

大家好,我是聚美集团 DBA 袁文学。我是 2018 年下半年入职聚美集团,可能大家的对聚美最大的印象还是传统电商平台,其实这些年聚美也拓展了一些新的业务方向,比如新零售、共享充电宝,以及短视频等等。今天我主要给大家分享就是我们在短视频业务两个场景下的 TiDB 的应用。
今天的分享分为以下几个部分,来给大家介绍下,聚美是如何在 2 个月的时间从调研到上线百 TB 数据的集群:
- 短视频业务场景及存储架构介绍
- 存在的问题
- TiDB 从调研到上线遇到的问题及解决方案
- TiDB 解决了什么问题
- 后续计划
业务场景及存储架构
场景一:视频互动
首先介绍一下我们的业务场景。短视频大家应该都在用,我们的刷宝短视频有一些视频互动的场景:打开一个短视频之后,除了视频内容之外,还有点赞、评论、分享、用户的粉丝数和关注数据等,我们把这些数据称之为视频互动数据。有关互动的数据,我们在后台会分成两个维度来它存储:视频和用户,数据量大概在百亿级别。互动相关的数据必须是长期存储的,不能删除,不能过期,所以这个数据量随着时间的增长就会越来越大。
数据存储架构,Redis +Kafka +MySQL 分库分表。我们前端使用了大量的 Redis 作为缓存层,挡掉外部过来的流量。写数据时,业务直接写到 Kafka,再通过 worker 消费到 MySQL 里。MySQL 按照用户ID 进行 4M4S 分库分表。每个实例上面 32 个库,每个库里 8 张表,因此每个表就被分成了 1024 个分表。
场景二:视频曝光
所谓曝光,就是当你看了一个短视频之后,后面系统就不会再给你推荐已经看过的视频了,因为我们后台会把用户看过的视频和用户 ID 或者设备 ID 持久化存起来,后续的视频推过来,会先经过过滤,用户没看过的视频才推过来。这个过滤是有一个过期时间的,比如我们设置了 90 天的过期时间,到期之后会自动的把它清理掉。曝光数据的特点是写入量非常大,比如每天 100W 用户在使用刷宝看短视频,假设每个用户看 50 个视频,一天写入的曝光记录就是 5000W 条。目前曝光数据量已经达到了千亿级。
视频曝光数据的存储:按用户分区后,每个分区再采用 Redis + Kafka+ MySQL 4 主 4 从分库分表的架构,流量也是大部分被 Redis 挡在外面了。实际上曝光 MySQL 的数据相当于冷数据,只有当数据要预热的时候,MySQL 的 QPS 才会比较高。平时 MySQL 的 QPS 可能不超过两千,预热的时可能会上万。
MySQL 遇到的问题
容量问题
第一个就是容量问题。因为曝光数据的量达到千亿级,如果继续用 MySQL 的分库分表方案,在我们的一个分区里面,本来是一个四主四从的分库方法,但是随着我们的活跃量越来越高,单个分区里一套集群已经不能满足需求了,我们必须要扩另外一套集群,用两套集群来轮转使用,才能满足 90 天内的数据存储。互动集群最开始量比较小,4 主 4 从没有问题,到 2019 年年中 UGC 上线后,磁盘使用率很快就达到 80% 左右,需要持续扩容,
而且研发也需要修改代码,持续扩容和哈希带来的研发和资源成本就会越来越高。我们 2019 年下半年就开始在考虑替换方案,让扩容变得透明,业务也不需要变动直接就可以搞定。
分库分表配置复杂
第二个问题就是分库分表配置的复杂性。我们分库分表是在业务端分库,每次扩一个集群,配置就增加很多。
MySQL 分库分表带来的连接数问题
MySQL 分库分表带来的连接数的问题,连接数过多就会导致 DDL 失败,发版也会变慢。
Kafka 队列消费延迟
分库分表决定了它一次只能消费一条数据,如果并发高的话 MySQL 扛不住,MySQL 集群内部有主从延迟,我们必须要把并发控制住,又要让 Kafka 队列消费没有延迟,有的时候要管理两个 Work,有时要写 Work 之类的这种操作。
大数据分析
我们的互动数据需要进行大数据分析,但是我们是分库分表方法,需要把其中的数据拖到一个 Hive 里面汇总再进行分析,这些都是我们现在遇到的一些不方便的点。
TiDB 从调研到上线遇到的问题
在 2019 年 10-11 月份的时候,我们开始调研 TiDB。11 月上旬开始调研 TiDB 的时候,通过官方文档,我们自己有一个测试环境,验证过后觉得可以满足需求,就在公有云上部署了一套 TiDB 集群,模拟我们的一个场景做测试。模拟的场景主要是互动库的场景,因为之前从来都没有用过 TiDB,对 TiDB 了解比较少,我们线上 MySQL 数据库用的都是云 SSD,所以最开始的机器就是云 SSD 的盘。在通过Ansible 部署的时候,检测到云 SSD 的磁盘 IO 不满足TiDB的需求。但是当时我们想只是做一个测试,就修改了脚本里面的参数把 TiDB 部署上去,直接在上面模拟业务压测。
1. 云 SSD 磁盘性能不足
我们业务的模拟压测的时候,创建了一个具有自增主键的表结构,这是用来模拟用户和粉丝的关注表,一个是用户 ID,另一个是粉丝的用户 ID,还有一个是关注时间,这个表还有一个索引。压测后发现它的性能根本不能满足我们的需求,具体表现就是:
响应时间很高
比如说 99% 的响应时间已经达到了 300 多毫秒了,80% 的时间是 120 毫秒,对于线上的环境来说,120 毫秒肯定是比较难以接受的。
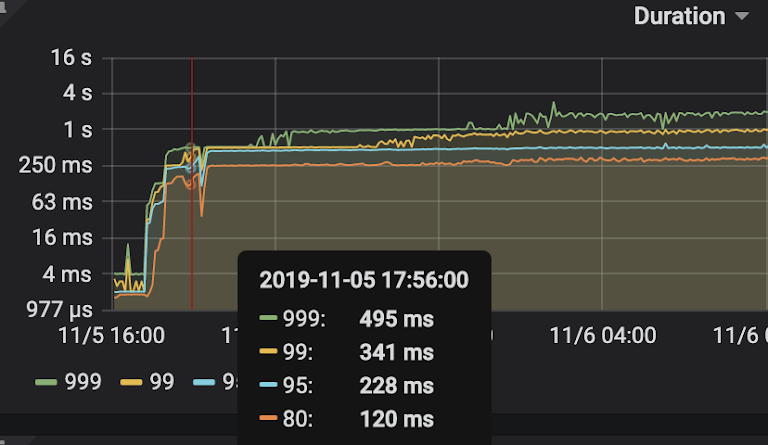
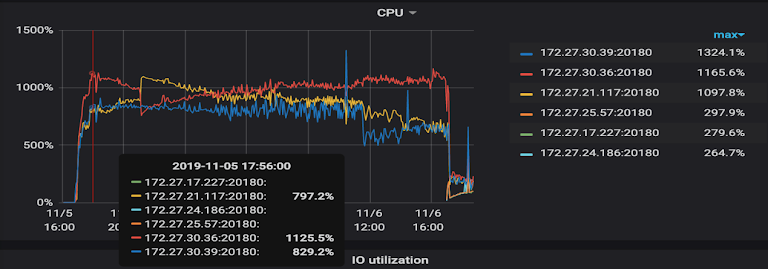
TiKV 的 CPU 和磁盘利用率也很高,而且在 TiKV 集群上的分布也不均匀
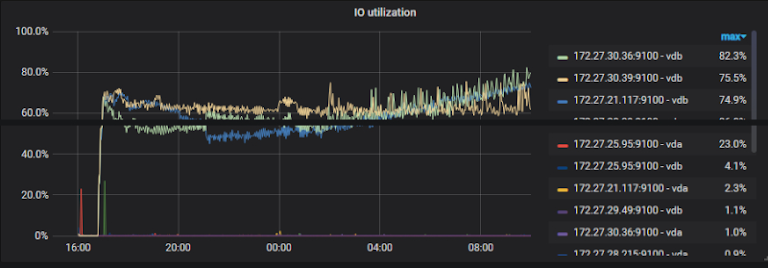
我们当时压测的数据是写数据,只有 1.3W 的 QPS,读是 5.6W 的 QPS,当时的 IO 基本达到了 70%-80%,TiKV 的 CPU 使用率是百分之一千到一千三,配置到是 16 核的机器,2T 的云 SSD 盘,这个配置下的资源利用率很高。
Token 耗时已经达到五百毫秒
Get token 单次查询到耗时如果降不下去的话,那么单次查询的 QPS 耗时也会很高。
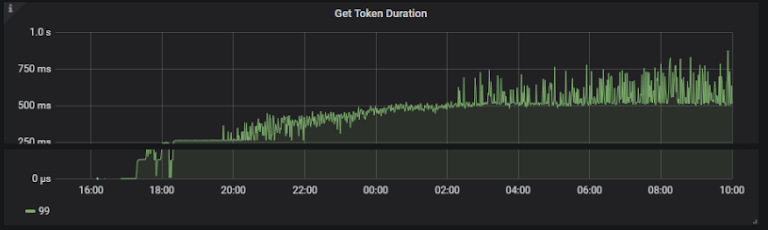
经过 PingCAP 的同学帮忙定位分析后。最后我们把云 SSD 盘换掉之后(部署时修改了检测参数;部署的时候 fio 检测已经提示我们云 SSD 的 IOPS 只有两万三,TiDB 要求达到四万;),系统的使用率跟单次查询的时间都降了下来。云 SSD 换掉后,我们发现云 SSD 和本地 SSD 的数据对比结果是本地 SSD 的性能大概是云 SSD 的 5 倍左右,因为本地 SSD 使用率到差不多 15%-16% 时,云 SSD 差不多已经到 80% 了。
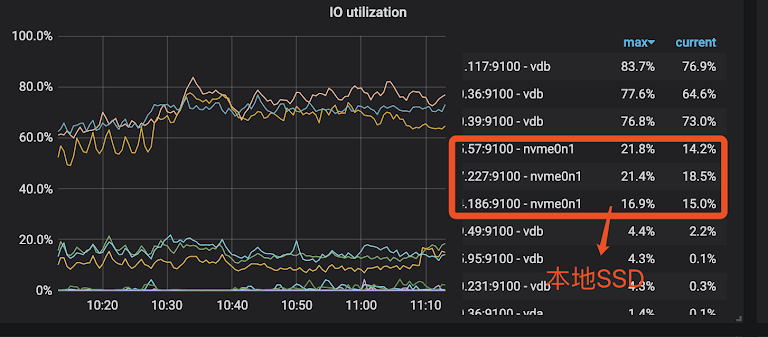
2. 写入热点问题
我们发现了一个写入热点的问题,因为测试的表结构里有一个自增的主键,在 MySQL 里面大多数都会有一个这样的主键,但是在 TiDB 中,这个自增的主键会导致 Region 分布到不同的 TiKV 上面。因为数据是写到 Leader 节点上的,Leader 节点分布不均匀就会只用到其中一部分的 IO,并没有把所有的 TiKV 的 IO 能力都平均的利用起来。这个表的 Leader 分布在三个 TiKV 上分别是 0.1% 和 21.6%,78%,索引数据的分布第一个节点是 86.59%,第二个是 12.55%,第三个是 0.86%,非常的不均匀。
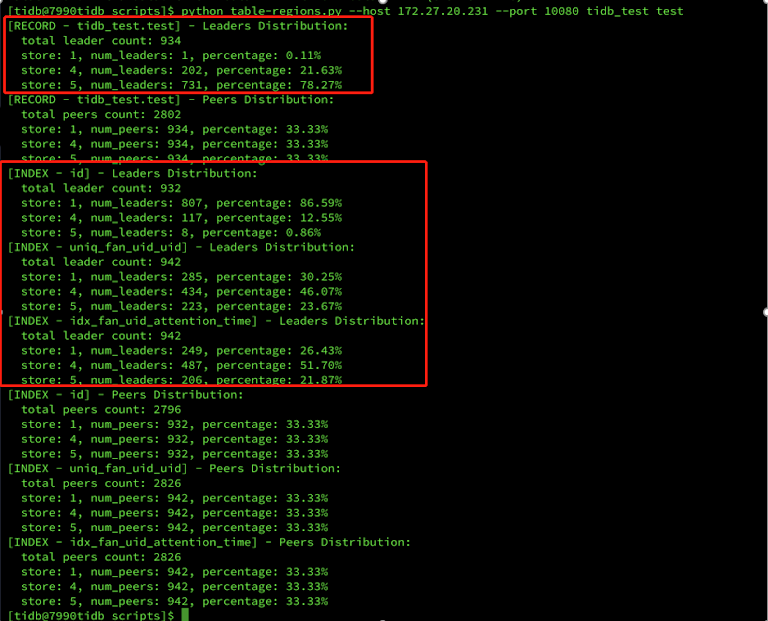
于是在压测环境上把这个表的自增主键去掉,但是我们去掉之后发现了另一个问题。如果一个 TiDB 的表里面没有主键,或者主键不是一个整数,那么 TiKV 就有会一个映射自增的 UID 在里面,同样这个 UID 也会造成写入热点的问题。后来在 PingCAP 官方的帮助下,我们把 shard_row_id_bits 这个参数加到表里面了。通过这个功能,它可以把 UID 打散到不同的 Region 里,缓解写入热点问题。
下图是我从 TiDB 官网上摘抄下来的,大家以后遇到这种写入热点问题,也可以按照这种思路来分析一下。

3. 数据同步
同步流程
因为我们的互动库在原来是 MySQL 四主四从的分库分表,我们把它同步到 TiDB 里面去,肯定是要把它汇总到一起的。数据同步我们是通过 TiDB 的 DM 工具,它支持全量和增量的方式同步,我们是用全量加增量的方式,大概的示意图就是这样的我们先看一下,同步的大概的流程:
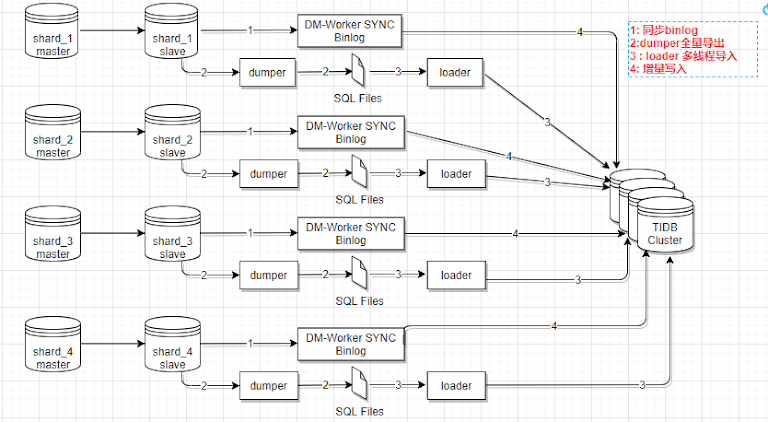
- 开始启动一个 DM-worker 之后,它就会把 Binlog 全部都拉到 dm-worker 本地存储一份
- 然后启动同步任务,DM 会在指定的机器上启动 dump 的进程,把上面的分库分表全部都 dump 到 dm-worker 机器上保存为 SQL 文件。
- 通过 Load 程序把刚才 dump 下来的那些 SQL 文件全部加载到 TiDB里面。加载完成之后,再把同步的 Binlog 增量写入到 TiDB
使用 DM 同步互动数据的时候,我们也遇到了一些问题。
分表主键不是全局唯一
我们分表里面的自增组件不是全局唯一的。
我们刚才说了,互动库是 1024 个分表,每一个分表都有自己的自增主。键这种情况下同步到 DM 怎么处理这个问题呢?TiDB 官网上提供了几种解决方案:
- 如果你的主键 ID 列,是一个在业务上没有意义的列,可以把它拿掉,这样就不会存在这个问题了。
- 使用联合主键,主键列加上某个列的组合能保证全局唯一。同步过去就不会有问题。
- column mapping 的方式,就是把一个列在前面,加一些映射的数字之后转化成另一个列。这种方式我们也测试过,但是最终没有采用这种方式(官网极度不推荐)。
因为我们的 ID 列没有在这个业务上直接使用到,我们就直接把它拿掉了。
单调递增列的索引写入热点
单调递增的列索引存在写入热点。比如我们的一个列,存了“关注时间”的信息,它就是一个单调递增的列,如果在这个列上存在索引,写到 TiDB 里面也是一个写入的热点,相当于把索引的 Region 分到不同的 TiKV 里面去,Region 的分布不均匀,它就会只用到其中一个或者两个 TiKV,不会把所有的 TiKV 平均利用起来。
独立数据迁移任务
一个任务同步多个 Sharding Group,我先解释一下 Sharding Group 这个概念吧,比如说,一个表在四主四从集群里面,每个库里面我都有分表,这一个表,所有的分表同步到 TiDB 里面之后就汇总到了一个表,我们就把前面的所有的分表,都称之为一个 Sharding Group,但是我们库里面应该肯定不可能是只有一个表的分表,我们比如说我们有视频点赞的分表,有视频评论的分表,我们一个任务同步多个 Sharding Group 的时候,就相当于只需一个任务就把所有的 MySQL 分表的数据全部都同步到了 TiDB 里面,只要其中一个分表里面的数据出现脏数据之类的,那么任务就挂起了,挂起了之后,我们当时是没有找到解决方法,就尝试重新同步。因为我们数据量比较大,重新同步耗时也很久。所以我们后来一个任务只负责一个 Sharding Group。比如一个任务,只负责点赞的分表,同步到 TiDB 里面,另一个任务又负责从评论的分表,把数据同步到 TiDB 里面,这样的话,一个任务的—个分表数据有问题,同步到 TiKV 的时候也只有这个任务会挂起,其他的任务是不受到影响的。
多个数据迁移任务需串行执行
当我们觉得可以了,很开心地启动了多个同步任务开始同步之后,同时同步很多个 Sharding Group 又遇到了另一个问题:多个任务并行启动的时候会出现 Duplicate keys 的错误。当时我们很费解为什么会出现这个问题?但理由来说,我们查了 MySQL 里面没有脏数据,但查了 TiKV 的日志,也确实出现了 Duplicate keys 错误。我们请教了 TiKV 相关大佬,他们分析之后,多个同步任务并行时,如果一个表的数据量非常大的话,TiKV 同步这个表的时候,会很繁忙,PD 去调度同步的时候,有可能没有接受到 TiKV 的反馈,就会进行重试的操作。但是这个时候 TiKV 的数据里已经存在了刚才插入的这一行,重试就会出现 Duplicate keys 错误。所以我们最终相当于是一个表一个表的同步完,这样就没有问题了。
4. 业务切换到 TiDB
最终把所有的表全部都同步到 TiDB 之后,我们观察了一段时间,保持 DM 的数据同步,根据业务的轻重程度,切了一部分的读到这个 TiDB 进行测试,同时肯定是有开关可以控制这个读的,如果有问题的话,我们可以通过开关直接把它切回到 MySQL 集群里面。测试了一段时间之后发现没有什么问题,我们就直接在线上双写 MySQL 和 TiDB。因为 DM 一直在同步 MySQL 到 TiDB 的数据,如果在两边都写的话,DM 会检测到 TiDB 已经存在这行记录,就会把 MySQL 同步过来的任务挂起,这样就相当于完成了一个双写的操作。挂起之后,后面的 DM 任务,如果确定没有问题可以关掉,由于没有读 TiDB 集群的数据,有问题也对线上没有影响。后来我们就逐渐把一些更重要的业务也往 TiDB 切,现在互动库已经全部切到 TiDB 了。
对于视频曝光服务由于存在时效性,所有没有同步数据的操作,增量数据改为只写 TiDB,并保持 MySQL 和 TiKV 的双读,等 MySQL 那边 90 天的有效期过去之后,所有新的数据都在 TiDB 这边了,后面我们就会只读 TiDB了,这样就完成了从 MySQL 到 TiDB 的切换。
因为曝光数据按用户 ID 分了大区,我们只切了两个大区域的数据到 TiDB,随着时间的发展我们会逐渐吧所有大区的数据都切到 TiDB 上。
TiDB 解决了什么问题
然后我们看一下 TiDB 解决了我们什么样的问题。前面提到的 MySQL相关的问题,TiDB 大部分都能解决。
- 首先它提高了扩展性。以前每次扩容 MySQL 对业务来说都很恼火,因为 shardingSphere 这个中间件是每一个分库都需要配置一个数据源,配置十分不友好。现在我们扩容直接扩 TiKV 就可以了,业务那边都不需要有什么操作,对业务是完全透明的。
- 扩容也更灵活了。因为现在我们增加多少容量,直接扩两个 TiKV 上去就 OK 了。以前的扩容我们是一次扩一套集群,业务也要添加新数据源再发版,而且初期资源的利用率很低。
- TIDB 给我们解决了分库分表带来的一系列的麻烦。前面说到,MySQL 分库分表的配置复杂,还有一个分库分表的在线执行 DDL、连接数影响发版等
- 提高了我们存储的写入效率。前面介绍了我们线上是直接写到 Kafka 队列里面,再通过 Kafka 消费到 MySQL 里。因为以前是 MYSQL 分库分表,从 Kafka 消费到 MySQL 只能一次写入一条数据。现在可以直接批量消费 Kafka 里面的队列,就可以通一次写入多条的方式来提高写入效率,加快 Kafka 的消费。现在基本上没有 Kafka 队列堆积的情况了。
业务现状及后续计划
我们从 2019 年 11 月份才开始正式使用 TiDB,到现在最多也就两个月的时间。在这段时间内,我们从 MySQL 迁移到 TiDB,以及曝光数据部分分区已经执行上线了,现在的线上有四套 TiDB 集群,所有集群的总容量 150T 左右,每套集群的数据量都是差不多百亿级别。如果曝光服务全部迁过来,仅曝光一个服务的数据量就是千亿级别的了。TiKV 的 Region 数量约 80 万左右。
针对当前的业务,我们还要做一些后续的计划。
- 首先,我们现在 TiDB 的部署和管理都是手动的,因为上线太快了,我们还没有做自动化操作,都是通过手动使用 Ansible 离线部署的方式。后续我们会把 TiDB 的部署和管理集成到我们的自动化平台里,这样以后部署就会很方便。
- 第二个就是曝光集群要全部使用 TiDB。当前是 TiDB+MySQL 混用,比例差不多 1:1,三个分区使用 TiDB,三个分区使用 MySQL,后续可能几个月,就基本上全部会迁移到 TiDB 上去。
- 最后持续推动 TiDB 在聚美高并发、低延时、海量存储等场景中的应用。我们目前两个业务场景用 TiDB 感觉还没什么问题,而且响应也是很快的,互动库 P99 的响应差不多是 10 毫秒,曝光库 P99 响应时间大概在 50 毫秒左右。因为我们的曝光是批量写入,会比较慢,读取是很快的,P99 的耗时也是差不多 10 毫秒左右。