
4.1 悲观事务模式的行为
悲观事务的行为和 MySQL 基本一致:
UPDATE、DELETE或INSERT语句都会读取已提交的最新数据来执行,并对所修改的行加悲观锁。SELECT FOR UPDATE语句会对已提交的最新的数据而非所修改的行加上悲观锁。- 悲观锁会在事务提交或回滚时释放。其他尝试修改这一行的写事务会被阻塞,等待悲观锁的释放。其他尝试读取这一行的事务不会被阻塞,因为 TiDB 采用多版本并发控制机制 (MVCC)。
- 需要检查唯一性约束的悲观锁可以通过设置系统变量
tidb_constraint_check_in_place_pessimistic控制是否跳过,详见约束。 - 如果多个事务尝试获取各自的锁,会出现死锁,并被检测器自动检测到。其中一个事务会被随机终止掉并返回兼容 MySQL 的错误码
1213。
- 通过
innodb_lock_wait_timeout变量,设置事务等锁的超时时间(默认值为50,单位为秒)。等锁超时后返回兼容 MySQL 的错误码1205。如果多个事务同时等待同一个锁释放,会大致按照事务start ts顺序获取锁。 - 乐观事务和悲观事务可以共存,事务可以任意指定使用乐观模式或悲观模式来执行。
- 支持
FOR UPDATE NOWAIT语法,遇到锁时不会阻塞等锁,而是返回兼容 MySQL 的错误码3572。 - 如果
Point Get和Batch Point Get算子没有读到数据,依然会对给定的主键或者唯一键加锁,阻塞其他事务对相同主键唯一键加锁或者进行写入操作。 - 支持
FOR UPDATE OF TABLES语法,对于存在多表 join 的语句,只对OF TABLES中包含的表关联的行进行悲观锁加锁操作。
和 MySQL InnoDB 的差异
1、TiDB 不支持 gap locking(间隙锁)
BEGIN /*T! PESSIMISTIC */;
SELECT * FROM t1 WHERE id BETWEEN 1 AND 10 FOR UPDATE;
BEGIN /*T! PESSIMISTIC */;
INSERT INTO t1 (id) VALUES (6); -- 仅 MySQL 中出现阻塞。
UPDATE t1 SET pad1='new value' WHERE id = 5; -- MySQL 和 TiDB 处于等待阻塞状态。
2、TiDB 不支持 SELECT LOCK IN SHARE MODE。
3、START TRANSACTION WITH CONSISTENT SNAPSHOT 之后,MySQL 仍然可以读取到之后在其他事务创建的表,而 TiDB 不能。
4、autocommit 事务优先采用乐观事务提交。
使用悲观事务模式时,autocommit 事务首先尝试使用开销更小的乐观事务模式提交。如果发生了写冲突,重试时才会使用悲观事务提交。所以 tidb_retry_limit = 0 时,autocommit 事务遇到写冲突仍会报 Write conflict 错误。
自动提交的 SELECT FOR UPDATE 语句不会等锁。
5、对语句中 EMBEDDED SELECT 读到的相关数据不会加锁。
4.2 异步提交事务
数据库的客户端会同步等待数据库系统通过两阶段 (2PC) 完成事务的提交,事务在第一阶段提交成功后就会返回结果给客户端,系统会在后台异步执行第二阶段提交操作,降低事务提交的延迟。如果事务的写入只涉及一个 Region,则第二阶段可以直接被省略,变成一阶段提交。
开启异步提交事务特性后,在硬件、配置完全相同的情况下,Sysbench 设置 64 线程测试 Update index 时,平均延迟由 12.04 ms 降低到 7.01ms ,降低了 41.7%。
tidb_enable_async_commit
注意
- 对于新创建的集群,默认值为 ON。对于升级版本的集群,如果升级前是 v5.0 以下版本,升级后默认值为
OFF。(你可以执行 set global tidb_enable_async_commit = ON; 和 set global tidb_enable_1pc = ON; 语句开启该功能。)- 启用 TiDB Binlog 后,开启该选项无法获得性能提升。要获得性能提升,建议使用 TiCDC 替代 TiDB Binlog。
- 启用该参数仅意味着 Async Commit 成为可选的事务提交模式,实际由 TiDB 自行判断选择最合适的提交模式进行事务提交。
4.3 Pipelined 特性
加悲观锁需要向 TiKV 写入数据,要经过 Raft 提交并 apply 后才能返回,相比于乐观事务,不可避免的会增加部分延迟。为了降低加锁的开销,TiKV 实现了 pipelined 加锁流程:当数据满足加锁要求时,TiKV 立刻通知 TiDB 执行后面的请求,并异步写入悲观锁,从而降低大部分延迟,显著提升悲观事务的性能。但当 TiKV 出现网络隔离或者节点宕机时,悲观锁异步写入有可能失败,从而产生以下影响:
- 无法阻塞修改相同数据的其他事务。如果业务逻辑依赖加锁或等锁机制,业务逻辑的正确性将受到影响。
- 有较低概率导致事务提交失败,但不会影响事务正确性。
如果业务逻辑依赖加锁或等锁机制,或者即使在集群异常情况下也要尽可能保证事务提交的成功率,应关闭 pipelined 加锁功能。

该功能默认开启,可修改 TiKV 配置关闭:
[pessimistic-txn]
pipelined = false
若集群是 v4.0.9 及以上版本,支持动态关闭该功能:
set config tikv pessimistic-txn.pipelined='false';
4.4 内存悲观锁
TiKV 在 v6.0.0 中引入了内存悲观锁功能。开启内存悲观锁功能后,悲观锁通常只会被存储在 Region leader 的内存中,而不会将锁持久化到磁盘,也不会通过 Raft 协议将锁同步到其他副本,因此可以大大降低悲观事务加锁的开销,提升悲观事务的吞吐并降低延迟。
当内存悲观锁占用的内存达到 Region 或节点的阈值时,加悲观锁会回退为使用 pipelined 加锁流程。当 Region 发生合并或 leader 迁移时,为避免悲观锁丢失,TiKV 会将内存悲观锁写入磁盘并同步到其他副本。
内存悲观锁实现了和 pipelined 加锁流程类似的表现,即集群无异常时不影响加锁表现,但当 TiKV 出现网络隔离或者节点宕机时,事务加的悲观锁可能丢失。
如果业务逻辑依赖加锁或等锁机制,或者即使在集群异常情况下也要尽可能保证事务提交的成功率,应关闭内存悲观锁功能。
该功能默认开启。如要关闭,可修改 TiKV 配置:
[pessimistic-txn]
in-memory = false
也支持动态关闭该功能:
set config tikv pessimistic-txn.in-memory='false';
五、监控
5.1 查询阻塞SQL
SELECT START_TIME,
USER,
DB,
STATE,
SESSION_ID,
SUBSTRING_INDEX(CURRENT_SQL_DIGEST_TEXT,
' ',3) AS 'table_operator'
FROM information_schema.CLUSTER_TIDB_TRX
WHERE CURRENT_SQL_DIGEST_TEXT IS NOT NULL
AND STATE='LockWaiting'
ORDER BY DB,CURRENT_SQL_DIGEST_TEXT,START_TIME
5.2 监控图表
TiKV-Details -> Scheduler - commit

如果发现这个 wait duration 特别高,说明耗在等待锁的请求上比较久,如果不存在底层写入慢问题的话,基本上可以判断这段时间内冲突比较多。
六、QA
6.1 TxnLockNotFound
pingcap/tidb/blob/master/store/tikv/lock_resolver.go#L124
// IsCommitted returns true if the txn's final status is Commit.
func (s TxnStatus) IsCommitted() bool { return s.ttl == 0 && s.commitTS > 0 }
// CommitTS returns the txn's commitTS. It is valid iff `IsCommitted` is true.
func (s TxnStatus) CommitTS() uint64 { return uint64(s.commitTS) }
// By default, locks after 3000ms is considered unusual (the client created the
// lock might be dead). Other client may cleanup this kind of lock.
// For locks created recently, we will do backoff and retry.
var defaultLockTTL uint64 = 3000
// TODO: Consider if it's appropriate.
var maxLockTTL uint64 = 120000
// ttl = ttlFactor * sqrt(writeSizeInMiB)
var ttlFactor = 6000
// Lock represents a lock from tikv server.
type Lock struct {
Key []byte
References
[2] TiDB 新特性漫谈:悲观事务
[3] 线性一致性和 Raft
[6] Large-scale Incremental Processing Using Distributed Transactions and Notifications