
【是否原创】是
【首发渠道】TiDB 社区
【首发渠道链接】其他平台首发请附上对应链接
【正文】
测试目的
测试在集群v5.1.0环境下,TiFlash从3实例扩展到4实例、5实例后的 TPC-H 的性能提升,其中 TPC-H 测试数据为100GB,TiFlash replica 为1。
测试环境
硬件配置
- CPU:40核 Intel® Xeon® CPU E5-2630 v4 @ 2.20GHz
- Memory:188GB
- Disk:NVMe SSD 3.6T * 2
- OS:CentOS Linux release 7.9.2009 (Core) x86-64
- FileSystem : ext4
软件版本
| 组件 | 版本 | Git Hash |
|---|---|---|
| PD | 5.1.0 | 8bc9675a923f81f79d8a566e208c8afdcf4ea3f3 |
| TiDB | 5.1.0 | 727fd955197fcc80dbd9875504afe71bcef956b2 |
| TiKV | 5.1.0 | 3bbe9da7623dcf1dcb95e8ae18aad9e07fd40163 |
| TiFlash | 5.1.0 | d74c23e6ee8ee3255a167ae25b612234cae81852 |
参数配置
在执行TPCH查询之前,在会话级别上设置:
set @@session.tidb_isolation_read_engines = ‘tiflash,tidb’;
其余集群参数均为默认配置。
测试方案
集群规划
| 角色 | 地址 |
|---|---|
| TiDB server | 172.16.4.51、172.16.4.42、172.16.5.88 |
| PD | 172.16.4.51、172.16.4.42、172.16.5.88 |
| TiKV | 172.16.4.31、172.16.4.32、172.16.4.33 |
| TiFlash | 172.16.4.31、172.16.4.32、172.16.4.33、172.16.4.34 (扩展)、172.16.4.35 (扩展) |
| 监控 | 172.16.5.121 |
| 中控机 | 172.16.5.192 |
以上,集群共有10台机器,其中监控和中控机单独各1台,172.16.4.34 和 172.16.4.35 作为 TiFlash 的扩展机器。
172.16.4.31 ~ 172.16.4.33上均部署了 TiKV 和 TiFlash ,为了避免 TiKV 和 TiFlash 争抢磁盘和 I/O 资源,把 TiKV 和 TiFlash 的数据目录部署在不同的 NVMe 盘上。
测试过程
1、通过tiup部署tidb集群
2、通过 TiUP 的 bench 工具导入 TPC-H 100G 数据
使用如下命令:
tiup bench tpch prepare \"
–host ${tidb_host} --port ${tidb_port} \"
–db tpch_100 --sf 100 --tiflash --analyze \"
–tidb_build_stats_concurrency 8 --tidb_distsql_scan_concurrency 30
3、执行查询
i. 下载 TPC-H 的 SQL 查询文件:
git clone https://github.com/pingcap/tidb-bench.git && cd tpch/queries
ii. 登录TiDB并设置 tidb_isolation_read_engines
set @@session.tidb_isolation_read_engines = ‘tiflash,tidb’;
因为本次测试目的为 TiFlash 的扩展性,所以执行查询时要从 TiFlash 中读取数据。
iii. 执行查询并扩展实例
- TiFlash 为3实例时,执行查询并记录耗时(执行多次,并取三次查询结果求平均值);
- 扩展 TiFlash 为4实例,并观察监控等待region分布均匀后,再执行查询并记录耗时;
- 扩展 TiFlash 为5实例,并观察监控等待region分布均匀后,再执行查询并记录耗时;
测试结果
注意:
本测试所执行 SQL 语句对应的表只有主键,没有建立二级索引。因此以下测试结果为无索引结果。
随着 TiFlash 实例扩展,各查询的执行时间如下:
| 查询 | TiFlash 3个节点各1个实例 | TiFlash 4个节点各1个实例 | TiFlash 5个节点各1个实例 |
|---|---|---|---|
| Q1 | 7.67s | 6.12s | 4.77s |
| Q2 | 2.37s | 1.90s | 1.59s |
| Q3 | 4.51s | 3.85s | 3.35s |
| Q4 | 7.02s | 4.21s | 3.28s |
| Q5 | 11.41s | 9.06s | 7.10s |
| Q6 | 1.00s | 0.97s | 0.83s |
| Q7 | 4.79s | 3.84s | 3.10s |
| Q8 | 8.43s | 6.56s | 5.44s |
| Q9 | 29.87s | 22.95s | 18.11s |
| Q10 | 4.57s | 3.68s | 3.10s |
| Q11 | 2.78s | 2.16s | 1.97s |
| Q12 | 2.56s | 2.27s | 1.79s |
| Q13 | 5.51s | 4.48s | 3.06s |
| Q14 | 1.24s | 1.10s | 0.92s |
| Q15 | 2.63s | 2.49s | 2.10s |
| Q16 | 1.28s | 1.05s | 0.86s |
| Q17 | 10.21s | 8.56s | 6.61s |
| Q18 | 14.11s | 10.66s | 8.23s |
| Q19 | 2.63s | 2.34s | 1.95s |
| Q20 | 6.36s | 5.19s | 4.10s |
| Q21 | 18.93s | 12.10s | 9.60s |
| Q22 | 1.18s | 0.97s | 0.73s |
趋势图:

以上性能图中,绿色为 TiFlash 为3实例下的查询效率,蓝色为 TiFlash 为4实例下的查询效率,黄色为 TiFlash 为5实例下的查询效率。纵坐标是查询的处理时间,单位为秒,纵坐标越低,表示性能越好。
下面展示随着 TiFlash 实例的扩展,各个查询的执行效率的提升比例,计算方式如下:
效率提升比例 = (3个TiFlash实例下的执行时间 - 4/5个TiFlash实例下的执行时间) / 3个TiFlash实例下的执行时间 *100%
| 查询 | TiFlash扩展到4个实例的效率提升比例 | TiFlash扩展到5个实例的效率提升比例 |
|---|---|---|
| Q1 | 20.21% | 37.81% |
| Q2 | 19.83% | 32.91% |
| Q3 | 14.63% | 25.72% |
| Q4 | 40.03% | 53.28% |
| Q5 | 20.60% | 37.77% |
| Q6 | 3.00% | 17.00% |
| Q7 | 19.83% | 35.28% |
| Q8 | 22.18% | 35.47% |
| Q9 | 23.17% | 39.37% |
| Q10 | 19.47% | 32.17% |
| Q11 | 22.30% | 29.14% |
| Q12 | 11.33% | 30.08% |
| Q13 | 18.69% | 44.46% |
| Q14 | 11.29% | 25.81% |
| Q15 | 5.32% | 20.15% |
| Q16 | 17.97% | 32.81% |
| Q17 | 16.16% | 35.26% |
| Q18 | 24.45% | 41.67% |
| Q19 | 11.03% | 25.86% |
| Q20 | 18.40% | 35.53% |
| Q21 | 36.08% | 49.29% |
| Q22 | 17.80% | 38.14% |
趋势图:
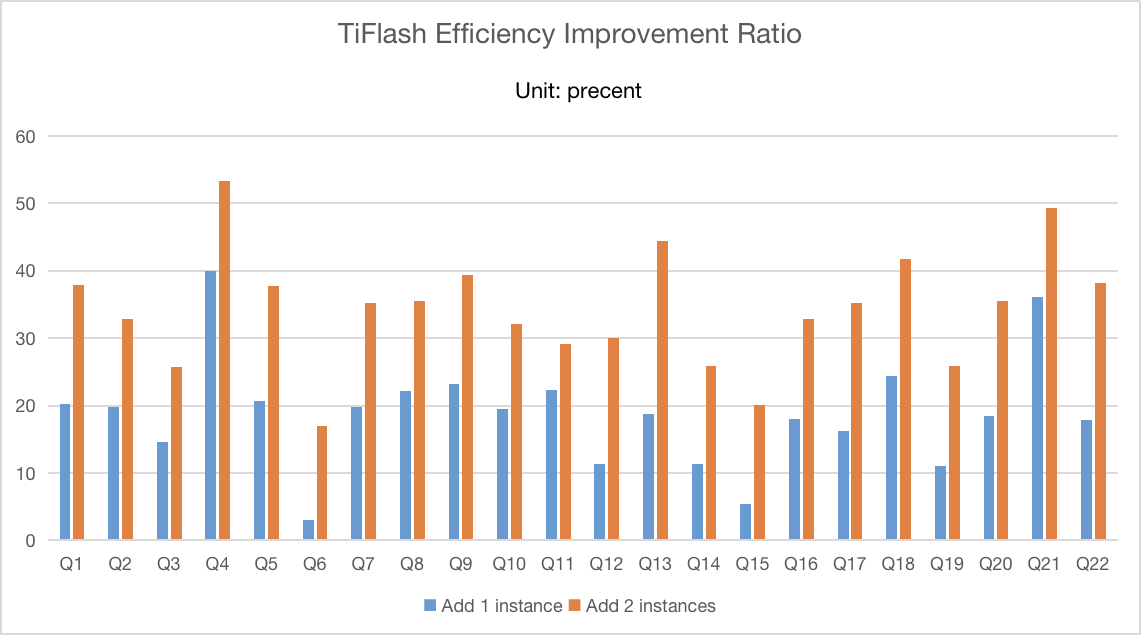
以上性能图中,蓝色为扩展了1个 TiFlash 实例下的查询效率提升比例,橙色为扩展了2个 TiFlash 实例下的查询效率提升比例。纵坐标是百分比,纵坐标越高,表示效率提升越明显。
测试总结
从以上性能图可以看出,随着TiFlash实例的扩展,各查询语句的执行时间普遍下降,执行效率普遍提升。并且其中大多数查询的效率有着较为明显地提升,如Q4、Q9、Q13、Q21等。